BERT复现学习
BERT复现学习
- 2018 年《BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding》
参考博客:
- https://www.cnblogs.com/nickchen121/p/15114385.html
- https://adaning.github.io/posts/52648.html
- https://wdndev.github.io/paper_reading/1.5.ELMo/index.html
- https://blog.csdn.net/kyle1314608/article/details/100595077
- https://github.com/codertimo/BERT-pytorch/tree/master
前置研究
图像领域预训练
CNN 可以对图片进行特征提取,一张图片放入到 CNN 中,由浅层到深层会分别提取出不同的特征,从“横竖撇捺”到“人脸”,
在图像领域中,存在两种对 CNN 浅层特征通用性的处理:
- 微调:浅层参数使用预训练模型的参数,高层参数随机初始化,利用新任务训练,浅层参数随着变化
- 冻结:浅层参数使用预训练模型的参数,高层参数随机初始化,利用新任务训练,浅层参数一直不变
优势:新任务训练收敛速度快,且可以利用微调使用深度神经网络模型解决小数据量任务
类比迁移
CV 中:
- 预训练通过前面多层神经网络对特征进行抽取,获取足够多的信息
- 新的任务只需要增加一个简单的输出层用于作为分类器
BERT 则类似于微调 NLP 模型,在预训练基础上加上一个输出层作为分类器
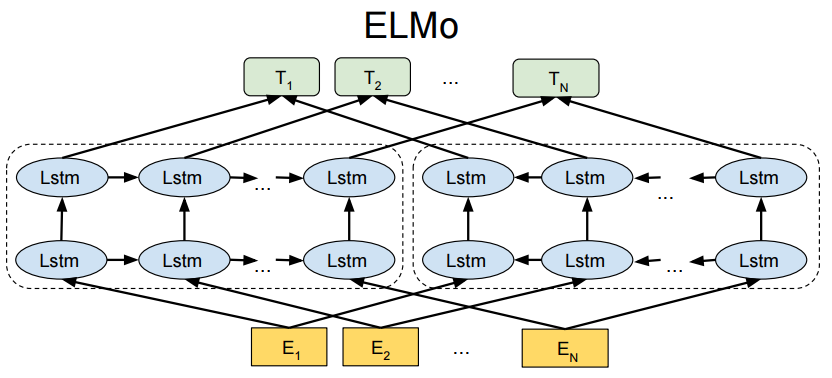
ELMO 模型
问题:word2vec 是一个静态模型,即训练好之后每个单词表示就固定了,而实际多义词在不同语境中应该有不同的词表示
ELMO(Embeddings from Language Models)利用双向 LSTM 解决动态语义问题,动态更新词的嵌入向量,实现相比于 GloVe 中基于 play 单词找出仅出现在体育领域的相关单词,也可以找出与表演等相关的句子
预训练阶段
- 第一层提取单词特征
- 第二层提取句法特征
- 第三层提取语义特征
Embedding模块
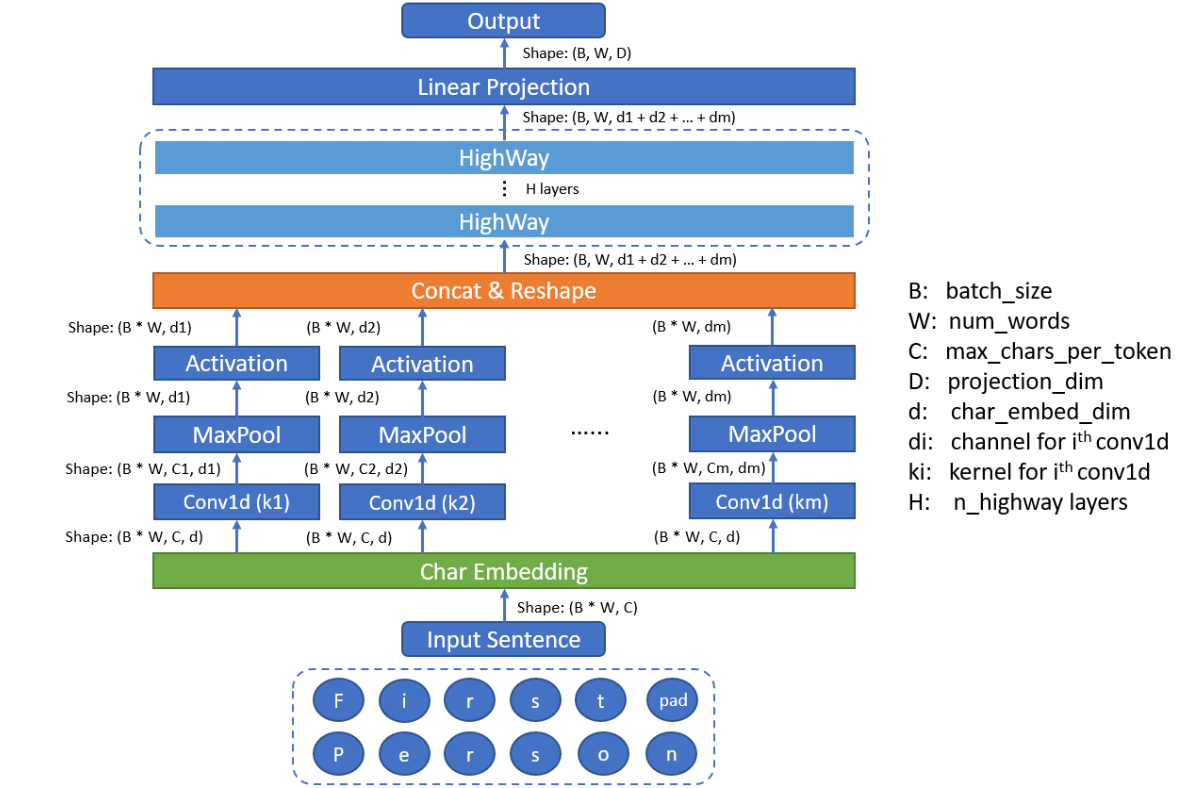
采用字符级卷积神经网络 CNN,有效解决 OOV(Out-of-Vocabulary,词汇外)问题,对 playing 单词来看
- Char Embedding:单词拆解为字符序列,填充后前后加入特殊token
<bow>和<eow>,每个字符被映射为一个低维向量
$$ [x_p,x_l,x_a,x_y,x_i,x_n,x_g] $$
- CNN Layers:卷积层用于提取单词内特征,使用从 1 到 7 等不同宽度的卷积核,卷积核实际是维护一个权重 W 和偏置 b,对于可连续看到的字符对应的向量进行计算,若卷积核宽度为 3 时
# [p, l, a] -> 向量 -> W*x + b -> ReLu -> 值
pla → 1.1
lay → 0.3
ayi → 0.0
yin → 0.2
ing → 2.4 # 最大池化获取该值- Max Pooling:有多个卷积核,每个卷积核对一个单词进行滑动后会获得多个值,如上获得了 5 个值,通过最大池化获取值最大的作为最终的值,作为表示该单词 playing 的多维向量里的一个值,若有 100 个卷积核,则每个单词由一个 100 维向量表示,每一维可能是学到的不同模式
- Highway Networks:池化后的 N 维向量送入高速公路网络,类似残差网络,g 为门控机制
$$ y=g\cdot \text{NonLinear}(x)+(1-g)\cdot x $$
- Linear Project:最终将该 N 维向量映射到 M 维作为固定词表示 E
双层LSTM模块
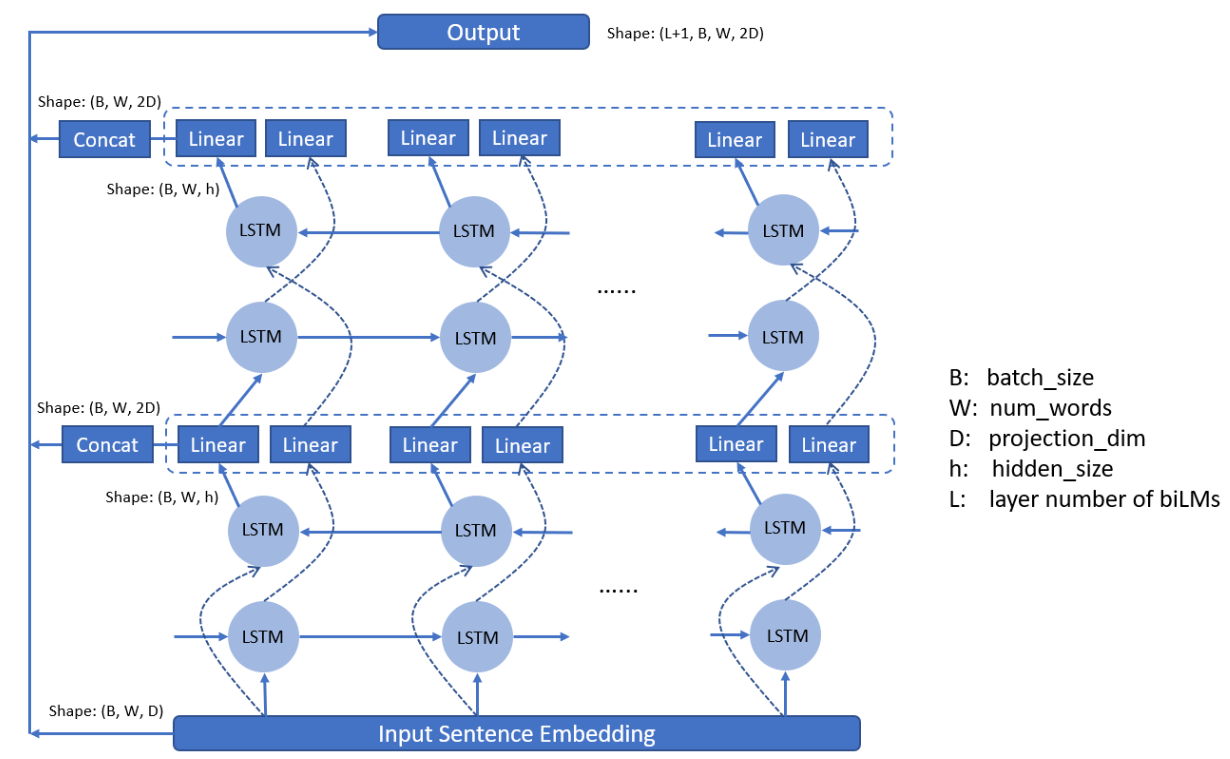
架构分成左侧的前向 LSTM 网络和右侧的反向 LSTM 网络,预训练一个语言模型,输入的句子是实时给出的,则最终得到的 T 是包含了左侧的上文信息以及右侧的下文信息的,不同句子中的一个单词的嵌入向量不一样
前向双层 LSTM 模型:根据前 k-1 个 token 序列来计算第 k 个 token 出现的概率
$$ p_1(t_1,t_2,\cdots,t_N)=\prod_{k=1}^Np{(t_k|t_1,t_2,\cdots,t_{k-1})} $$
后向双层 LSTM 模型:根据后 N-k 个 token 序列来计算第 k 个 token 出现的概率
$$ p_2(t_1,t_2,\cdots,t_N)=\prod_{k=1}^Np{(t_k|t_{k+1},t_{k+2},\cdots,t_N)} $$
训练过程中最大化以下公式
$$ \sum^N_{k=1}(\log p_1 + \log p_2) $$
词向量表征模块
对于每个 token,通过一个 L 层的双向 LSTM 网络后可以得到 2L+1 个表示向量
$$ h_{k,0}\ h_{k,1}\ \cdots \ h_{k,L} $$
- 对 token 的直接 CNN 编码
- 第一层双向 LSTM 输出结果
- 第 L 层双向 LSTM 输出结果
通过学习任务权重,引入可学习参数,针对不同下游任务进行定制化融合
$$ ELMo_k^{task}=\gamma^{task}\sum_{j=0}^L{s_j^{task}h_{k, j}} $$
s是归一化权重gamma是缩放系数
最终获得向量 ELMo,并之后接入用于二阶段下游任务中
BERT
BERT 的意义在于从大量无标记数据集中训练得到的深度模型,可以显著提高各项自然语言处理任务的准确率
- 参考了 ELMO 模型的双向编码思想
- 借鉴了 GPT 用 Transformer 作为特征提取器的思路
- 采用了 word2vec 所使用的 CBOW 方法
采用双向编码:可以同时考虑上下文信息,不仅考虑前文信息
使用 Encoder 作为特征提取器,使用掩码训练方式,使得语义信息提取能力相对于 GPT 更强
只有编码器的 transformer,有两个版本,训练 BERT 一般得要不低于 10 亿个词
| Base | Large | |
|---|---|---|
| transformer blocks | 12 | 24 |
| hidden size | 768 | 1024 |
| heads | 12 | 16 |
| parameters | 110M | 340 |
两阶段训练
- 第一阶段:使用易获取的大规模无标签语料训练基础语言模型
- 第二阶段:根据指定任务的少量带标签训练数据进行微调训练
可以看到全局信息,目标函数为
$$ P(w_i|w_1,\cdots,w_{i-1},w_{i+1},\cdots,w_n) $$
预训练任务
带掩码的语言模型(Masked Language Model Task)
BERT 希望做一个更通用的任务,即语言模型,给定前面句子预测下一个词,transformer 中的 Encoder 是不带掩码的,可以看到预测值后面的内容,标准语言模型要求是单向的,所以需要带掩码的语言模型
任务变化为:通过随机概率(15%)将一些词换成 [MASK] 让模型去预测,类似完形填空
弊端:训练阶段有 [MASK],但模型微调训练阶段或推理阶段,输入文本中没有 [MASK],导致产生由训练和预测数据偏差导致的性能损失
任务变化为:在 15% 中的这些词,再进行分配
- 80% 样本用
[MASK]代替 - 10% 样本不发生变化:缓解
- 10% 样本用任意词代替:让 BERT 学会根据上下文信息自动纠错
下一句子预测(NSP)
BERT 希望预测一个句子对中两个句子是否相邻
训练样本中,50% 概率选择相邻句子对,50%概率选择随机句子对
下游任务
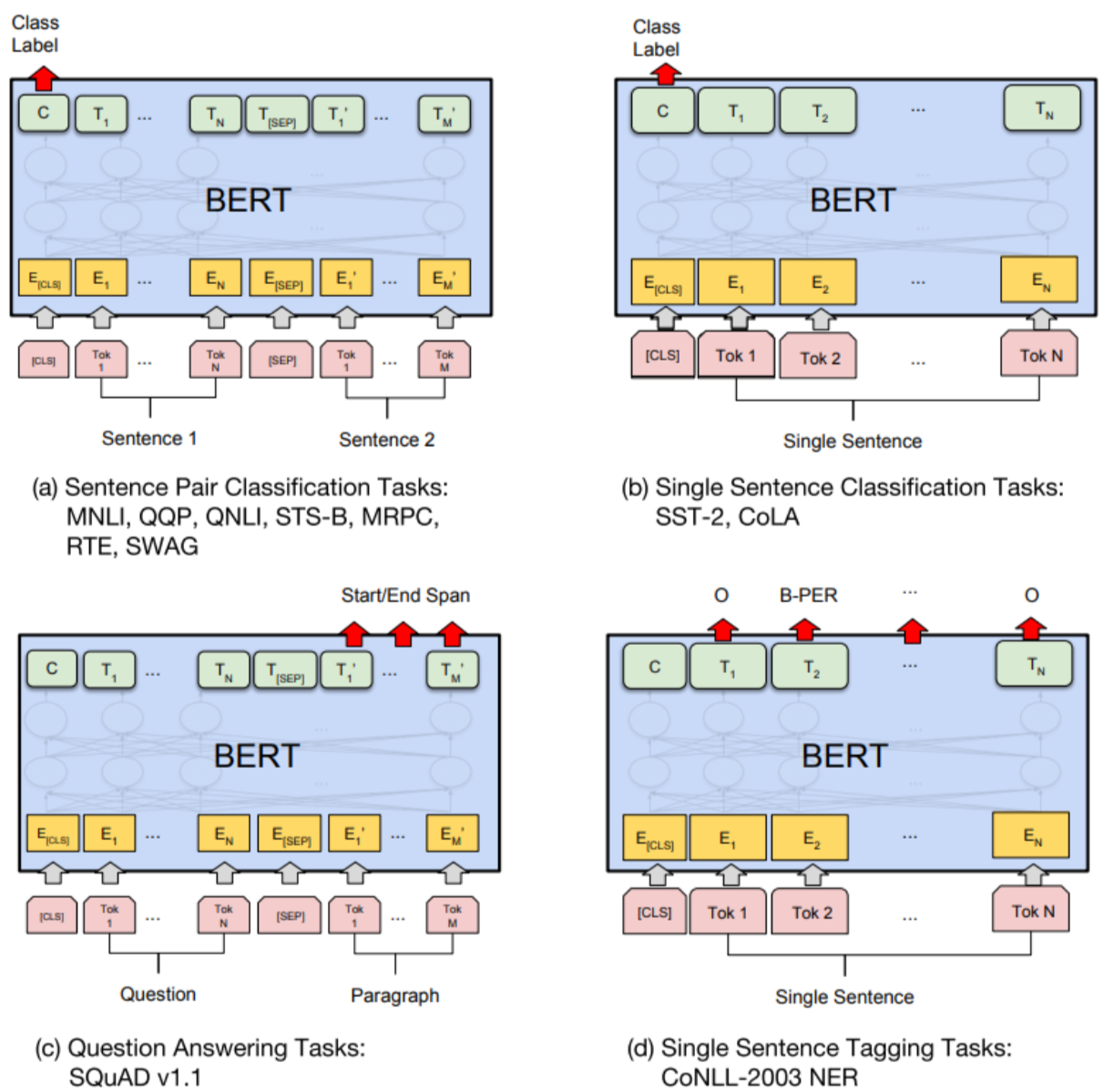
微调训练任务:
句对句类:判断句对是否相似、判断后者是否为前者答案
单句分类:情感判断、判断是否语义连贯的句子
文本问答:给定问句和蕴含答案的句子,找出答案的起始位置和终止位置
单句标注:标志每个词的标签,如人名、地名
BERT构建
导入包
import os
os.environ["HF_ENDPOINT"] = "https://hf-mirror.com"
os.environ["HF_HOME"] = "./model/"
import math
import torch
import torch.nn.functional as F
from torch import nn
