Transformer复现学习
Transformer复现学习
- 2017 年 《Attention is All You Need》
- 参考博客学习
词嵌入
词元 token 转换为计算机能理解的词嵌入 word embedding,即 token 映射到词向量空间中
- 统计机器学习时代:无法反映词语之间语义关联
- 独热编码:n 个不同取值的特征,n 长的二进制向量,只有一位为1
- 词袋:构建词汇表,且对每个词统计词频,词频值列表即为词袋
- Word2Vec:token 映射为向量,在多维空间语义相近的词向量,方向也相近,多维包含对语义、词性等的关系(单独训练一个词嵌入模型),token 语义、词性等越接近,词向量在向量空间越接近,点积越大
- Transformer:词嵌入模型和语言模型一起训练
每个 token 映射到维度为 d 的向量空间——词嵌入,即长为 d 的向量表示
长度为 S 的序列,即有 S 个 token,转换为词嵌入后映射为 S*d 的矩阵 E
词嵌入矩阵 W 用于将 S 个 token 找到其对应的向量转换为 E,W 是可学习的参数
位置编码
自注意力的 Q,K,V 三个矩阵都由同一个输入 X 线性转换而来,而若 X 序列顺序打乱后再加权求和来计算注意力分数,得到的值是一样的,即丢失了 X 的序列顺序信息,所以需要位置信息
- transformer 采用静态正余弦位置编码:奇数位用余弦,偶数位用正弦,维度与词嵌入向量一样,为序列中的每个位置生成一个独特的向量表示
- E_pos 表示位置编码矩阵,静态不变
- PE(pos, i) 表示 E_pos 中第 pos 个位置第 i 个维度的值
- pos 表示 token 在原序列中的位置索引
- i 表示向量维度的索引
- d 表示词向量的总维度
$$ PE(pos, 2i)=sin(\frac{pos}{10000^{2i/d_{model}}}) $$
$$ PE(pos, 2i+1)=cos(\frac{pos}{10000^{2i/d_{model}}}) $$
- 后续大模型采用旋转位置编码
隐藏状态
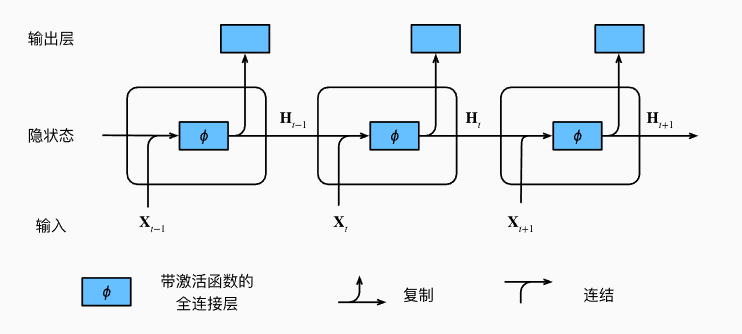
隐藏状态:RNN 在处理输入序列时用于存储和传递信息的内部状态,在每个时间步更新,捕捉输入序列中的信息和上下文关系
$$ h_t = f(h_{t-1}, x_t) $$
- h_t:时间步 t 的隐藏状态,h_0 初始化为零向量
- x_t:时间步 t 的输入
- f:非线性函数,通常由神经网络层实现
# 包导入
import torch
import torch.nn as nn
import torch.nn.functional as FRNN
循环神经网络 RNN: 跟多层感知机 MLP 的区别在于加入了循环层和隐藏状态
$$ H_t = f(UX_t + WH_{t-1}) $$
$$ O_t = g(VH_t) $$
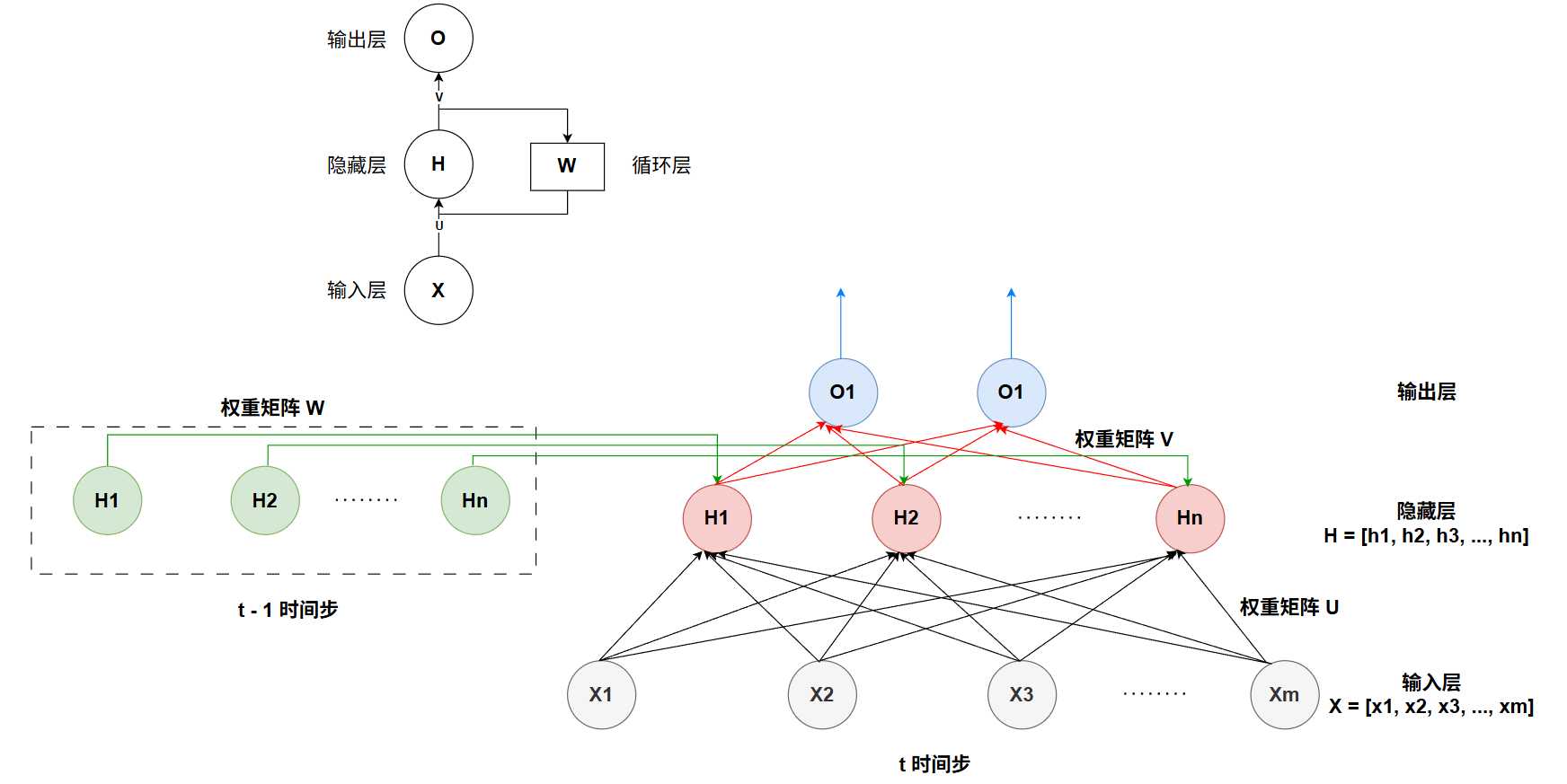
如下图所示,X_t 为在时间步 t 的 [n, d] 矩阵,n 个长为 d 的序列样本,H_t 为在时间步 t 的 [n, h] 矩阵,n 个 h 维隐藏状态
简易实现 RNN(未包含将输入字符转换为 Embedding 的操作)
class RNN(nn.Module):
def __init__(self, input_size, hidden_size, output_size):
"""
input_size: 输入维度
hidden_size: 隐藏状态维度
output_size: 输出维度
"""
super().__init__()
self.hidden_size = hidden_size
# 权重矩阵
self.W_xh = nn.Linear(input_size, hidden_size) # U
self.W_hh = nn.Linear(hidden_size, hidden_size) # W
self.W_hy = nn.Linear(hidden_size, output_size) # V
def forward(self, x, hidden=None):
"""
x: [batch_size, seq_len, embd_size]
batch_size 个样本, 每个样本序列 seq_len 个词元, 每个词元映射为 embd_size 长的嵌入向量, 也称作特征维度
"""
batch_size = x.size(0)
seq_len = x.size(1)
# 初始化隐藏状态为全 0 [batch_size, hidden_size]
if hidden is None:
hidden = torch.zeros(batch_size, self.hidden_size, device=x.device)
# 存储每个时间步的输出
outputs = []
for t in range(seq_len):
x_t = x[:, t, :] # 当前时间步的输入 [batch_size, embd_size]
hidden_t = torch.tanh(
self.W_xh(x_t) + # 当前输入影响 [batch_size, hidden_size]
self.W_hh(hidden) # 历史信息影响 [batch_size, hidden_size]
)
y_t = self.W_hy(hidden_t) # 输出 [batch_size, output_size]
hidden = hidden_t # 更新隐藏状态,用于下一个时间步
outputs.append(y_t.unsqueeze(1)) # 增加时间步维度 [batch_size, seq_len, output_size]
# 将所有时间步的输出拼接起来
outputs = torch.cat(outputs, dim=1) # [batch_size, seq_len, output_size]
return outputs, hiddenLSTM
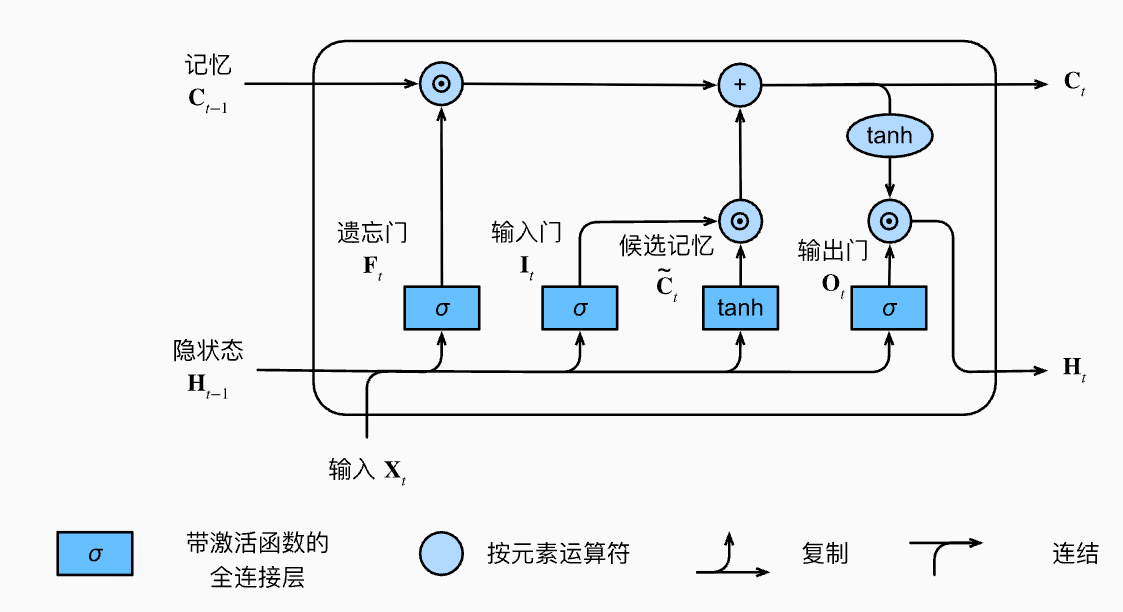
理解 LSTM
遗忘门:值朝0减少
输入门:决定是否忽略掉输入数据
输出门:决定是否使用隐藏状态
$$ F_t=\sigma(X_tW_{xf}+H_{t-1}W_{hf}+b_f) $$
$$ I_t = \sigma(X_tW_{xi} + H_{t-1}W_{hi} + b_i) $$
$$ O_t=\sigma(X_tW_{xo}+H_{t-1}W_{ho}+b_o) $$
候选记忆单元:类似 RNN 中计算 H(也有称为候选记忆细胞的)
$$ \tilde C_t=\tanh(X_tW_{xc}+H_{t-1}W_{hc}+b_c) $$
记忆单元(细胞状态,长期记忆):遗忘部分旧记忆,添加部分新记忆
- 若 F 为 1 则把过去的记忆单元忽略,若 F 为 0 则包含过去的记忆单元
- 若 I 为 1 则把当前候选记忆单元忽略,若 I 为 0 则包含当前候选记忆单元
- 导致最终范围无法保证在 -1 和 1 之间
$$ C_t = F_t\odot C_{t-1} + I_t\odot \tilde C_t $$
隐藏状态(短期记忆):
- tanh 将值重新变到 -1 和 1 之间
- 若 O 为 1 则把当前记忆单元忽略,重置状态
- 若 O 为 1 则包含当前候选记忆单元
$$ H_t = O_t\odot \tanh(C_t) $$
简易实现 LSTM(未包含将输入字符转换为 Embedding 的操作)
class LSTM(nn.Module):
def __init__(self, input_size, hidden_size, output_size):
"""
input_size: 输入维度
hidden_size: 隐藏状态维度
output_size: 输出维度
"""
super().__init__()
self.hidden_size = hidden_size
self.W_xf = nn.Linear(input_size, hidden_size) # 遗忘门输入权重
self.W_hf = nn.Linear(hidden_size, hidden_size) # 遗忘门隐藏权重
self.b_f = nn.Parameter(torch.zeros(hidden_size)) # 遗忘门偏置
self.W_xi = nn.Linear(input_size, hidden_size) # 输入门输入权重
self.W_hi = nn.Linear(hidden_size, hidden_size) # 输入门隐藏权重
self.b_i = nn.Parameter(torch.zeros(hidden_size)) # 输入门偏置
self.W_xo = nn.Linear(input_size, hidden_size) # 输出门输入权重
self.W_ho = nn.Linear(hidden_size, hidden_size) # 输出门隐藏权重
self.b_o = nn.Parameter(torch.zeros(hidden_size)) # 输出门偏置
self.W_xc = nn.Linear(input_size, hidden_size) # 候选记忆单元输入权重
self.W_hc = nn.Linear(hidden_size, hidden_size) # 候选记忆单元隐藏权重
self.b_c = nn.Parameter(torch.zeros(hidden_size)) # 候选记忆单元偏置
# 输出层
self.W_hy = nn.Linear(hidden_size, output_size)
def forward(self, x, hidden_state=None):
"""
x: [batch_size, seq_len, embd_size]
hidden_state: 元组 (hidden, cell_state)
hidden: [batch_size, hidden_size] 隐藏状态
cell_state: [batch_size, hidden_size] 细胞状态
"""
batch_size = x.size(0)
seq_len = x.size(1)
# 初始化隐藏状态和细胞状态为全0
if hidden_state is None:
