
基础
笔记相关
- 数学公式:
$$为不另起一行,$$$$为另起一行\\换行需要转换为\\\换行_有时需要转义为\_\,有时需要转义为\\,- 以下均可能被包裹在
{}中,只需要转义第一个字符<需要转义为\<[需要转义为\[- 先下标再上标
灰度图
一般为3个数相乘,前两个数是长宽,单位为像素,最后一个数是指RGB通道数,灰度图为1,相乘的结果作为维数,输入值将平展为一列向量
均方误差
mean_squared_error: MSE
专业术语
- 输入变量/特征 x
- 输出变量/目标变量 y
- 训练示例总数 m
- 训练示例 (x, y)
- 第 i 个训练示例$(x^{(i)}, y^{(i)})$
- 输出的估计值 $\hat y$
- 函数/模型 f
- 系数,权重,变量
- 满足指标,优化指标
- 人类水平代表贝叶斯最优误差
- F-范数:矩阵每个数平方和开根号
模型训练步骤
- 给定x,w,b明确输出函数
- 确定损失和代价函数
- 训练数据最小化代价函数
模型评估
多元特征时,不好绘制多维图像,使用一些系统方法评估模型
构造数据:数据增强(旋转,扭曲)、数据合成(人工生成)
迁移学习——针对数据集小
- 预训练,获取大模型:神经网络先分类1000份得到前N-1层的参数
- 微调,小模型调参:使用这些参数,迁移到另一个神经网络,用梯度下降优化求第N层的参数或将前N-1层参数作为初始值继续变化,最后一层1000个神经元替换为其他如10个神经元,用于分类10份
- 两模型输入类型需相同
多任务学习
一个神经网络模型中分类每张图都包含多个标签
端到端深度学习(end-to-end)
大量数据包括各种子数据,不经过中间过程
预处理
将数据集分为训练集(训练模型)和测试集(评估模型),需要具有相同分布
- 回归模型:计算训练集与测试集的代价函数中的平方误差项,比较测试集大小
- 分类模型:计算训练集与测试集的代价函数中的平均损失函数项,主要看测试集和训练集中误分类的分值,即预测的y和实际y不相等的个数