from torch.utils.data import Dataset, DataLoader
from torch.optim import AdamW
from torch.optim.lr_scheduler import LambdaLR
from datasets import load_dataset
from transformers import BertTokenizer
import numpy as np
from tqdm import tqdm
import random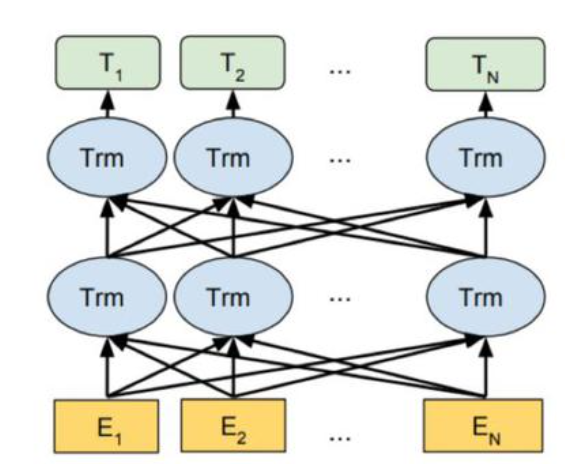
Embedding模块
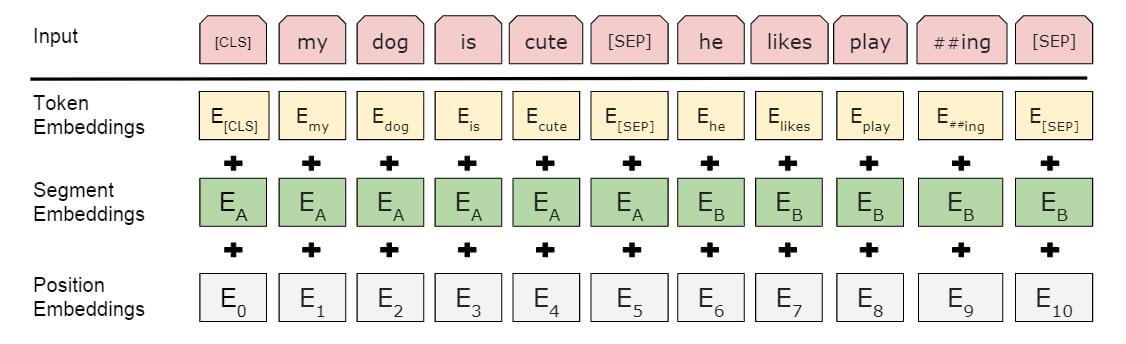
对于输入进行了修改,每个样本是一个句子对
- 加入额外的片段嵌入
- 位置编码可学习,不使用静态正余弦位置编码
BERT 中包含三种编码:Token Embedding,Position Embedding,Segment Embedding
- Segment Embedding 用于使得模型知道哪些词属于哪个句子,判断句子关系
- BERT 使用 WordPiece 分词器,将单词拆分为更小的子词单元,如
##ing表示ing是某单词的一部分 [CLS]:分类 Classification token,出现在序列开头,用于分类任务[SEP]:分隔 Separator token,分隔两个句子,标记句子结束
class BERTEmbedding(nn.Module):
def __init__(self, vocab_size, n_segs, d_model, max_len, dropout):
super().__init__()
self.token_embedding = nn.Embedding(vocab_size, d_model)
self.segment_embedding = nn.Embedding(n_segs, d_model)
self.position_embedding = nn.Embedding(max_len, d_model)
self.layer_norm = nn.LayerNorm(d_model)
self.dropout = nn.Dropout(dropout)
def forward(self, input_ids, segment_ids):
"""
input_ids: [batch_size, seq_len]
segment_ids: [batch_size, seq_len]
return: [batch_size, seq_len, d_model]
"""
batch_size, seq_len = input_ids.size()
token_emb = self.token_embedding(input_ids)
position_ids = torch.arange(seq_len, dtype=torch.long, device=input_ids.device)
position_ids = position_ids.unsqueeze(0).expand(batch_size, seq_len)
pos_emb = self.position_embedding(position_ids)
seg_emb = self.segment_embedding(segment_ids)
x = self.layer_norm(token_emb + pos_emb + seg_emb)
x = self.dropout(x)
return xEncoder模块
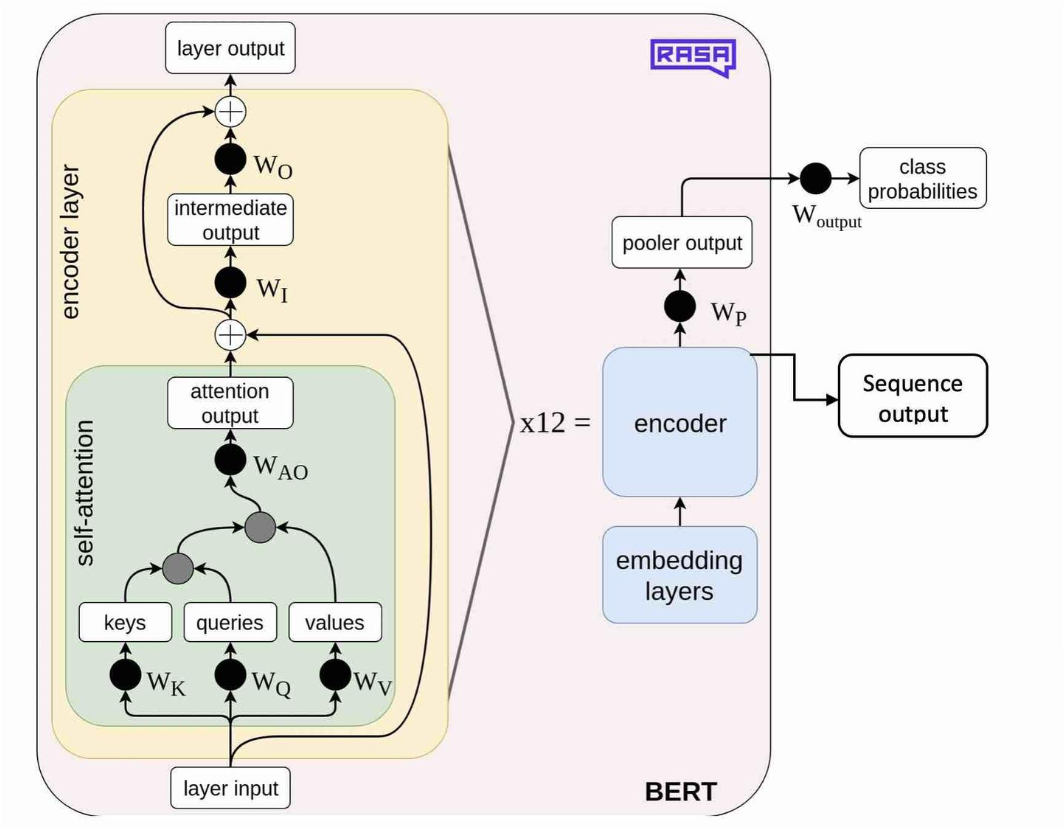
直接根据 transformer 中的模块修改而来
多头注意力模块
未修改
class MHABlock(nn.Module):
def __init__(self, d_model: int, h: int, dropout: float):
super().__init__()
self.d_model = d_model
self.h = h
self.d_k = d_model // h
self.WQ = nn.Linear(d_model, d_model, bias=False)
self.WK = nn.Linear(d_model, d_model, bias=False)
self.WV = nn.Linear(d_model, d_model, bias=False)
self.WO = nn.Linear(d_model, d_model, bias=False)
self.dropout = nn.Dropout(dropout)
@staticmethod
def attention(Q, K, V, mask, dropout):
d_k = Q.shape[-1]
attn_scores = (Q @ K.transpose(-2, -1)) / math.sqrt(d_k)
if mask is not None:
attn_scores = attn_scores.masked_fill(mask == 0, -1e9)
attn_scores = attn_scores.softmax(dim=-1)
if dropout is not None:
attn_scores = dropout(attn_scores)
return attn_scores @ V
def forward(self, XQ, XK, XV, mask):
Q = self.WQ(XQ)
K = self.WK(XK)
V = self.WV(XV)
Q = Q.view(Q.shape[0], Q.shape[1], self.h, self.d_k).transpose(1, 2)
K = K.view(K.shape[0], K.shape[1], self.h, self.d_k).transpose(1, 2)
V = V.view(V.shape[0], V.shape[1], self.h, self.d_k).transpose(1, 2)
attn = MHABlock.attention(Q, K, V, mask, self.dropout)
attn = attn.transpose(1, 2).contiguous().view(attn.shape[0], -1, self.d_model)
return self.WO(attn)前馈网络模块
使用了 GELU 激活函数
class FFNBlock(nn.Module):
def __init__(self, d_model: int, d_ff: int, dropout: float):
super().__init__()
self.net = nn.Sequential(
nn.Linear(d_model, d_ff),
nn.GELU(),
nn.Dropout(dropout),
nn.Linear(d_ff, d_model)
)
def forward(self, x):
return self.net(x)编码块模块
未修改
class EncoderBlock(nn.Module):
def __init__(self, d_model: int, num_heads: int, d_ff: int, dropout: float):
super().__init__()
self.mha_block = MHABlock(d_model=d_model, h=num_heads, dropout=dropout)
self.ffn = FFNBlock(d_model=d_model, d_ff=d_ff, dropout=dropout)
self.norm1 = nn.LayerNorm(d_model)
self.norm2 = nn.LayerNorm(d_model)
self.dropout = nn.Dropout(dropout)
def forward(self, x, pad_mask):
_x = self.norm1(x)
x = x + self.dropout(self.mha_block(_x, _x, _x, pad_mask))
_x = self.norm2(x)
x = x + self.dropout(self.ffn(_x))
return x编码器模块
未修改
class Encoder(nn.Module):
def __init__(self, num_layers: int, d_model: int, num_heads: int, d_ff: int, dropout: float):
super().__init__()