hidden = torch.zeros(batch_size, self.hidden_size, device=x.device)
cell_state = torch.zeros(batch_size, self.hidden_size, device=x.device)
else:
hidden, cell_state = hidden_state
outputs = []
for t in range(seq_len):
x_t = x[:, t, :] # 当前时间步的输入 [batch_size, embd_size]
# [batch_size, hidden_size]
f_t = torch.sigmoid(self.W_xf(x_t) + self.W_hf(hidden) + self.b_f) # 遗忘门
i_t = torch.sigmoid(self.W_xi(x_t) + self.W_hi(hidden) + self.b_i) # 输入门
o_t = torch.sigmoid(self.W_xo(x_t) + self.W_ho(hidden) + self.b_o) # 输出门
c_tilde = torch.tanh(self.W_xc(x_t) + self.W_hc(hidden) + self.b_c) # 候选记忆细胞
cell_state = f_t * cell_state + i_t * c_tilde # 细胞状态 每一层
hidden = o_t * torch.tanh(cell_state) # 隐藏状态 每一层
y_t = self.W_hy(hidden) # [batch_size, output_size]
outputs.append(y_t.unsqueeze(1))
outputs = torch.cat(outputs, dim=1) # 所有: [batch_size, seq_len, output_size]
return outputs, (hidden, cell_state)注意力机制
Seq2Seq
一种框架,可解决机器翻译和语音识别等任务
- 传统 RNN 以及 LSTM 可以在每一时刻对应一个输入,生成一个输出,当其处理 Seq2Seq 问题时,只能生成与输入序列相同长度的输出,或少于输入序列
- 翻译任务重输入输出可能不一样,导致了 Encoder-Decoder 架构出现,端到端学习算法
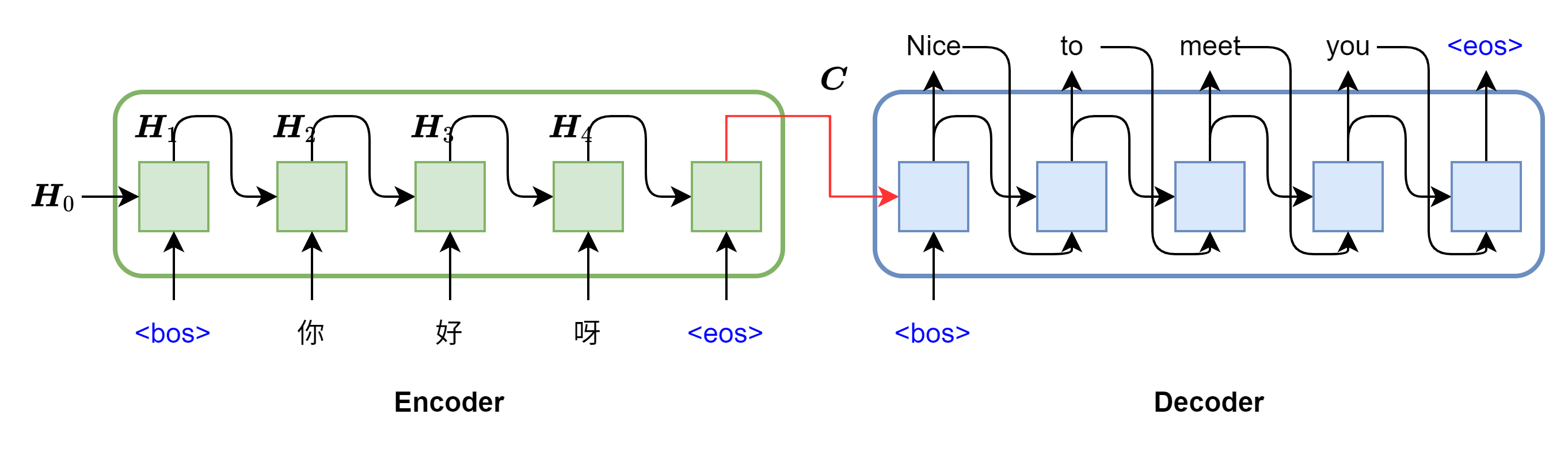
- 包含编码器、中间向量、解码器
- 缺陷:无论输入输出长度是啥,中间向量 c 都被压缩到固定长度向量中
- 语义向量无法完全表示整个序列信息 + 先输入内容信息会被后输入内容信息覆盖掉
# 包导入
import random
import torch
import torch.nn as nn编码器
理解和总结待翻译的不定长序列,经过 RNN 的最后一个时间步的隐藏层输出,作为中间向量 C
- 加入了 Embedding 过程:将中文原句子序列和英文目标句子序列分词得到 token,加入句子开头结尾的 token,映射到高维词向量空间
- 归纳为向量输入给解码器作为上文的参考,编码器输出的中间状态向量 C 实际指最后一层的隐藏状态和细胞状态
class Encoder(nn.Module):
def __init__(self, input_dim, emb_dim, hid_dim, n_layers, dropout):
"""
input_dim: 输入词汇表大小 vocab_size
emb_dim: 词嵌入维度
hid_dim: 隐藏层维度: 即 h_t, c_t 第 t 时间步的隐藏状态和细胞状态的维度
n_layers: LSTM层数
dropout: 丢弃概率
"""
super(Encoder, self).__init__()
self.hid_dim = hid_dim
self.n_layers = n_layers
# input_dim: 输入特征维度, emb_dim: 词向量维度
self.embedding = nn.Embedding(input_dim, emb_dim)
self.rnn = nn.LSTM(emb_dim, hid_dim, n_layers, dropout=dropout)
self.dropout = nn.Dropout(dropout)
def forward(self, src):
embedded = self.dropout(self.embedding(src))
outputs, (hidden, cell) = self.rnn(embedded)
return hidden, cellforward 过程
- src:[seq_len, batch_size],batch_size 个样本, 每个样本 seq_len 个词
- 第一个词为
token,最后一个词为 token,并进行了填充
# 此时 4 批量处理, 每个样本 7 个词
src = torch.tensor([
[2, 2, 2, 2],
[4, 4, 4, 4],
[93, 69, 589, 86],
[21, 23, 12, 32],
[34, 1, 90, 1],
[1, 1, 19, 1],
[1, 1, 1, 1]
])- 经过 Embedding & Dropout 实际是将每一个 token 值都扩充为一个维度为 emb_dim 的向量,所以与 batch_size 和 seq_len 的先后顺序无关,可以为 [batch_size, seq_len] 也可为 [seq_len, batch_size]
embedded: [seq_len, batch_size, emb_dim]- 经过 LSTM 层,逐时间步处理:t = 0, 1, …, 6,每个时间步输入是 [batch_size, emb_dim]
- 单向LSTM:
n_directions=1 - outputs 表示最后一层、所有时间步、所有批量的 h_t,cell 和 hidden 表示所有层、最后一个时间步、所有批量的 h_t,cell 表示所有层、最后一个时间步、所有批量的 c_t
outputs = [seq_len, batch_size, hid_dim * n_directions]
# outputs[-1, :, :] 最后一个时间步的输出
hidden(ht) = [n_layers * n_directions, batch_size, hid_dim]
# hidden[0, :, :] 第一层的最后隐藏状态
cell(ct) = [n_layers * n_directions, batch_size, hid_dim]解码器
根据上文的语义信息进行推理预测,以<bos> 开头,经过上文提示,第一个时间步预测出 “Nice”,将 “Nice” 的词向量和当前时间步的隐藏层输出作为下一个时间步的输入
class Decoder(nn.Module):
def __init__(self, output_dim, emb_dim, hid_dim, n_layers, dropout):
super(Decoder, self).__init__()
self.output_dim = output_dim # 输出词汇表大小
self.hid_dim = hid_dim
self.n_layers = n_layers
self.embedding = nn.Embedding(output_dim, emb_dim)
self.rnn = nn.LSTM(emb_dim, hid_dim, n_layers, dropout=dropout)
self.fc_out = nn.Linear(hid_dim, output_dim)
self.dropout = nn.Dropout(dropout)
def forward(self, input, hidden, cell):
"""
input: [batch_size]
hidden: [n_layers * n_directions, batch_size, hid_dim] -> [n_layers, batch_size, hid_dim]
cell: [n_layers * n_directions, batch_size, hid_dim] -> [n_layers, batch_size, hid_dim]
"""
# input = [1, batch size]
input = input.unsqueeze(0) # [1, batch_size]
embedded = self.dropout(self.embedding(input)) # [1, batc_size, emb_dim]
# output: [seq_len, batch_size, hid_dim * n_directions] -> [1, batch_size, hid_dim]
# hidden: [n_layers * n_directions, batch_size, hid_dim] -> [n_layers, batch_size, hid_dim]
# cell: [n_layers * n_directions, batch_size, hid_dim] -> [n_layers, batch_size, hid_dim]
output, (hidden, cell) = self.rnn(embedded, (hidden, cell))
prediction = self.fc_out(output.squeeze(0)) # [batch_size, output_dim]
return prediction, hidden, cellSeq2Seq 框架实现
class Seq2Seq(nn.Module):
def __init__(self, encoder, decoder, device):
super(Seq2Seq, self).__init__()
self.encoder = encoder
self.decoder = decoder
self.device = device
assert encoder.hid_dim == decoder.hid_dim, "编码器和解码器的隐藏维度必须相等!"