标准化:需要先将数据规格化,即减去平均值并除以标准差,得到[-1, 1]的范围,并且打乱数据
交叉验证
cross validate
分为:训练集60%、测试集20%、交叉验证集20%,大数据集时:可分为98%、1%、1%
- 练模型:N个模型使用训练集得到N组参数
- 挑模型:使用交叉验证集求每个模型的平方误差$J_{cv}$比较
- 测模型:最终使用测试集求平方误差评估泛化误差(Generalization Error)
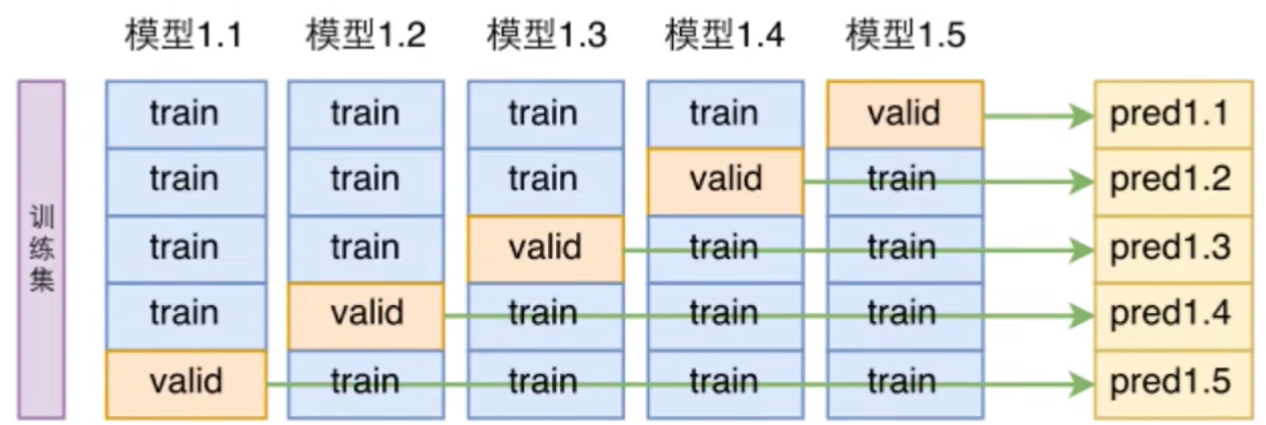
- 针对训练集进行交叉验证:将训练集分成 K [n1,n2,…,nK] 份,进行 K 次实验
- 第 i 次实验中,取 ni 作为训练集中的验证集,其余为训练集中的训练集
- K 次实验最终取平均
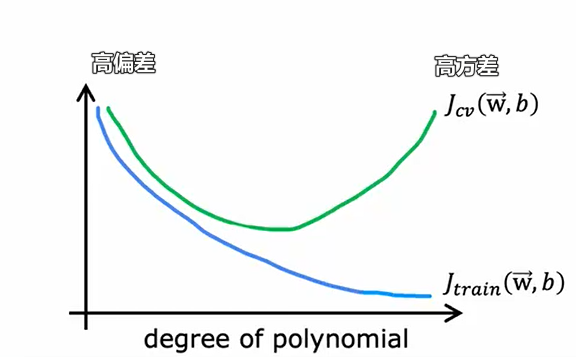
偏差方差
高偏差:不拟合,$J_{cv}$高,$J_{train}$高,相差不大
高方差:过拟合,$J_{cv}$高,$J_{train}$低,后者远小于前者
与多项式程度的关系
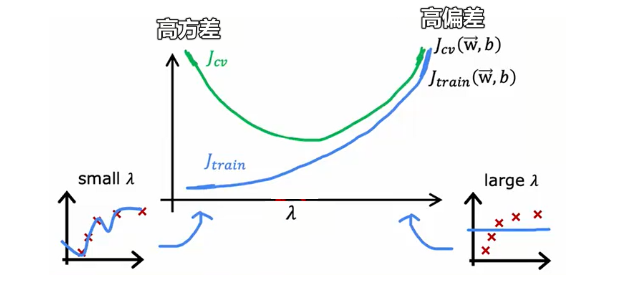
正则化参数$\lambda$影响偏差、方差
表现基准
需要加入人类基准表现,来判断模型的训练误差$J_{train}$和交叉验证误差$J_{cv}$
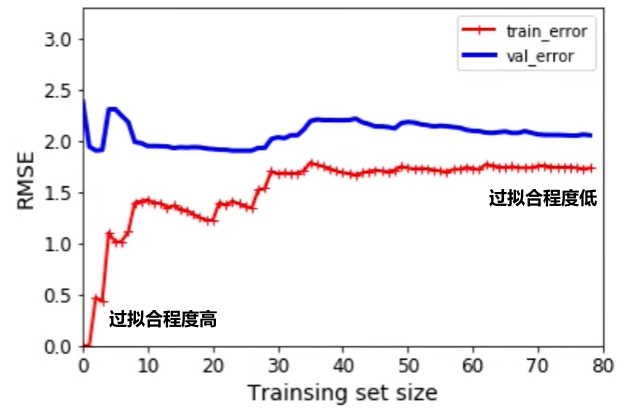
学习曲线判断偏/方差
高偏差下,增加训练集不会有助于模型(例如:使用线性模型拟合二次函数,再多点都不利于拟合)
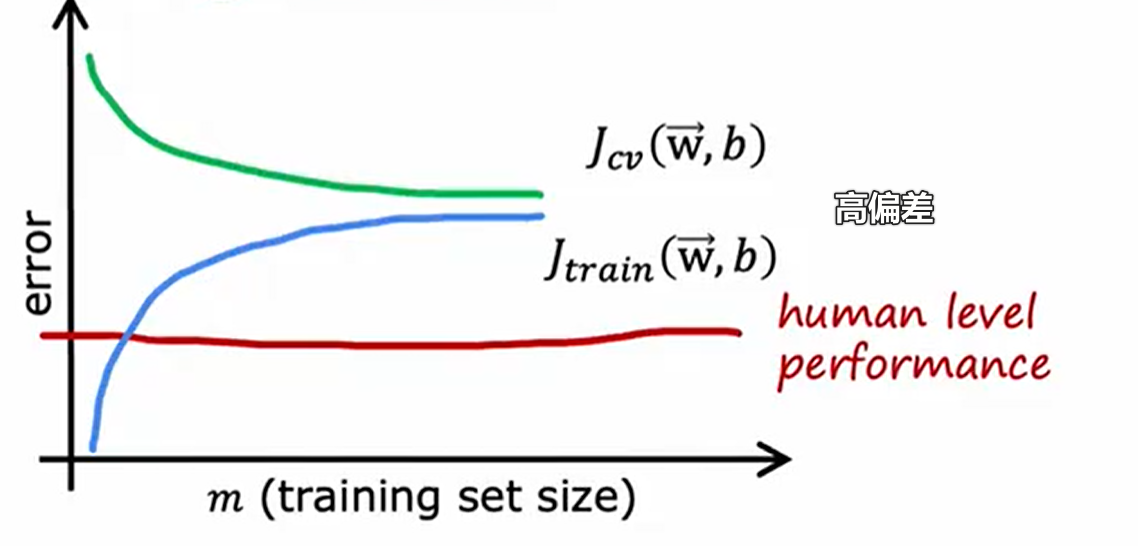
高方差下,增加训练集有助于模型(例如:模型过拟合匹配了四次函数,数据增多使模型逐渐接近四次函数模型)
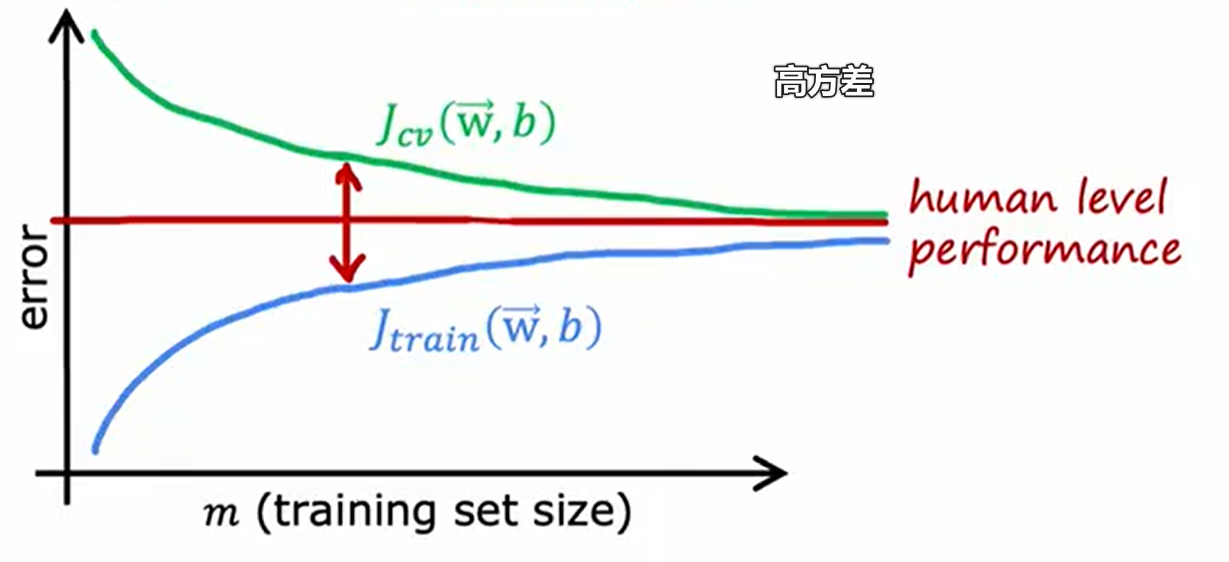
- 更多训练集:解决高方差
- 更少特征:解决高方差
- 更多特征:解决高偏差