self.layers = nn.ModuleList([
EncoderBlock(d_model, num_heads, d_ff, dropout) for _ in range(num_layers)
])
def forward(self, x, pad_mask):
for layer in self.layers:
x = layer(x, pad_mask)
return x掩码函数
在 BERT 中没有 Decoder,所以掩码只为 Padding 服务
def create_pad_mask(tokens, pad_idx=0):
pad_mask = (tokens != pad_idx).unsqueeze(1).unsqueeze(2)
return pad_mask # (batch_size, 1, 1, seq_len)池化模块
Pooler 是 Hugging Face 实现 BERT 时加入的额外组件,NSP 任务需要提取 [CLS] 处的特征,此处将该输出接入一个全连接层,并用 tanh 激活,最后再接上二分类输出层
class Pooler(nn.Module):
def __init__(self, d_model):
super().__init__()
self.fc = nn.Linear(d_model, d_model)
self.tanh = nn.Tanh()
def forward(self, x):
x = self.fc(x)
x = self.tanh(x)
return xBERT模块
class BERT(nn.Module):
def __init__(self, vocab_size, n_segs, d_model, nhead, n_layers, d_ff, dropout, max_len):
super().__init__()
self.embedding = BERTEmbedding(vocab_size, n_segs, d_model, max_len, dropout)
self.encoders = Encoder(n_layers, d_model, nhead, d_ff, dropout)
self.pooler = Pooler(d_model)
self.fc = nn.Linear(d_model, d_model)
self.gelu = nn.GELU()
self.layer_norm = nn.LayerNorm(d_model)
self.nsp_head = nn.Linear(d_model, 2)
self.mlm_head = nn.Linear(d_model, vocab_size)
self.d_model = d_model
# MLM 预测层与 token embedding 共享权重
self.mlm_head.weight = self.embedding.token_embedding.weight
def forward(self, input_ids, segment_ids, masked_pos):
"""
segment_ids, input_ids: [batch_size, seq_len]
"""
# x: [batch_size, seq_len, d_model]
x = self.embedding(input_ids, segment_ids)
# pad_mask: [batch_size, 1, 1, seq_len]
pad_mask = create_pad_mask(input_ids)
# output: [batch_size, seq_len, d_model]
output = self.encoders(x, pad_mask)
# NSP任务
hidden_pool = self.pooler(output[:, 0]) # 取每个样本第 0 个 token, [CLS] 的隐藏状态 [batch_size, d_model]
logits_cls = self.nsp_head(hidden_pool) # [batch_size, n_segs:2] 是否为下一个句子
# MLM任务
# masked_pos: [batch_size, max_pred] -> [batch_size, max_pred, 1] -> [batch, max_pred, d_model]
masked_pos = masked_pos.unsqueeze(-1).expand(-1, -1, self.d_model)
# h_masked: [batch_size, max_pred, d_model]
h_masked = torch.gather(output, dim=1, index=masked_pos)
h_masked = self.gelu(self.fc(h_masked))
h_masked = self.layer_norm(h_masked)
# logits_lm: [batch_size, max_pred, vocab_size]
logits_lm = self.mlm_head(h_masked)
return logits_cls, logits_lm训练的目标有两个,此处放在一起有可能导致最终不能同时满足要求,可能导致 mlm 准确率和 nsp 准确率成反比
训练模型
数据集模块
- mlm_prob 为 15%
- 且使用 -1 作为 padding id
class BERTDataset(Dataset):
def __init__(self, texts, tokenizer, max_len=128, mlm_prob=0.15):
self.texts = texts
self.tokenizer = tokenizer
self.max_len = max_len
self.mlm_prob = mlm_prob
self.vocab_size = tokenizer.vocab_size
def __len__(self):
return len(self.texts)
def create_mlm_data(self, tokens):
"""创建MLM任务的mask"""
output_tokens = tokens.copy()
masked_positions = []
masked_labels = []
for i, token in enumerate(tokens):
# 跳过特殊token
if token in [self.tokenizer.cls_token_id, self.tokenizer.sep_token_id,
self.tokenizer.pad_token_id]:
continue
if random.random() < self.mlm_prob:
masked_positions.append(i)
masked_labels.append(token)
prob = random.random()
if prob < 0.8: # 80%替换为[MASK]
output_tokens[i] = self.tokenizer.mask_token_id
elif prob < 0.9: # 10%替换为随机token
output_tokens[i] = random.randint(0, self.vocab_size - 1)
# 10%保持不变
return output_tokens, masked_positions, masked_labels
def __getitem__(self, idx):
# 获取两个句子用于NSP任务
text = self.texts[idx]
# 50%概率选择连续句子,50%选择随机句子
if random.random() < 0.5 and idx < len(self.texts) - 1:
# 第一句非末尾, 选择下一个句子
is_next = 1
next_text = self.texts[idx + 1]
else:
# 选择随机句子
is_next = 0
random_idx = random.randint(0, len(self.texts) - 1)
while random_idx == idx:
random_idx = random.randint(0, len(self.texts) - 1)
next_text = self.texts[random_idx]
# Tokenize
tokens_a = self.tokenizer.encode(text, add_special_tokens=False)
tokens_b = self.tokenizer.encode(next_text, add_special_tokens=False)