assert encoder.n_layers == decoder.n_layers, "编码器和解码器必须有相同层数!"
def forward(self, src, trg, teacher_forcing_ratio=0.5):
"""
src = [src_len, batch_size] 源语言序列
trg = [trg_len, batch_size] 目标语言序列
teacher_forcing_ratio: 训练过程中的每个时刻,有一定概率使用上一时刻的输出作为输入,也有一定概率使用正确的 target 作为输入
"""
batch_size = trg.shape[1]
trg_len = trg.shape[0]
trg_vocab_size = self.decoder.output_dim # 输出词汇表大小
# 初始化输出张量,用于存储每个时间步的预测结果
outputs = torch.zeros(trg_len, batch_size, trg_vocab_size).to(self.device)
# encoder 模块
hidden, cell = self.encoder(src)
# decoder 模块的第一个输入 token 是序列开始标记: <bos>
input = trg[0, :]
for t in range(1, trg_len):
output, hidden, cell = self.decoder(input, hidden, cell)
outputs[t] = output # 预测结果
teacher_force = random.random() < teacher_forcing_ratio
# 获取预测中概率最高的 token
top1 = output.argmax(1)
# 决定输入是根据预测得到的(预测可能是错误的),还是真实值(起纠偏作用)
input = trg[t] if teacher_force else top1
return outputs尝试训练
- S 用于开头,E 用于结尾,P 用于填充
- 数据集获取
def make_batch(seq_data, n_step, num_dic):
"""
创建训练批次数据 seq_data: [batch_size, 2]
"""
input_batch, output_batch, target_batch = [], [], []
for seq in seq_data:
src_word = seq[0] + 'P' * (n_step - len(seq[0]))
trg_word = seq[1] + 'P' * (n_step - len(seq[1]))
# 实际此处命名为 output 不合适
input_idx = [num_dic[n] for n in src_word] # Encoder 输入源序列索引
output_idx = [num_dic[n] for n in ('S' + trg_word)] # Decoder 输入序列索引(加S)
target_idx = [num_dic[n] for n in (trg_word + 'E')] # Decoder 目标序列索引(加E)
input_batch.append(input_idx)
output_batch.append(output_idx)
target_batch.append(target_idx)
input_tensor = torch.LongTensor(input_batch).t() # [seq_len, batch_size]
output_tensor = torch.LongTensor(output_batch).t() # [seq_len+1, batch_size]
target_tensor = torch.LongTensor(target_batch).t() # [seq_len+1, batch_size]
return input_tensor, output_tensor, target_tensor
def make_testbatch(input_word, n_step, num_dic):
"""创建测试批次数据"""
# 填充输入
input_w = input_word + 'P' * (n_step - len(input_word))
input_idx = [num_dic[n] for n in input_w]
output_idx = [num_dic[n] for n in ('S' + 'P' * n_step)] # 初始化为 SPPPP, 只需要第一个为 S
# 转换为索引
input_batch = torch.LongTensor([input_idx]).t() # [seq_len, 1]
output_batch = torch.LongTensor([output_idx]).t() # [seq_len+1, 1]
return input_batch, output_batch训练过程
if __name__ == '__main__':
n_step = 8 # 序列最大长度, 不够则使用 padding, 单词数
hidden_dim = 128 # 隐藏层维度
emb_dim = 32 # 词向量维度
dropout = 0.0 # LSTM 一层不使用 dropout
char_arr = [c for c in 'SEPabcdefghijklmnopqrstuvwxyz']
num_dic = {n: i for i, n in enumerate(char_arr)}
n_class = len(num_dic) # 词汇表大小
# 训练数据
seq_data = [
['man', 'woman'],
['black', 'white'],
['king', 'queen'],
['girl', 'boy'],
['up', 'down'],
['high', 'low'],
['men', 'women'],
['you', 'me']
]
batch_size = len(seq_data) # 样本数量
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
encoder = Encoder(n_class, emb_dim, hidden_dim, n_layers=1, dropout=dropout)
decoder = Decoder(n_class, emb_dim, hidden_dim, n_layers=1, dropout=dropout)
model = Seq2Seq(encoder, decoder, device).to(device)
# 损失函数和优化器
criterion = nn.CrossEntropyLoss(ignore_index=num_dic['P'])
optimizer = optim.Adam(model.parameters(), lr=0.001)
# 准备训练数据
input_batch, output_batch, target_batch = make_batch(seq_data, n_step, num_dic)
input_batch = input_batch.to(device)
output_batch = output_batch.to(device)
target_batch = target_batch.to(device)
for epoch in range(5000):
optimizer.zero_grad()
outputs = model(input_batch, output_batch) # [trg_len, batch_size, vocab_size]
# 计算损失: 跳过第一个时间步
outputs = outputs[1:].reshape(-1, n_class) # [trg_len-1 * batch_size, vocab_size]
targets = target_batch[1:].reshape(-1) # [trg_len-1 * batch_size]
loss = criterion(outputs, targets)
loss.backward()
optimizer.step()
if (epoch + 1) % 500 == 0:
print(f'Epoch: {epoch+1:04d}, Loss: {loss.item():.6f}')测试翻译结果