- 增加多项式特征:解决高偏差
- 增加正则化:解决高偏差
- 减少正则化:解决高方差
- 更大神经网络:解决高偏差
混淆矩阵
处理倾斜数据集,使用不同误差度量,而非分类误差
Confusion Matrix
| 相关(Relevant),正类 | 无关(NonRelevant),负类 | |
|---|---|---|
| 被检索到(Retrieved) | TP (true positives)检索到正确的值 | FP (false positives)检索到错误的值:存伪 |
| 未被检索到(Not Retrieved | FN (false negatives)未检测到正确的值:去真 | TN (true negatives)未检测到错误的值 |
两个指标:区分只报单一类别的模型
精准度:$precision=\frac{TP}{TP+FP(total,predicted,positive)}$:预测病人得某病,大概率病人确实有该病
召回率:$recall=\frac{TP}{TP+FN(total,actual,positive)}$:病人有该病,大概率模型能够识别出来确有该病
当$f_{w,b}(x)\gt$threshold阈值,预测为1:
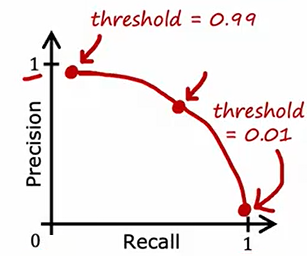
不使用平均值$\frac{Precision+Recall}{2}$,因为P很低但R很高的情况如:只播报不得病也可能获得高平均值,而通过调和平均值,给低值更多权重,结合为一个综合指标**:F1 score**
$F_1=\frac{2}{\frac{1}{precision}+\frac{1}{recall}}=\frac{TP}{TP+\frac{FN+FP}{2}}$
ROC曲线
Receiver Operating Characteristic,该曲线是二元分类中的常用评估方法,通过计算各种阈值的 true positive rate(TPR) 和 false positive rate(FPR) 进行绘制
