计算机视觉
概念
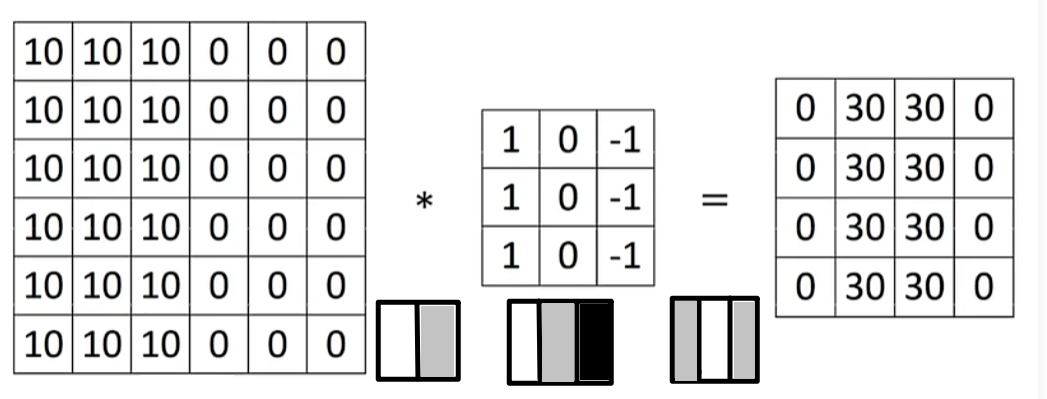
垂直边缘检测
- 灰度图
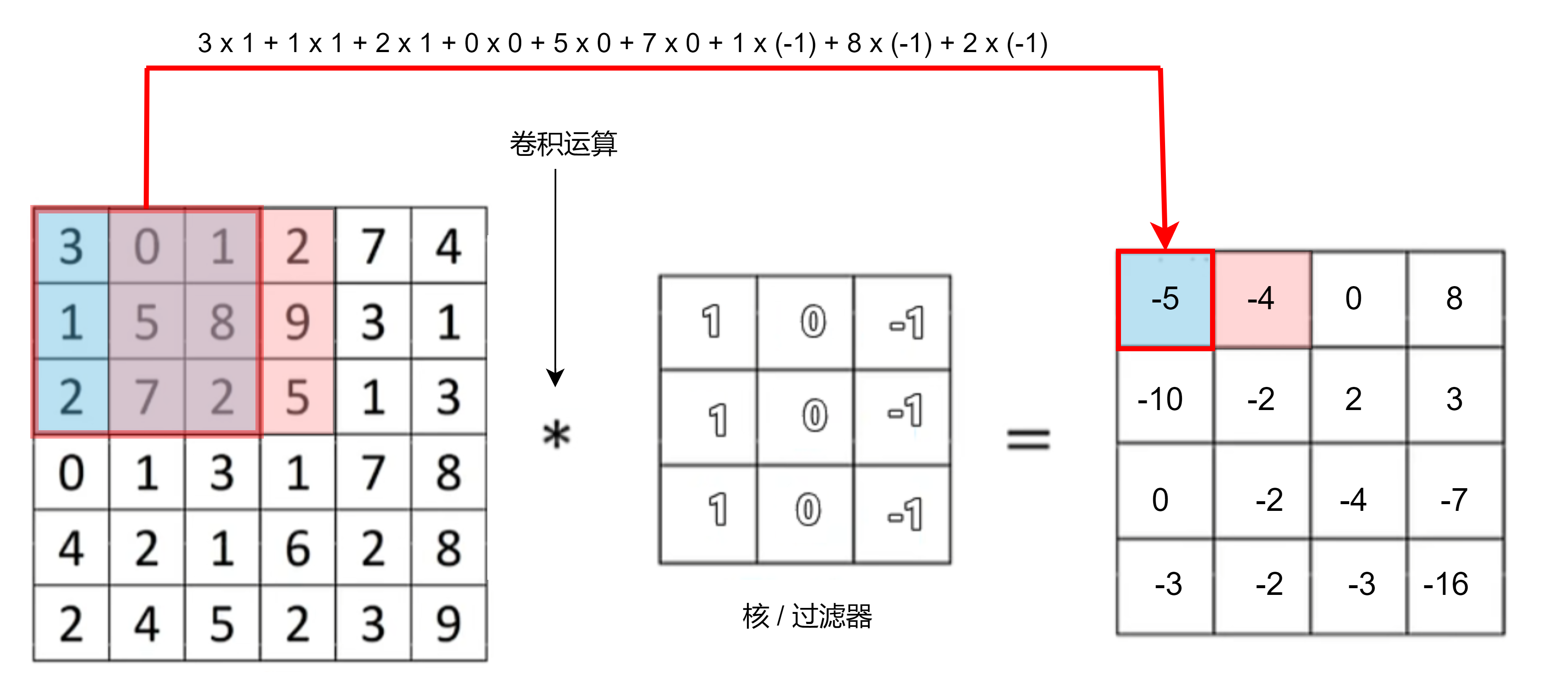
N x N * f x f = ( N - f + 1 ) * ( N - f + 1),f 基本为奇数
滤波器/卷积核
Sobel过滤器:强调方向,垂直方向,中间权重为2
[-1, 0, 1]
[-2, 0, 2]
[-1, 0, 1]Scharr过滤器:更平滑
[-3, 0, 3]
[-10, 0, 10]
[-3, 0, 3]padding填充
为了让卷积不会减少图像尺寸,或者保留边缘信息,会对输入图像四周进行填充
p=1时在矩阵外围每边填充一圈0- (N + 2p) x (N + 2p) * f x f = ( N + 2p - f + 1 ) * ( N + 2p - f + 1)
卷积模式
Same:填充使卷积运算后矩阵大小保持不变
Valid:不进行填充,图像变小
stride步长
- 过滤器每次计算后向上向下移动到新位置的长度均为步长,步长越大使得卷积结果矩阵大小越小
- 输出:$( \lfloor\frac{N + 2p - f}{s} + 1 \rfloor) * ( \lfloor\frac{N + 2p - f}{s} + 1\rfloor)$
1x1卷积
- 作用:降维(减少通道数),增加非线性
- 举例:
- 输入:$28 \times 28 \times 192$
- 使用 32 个 $1 \times 1 \times 192$ 卷积核 → 每个核输出一个通道
- 输出:$28 \times 28 \times 32$
三维卷积
通道 = 深度