def translate(word):
input_batch, output_batch = make_testbatch(word, n_step, num_dic)
input_batch = input_batch.to(device)
output_batch = output_batch.to(device)
model.eval()
with torch.no_grad():
outputs = model(input_batch, output_batch, teacher_forcing_ratio=0.0)
# 获取预测结果
# outputs形状: [seq_len+1, 1, n_class]
predictions = outputs.argmax(2) # [seq_len+1, 1]
# 转换为字符
decoded = []
for idx in predictions[:, 0].cpu().numpy():
decoded.append(char_arr[idx])
# 找到结束标记
try:
end = decoded.index('E')
translated = ''.join(decoded[:end])
except ValueError:
translated = ''.join(decoded)
return translated.replace('P', '')
test_words = ['man', 'mans', 'king', 'black', 'ups']
for word in test_words:
result = translate(word)
print(f'{word} -> {result}'最终效果由于是字符级,效果不佳,总体的流程就是 Encoder 将输入序列的语义提取出来归纳为了一个向量,接着 Decoder 将其作为参考来进行训练/推理预测,一切句子开头都是 【开始 token】,接着不断向后预测
注意力思想
编码器:无论输入序列多长最终都要压缩为固定维度向量,导致信息损失
解码器:主要根据序列中上一个输入和上一个隐藏状态来预测下一个值,而序列过长时网络会遗忘上下文信息,在生成下一个 token 时,需要能看到原序列的相关内容
即需要将注意力放在解决当前问题的上文段落中,于是要在每个时间步的输入基础上添加一个关于上文的注意力向量,对于时间步 j,加权方式获取注意力向量
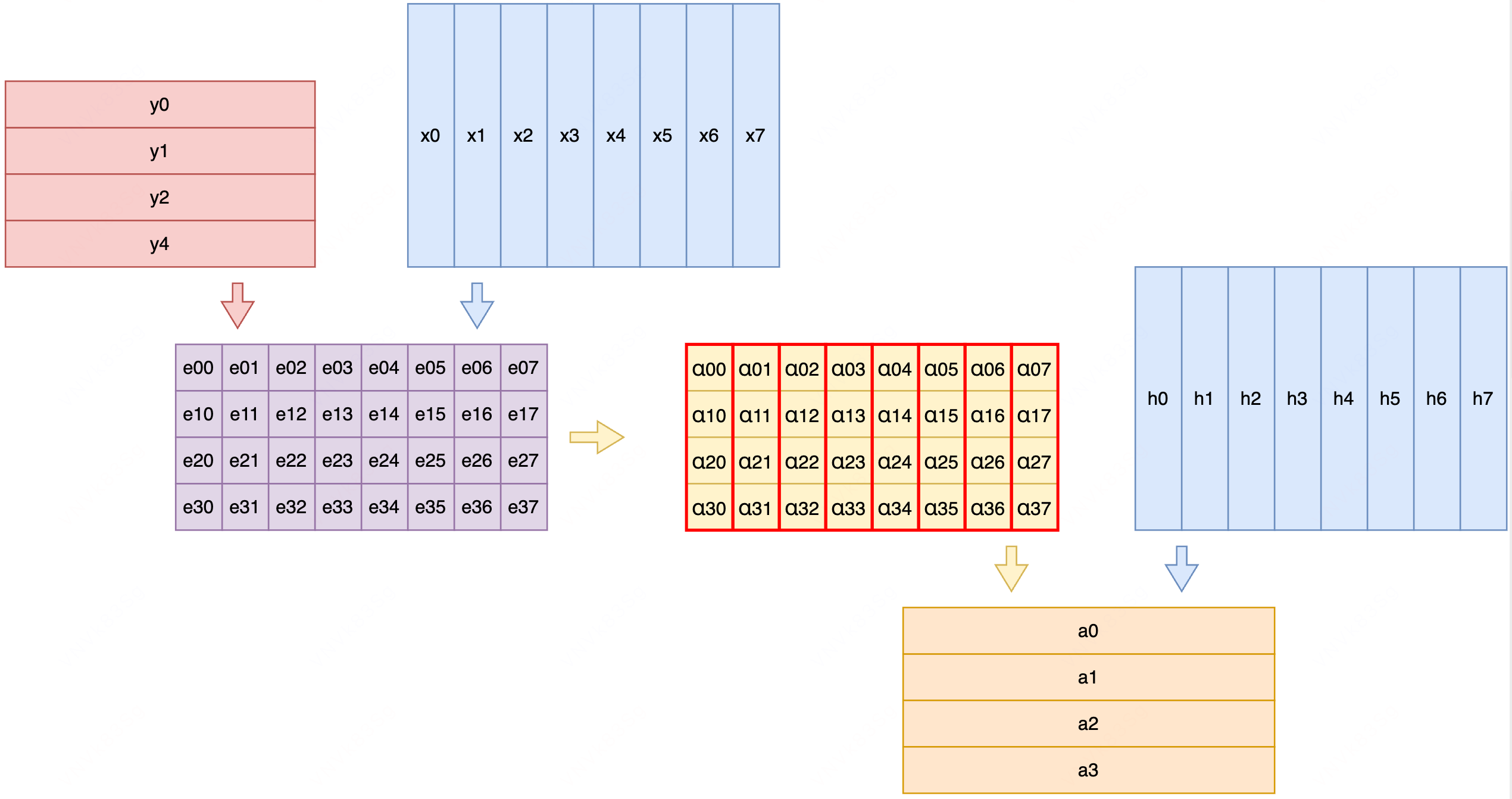
$$ a_j = \sum_{i=1}^S{\alpha_{ij}h_i},\quad其中 \sum_{i=1}^S{\alpha_{ij}=1} $$
- S:编码器的输入序列长度
- h:编码器第 i 个时间步的隐藏状态,包含输入序列中第 i 个词附近的信息
- a:上下文向量,对应解码器第 j 个时间步的输入上下文,即所有输入词语输出时间步 j 相关信息
- alpha:时间步 j 的输出对第 i 个输入 token 的相关性/关注程度。相关性越大,表示解码器时间步 j 的输出答案应该去编码器第 i 个时间步的隐藏层输出信息里找
主要看标量 alpha 如何得到:
- Encoder 输入序列
$$ X = (x_1^T,\cdots, x_S^T) $$
- Decoder 第 j 个时间步的 token 输入
$$ y_j $$
- 计算加权系数(注意力分数)
$$ e_{ij}=xy^T $$
若 Encoder 和 Decoder 的词嵌入向量维度不一样,先线形映射再点积计算
$$ e_{ij}=xWy^T $$
- softmax 归一化
$$ \alpha_{ij}=\frac{e^{e_{ij}}}{\sum_{k=1}^S{e_{kj}}} $$
大概流程
自注意力机制
在之前的注意力思想中可知,计算需要三种向量:
- 上文序列的词向量 xi
- 第 i 个时间步经过 RNN 的隐藏层输出 hi
- Decoder 第 j 个时间步的输入 token 词向量 yj
由于 RNN 第 t 个时间步需要等待上一个时间步 t - 1 的输出,导致训练和推理是串行的,速度慢,而 Self-Attention 解决了这一点,实现了并行执行,下一个 token 输出不再依赖于上一个 token 的输入,映射三个向量:
- qi:查询,询问上下文中哪些语义、文本信息是值得注意的,相当于 yj
- ki:键,上文序列的词向量,相当于 xi
- vi:值,提取上文序列词向量 ki 信息的隐藏层 hi
$$ q_i = x_iW^Q,\ k_i = x_iW^K,\ v_i = x_iW^V. $$
x 通过三个映射空间 W 得到 q,k,v,W 需要模型自己学习在训练过程中理解学习注意力思想
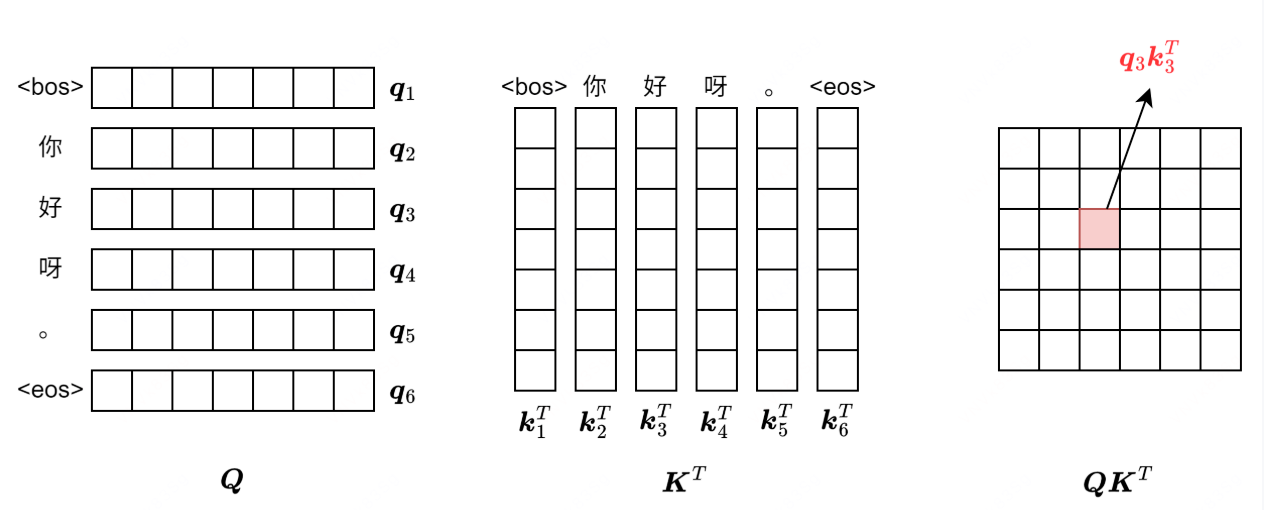
经过点积计算得到每个 token 在自身上下文中的注意力分数矩阵,由于模型对参数大小非常敏感,先使用缩放点积注意力方式,对注意力分数进行缩放,再进行 Softmax,最后和语义信息矩阵 V 相乘,得到注意力矩阵
$$ Attention(Q,K,V)=Softmax(\frac{QK^T}{\sqrt{d_k}})V $$
为何需要在 softmax 前进行一次缩放:用于控制注意力权重的梯度稳定性,防止梯度消失
当网络预测非常自信,概率分布极度倾斜时,所有输出节点的梯度都会变得极小,接着极小梯度会通过链式法则反向传播到前面的层,导致网络权重更新幅度极低,学习停滞,即“梯度消失“,softmax 中,z_i 很大会导致计算中分子指数增长,某个位置权重接近 1 其他接近 0,梯度变的非常小
$$ \text{softmax}(z_i) = \frac{e^{z_i}}{\sum_j e^{z_j}} $$
Q 和 K 中的元素是独立随机变量,均值为 0,方差为 1,对于维度为 d_k 的向量,点积之后方差变为 d_k,方差增大可能使得 softmax 的输入元素大,导致最大概率接近 1
$$ \text{Var}(q \cdot k) = \sum_{i=1}^{d_k} \text{Var}(q_i)\text{Var}(k_i) = d_k \times 1 \times 1 = d_k $$
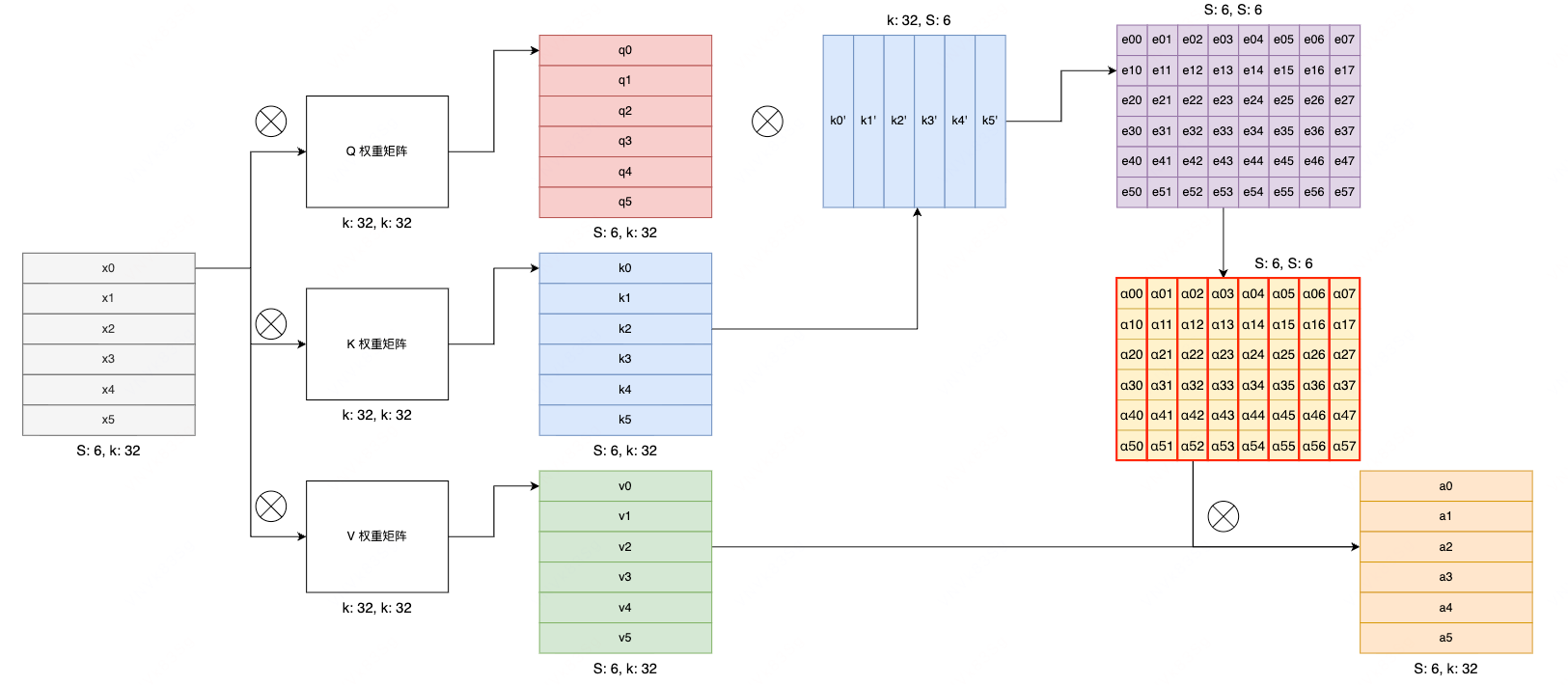
上图中初始输入每一行 x 为一个 token 的 embedding 序列,最终第 i 行的向量是第 i 个 token 的注意力向量,中间输出的正方形矩阵中每一个值都表示某一个 token 对某一个 token 的关注度
掩码机制
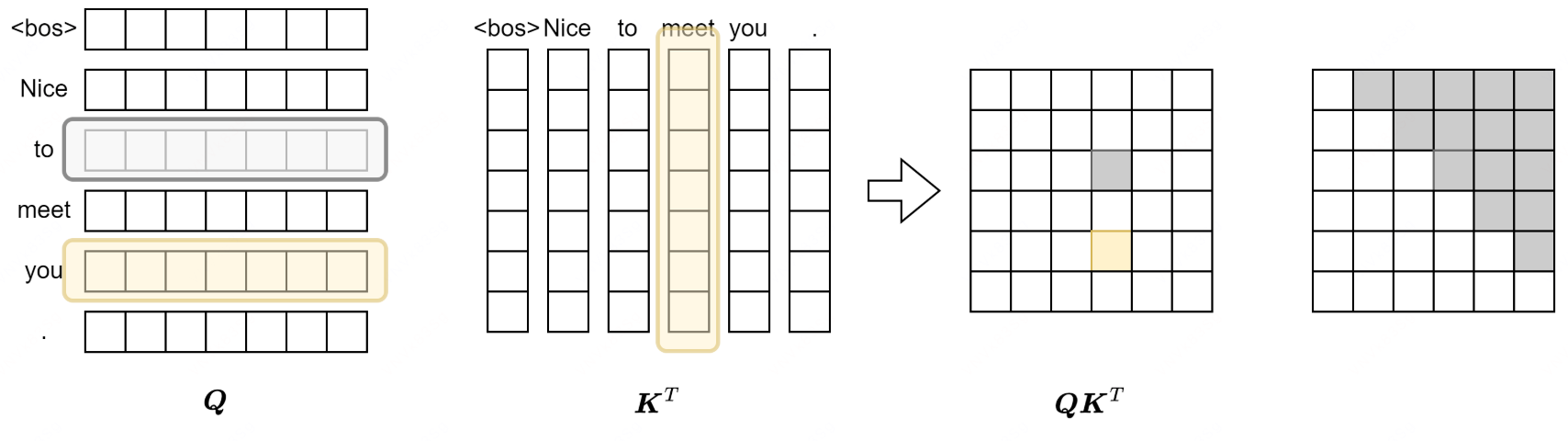
Decoder 监督学习阶段,需要使用['<bos>', 'Nice', 'to', 'meet', 'you', '.']预测输出['Nice', 'to', 'meet', 'you', '.', '<eos>'],是用于上文预测下文,而不可以看到后面的答案,所以需要 token 对后文的注意力分数为 0
如图,灰色代表 0,黄色代表非 0,Query 矩阵中 to 对应的向量不可注意到 meet 但 you 可以
多头注意力机制
假设维度
$$ d_{model} = 6 $$
将该维度切分成 3 个部分即该维度需要被头的个数整除,Q,K,V 都同样操作,得到对应蓝、绿、红三个部分,分别得到注意力分数矩阵的一部分,最后相加即完整注意力分数矩阵,而上述的矩阵乘法可以再 GPU 上并行执行,因此蓝、绿、红是三个不同的头,并行做相同操作
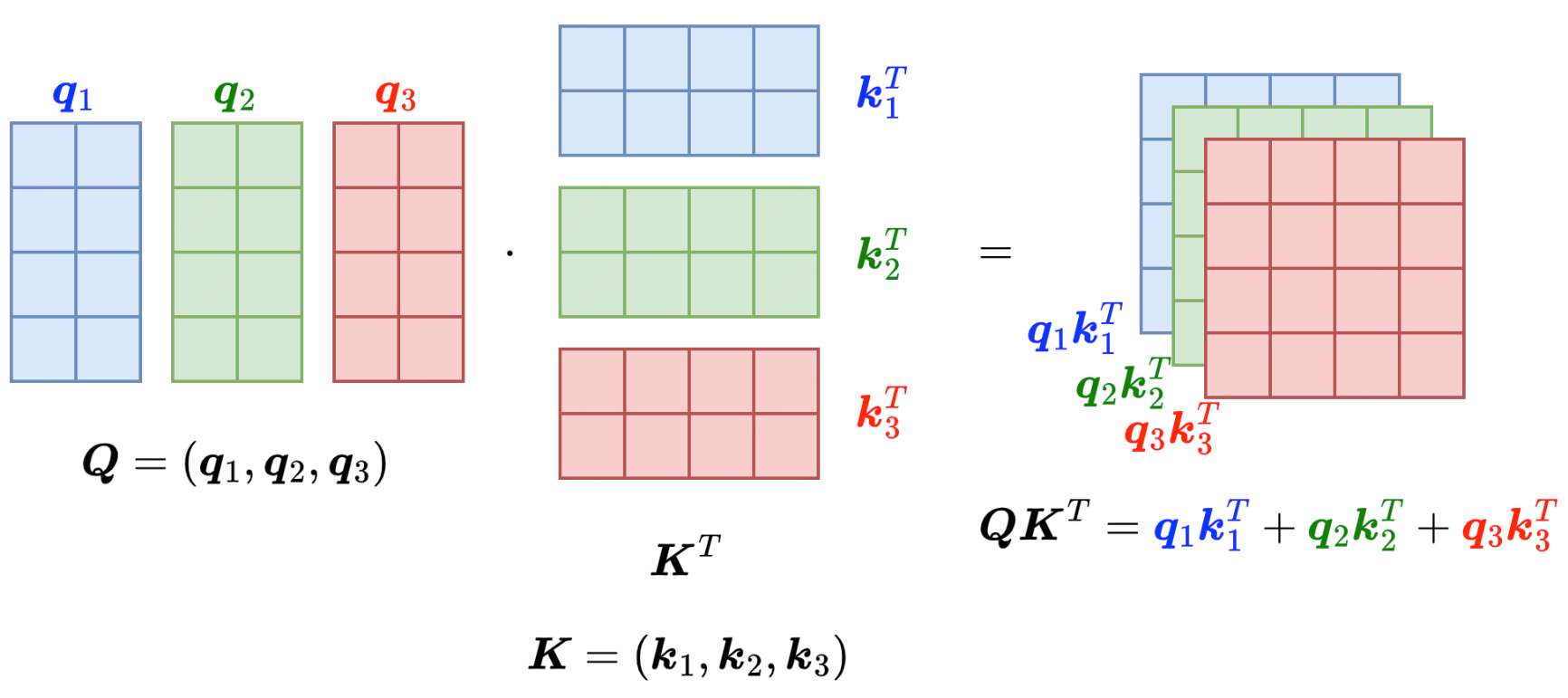
Q,K,V 的维度
$$ \mathbb{R}^{S\times h\times d_{k}}, \quad 其中,, d_k = \frac{d_{model}}{h} $$
几个头可并行执行,因此将头这个维度放在最外层,即 h 个大小为 [S, d_k] 的矩阵同时做相同操作
$$ \mathbb{R}^{h\times S\times d_{k}} $$
此时使用 v_k 而未使用 V,实际因为多头注意力通过将输入映射到多个不同的子空间,增强了模型捕捉不同语义关系的能力,比如第一个头的子空间看词性,第二个看token含义等等……
$$ head_k=Softmax(\frac{q_{k}k_k^T}{\sqrt{d_k}})v_k,\quad 1\le k\le h $$
最终需要将维度还原为[S, d_model],需要完成头的拼接,并且做一个线形变换,W 可学习,得到最终的多头注意力矩阵