- y轴:TPR = TP / (TP + FN) (Recall)
- x轴:FPR = FP / (FP + TN)
一个好的分类器尽可能朝左上方远离虚线
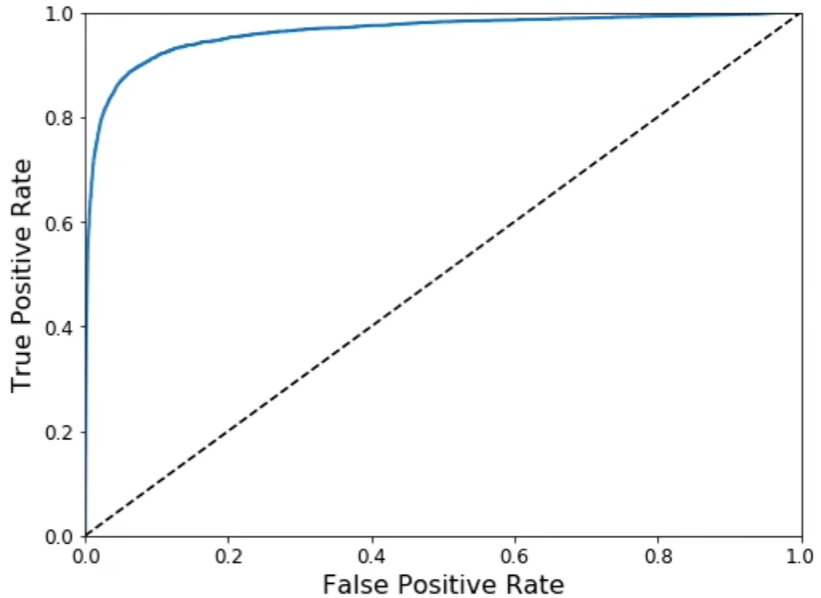
比较分类器的方法:测量曲线下面积(AUC),完美的AUC为1,纯随机分类器的AUD为0.5
编程基础
python
|
|
Numpy
广播机制:shape 不相等时会复制调整使运算通过
|
|
Pyplot
|
|
机器学习
类别
- 有监督学习:给定输入输出对训练,最终可通过输入预测输出【回归(拟合)、分类(边界)】
- 无监督学习:将未标记的数据自动分配到不同组【聚类、异常检测、推荐系统、降维】
- 强化学习
- 深度学习
优化方法
梯度下降
(Gradient Descent,GD)
根据梯度下降,多参数下可能获得代价函数的多个局部极小值,迭代次数自定义,沿梯度方向将增加损失函数值
$\begin{cases}w_j = w_j-\alpha \frac{\partial}{\partial w}J(w,b)\ b=b-\alpha\frac{\partial}{\partial b}J(w,b) \end{cases}$,$\alpha$为学习率,后面一项为 J 关于 w 和 b 的导数,同时更新 w 和 b
动量梯度下降——加速梯度下降
计算 dw 和 db 的滑动平均值 v ,更新权重时使得梯度下降更平滑
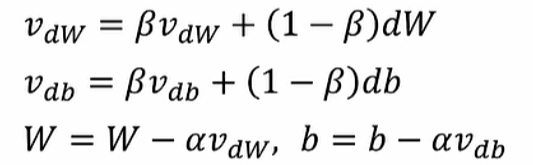
RMSprop算法——加速
均方根传递(Root Mean Square prop),当梯度下降震荡时,减少某 w 参数方向的震荡
$S_{dW}=\beta_2 S_{dW} + (1-\beta_2)dW^2\ W=W-\alpha \frac{dW}{\sqrt{S_{dW}}+\varepsilon}$
Adam算法