# 截断
max_len_per_sent = (self.max_len - 3) // 2
tokens_a = tokens_a[:max_len_per_sent]
tokens_b = tokens_b[:max_len_per_sent]
# 构建输入: [CLS] + tokens_a + [SEP] + tokens_b + [SEP]
tokens = [self.tokenizer.cls_token_id] + tokens_a + [self.tokenizer.sep_token_id] + \
tokens_b + [self.tokenizer.sep_token_id]
segment_ids = [0] * (len(tokens_a) + 2) + [1] * (len(tokens_b) + 1)
# 创建MLM数据
tokens, masked_positions, masked_labels = self.create_mlm_data(tokens)
# Padding
n_pad = self.max_len - len(tokens)
tokens += [self.tokenizer.pad_token_id] * n_pad # tokens_ids 用 [pad] 填充
segment_ids += [0] * n_pad # segment_ids 用 0 填充
# Padding masked positions
n_masked = len(masked_positions) # mask 的数量
max_pred = max(1, int(self.max_len * self.mlm_prob)) # 最大序列长128 * 概率 0.15, 即 mask 数量不能超过 15%
if n_masked < max_pred:
masked_positions += [0] * (max_pred - n_masked)
masked_labels += [-1] * (max_pred - n_masked) # 使用 -1 作为 padding
else: # 否则截断
masked_positions = masked_positions[:max_pred]
masked_labels = masked_labels[:max_pred]
return {
'input_ids': torch.tensor(tokens, dtype=torch.long),
'segment_ids': torch.tensor(segment_ids, dtype=torch.long),
'masked_pos': torch.tensor(masked_positions, dtype=torch.long),
'masked_labels': torch.tensor(masked_labels, dtype=torch.long),
'is_next': torch.tensor(is_next, dtype=torch.long)
}由于不太确定数据集加载是否正确,所以此处对数据进行了查看
- 加载数据集
tokenizer = BertTokenizer.from_pretrained('bert-base-uncased')
dataset = load_dataset('wikitext', 'wikitext-2-raw-v1')
train_texts = [text.strip() for text in dataset['train']['text'] if text.strip()]
val_texts = [text.strip() for text in dataset['validation']['text'] if text.strip()]
# 创建数据集
train_dataset = BERTDataset(train_texts, tokenizer, max_len=128)
val_dataset = BERTDataset(val_texts, tokenizer, max_len=128)- 以索引 3 来查看训练文本和训练集数据,内容一致,以及查看索引 4 训练集数据
print(train_texts[3])
print(train_dataset.texts[3])
# It met with positive sales in Japan , and was praised by both Japanese and western critics . After release , it received downloadable content , along with an expanded edition in November of that year . It was also adapted into manga and an original video animation series . Due to low sales of Valkyria Chronicles II , Valkyria Chronicles III was not localized , but a fan translation compatible with the game 's expanded edition was released in 2014 . Media.Vision would return to the franchise with the development of Valkyria : Azure Revolution for the PlayStation 4 .
print(train_dataset.texts[4])
# = = Gameplay = =- 实际数据集包含
input_ids,segment_ids,masked_pos,masked_labels,is_next,前两个长度为 128,masked_pos 和 masked_labels 长度一致 ,is_next 为一个值,每次都会随机进行 mask,对 mask 是否正确进行预测,每次运行随机
sample = train_dataset[3]
m_p = sample['masked_pos'].tolist()
ids = sample['input_ids'].tolist()
m_l = sample['masked_labels'].tolist()
for i, (pos, label) in enumerate(zip(m_p, m_l)):
if label == -1: # padding
continue
actual_token = ids[pos]
print(f"位置{pos}: 应预测{tokenizer.convert_ids_to_tokens([label])[0]}, "
f"实际是{tokenizer.convert_ids_to_tokens([actual_token])[0]}")
# 位置7: 应预测japan, 实际是[MASK]
# 位置13: 应预测both, 实际是[MASK]
# 位置19: 应预测after, 实际是sheltered
# 位置36: 应预测year, 实际是year
# 位置59: 应预测chronicles, 实际是[MASK]
# 位置67: 应预测-, 实际是[MASK]segment_ids 则第一句话位置处均为 0,第二句话位置处均为 1,剩余用 0 填充
- 查看 NSP 数据,第一句最终从 val 被截断,第二句太少而进行了大量的 [pad] 填充
sample = train_dataset[3]
ids = sample['input_ids'].tolist()
for i in ids:
print(tokenizer.convert_ids_to_tokens(i), end=' ')
# 第一句: [CLS] it met with positive sales [MASK] japan , and was praised by [MASK] japanese and western [MASK] . after release , it received downloadable content , along with an expanded edition in november of that year [MASK] it was also adapted into manga and an original [MASK] animation series [MASK] due to low sales [MASK] val [MASK] ##ria chronicles ii , val [SEP]
# 第二句: = = = = garage = [MASK] = = [SEP] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] 目前看来数据集加载处理没有问题,而因为数据集本身未经过处理,可能导致最终效果也不是特别好
批处理函数