$$ MHA = Concat(head_1, \cdots, head_h)W^O $$
⚠️ 注意
此处分头中列举的相加可得到完整注意力分数矩阵最终是未应用的,最终的输出是拼接而非相加,也就是说,实际是每个头关注的都是各自不同的子空间中学习不同关系特征(如动作→宾语,主语→谓语,地点→动作等等),最终有不同的子注意力分数矩阵,最终拼接后得到最终注意力分数矩阵
层归一化
批量归一化(Batch Normalization)
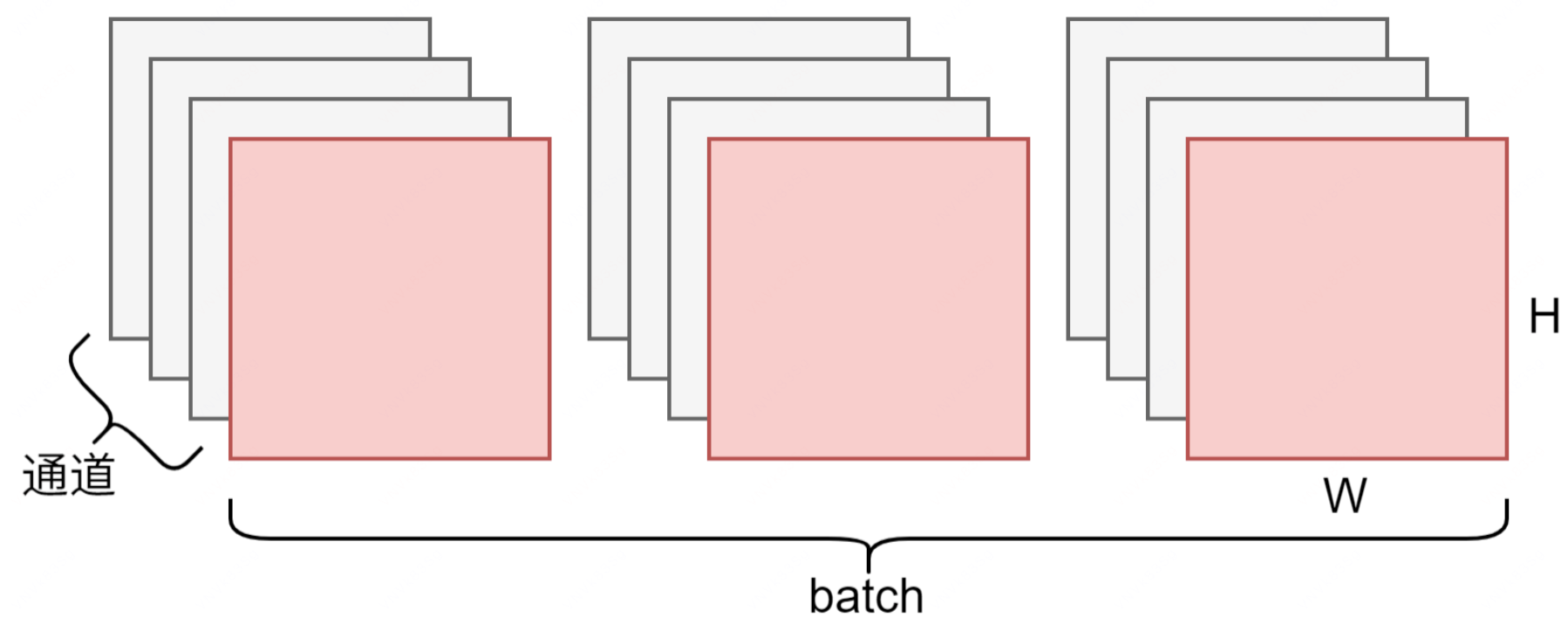
CNN 卷积神经网络中的批归一化:
- [B, C, W, H] 一个 batch 中 B(3) 个样本,C(4) 个 channel,长宽为 W, H
- 对一个 batch 中每个特征图的同一个 channel 为单位进行归一化
- 计算红色部分的所有数据的均值和方差,再根据方差和均值归一化原数据
层归一化(Layer Normalization)
1️⃣ 原始提出用于卷积的层归一化:
- 以一个样本的整个特征图 [C, H, W] 为单位进行归一化,与 batch 无关
- 每个样本计算一个均值和方差
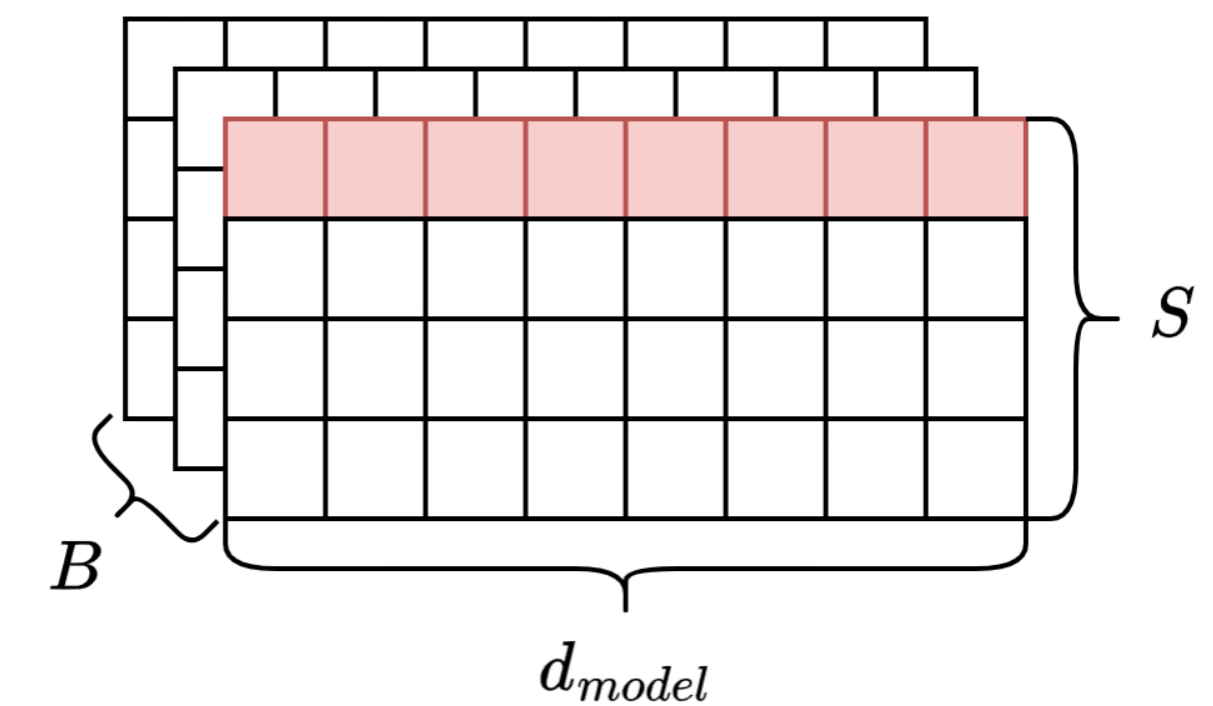
2️⃣ Transformer 引入到序列数据中:
- [B, S, d_model] 一个 batch 中 B 个样本,序列长度为 S,特征维度为 d_model(embedding 维度)
- channel 对应一个 token 的特征维度 d_model
- H x W 对应一个 token 词向量中的一个特征,一共 d_model 个特征
- 以一个 token 的所有特征向量为单位进行层归一化
对于
$$ x=(x_1,\cdots,x_{d_{model}}) $$
计算均值E(x)和方差D(x)后,对每个值进行线形变换(缩放、平移)
$$ y_i=\frac{x_i-E(x)}{\sqrt {D(x)}+\epsilon}\cdot \gamma_i + \beta_i,,,1\le i\le d_{model} $$
其中 gamma 和 beta 是可学习参数,随模型训练一起调整
构建 Transformer
包导入
import math
import torch
import torch.nn as nn
import torch.optim as optim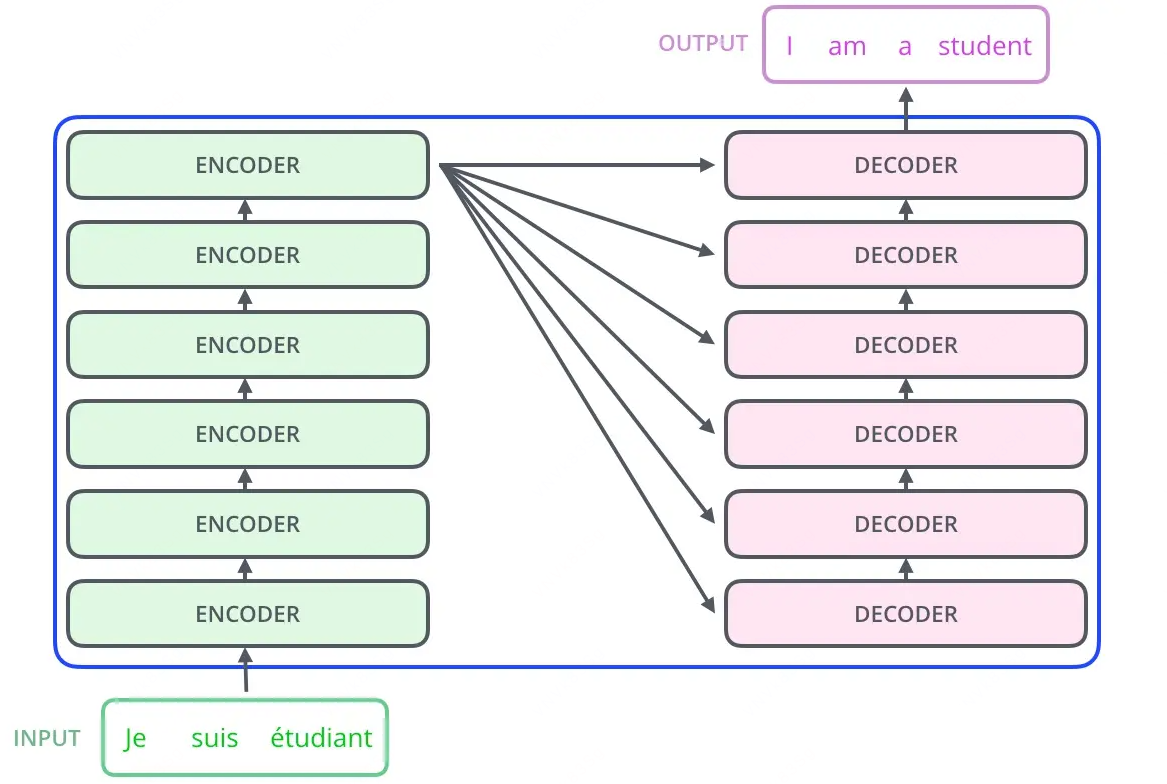
Transformer 由多个编码器和解码器组成
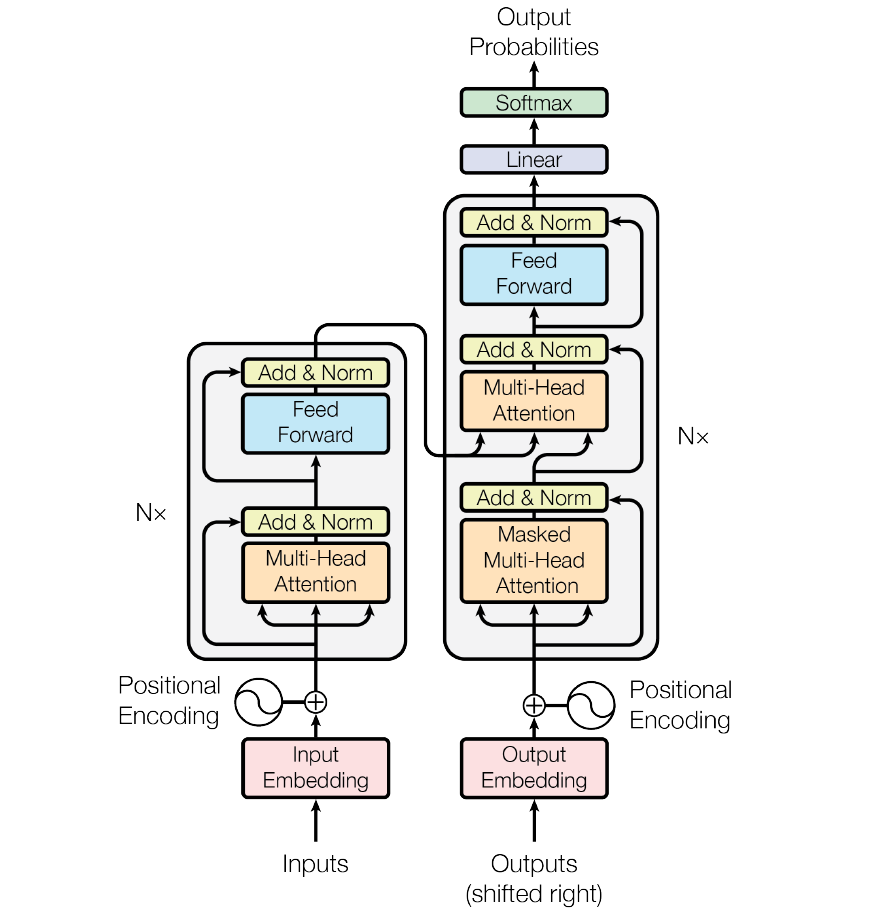
首先需要将灰色部分抽象为 N 个 Encoder Block 和 N 个 Decoder Block
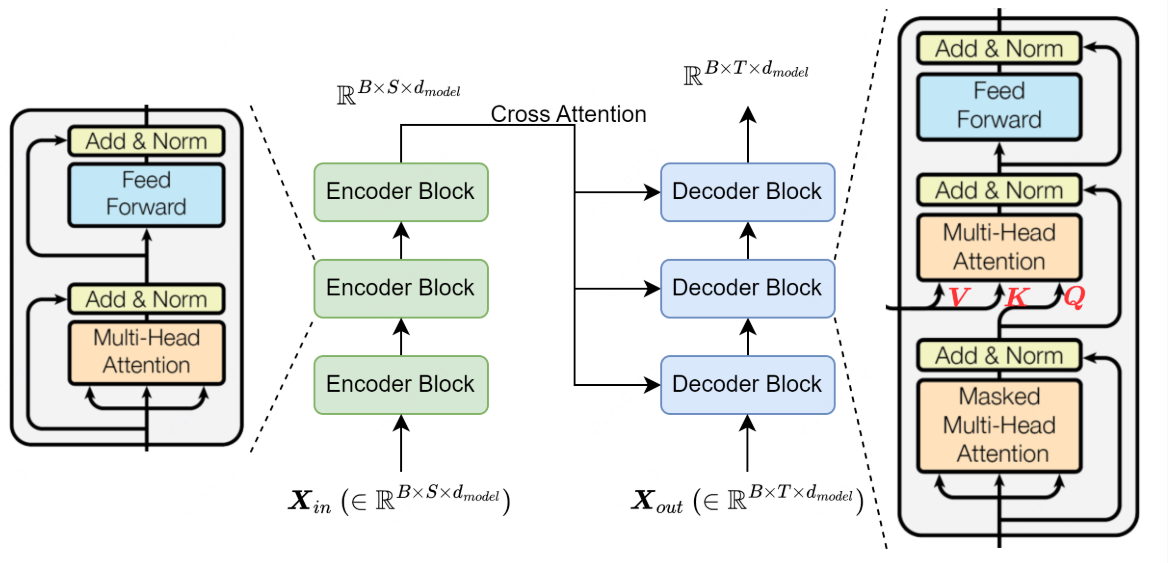
训练时以批次为单位,批次大小为 batch_size = B ,即 B 个大小相同的序列 [S, d_model] 做相同操作,即 Encoder Block 输入输出总是 [B, S, d_model],Encoder 模块最后一层的输出作为所有 Decoder Block 的交叉注意力输入,输入到 MHA 的 value 和 key 的位置,与 Seq2Seq 的含义相同,编码器将源序列的信息压缩到大小为 [S, d_model] 的矩阵中,作为目标序列的查询对象
Decoder 的输入和输出大小也一样,与 Encoder 区别是序列长度为 T,(但实际 S = T,若序列长度不一样需要将源序列和目标序列的长度填充至最大值)
MHA:多头注意力模块
三个橘黄色方块为多头注意力模块,区别在输入输出大小、是否添加掩码
- (B x h) 个 (S x d_k) 矩阵并行计算
class MHABlock(nn.Module):
def __init__(self, d_model: int, h: int, dropout: float):
super().__init__()
self.d_model = d_model # 嵌入向量维度/特征维度
self.h = h # 头数
assert d_model % h == 0, "h 无法整除 d_model"
self.d_k = d_model // h # 每个头的特征维度
self.WQ = nn.Linear(d_model, d_model, bias=False)
self.WK = nn.Linear(d_model, d_model, bias=False)
self.WV = nn.Linear(d_model, d_model, bias=False)
self.WO = nn.Linear(d_model, d_model, bias=False)
self.dropout = nn.Dropout(dropout)
@staticmethod
def attention(Q: torch.tensor, K: torch.tensor, V: torch.tensor, mask, dropout: nn.Dropout):
# Q, K, V: (B, h, S, d_k)
d_k = Q.shape[-1]
attn_scores = (Q @ K.transpose(-2, -1)) / math.sqrt(d_k)
if mask is not None:
attn_scores.masked_fill_(mask == 0, -1e9)
attn_scores = attn_scores.softmax(dim=-1)
if dropout is not None:
attn_scores = dropout(attn_scores)
return attn_scores @ V
def forward(self, XQ: torch.tensor, XK: torch.tensor, XV: torch.tensor, mask):
# 多个 X 用于注意力变体: 交叉注意力, Q 来自解码器, K、V 来自编码器
Q = self.WQ(XQ)
K = self.WK(XK)
V = self.WV(XV)
# 多头拆分 (B, S, d_model) ==> (B, S, h, d_k) ==> (B, h, S, d_k)
Q = Q.view(Q.shape[0], Q.shape[1], self.h, self.d_k).transpose(1, 2)
K = K.view(K.shape[0], K.shape[1], self.h, self.d_k).transpose(1, 2)
V = V.view(V.shape[0], V.shape[1], self.h, self.d_k).transpose(1, 2)
attn = MHABlock.attention(Q, K, V, mask, self.dropout)
# 多头拼接 (B, h, S, d_k) ==> (B, S, h, d_k) ==> (B, S, d_model)
attn = attn.transpose(1, 2).contiguous().view(attn.shape[0], -1, self.d_model)
return self.WO(attn)交叉注意力,根据编码器的内容 K V,由解码器去 Q 查询
Layer Norm:层归一化模块
在代码表示中: d_model = hidden_size = features
class LayerNorm(nn.Module):
def __init__(self, features: int, eps: float=1e-6):
super().__init__()
self.eps = eps
self.gamma = nn.Parameter(torch.ones(features))
self.beta = nn.Parameter(torch.zeros(features))
def forward(self, x):
# x: (B, S, d_model)
mean = x.mean(dim=-1, keepdim=True)
std = x.std(dim=-1, keepdim=True) # (B, S, 1)
return self.gamma * (x - mean) / (std + self.eps) + self.betaPositional Encoding:位置编码模块