(Adaptive Moment estimation)自适应矩估计结合RMSprop和动量,对每个参数($w_i, b$)使用不同的学习率
默认:$\beta_1:0.9,\quad \beta_2: 0.999\quad \varepsilon: 10^{-8}$, $\alpha$ 需要调整
- 动量:$V_{dW}=\beta_1 V_{dW}+(1-\beta_1)d_W\quad V_{db}=\beta_1 V_{db}+(1-\beta_1)d_b$
- RMSprop:$S_{dW}=\beta_2 S_{dW} + (1-\beta_2)dW^2\quad S_{db}=\beta_2 S_{db} + (1-\beta_2)db^2$
- 偏差修正: $V_{dW}^{correct}=\frac{V_{dW}}{1-\beta_1^t}\quad V_{db}^{correct}=\frac{V_{db}}{1-\beta_1^t}\quad S_{dW}^{correct}=\frac{S_{dW}}{1-\beta_2^t}\quad S_{dW}^{correct}=\frac{S_{dW}}{1-\beta_2^t}$
- 更新参数:$W=W-\alpha\frac{V_{dW}^{correct}}{\sqrt{S_{dW}^{correct}}+\varepsilon}\quad b=b-\alpha\frac{V_{db}^{correct}}{\sqrt{S_{db}^{correct}}+\varepsilon}$
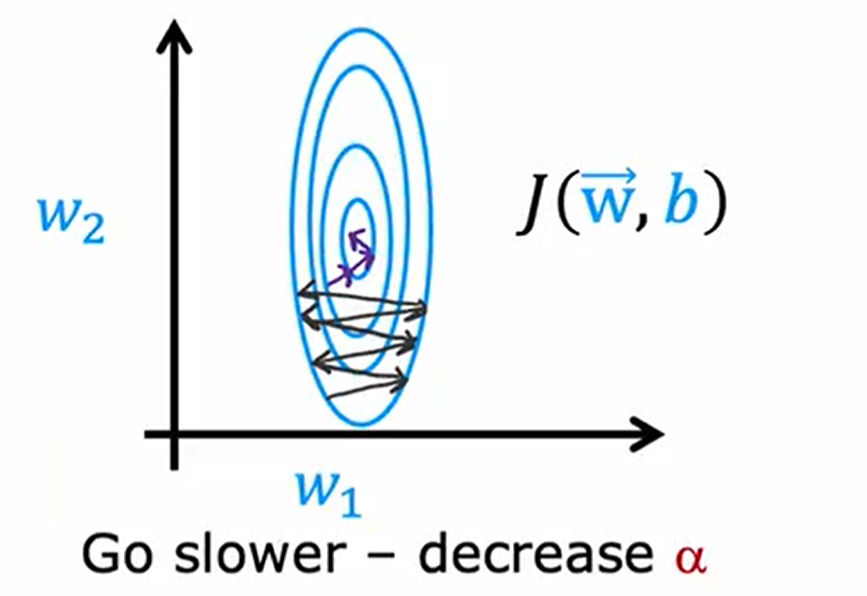
使用等高图绘制代价函数,由梯度下降从start到minimum,若每次参数移动方向基本一致,Adam将提高学习率,加快速度
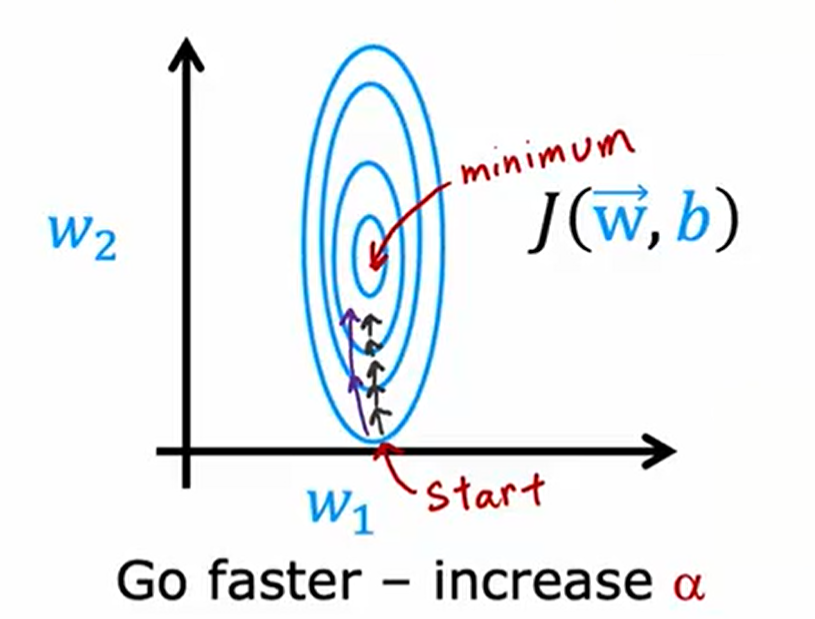
当梯度下降呈现下图形式,参数不断来回振荡,Adam将减少学习率,加快速度
|
|
机器学习策略