卷积神经网络
- 常用于图像数据处理
- 输入: 一个图像(可能有多个通道,如 RGB)
- 输出: 多个特征图,每个对应一个卷积核
一层架构
2 个过滤器即 2 个特征,每个卷积核学会从图像中提取某种类型的特征

多层架构:
经过多个卷积核,最终展开输入Softmax单元或Logistic回归
第一层卷积提取基础特征(如边缘)
第二层卷积提取更复杂结构(如形状)
…
最后几层展开(flatten)后送入全连接层(FC)+ Softmax做分类
参数
例如使用 10 个 $3 \times 3 \times 3$ 的卷积核:
- 每个卷积核:$3 \times 3 \times 3 = 27$ 个权重
- 每个核再加 1 个偏置:总共 28 个参数
- 10 个核 → $10 \times (27 + 1) = 280$ 个参数
卷积核共享权重,使得参数数量远少于全连接网络,不易过拟合
层类型
- 卷积层(Convolution, CONV)
- 池化层(Pooling, POOL):下采样(downsampling),减少数据量和计算复杂度,增强特征稳定性
- 全连接层(Fully connected, FC)
最大池化层(max pooling)
最大值采样:f=2,输出对应区域最大值,若在滤波器中任何地方检测到了特征,保留最大值

平均池化层(average pooling)
均值采样:f=2

池化层没有需要学习的参数,只需设置过滤器大小f,步长s
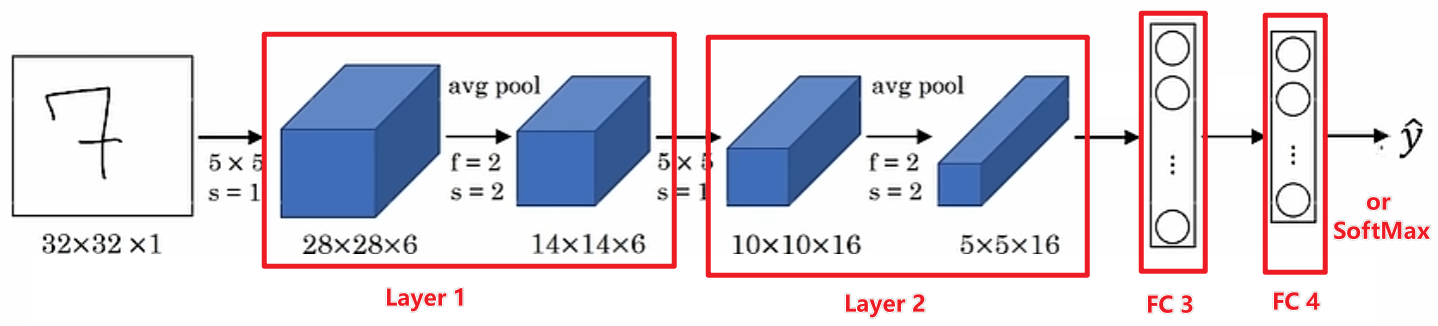
经典架构
LeNet-5
AlexNet