batch 是一个列表,包含多个样本,每个样本中是字典
- 批处理,从每个样本中取出
input_ids字段,得到张量列表,通过torch.stack()堆叠成一个新的张量,比如 32 个样本,每个样本 [128],则最终 shape 为 [32, 128]
def collate_fn(batch):
"""批处理函数"""
input_ids = torch.stack([item['input_ids'] for item in batch])
segment_ids = torch.stack([item['segment_ids'] for item in batch])
masked_pos = torch.stack([item['masked_pos'] for item in batch])
masked_labels = torch.stack([item['masked_labels'] for item in batch])
is_next = torch.stack([item['is_next'] for item in batch])
return {
'input_ids': input_ids,
'segment_ids': segment_ids,
'masked_pos': masked_pos,
'masked_labels': masked_labels,
'is_next': is_next
}预热余弦退火策略
训练初期先缓慢增加学习率以稳定模型,随后按照余弦函数曲线逐渐减小学习率,帮助模型更好收敛
当前步数小于设定的预热步数时,学习率倍数从 0 线性增加到 1
预热结束后,学习率平滑下降
- 计算当前处于”后预热阶段“的百分比,0 到 1
- 余弦变换
$$ \frac{1}{2}\times (1+\cos (\pi\times\text{progress})) $$
def get_cosine_schedule_with_warmup(optimizer, num_warmup_steps, num_training_steps):
"""带warmup的余弦退火学习率"""
def lr_lambda(current_step):
# 线性预热
if current_step < num_warmup_steps:
return float(current_step) / float(max(1, num_warmup_steps))
# 余弦退火
progress = float(current_step - num_warmup_steps) / float(max(1, num_training_steps - num_warmup_steps))
return max(0.0, 0.5 * (1.0 + math.cos(math.pi * progress)))
return LambdaLR(optimizer, lr_lambda)训练函数
同时计算准确率
def train_epoch(model, dataloader, optimizer, scheduler, device, epoch):
model.train()
total_loss = 0
total_mlm_loss = 0
total_nsp_loss = 0
total_mlm_acc = 0
total_nsp_acc = 0
pbar = tqdm(dataloader, desc=f'Epoch {epoch}')
for batch in pbar:
input_ids = batch['input_ids'].to(device)
segment_ids = batch['segment_ids'].to(device)
masked_pos = batch['masked_pos'].to(device)
masked_labels = batch['masked_labels'].to(device)
is_next = batch['is_next'].to(device) # batch_size 个值, 0 或 1
optimizer.zero_grad()
# 前向传播
# logits_cls: [batch_size, n_seg] logits_lm: [batch_size, max_pred, vocab_size]
logits_cls, logits_lm = model(input_ids, segment_ids, masked_pos)
# 计算损失
nsp_loss = F.cross_entropy(logits_cls, is_next)
# MLM损失(忽略padding的位置,使用 -1)
mlm_loss = F.cross_entropy(
logits_lm.view(-1, logits_lm.size(-1)),
masked_labels.view(-1),
ignore_index=-1
)
loss = mlm_loss + nsp_loss
# 反向传播
loss.backward()
torch.nn.utils.clip_grad_norm_(model.parameters(), 1.0)
optimizer.step()
scheduler.step()
# 计算准确率
nsp_pred = logits_cls.argmax(dim=-1)
nsp_acc = (nsp_pred == is_next).float().mean()
# MLM 准确率计算
mlm_pred = logits_lm.argmax(dim=-1) # 对预测 logits 取最大值
mlm_mask = (masked_labels != -1)
if mlm_mask.sum() > 0: # 避免除以0
mlm_acc = ((mlm_pred == masked_labels) & mlm_mask).float().sum() / mlm_mask.float().sum()
else:
mlm_acc = torch.tensor(0.0)
# 累计
total_loss += loss.item()
total_mlm_loss += mlm_loss.item()
total_nsp_loss += nsp_loss.item()
total_mlm_acc += mlm_acc.item()
total_nsp_acc += nsp_acc.item()
pbar.set_postfix({
'loss': f'{loss.item():.4f}',
'mlm_acc': f'{mlm_acc.item():.4f}',
'nsp_acc': f'{nsp_acc.item():.4f}',
'lr': f'{scheduler.get_last_lr()[0]:.6f}'
})
n = len(dataloader)
return {
'loss': total_loss / n,
'mlm_loss': total_mlm_loss / n,
'nsp_loss': total_nsp_loss / n,
'mlm_acc': total_mlm_acc / n,
'nsp_acc': total_nsp_acc / n
}对于 NSP 任务
- 计算损失值,使用了
cross_entropy,在内部对于预测的 logits [batch_size, 2],对其进行 softmax,取对应真实标签 is_next [batch_size] 中的对应的概率,若为 0 则取第 0 个,若为 1 则取第 1 个,接着进行交叉熵损失计算 - 计算准确率,通过
argmax(dim=-1)取出概率更大的一个,获得长为 batch_size 的列表,is_next 是一个长为 batch_size 的列表,以此计算准确率
对于 MLM 任务
- 计算损失值,预测的 logits_lm [batch_size, max_pred, vocab_size],先将其转换为 [batch_size * max_pred, vocab_size],softmax 后交叉熵损失计算,而 masked_labels 先转换为 [batch_size * max_pred] 计算最终损失值,忽略 -1 因为 -1 为未 masked 的位置
