
强化学习
奖励函数(reward function)
奖励(reward):R,通过奖励好行为和惩罚坏行为使自动学习,核心要素:(s_start, action, reward(s_start), s_change)
回报 (return)
折扣因子(discount factor)$\gamma=0.9$:奖励随动作增加减少
$return=R_1 \cdot (\gamma) + R_2 \cdot (\gamma)^2 + \cdots + R_n\cdot (\gamma)^n$
策略函数(policy)
强化学习需要找到策略函数:$\pi(s)=a$来最大化回报
马尔科夫决策过程:Markov Decision Process(MDP)
未来只取决于现在状态
状态-动作价值函数(State-action value function, Q function or optimal Q function or Q*)
$\max_a Q(s, a)$得到从状态 s 经过动作 a 后最佳表现的回报
贝尔曼方程(Bellman Equation)
- s:当前状态,R(s):当前状态的奖励,a:当前动作,s’:a动作后的状态,a’:s’状态时采取的动作
- $Q(s,a)=R(s)+\gamma \max_{a’}Q(s’,a’)=R_1+\gamma R_2 +\gamma^2 R_3 +\cdots= R_1+\gamma[R_2+\gamma R_3 +\cdots]$
随机环境(Stochastic Environment)
当出现随机情况,即下一个状态可能未实现,则更关注的是最大化多次运动下的期望回报
- $Expected,,Return = Average(R_1+\gamma R_2+\gamma^2 R_3 +\cdots)=E[R_1+\gamma R_2+\gamma^2 R_3 +\cdots]$
- $Q(s,a)=R(s)+\gamma E[\max_{a’}Q(s’,a’)]$
连续状态空间
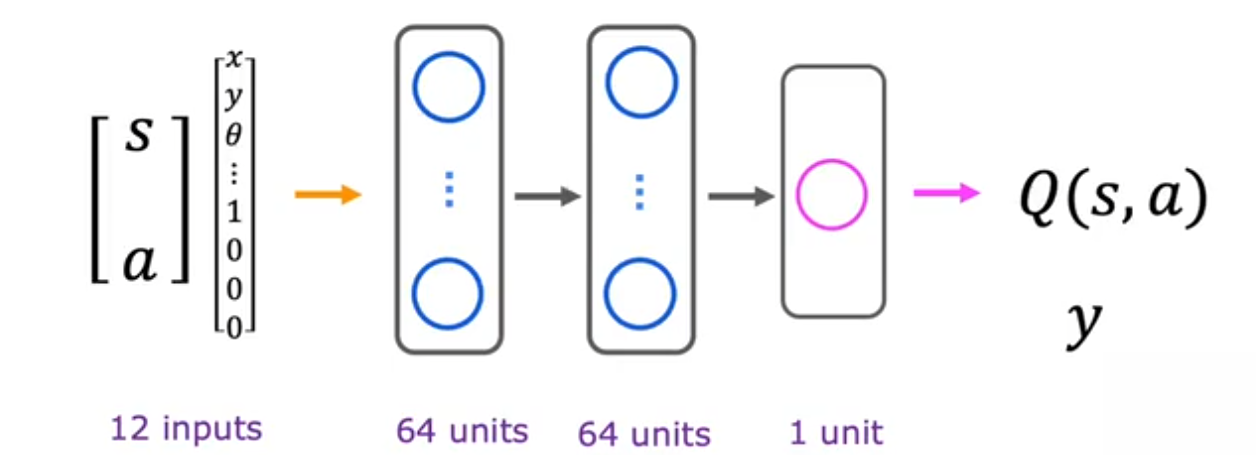
每个状态不是离散的,通过向量表示:$s=[x,,y,,\theta,,x’,,y’,,\theta’]$可分别表示位置,方向,速度,角度等
深度强化学习-学习状态值函数
使用神经网络去预测Q函数,选择最大化 Q(s,a) 的动作 a
ε-贪婪策略
- 0.95概率选择最大化 Q(s,a) 的动作 a:exploitation
- 0.05概率选择随机的动作 a (ε=0.05, 逐渐减小 ε ):exploration
软更新
当使用小批量梯度下降时,更新 Q 的参数 w 及 b 时:$w=0.01w_{new}+0.99w\quad b=0.01b_{new}+0.99b$
MCTS
蒙特卡洛树搜索,The Monte Carlo Tree Search,给定一个游戏状态,选择最佳下一步
-
选择selection:选择最大化UCB值的结点,$UCB(S_i)=\overline{V_i}+c\sqrt{\frac{\log N}{n_i}}, c=2$
- $V_i$指该结点下平均价值,N探索次数,n当前结点探索次数
-
扩展node_expansion:创建一个或多个子节点
-
仿真Rollout:某一节点用随机策略进行游戏
-
1 2 3 4 5 6Def Rollout(S_i): loop forever: if S_i is a terminal state: return value(S_i) A_i = random(available-actions(S_i)) S_i = simulate(A_i, S_i) -
反向传播backpropagation:使用随机搜索结果更新搜索树,价值累加,探索次数加一
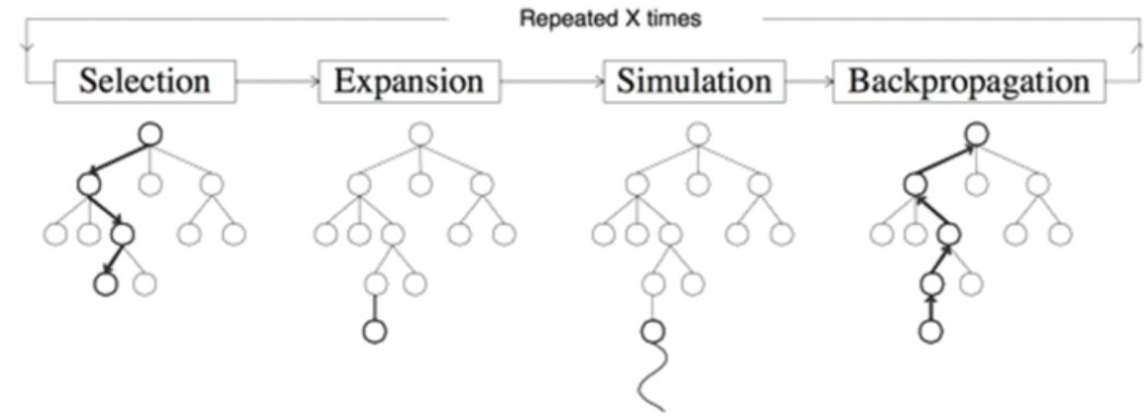
- 通过计算UCB最大值一直到叶结点,查看是否探索过,未探索过则仿真
- 探索过则枚举当前结点所有可能动作添加到树,扩展一个新结点