class PositionalEncoding(nn.Module):
def __init__(self, d_model: int, seq_len: int, dropout: float):
super().__init__()
self.d_model = d_model
self.seq_len = seq_len
self.dropout = nn.Dropout(dropout)
# pe: (seq_len, d_model)
pe = torch.zeros(seq_len, d_model)
# position: (seq_len, 1) 数值从 0 到 seq_len
position = torch.arange(0, seq_len, dtype=torch.float).unsqueeze(1)
# div_term: (d_model / 2)
div_term = torch.pow(10000.0, -torch.arange(0, d_model, 2, dtype=torch.float) / d_model)
# (seq_len, d_model/2)
pe[:, 0::2] = torch.sin(position * div_term)
pe[:, 1::2] = torch.cos(position * div_term)
# (1, seq_len, d_model) 在 batch 维度上广播, 方便 x[B, S, d] + pe[1, S, d]
pe = pe.unsqueeze(0)
self.register_buffer('pe', pe) # 注册为模块缓冲区, 不参与梯度更新, 位置编码固定, 不学习, 但随模型一起保存在 GPU
def forward(self, x):
x = x + (self.pe[:, :x.shape[1], :]).requires_grad_(False)
return self.dropout(x)Feed Forward:前馈模块
先需要将 d_model 升维映射到 d_ff 空间中,然后再降维回 d_model
class FFNBlock(nn.Module):
def __init__(self, d_model: int, d_ff: int, dropout: float):
super().__init__()
self.net = nn.Sequential(
nn.Linear(d_model, d_ff), nn.ReLU(),
nn.Dropout(dropout),
nn.Linear(d_ff, d_model)
)
def forward(self, x):
return self.net(x)组装 Encoder
Encoder Block:编码模块
class EncoderBlock(nn.Module):
def __init__(self, features: int, num_heads: int, d_ff: int, dropout: float):
super().__init__()
self.mha_block = MHABlock(d_model=features, h=num_heads, dropout=dropout)
self.ffn = FFNBlock(d_model=features, d_ff=d_ff, dropout=dropout)
self.norm1 = LayerNorm(features=features)
self.norm2 = LayerNorm(features=features)
self.dropout = nn.Dropout(dropout)
def forward(self, x, src_mask):
# Pre-Norm
_x = self.norm1(x)
x = x + self.dropout(self.mha_block(_x, _x, _x, src_mask))
_x = self.norm2(x)
x = x + self.dropout(self.ffn(_x))
return xPre-Norm 和 Post-Norm 是 Layer Normalization 和 Residual Connections 两种不同的组合方式
- 原始 Transformer 论文使用的 Post-Norm 结构
- 训练深层网络时,存在梯度易爆炸、学习率敏感、初始化权重敏感等问题
y = Norm(x + attn(x))
x_next = Norm(y + FFN(y))- Pre-Norm 结构训练更稳定,收敛性更好
y = x + attn(Norm(x))
x_next = y + FFN(Norm(y))Encoder 编码器
class Encoder(nn.Module):
def __init__(self, num_layers: int, features: int, num_heads: int, d_ff: int, dropout: float):
super().__init__()
self.layers = nn.ModuleList([EncoderBlock(features, num_heads, d_ff, dropout) for _ in range(num_layers)])
def forward(self, x, src_mask):
for layer in self.layers:
x = layer(x, src_mask)
return x组装 Decoder
Decoder Block:解码模块
class DecoderBlock(nn.Module):
def __init__(self, features: int, num_heads: int, d_ff: int, dropout: float):
super().__init__()
self.mha_block = MHABlock(d_model=features, h=num_heads, dropout=dropout)
self.masked_mha_block = MHABlock(d_model=features, h=num_heads, dropout=dropout)
self.ffn_block = FFNBlock(d_model=features, d_ff=d_ff, dropout=dropout)
self.norm1 = LayerNorm(features)
self.norm2 = LayerNorm(features)
self.norm3 = LayerNorm(features)
self.dropout = nn.Dropout(dropout)
def forward(self, x, encoder_output, src_mask, tgt_mask):
# Pre-Norm
_x = self.norm1(x)
x = x + self.dropout(self.masked_mha_block(_x, _x, _x, tgt_mask))
_x = self.norm2(x)
x = x + self.dropout(self.mha_block(_x, encoder_output, encoder_output, src_mask))
_x = self.norm3(x)
x = x + self.dropout(self.ffn_block(_x))
return xDecoder:解码器
class Decoder(nn.Module):
def __init__(self, num_layers: int, features: int, num_heads: int, d_ff: int, dropout: float):
super().__init__()
self.layers = nn.ModuleList([DecoderBlock(features, num_heads, d_ff, dropout) for _ in range(num_layers)])
def forward(self, x, encoder_output, src_mask, tgt_mask):
for layer in self.layers:
x = layer(x, encoder_output, src_mask, tgt_mask)
return x完整 Transformer
class Transformer(nn.Module):
def __init__(
self,