- 计算准确率,首先在 vocb_size 维度对预测 logits 取最大值,接着计算 label 不为 -1 的 mlm_mask,对其求和 sum() 得到 true 的个数,需要确保该值大于 0,即保证有 mask 的内容,接着计算是否有预测正确的值,计算准确率
评估函数
@torch.no_grad()
def evaluate(model, dataloader, device):
model.eval()
total_loss = 0
total_mlm_loss = 0
total_nsp_loss = 0
total_mlm_acc = 0
total_nsp_acc = 0
for batch in tqdm(dataloader, desc='Evaluating'):
input_ids = batch['input_ids'].to(device)
segment_ids = batch['segment_ids'].to(device)
masked_pos = batch['masked_pos'].to(device)
masked_labels = batch['masked_labels'].to(device)
is_next = batch['is_next'].to(device)
logits_cls, logits_lm = model(input_ids, segment_ids, masked_pos)
nsp_loss = F.cross_entropy(logits_cls, is_next)
mlm_loss = F.cross_entropy(
logits_lm.view(-1, logits_lm.size(-1)),
masked_labels.view(-1),
ignore_index=-1
)
loss = mlm_loss + nsp_loss
nsp_pred = logits_cls.argmax(dim=-1)
nsp_acc = (nsp_pred == is_next).float().mean()
mlm_pred = logits_lm.argmax(dim=-1)
mlm_mask = (masked_labels != -1)
if mlm_mask.sum() > 0:
mlm_acc = ((mlm_pred == masked_labels) & mlm_mask).float().sum() / mlm_mask.float().sum()
else:
mlm_acc = torch.tensor(0.0)
total_loss += loss.item()
total_mlm_loss += mlm_loss.item()
total_nsp_loss += nsp_loss.item()
total_mlm_acc += mlm_acc.item()
total_nsp_acc += nsp_acc.item()
n = len(dataloader)
return {
'loss': total_loss / n,
'mlm_loss': total_mlm_loss / n,
'nsp_loss': total_nsp_loss / n,
'mlm_acc': total_mlm_acc / n,
'nsp_acc': total_nsp_acc / n
}参数配置
由于准备使用小数据集 wikitext-2-raw-v1 进行测试,修改了部分参数配置
- 原始论文层数为 12,减小为 6
# 设置随机种子
seed = 42
torch.manual_seed(seed)
np.random.seed(seed)
random.seed(seed)
# 设备
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
print(f'Using device: {device}')
config = {
'vocab_size': 30522,
'n_segs': 2,
'd_model': 512,
'nhead': 8,
'n_layers': 6,
'd_ff': 1024,
'dropout': 0.1,
'max_len': 128,
'batch_size': 64,
'num_epochs': 100,
'lr': 1e-4,
'warmup_ratio': 0.1,
'weight_decay': 0.01,
'save_dir': './bert_checkpoints'
}
os.makedirs(config['save_dir'], exist_ok=True)正式训练
# 加载tokenizer
print('Loading tokenizer...')
tokenizer = BertTokenizer.from_pretrained('bert-base-uncased')
# 加载数据集
print('Loading dataset...')
dataset = load_dataset('wikitext', 'wikitext-2-raw-v1')
# 过滤空文本
train_texts = [text.strip() for text in dataset['train']['text'] if text.strip()]
val_texts = [text.strip() for text in dataset['validation']['text'] if text.strip()]
print(f'Train samples: {len(train_texts)}') # 23767
print(f'Val samples: {len(val_texts)}') # 2461
# 创建数据集
train_dataset = BERTDataset(train_texts, tokenizer, max_len=config['max_len'])
val_dataset = BERTDataset(val_texts, tokenizer, max_len=config['max_len'])
# 创建数据加载器
train_loader = DataLoader(
train_dataset,
batch_size=config['batch_size'],
shuffle=True,
collate_fn=collate_fn,
num_workers=4,
pin_memory=True
)
val_loader = DataLoader(
val_dataset,
batch_size=config['batch_size'],
shuffle=False,
collate_fn=collate_fn,
num_workers=4,
pin_memory=True
)
# 创建模型
print('Creating model...')
model = BERT(
vocab_size=config['vocab_size'],
n_segs=config['n_segs'],
d_model=config['d_model'],
nhead=config['nhead'],
n_layers=config['n_layers'],
d_ff=config['d_ff'],
dropout=config['dropout'],
max_len=config['max_len']
).to(device)
# 打印模型参数量
total_params = sum(p.numel() for p in model.parameters())
print(f'Total parameters: {total_params:,}') # 28,857,148
# 优化器配置
optimizer = AdamW(
model.parameters(),
lr=config['lr'],
betas=(0.9, 0.999),
eps=1e-6,
weight_decay=config['weight_decay']
)
# 计算warmup步数
total_steps = len(train_loader) * config['num_epochs']
warmup_steps = int(total_steps * config['warmup_ratio'])
print(f'Total training steps: {total_steps}') # 37200
print(f'Warmup steps: {warmup_steps}') # 3720
scheduler = get_cosine_schedule_with_warmup(
optimizer,
num_warmup_steps=warmup_steps,
num_training_steps=total_steps
)
# 训练循环
print('Starting training...')