VGG-16
结构简单,更关注卷积层,有16层带权重的层

卷积残差网络
- 传统CNN问题
- 梯度爆炸:深层网络,前面层难以有效更新
- 准确率下降:深层模型表现变差
- conv residual network, ResNet,利用跳跃连接(skip connection),解决梯度爆炸和消失
思路:引入残差模块,将输入x绕过卷积层,加到输出中,$y=F(x)+x$

残差神经网络ResNet

初始网络
- Inception network,做多次并行卷积提取不同尺寸的特征后,将结果拼接

计算成本高:计算成本=卷积核的3个参数 x 卷积核所可移动的位置数 x 卷积核数量
- 使用1x1卷积先减少通道数/维度化为瓶颈层(bottleneck layer),即降维
- 再进行大的卷积核操作,再升维
- 以此降低计算成本
单模块
重复多次使用该单模块

MobileNets
深度可分离卷积(depthwise-separable convolutions)
标准卷积(以 3x3x3 输入为例):
- 每个输出通道都由所有输入通道共同参与计算
- 成本:
3×3×输入通道数×输出通道数×空间位置数
深度可分离卷积 = Depthwise + Pointwise:
- Depthwise convolution
- 每个输入通道单独做卷积(不融合通道)
- 成本显著减少:每通道单独计算
- Pointwise convolution(即 1×1 卷积)
- 用于将 depthwise 的输出整合成目标输出通道数
- 相当于通道混合
- 成本计算为:3x3x4x4x3 + 1x1x3x4x4x5 远小于一般卷积成本

从D × D × M × N × H × W(标准卷积)降为: D × D × M × H × W + 1 × 1 × M × N × H × W
架构

解决内存过小的问题,将输入值投射到较小的数据集
目标检测
目标定位
希望预测一个物体的位置和种类,$y$ 表示预测结果
- $p_c$:是否存在对象的概率
- $b_x, b_y$:边界框中心点的横纵坐标
- $b_h, b_w$:边界框的高和宽,可大于1
- $c_1,c_2,c_3$:对象种类
地标检测(Landmark detection)
全连接层转换为卷积层,识别物体上关键点位置

滑动窗口检测(sliding Windows Detection)
- 图像上滑动一个固定大小窗口检测目标,每个窗口都经过CNN分类器处理
- 计算量大,将滑动窗口和卷积操作合并成一个前向传播运算,共享运算,提升效率

YOLO
- You only look once
- 将图像一次性划分
S x S的网格,每个网格检测其中是否存在物体
1️⃣ 边界框预测
$b_x, b_y, b_h, b_w$中:前两个只能小于1,后两个可大于1
2️⃣ 交并比(Intersection over union)
评估预测框与真实框的重叠程度
$$IoU=\frac{预测框 \cap 真实框}{预测框\cup真实框}$$
若大于阈值0.5(可调)认为预测正确
3️⃣ 非极大值抑制
保证对每个对象只得到一个检测,选择最大可能性的边框,抑制其余邻近边框
4️⃣ 锚框(anchor box)
一个网格单元检测多个目标,将输出 y 向量叠加一倍,维度翻倍,分别描述不同目标
语义分割
Semantic Segmentation,对图像中每个像素进行分类
转置卷积(Transpose Convolution)
重叠部分叠加相加,padding为1(填充边界),stride为2(扩展图像尺寸)
灰色部分不填充,最终将2x2扩展为4x4