src_vocab_size: int,
tgt_vocab_size: int,
d_model: int=512,
nhead: int=8,
num_encoder_layers: int=6,
num_decoder_layers: int=6,
dim_feedforward: int=2048,
dropout: float=0.1,
src_seq_len: int=512,
tgt_seq_len: int=512
):
super().__init__()
self.src_embedding = nn.Embedding(src_vocab_size, d_model)
self.tgt_embedding = nn.Embedding(tgt_vocab_size, d_model)
self.input_pe = PositionalEncoding(d_model, src_seq_len, dropout)
self.output_pe = PositionalEncoding(d_model, tgt_seq_len, dropout)
self.encoder = Encoder(num_encoder_layers, d_model, nhead, dim_feedforward, dropout)
self.decoder = Decoder(num_decoder_layers, d_model, nhead, dim_feedforward, dropout)
self.fc_out = nn.Linear(d_model, tgt_vocab_size)
self.dropout = nn.Dropout(dropout)
self.d_model = d_model
def forward(self, src, tgt, src_mask, tgt_mask):
src = self.input_pe(self.src_embedding(src) * math.sqrt(self.d_model))
tgt = self.output_pe(self.tgt_embedding(tgt) * math.sqrt(self.d_model))
encoder_output = self.encoder(src, src_mask)
decoder_output = self.decoder(tgt, encoder_output, src_mask, tgt_mask)
output = self.fc_out(decoder_output)
return output位置编码需要乘以
$$ \sqrt{d_{model}} $$
由于词嵌入层通常使用 Xavier 或 Kaiming 初始化,权重方差设计为 1/d_model,若未进行缩放,则嵌入输出的方差为 1,点积后方差仍会膨胀到 d_k,因此输入嵌入先乘以 sqrt(d_model) ,使得嵌入输出的方差为 d_model,点积后再除以 sqrt(d_k) ,将方差拉回 1
训练机器翻译模型
序列处理
两句话,相当于批次大小 B=2,添加开始和结尾特殊 token,并且以最大长度为准将 batch 中所有句子使用填充 token 填充到最大长度,使用 BERT 中文分词器,接着根据词汇表将 token 转换为 token id,最后进行词嵌入,每个 token id 对应一个大小为 d_model 的向量,最终每个句子由一个 S x d_model 大小的矩阵表示,一个批次中有 B 个这样的矩阵,一次输入 X 为 [B, S, d_model]
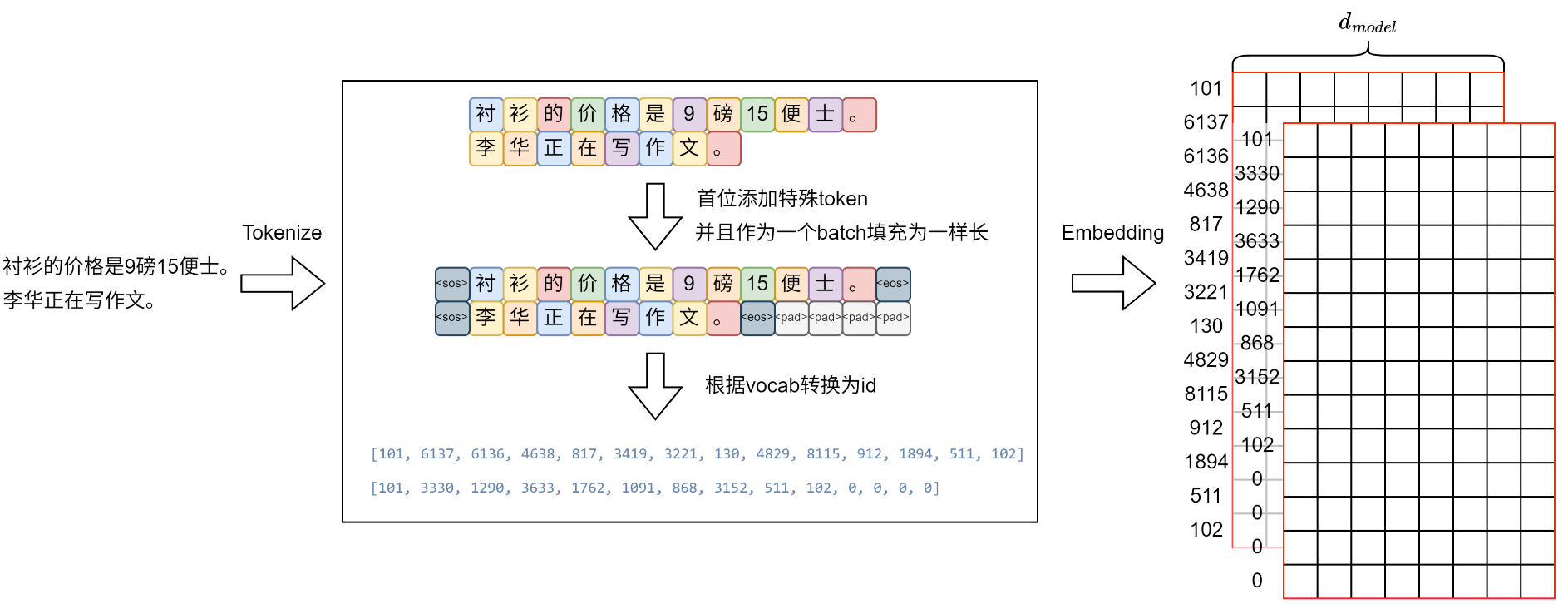
数据处理
- 使用 translation2019zh,中英文翻译数据集,train 大小大概 1.2 G
- JSON 格式:
{"english":"xxx","chinese":"yyy"},每一行符合 JSON 格式 - 下载:
curl -L -o ./translation2019zh.zip\ [https://www.kaggle.com/api/v1/datasets/download/terrychanor](https://www.kaggle.com/api/v1/datasets/download/terrychanor)
g/translation2019zh
unzip translation2019zh.zip # translation2019zh_train.json & _valid.json翻译数据集类
from torch.utils.data import Dataset, DataLoader
import json
import os
class TranslationDataset(Dataset):
def __init__(self, data_path, src_tokenizer, tgt_tokenizer, max_len=128):
self.data = self.load_data(data_path)
self.src_tokenizer = src_tokenizer # 源语言分词器 chinese
self.tgt_tokenizer = tgt_tokenizer # 目标语言分词器 english
self.max_len = max_len # 最大序列长度
def load_data(self, path):
"""数据加载"""
data = []
if not os.path.exists(path):
print(f"ERROR:文件 {path} 不存在")
return None
with open(path, 'r', encoding='utf-8') as f:
content = f.read().strip()
lines = content.split('\n')
for line in lines:
data.append(json.loads(line))
return data
def __len__(self):
return len(self.data)
def __getitem__(self, idx):
item = self.data[idx]
src_text = item.get('chinese', '')
tgt_text = item.get('english', '')
# BertTokenizer 会自动添加[CLS]和[SEP]来表示句子的起始和中止,在这里手动添加
src_encoding = self.src_tokenizer(src_text, truncation=True, max_length=self.max_len, add_special_tokens=False)
tgt_encoding = self.tgt_tokenizer(tgt_text, truncation=True, max_length=self.max_len, add_special_tokens=False)
# 获取 ID 列表
src_ids = src_encoding['input_ids']
tgt_ids = tgt_encoding['input_ids']
# 添加特殊 token (借用BERT的[CLS]作为SOS, [SEP]作为EOS)
sos_id = self.src_tokenizer.cls_token_id
eos_id = self.src_tokenizer.sep_token_id
return torch.tensor([sos_id] + src_ids + [eos_id], dtype=torch.long), \
torch.tensor([sos_id] + tgt_ids + [eos_id], dtype=torch.long)分词器使用 BERT 分词器实现,手动添加特殊 token <sos> 和 <eos>
批处理函数
DataLoader 中使用 collate_fn 变量,批处理函数目的是将每个批次的源序列和目标序列填充到一样长度,使用特殊 token <pad> 填充,每个 batch 填充后的序列长度可能不一样
from torch.nn.utils.rnn import pad_sequence
def collate_fn(batch):
src_batch, tgt_batch = zip(*batch) # [(src1, tgt1), (src2, tgt2), ...] -> (src1, src2, ...) & (tgt1, tgt2, ...)