best_val_loss = float('inf')
best_mlm_acc = 0.0
patience = 10 # Early stopping patience
patience_counter = 0
for epoch in range(1, config['num_epochs'] + 1):
print(f'\n=== Epoch {epoch}/{config["num_epochs"]} ===')
# 训练
train_metrics = train_epoch(model, train_loader, optimizer, scheduler, device, epoch)
print(f'Train - Loss: {train_metrics["loss"]:.4f}, '
f'MLM Loss: {train_metrics["mlm_loss"]:.4f}, '
f'NSP Loss: {train_metrics["nsp_loss"]:.4f}, '
f'MLM Acc: {train_metrics["mlm_acc"]:.4f}, '
f'NSP Acc: {train_metrics["nsp_acc"]:.4f}')
# 评估
val_metrics = evaluate(model, val_loader, device)
print(f'Val - Loss: {val_metrics["loss"]:.4f}, '
f'MLM Loss: {val_metrics["mlm_loss"]:.4f}, '
f'NSP Loss: {val_metrics["nsp_loss"]:.4f}, '
f'MLM Acc: {val_metrics["mlm_acc"]:.4f}, '
f'NSP Acc: {val_metrics["nsp_acc"]:.4f}')
# 同时追踪loss和accuracy
improved = False
if val_metrics['loss'] < best_val_loss:
best_val_loss = val_metrics['loss']
improved = True
if val_metrics['mlm_acc'] > best_mlm_acc:
best_mlm_acc = val_metrics['mlm_acc']
improved = True
if improved:
patience_counter = 0
checkpoint_path = os.path.join(config['save_dir'], 'best_model.pt')
torch.save({
'epoch': epoch,
'model_state_dict': model.state_dict(),
'optimizer_state_dict': optimizer.state_dict(),
'scheduler_state_dict': scheduler.state_dict(),
'val_loss': val_metrics['loss'],
'mlm_acc': val_metrics['mlm_acc'],
'config': config
}, checkpoint_path)
print(f'Saved best model (Loss: {best_val_loss:.4f}, MLM Acc: {best_mlm_acc:.4f})')
else:
patience_counter += 1
print(f'No improvement for {patience_counter}/{patience} epochs')
# 提早停止
if patience_counter >= patience:
print(f'\nEarly stopping triggered after {epoch} epochs')
print(f'Best Val Loss: {best_val_loss:.4f}')
print(f'Best MLM Acc: {best_mlm_acc:.4f}')
break
print('\nTraining completed!')最终训练结果
- MLM 任务准确率 30% 多
- NSP 准确率 70% 多
- 验证集损失:6.3781
模型推理
MLM测试
@torch.no_grad()
def test_mlm(model, tokenizer, text, device):
"""测试Masked Language Model"""
model.eval()
# Tokenize并添加mask
tokens = tokenizer.encode(text, add_special_tokens=True)
print(f"\nOriginal text: {text}")
print(f"Tokens: {tokenizer.convert_ids_to_tokens(tokens)}")
# 随机mask几个token
masked_indices = []
masked_tokens = []
for i in range(1, len(tokens) - 1): # 跳过[CLS]和[SEP]
if random.random() < 0.15:
masked_indices.append(i)
masked_tokens.append(tokens[i])
tokens[i] = tokenizer.mask_token_id
print(f"Masked tokens: {tokenizer.convert_ids_to_tokens(masked_tokens)}")
print(f"Masked text: {tokenizer.convert_ids_to_tokens(tokens)}")
# 准备输入
max_len = 128
segment_ids = [0] * len(tokens)
# Padding
n_pad = max_len - len(tokens)
tokens += [tokenizer.pad_token_id] * n_pad
segment_ids += [0] * n_pad
# 准备masked_pos
n_masked = len(masked_indices)
max_pred = max(1, int(max_len * 0.15))
if n_masked < max_pred:
masked_indices += [0] * (max_pred - n_masked)
# masked_tokens += [-1] * (max_pred - n_masked)
else:
masked_indices = masked_indices[:max_pred]
# masked_tokens = masked_tokens[:max_pred]
# 转换为tensor
input_ids = torch.tensor([tokens], dtype=torch.long).to(device)
segment_ids = torch.tensor([segment_ids], dtype=torch.long).to(device)
masked_pos = torch.tensor([masked_indices], dtype=torch.long).to(device)
# 预测
_, logits_lm = model(input_ids, segment_ids, masked_pos)
predictions = logits_lm.argmax(dim=-1)[0]
# 显示预测结果
print("\nPredictions:")
for i, (pos, true_token) in enumerate(zip(masked_indices[:len(masked_tokens)], masked_tokens)):
pred_token = predictions[i].item()
print(f"Position {pos}: True={tokenizer.convert_ids_to_tokens([true_token])[0]}, "
f"Predicted={tokenizer.convert_ids_to_tokens([pred_token])[0]}")NSP测试
@torch.no_grad()
def test_nsp(model, tokenizer, sent1, sent2, device):
"""测试Next Sentence Prediction"""
model.eval()
# Tokenize
tokens_a = tokenizer.encode(sent1, add_special_tokens=False)
tokens_b = tokenizer.encode(sent2, add_special_tokens=False)
# 构建输入
tokens = [tokenizer.cls_token_id] + tokens_a + [tokenizer.sep_token_id] + \
tokens_b + [tokenizer.sep_token_id]
segment_ids = [0] * (len(tokens_a) + 2) + [1] * (len(tokens_b) + 1)
# Padding
max_len = 128
n_pad = max_len - len(tokens)
tokens += [tokenizer.pad_token_id] * n_pad
segment_ids += [0] * n_pad
# 准备masked_pos, 虽然不用, 但模型需要
masked_pos = [0] * max(1, int(max_len * 0.15))
# 转换为tensor
input_ids = torch.tensor([tokens], dtype=torch.long).to(device)
segment_ids = torch.tensor([segment_ids], dtype=torch.long).to(device)
masked_pos = torch.tensor([masked_pos], dtype=torch.long).to(device)
# 预测
logits_cls, _ = model(input_ids, segment_ids, masked_pos)
probs = F.softmax(logits_cls, dim=-1)[0]
print(f"\nSentence 1: {sent1}")
print(f"Sentence 2: {sent2}")
print(f"IsNext probability: {probs[1].item():.4f}")
print(f"NotNext probability: {probs[0].item():.4f}")
print(f"Prediction: {'IsNext' if probs[1] > probs[0] else 'NotNext'}")完整推理
def inference():
"""加载训练好的模型并进行推理测试"""
# 设备
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
print(f'Using device: {device}')
# 加载tokenizer
tokenizer = BertTokenizer.from_pretrained('bert-base-uncased')
# 加载检查点
checkpoint_path = '../BERT2/bert_checkpoints/best_model.pt'
print(f'Loading checkpoint from {checkpoint_path}')
checkpoint = torch.load(checkpoint_path, map_location=device)
config = checkpoint['config']
# 创建模型
model = BERT(
vocab_size=config['vocab_size'],
n_segs=config['n_segs'],
d_model=config['d_model'],
nhead=config['nhead'],
n_layers=config['n_layers'],
d_ff=config['d_ff'],
dropout=config['dropout'],
max_len=config['max_len']
).to(device)
# 加载模型权重
model.load_state_dict(checkpoint['model_state_dict'])
print(f'Model loaded from epoch {checkpoint["epoch"]}')
print(f'Validation loss: {checkpoint["val_loss"]:.4f}')
# ==================== MLM测试 ====================
print('\n' + '='*50)
print('Testing Masked Language Model (MLM)')
print('='*50)
test_sentences = [
"The quick brown fox jumps over the lazy dog.",
"Machine learning is a subset of artificial intelligence.",
"Python is a popular programming language for data science.",
"The weather today is sunny and warm."