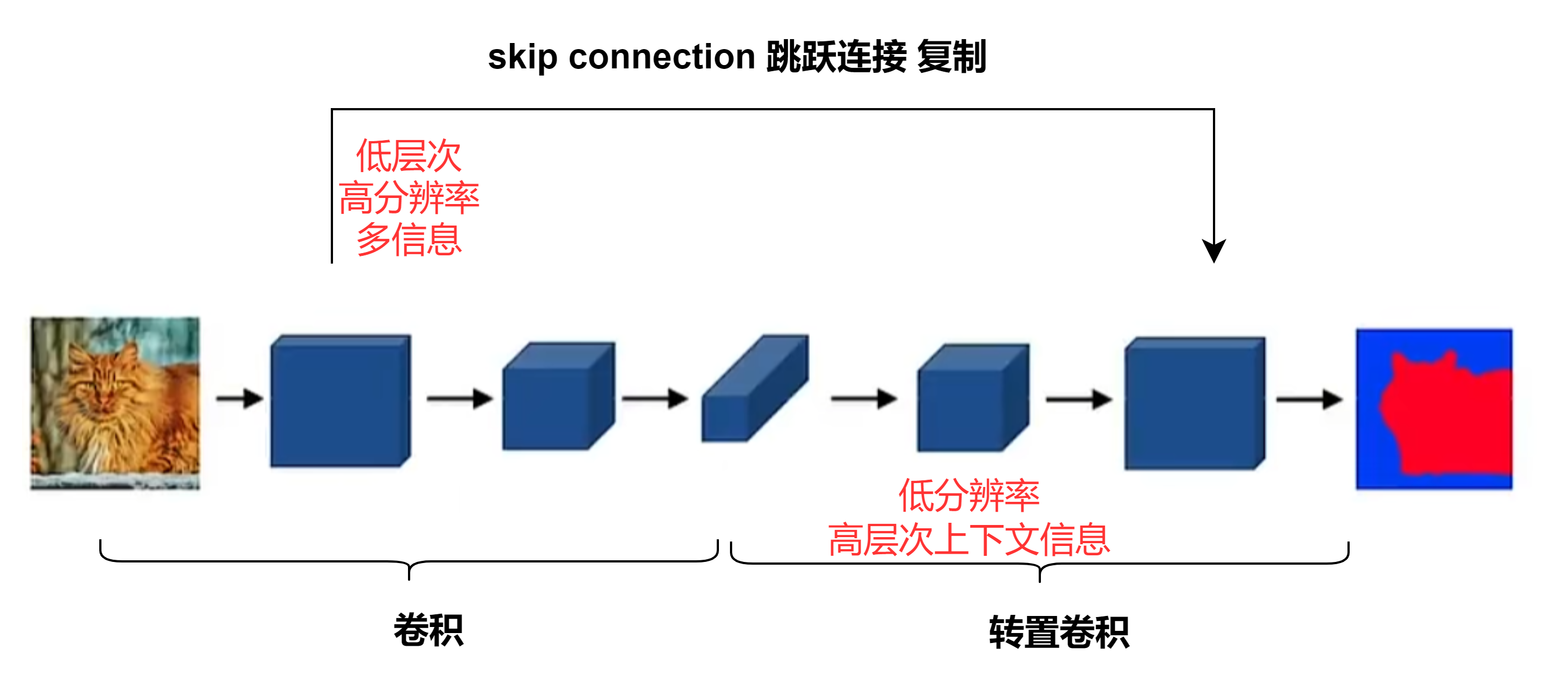
U-Net
- 编码器:提取图像特征
- 解码器:逐步恢复图像尺寸
- Skip connections:连接对称层,增强高分辨率细节

人脸识别
目标:同一个人识别为同一个人
One-shot learning,单样本学习:在只有一个样本情况下就能识别新人物
相似方程:d(img1, img2) = 图像差异度 与 $\tau$ 比较
孪生网络(Siamese network)
用相同卷积网络(共享参数)对不同图片处理,对比图像特征
距离函数:$d(x^{(1)},x^{(2)})=||f(x^{(1)})-f(x^{(2)})||^2_2$
值越小越可能是同一人

三元组损失(Triplet loss)
三个输入:Anchor(A)、Positive(P, 同一个人)、Negative(N, 不同人)
损失函数:$L(A,P,N)=\max(||f(A)-f(P)||^2- ||f(A)-f(N)||^2+\alpha,0)$
$\alpha$表示margin,容差边界,确保 A 更接近 P 而远离 N
代价函数:$J=\sum_{i=1}^mL(A^{(i)},P^{(i)},N^{(i)})$
也可使用二分类逻辑回归,看两图片是否返回1或0分别表示相同或不同
神经风格迁移
目标:生成图像G(Generated image),内容像C(Content),风格像S(Style)
代价函数:$J(G)=\alpha J_{Content}(C,G)+\beta J_{Style}(S,G)$
1️⃣ 内容代价函数
内容损失为特征差异
$J_{Content}(C,G)=\frac{1}{2}||a^{[l][C]}-a^{[l][G]}||^2$,a 为激活因子,在 l 层
2️⃣ 风格代价函数
风格矩阵/gram matrix
$a_{i,j,k}^{[l]}$:表示高 i 宽 j 通道 k 的激活因子
$G^{[l]}:,,n_c^{[l]}\times n_c^{[l]}$:记录每一对通道间的相关性
$G_{kk’}^{[l](S)}=\sum_{i=1}^{n_H^{[l]}}\sum_{j=1}^{n_W^{[l]}}a_{ijk}^{[l](S)}a_{ijk’}^{[l](S)},\quad\quad k=1,\cdots ,n_c^{[l]}$
$G_{kk’}^{[l](G)}=\sum_{i=1}^{n_H^{[l]}}\sum_{j=1}^{n_W^{[l]}}a_{ijk}^{[l](G)}a_{ijk’}^{[l](G)},\quad\quad k=1,\cdots ,n_c^{[l]}$
风格损失为:
$J_{Style}^{[l]}(S,G)=\frac{1}{(\cdots)}||G^{[l][S]}-G^{[l][G]}||_F^2$

总风格代价函数
$J_{Style}(S,G)=\sum_l \lambda^{[l]}J_{Style}^{[l]}(S,G)$
更新生成图像
梯度下降优化:$G=G-\frac{\alpha}{2G}\triangledown J(G)$