pad_idx = 0 # 0: BERT tokenizer 默认 pad_token_id
# 填充序列
src_padded = pad_sequence(src_batch, batch_first=True, padding_value=pad_idx)
tgt_padded = pad_sequence(tgt_batch, batch_first=True, padding_value=pad_idx)
# [batch_size, seq_len]
return src_padded, tgt_padded掩码生成
src_mask:作用于源序列,防止关注 padding 位置,[B, 1, 1, S],中间两个维度为了在 h 和列方向进行广播,所有 token 不能查询 padding,即不能对 padding 形成注意力,K 转置的最后被 padding 的几列和 Q 所有行相乘后得到的注意力分数为 0,padding 可以对其他 token 形成注意力,生成大小为 [d_model, d_model] 最后被 padding 的几列均为-inf的掩码矩阵tgt_mask:作用于目标序列,除了防止关注 padding 位置,还需要三角掩码防止对未来进行关注,[B, 1, S, S]
def create_masks(src, tgt, pad_idx=0):
src_seq_len = src.shape[1]
tgt_seq_len = tgt.shape[1]
# (src != pad_idx) -> (B, S) -> unsqueeze -> (B, 1, 1, S)
src_mask = (src != pad_idx).unsqueeze(1).unsqueeze(2)
# 屏蔽pad: (B, 1, 1, T)
tgt_pad_mask = (tgt != pad_idx).unsqueeze(1).unsqueeze(2)
# 屏蔽未来 (Look-ahead): (1, 1, T, T)
# 下三角矩阵为1,其余为0
tgt_sub_mask = torch.tril(torch.ones((tgt_seq_len, tgt_seq_len), device=src.device)).bool()
# 两个矩阵结合
tgt_mask = tgt_pad_mask & tgt_sub_mask.unsqueeze(0).unsqueeze(0)
return src_mask, tgt_mask配置设置
class Config:
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
train_data_path = "./translation2019zh_train.json"
valid_data_path = "./translation2019zh_valid.json"
# 训练超参数
batch_size = 32
num_epochs = 1
learning_rate = 0.0001
max_len = 128 # 限制最大句子长度
# 模型参数
d_model = 512
nhead = 8
num_encoder_layers = 3
num_decoder_layers = 3
dim_feedforward = 2048
dropout = 0.1
# 使用 Hugging Face 的 BERT 分词器
src_tokenizer_name = 'bert-base-chinese'
tgt_tokenizer_name = 'bert-base-uncased'训练模块
from tqdm import tqdm
def train(model, iterator, optimizer, criterion, clip, device):
model.train()
epoch_loss = 0
proc_bar = tqdm(iterator, desc="Training")
for i, (src, tgt) in enumerate(proc_bar):
src = src.to(device)
tgt = tgt.to(device)
# 原始目标序列 [SOS] I love China [EOS] -> [1, 10, 20, 30, 2]
# tgt_input: [SOS] I love China -> [1, 10, 20, 30]
# tgt_output: I love China [EOS] -> [10, 20, 30, 2]
tgt_input = tgt[:, :-1] # tgt输入: 去掉最后一个 token <eos>
tgt_output = tgt[:, 1:] # tgt输出(标签): 去掉第一个 token <sos>
src_mask, tgt_mask = create_masks(src, tgt_input, pad_idx=0)
optimizer.zero_grad()
# 前向传播 每个位置表示某样本在某时间步在词汇表上的概率分布
output = model(src, tgt_input, src_mask, tgt_mask) # (batch_size, seq_len, tgt_vocab_size)
output_dim = output.shape[-1]
# 拉平以计算损失
output = output.contiguous().view(-1, output_dim) # [batch_size * seq_len, tgt_vocab_size]
tgt_output = tgt_output.contiguous().view(-1) # [batch_size * seq_len]
loss = criterion(output, tgt_output)
loss.backward()
torch.nn.utils.clip_grad_norm_(model.parameters(), clip) # 梯度裁剪: 防止梯度爆炸,稳定训练
optimizer.step()
epoch_loss += loss.item()
proc_bar.set_postfix(loss=loss.item())
return epoch_loss / len(iterator)评估模块
def evaluate(model, iterator, criterion, device):
model.eval()
epoch_loss = 0
with torch.no_grad(): # 禁用梯度计算
for i, (src, tgt) in enumerate(iterator):
src = src.to(device)
tgt = tgt.to(device)
tgt_input = tgt[:, :-1]
tgt_output = tgt[:, 1:]
src_mask, tgt_mask = create_masks(src, tgt_input, pad_idx=0)
output = model(src, tgt_input, src_mask, tgt_mask)
output_dim = output.shape[-1]
output = output.contiguous().view(-1, output_dim)
tgt_output = tgt_output.contiguous().view(-1)
loss = criterion(output, tgt_output)
epoch_loss += loss.item()
return epoch_loss / len(iterator)完整训练
import torch.optim as optim
import os
os.environ["HF_ENDPOINT"] = "https://hf-mirror.com"
os.environ["HF_HOME"] = "./model/"
from transformers import AutoTokenizer # 缓存和下载地址的配置都必须在导入这个包之前完成
src_tokenizer = AutoTokenizer.from_pretrained(Config.src_tokenizer_name)
tgt_tokenizer = AutoTokenizer.from_pretrained(Config.tgt_tokenizer_name)
train_dataset = TranslationDataset(Config.train_data_path, src_tokenizer, tgt_tokenizer, max_len=Config.max_len)
val_dataset = TranslationDataset(Config.valid_data_path, src_tokenizer, tgt_tokenizer, max_len=Config.max_len)
# 传入数据的同时填充序列到相同长度(按照批次中最长的那个序列)
train_loader = DataLoader(train_dataset, batch_size=Config.batch_size, shuffle=True, collate_fn=collate_fn)
val_loader = DataLoader(val_dataset, batch_size=Config.batch_size, shuffle=False, collate_fn=collate_fn)
model = Transformer(
src_vocab_size=src_tokenizer.vocab_size,
tgt_vocab_size=tgt_tokenizer.vocab_size,
d_model=Config.d_model,
nhead=Config.nhead,
num_encoder_layers=Config.num_encoder_layers,
num_decoder_layers=Config.num_decoder_layers,
dim_feedforward=Config.dim_feedforward,
dropout=Config.dropout,
src_seq_len=Config.max_len + 5,
tgt_seq_len=Config.max_len + 5
).to(Config.device)
# 初始化权重Xavier init通常对Transformer有效, 只对维度大于1的权重进行初始化(排除偏置项)
def initialize_weights(m):
if hasattr(m, 'weight') and m.weight.dim() > 1:
nn.init.xavier_uniform_(m.weight.data)
model.apply(initialize_weights)
optimizer = optim.Adam(model.parameters(), lr=Config.learning_rate)
# 忽略<pad>的loss
criterion = nn.CrossEntropyLoss(ignore_index=0)
best_valid_loss = float('inf')
start_epoch = 0
for epoch in range(start_epoch, Config.num_epochs):
train_loss = train(model, train_loader, optimizer, criterion, 1.0, Config.device)
valid_loss = evaluate(model, val_loader, criterion, Config.device)
# 保存最佳模型
if valid_loss < best_valid_loss:
best_valid_loss = valid_loss
torch.save(model.state_dict(), 'transformer_model.pt')运行在服务器一张 A800 80G 卡上,最终 loss 为 2.73
推理
自回归(Auto-Regression):Decoder 首先输入 <sos> ,模型根据从 Encoder 中理解到的信息生成下一个 token,并将其加入到 Decoder 输入中,得到 Decoder 下一个输入序列,此时可能为 [<sos>, it] ,以预测下一个 token,如此循环直到句子的截止符<eos>或达到设定的序列最大长度
def translate_sentence(sentence, src_tokenizer, tgt_tokenizer, model, device, max_len=128):
model.eval()
# 手动添加特殊 token,因此 add_special_tokens=False, 获取 token_id
tokens = src_tokenizer(sentence, truncation=True, max_length=max_len, add_special_tokens=False)['input_ids']
sos_idx = src_tokenizer.cls_token_id
eos_idx = src_tokenizer.sep_token_id
src_indices = [sos_idx] + tokens + [eos_idx]
src_tensor = torch.LongTensor(src_indices).unsqueeze(0).to(device) # (1, src_len)
# 屏蔽 <pad>
src_mask = (src_tensor != 0).unsqueeze(1).unsqueeze(2) # (1, 1, 1, src_len)
with torch.no_grad():
# 对应Transformer.forward中的: src = self.input_pe(self.src_embedding(src) * math.sqrt(self.d_model))
src_emb = model.src_embedding(src_tensor) * math.sqrt(model.d_model)
src_emb = model.input_pe(src_emb)
encoder_output = model.encoder(src_emb, src_mask)
# 自回归生成
tgt_indices = [sos_idx] # 初始输入只有<sos>
for i in range(max_len):
tgt_tensor = torch.LongTensor(tgt_indices).unsqueeze(0).to(device) # (1, current_tgt_len)
# Look-ahead mask (注意, 在推理的过程中实际上不需要掩码了, 因为Decoder的过程本来就是预测未来)
tgt_len = tgt_tensor.shape[1]
tgt_sub_mask = torch.tril(torch.ones((tgt_len, tgt_len), device=device)).bool() # (T, T)
tgt_mask = tgt_sub_mask.unsqueeze(0).unsqueeze(0) # (1, 1, T, T)
with torch.no_grad():
# 对应Transformer.forward中的: tgt = self.output_pe(self.tgt_embedding(tgt) * math.sqrt(self.d_model))
tgt_emb = model.tgt_embedding(tgt_tensor) * math.sqrt(model.d_model)
tgt_emb = model.output_pe(tgt_emb)
output = model.decoder(tgt_emb, encoder_output, src_mask, tgt_mask)
# 通过全连接层映射到词表
output = model.fc_out(output)
# 获取最后一个时间步的预测结果 output shape: (1, T, tgt_vocab_size)
# argmax(2): 沿着第二个维度取最大值 -> (1, T) 每个位置保存概率最高的 token id
# [:, -1]: -> (1,)
# .item(): -> 1 转换为标量
pred_token = output.argmax(2)[:, -1].item() # 取概率最高的 token
tgt_indices.append(pred_token)
# 预测出结束符<eos>则停止生成
if pred_token == eos_idx:
break
# token id 转换回 token, skip_special_tokens=True 会自动去掉特殊token
translated_sentence = tgt_tokenizer.decode(tgt_indices, skip_special_tokens=True)
return translated_sentence最终推理展示
src_tokenizer = AutoTokenizer.from_pretrained(Config.src_tokenizer_name)
tgt_tokenizer = AutoTokenizer.from_pretrained(Config.tgt_tokenizer_name)
model = Transformer(
src_vocab_size=src_tokenizer.vocab_size,
tgt_vocab_size=tgt_tokenizer.vocab_size,
d_model=Config.d_model,
nhead=Config.nhead,
num_encoder_layers=Config.num_encoder_layers,
num_decoder_layers=Config.num_decoder_layers,
dim_feedforward=Config.dim_feedforward,
dropout=Config.dropout,
src_seq_len=Config.max_len + 5,
tgt_seq_len=Config.max_len + 5
).to(Config.device)
model_path = 'transformer_model.pt'
model.load_state_dict(torch.load(model_path, map_location=Config.device))
while True:
sentence = input("Chinese: ")
if sentence.lower() == 'q':
break
translation = translate_sentence(sentence, src_tokenizer, tgt_tokenizer, model, Config.device)
print(f"==> English: {translation}")