]
for sent in test_sentences:
test_mlm(model, tokenizer, sent, device)
print('-'*50)
# ==================== NSP测试 ====================
print('\n' + '='*50)
print('Testing Next Sentence Prediction (NSP)')
print('='*50)
# 测试连续句子对(应该预测为IsNext)
print("\n--- Testing consecutive sentences ---")
test_nsp(
model, tokenizer,
"I went to the store yesterday.",
"I bought some milk and eggs.",
device
)
test_nsp(
model, tokenizer,
"The company announced new products.",
"The stock price increased significantly.",
device
)
# 测试不相关句子对(应该预测为NotNext)
print("\n--- Testing random sentences ---")
test_nsp(
model, tokenizer,
"I love pizza and pasta.",
"The quantum computer uses qubits.",
device
)
test_nsp(
model, tokenizer,
"The cat sat on the mat.",
"Machine learning requires large datasets.",
device
)
inference()最终推理效果不是很好,MLM 任务效果很差,NSP 任务基本都是预测为是下一句
Model loaded from epoch 89
Validation loss: 6.4003
==================================================
Testing Masked Language Model (MLM)
==================================================
Original text: The quick brown fox jumps over the lazy dog.
Tokens: ['[CLS]', 'the', 'quick', 'brown', 'fox', 'jumps', 'over', 'the', 'lazy', 'dog', '.', '[SEP]']
Masked tokens: ['quick']
Masked text: ['[CLS]', 'the', '[MASK]', 'brown', 'fox', 'jumps', 'over', 'the', 'lazy', 'dog', '.', '[SEP]']
Predictions:
Position 2: True=quick, Predicted==
--------------------------------------------------
Original text: Machine learning is a subset of artificial intelligence.
Tokens: ['[CLS]', 'machine', 'learning', 'is', 'a', 'subset', 'of', 'artificial', 'intelligence', '.', '[SEP]']
Masked tokens: ['.']
Masked text: ['[CLS]', 'machine', 'learning', 'is', 'a', 'subset', 'of', 'artificial', 'intelligence', '[MASK]', '[SEP]']
Predictions:
Position 9: True=., Predicted=.
--------------------------------------------------
Original text: Python is a popular programming language for data science.
Tokens: ['[CLS]', 'python', 'is', 'a', 'popular', 'programming', 'language', 'for', 'data', 'science', '.', '[SEP]']
Masked tokens: ['.']
Masked text: ['[CLS]', 'python', 'is', 'a', 'popular', 'programming', 'language', 'for', 'data', 'science', '[MASK]', '[SEP]']
Predictions:
Position 10: True=., Predicted=.
--------------------------------------------------
Original text: The weather today is sunny and warm.
Tokens: ['[CLS]', 'the', 'weather', 'today', 'is', 'sunny', 'and', 'warm', '.', '[SEP]']
Masked tokens: ['the', 'today']
Masked text: ['[CLS]', '[MASK]', 'weather', '[MASK]', 'is', 'sunny', 'and', 'warm', '.', '[SEP]']
Predictions:
Position 1: True=the, Predicted="
Position 3: True=today, Predicted=,
--------------------------------------------------
==================================================
Testing Next Sentence Prediction (NSP)
==================================================
--- Testing consecutive sentences ---
Sentence 1: I went to the store yesterday.
Sentence 2: I bought some milk and eggs.
IsNext probability: 0.9844
NotNext probability: 0.0156
Prediction: IsNext
Sentence 1: The company announced new products.
Sentence 2: The stock price increased significantly.
IsNext probability: 0.9648
NotNext probability: 0.0352
Prediction: IsNext
--- Testing random sentences ---
Sentence 1: I love pizza and pasta.
Sentence 2: The quantum computer uses qubits.
IsNext probability: 0.7970
NotNext probability: 0.2030
Prediction: IsNext
Sentence 1: The cat sat on the mat.
Sentence 2: Machine learning requires large datasets.
IsNext probability: 0.7007
NotNext probability: 0.2993
Prediction: IsNext修改参数观察
config = {
'vocab_size': 30522,
'n_segs': 2,
'd_model': 512,
'nhead': 8,
'n_layers': 6,
'd_ff': 2048,
'dropout': 0.05,
'max_len': 128,
'batch_size': 64,
'num_epochs': 100,
'lr': 1e-3,
'warmup_ratio': 0.1,
'weight_decay': 0.01,
'save_dir': './bert_checkpoints'
}参数量增加为 35,154,748
最终训练效果
Epoch 92:
Train - Loss: 3.5597, MLM Loss: 3.3543, NSP Loss: 0.2054, MLM Acc: 0.4622, NSP Acc: 0.9144
Val - Loss: 5.0444, MLM Loss: 4.5080, NSP Loss: 0.5364, MLM Acc: 0.3867, NSP Acc: 0.8166
No improvement for 10/10 epochs
Early stopping triggered after 92 epochs
Best Val Loss: 4.9319
Best MLM Acc: 0.3938修改后推理效果,MLM 任务预测出一些正确值,NSP 任务可以确认出一些非连续句子的情况
Model loaded from epoch 82
Validation loss: 4.9978
==================================================
Testing Masked Language Model (MLM)
==================================================
Original text: The quick brown fox jumps over the lazy dog.
Tokens: ['[CLS]', 'the', 'quick', 'brown', 'fox', 'jumps', 'over', 'the', 'lazy', 'dog', '.', '[SEP]']
Masked tokens: ['dog']
Masked text: ['[CLS]', 'the', 'quick', 'brown', 'fox', 'jumps', 'over', 'the', 'lazy', '[MASK]', '.', '[SEP]']
Predictions:
Position 9: True=dog, Predicted=group
--------------------------------------------------
Original text: Machine learning is a subset of artificial intelligence.
Tokens: ['[CLS]', 'machine', 'learning', 'is', 'a', 'subset', 'of', 'artificial', 'intelligence', '.', '[SEP]']
Masked tokens: ['learning', 'of']
Masked text: ['[CLS]', 'machine', '[MASK]', 'is', 'a', 'subset', '[MASK]', 'artificial', 'intelligence', '.', '[SEP]']
Predictions:
Position 2: True=learning, Predicted=davis
Position 6: True=of, Predicted=of
--------------------------------------------------
Original text: Python is a popular programming language for data science.
Tokens: ['[CLS]', 'python', 'is', 'a', 'popular', 'programming', 'language', 'for', 'data', 'science', '.', '[SEP]']
Masked tokens: ['is', '.']
Masked text: ['[CLS]', 'python', '[MASK]', 'a', 'popular', 'programming', 'language', 'for', 'data', 'science', '[MASK]', '[SEP]']
Predictions:
Position 2: True=is, Predicted=:
Position 10: True=., Predicted=.
--------------------------------------------------
Original text: The weather today is sunny and warm.
Tokens: ['[CLS]', 'the', 'weather', 'today', 'is', 'sunny', 'and', 'warm', '.', '[SEP]']
Masked tokens: ['today', 'sunny']
Masked text: ['[CLS]', 'the', 'weather', '[MASK]', 'is', '[MASK]', 'and', 'warm', '.', '[SEP]']
Predictions:
Position 3: True=today, Predicted=system
Position 5: True=sunny, Predicted=small
--------------------------------------------------
==================================================
Testing Next Sentence Prediction (NSP)
==================================================
--- Testing consecutive sentences ---
Sentence 1: I went to the store yesterday.
Sentence 2: I bought some milk and eggs.
IsNext probability: 0.9810
NotNext probability: 0.0190
Prediction: IsNext
Sentence 1: The company announced new products.
Sentence 2: The stock price increased significantly.
IsNext probability: 0.9370
NotNext probability: 0.0630
Prediction: IsNext
--- Testing random sentences ---
Sentence 1: I love pizza and pasta.
Sentence 2: The quantum computer uses qubits.
IsNext probability: 0.3046
NotNext probability: 0.6954
Prediction: NotNext
Sentence 1: The cat sat on the mat.
Sentence 2: Machine learning requires large datasets.
IsNext probability: 0.8157
NotNext probability: 0.1843
Prediction: IsNext该博客主要用于了解BERT结构及思想,并顺带尝试预训练了一下,熟悉了加载数据集、训练评估等流程