正交化
回归模型
线性回归
解决回归问题,预测一个连续型的因变量
线性回归模型:$f(x)=wx+b$【w: weight权重, b: bias偏置】
代价函数
Cost function,或平方误差成本(Squared error cost)函数:$J(w, b)=\frac{1}{2m}\cdot\sum_{i-1}^{m}(\hat y^{(i)} - y^{(i)})^2=\frac{1}{2m}\cdot\sum_{i-1}^{m}(f_{w,b}(x^{(i)}) - y^{(i)})^2$,找 w 和 b 使得$J(w,b)$最小,
步长/学习率
范围 [0, 1],对结果产生影响,从小选择
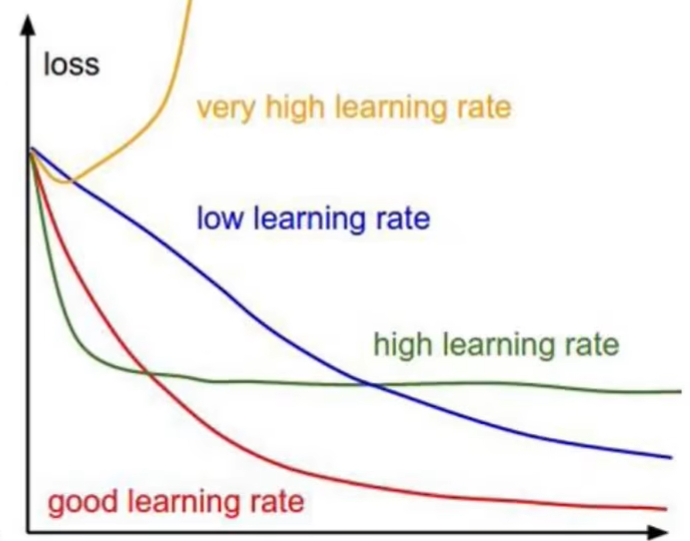
步长过小:收敛慢,花费时间长
步长过大:抖动幅度大,无法收敛或发散
学习率衰减
- mini-batch会产生噪声,使得最终无法收敛,所以尝试使学习率慢慢减少,则步长也慢慢减少,使得学习率开始高,后期低
- $\alpha=\frac{1}{1+d*t}\alpha_0$,d 为衰减率,t 为迭代数
- $\alpha=0.95^{t}\alpha_0\quad or \quad =\frac{k}{\sqrt{t}}\alpha_0$
过拟合
degree值过高可能会出现过拟合,表明模型过于贴合训练集,方差大
解决过拟合:可以增加训练集数;使用更少特征;正则化
L1 正则化为$\frac{\lambda}{2m}\sum_{j=1}^n|w_j|$
L2 正则化
用于解决过拟合,令模型选择更合适的$\theta$值,对权重参数用$\lambda$进行惩罚,减小参数大小,让权重参数尽可能平滑
若有 n 个参数 w ,对每个参数都进行惩罚,线性回归模型的代价函数变为:
$J(w, b)=\frac{1}{2m}\sum^m_{i=1}(f_{w,b}(x^{(i)})-y^{(i)})^2+\frac{\lambda}{2m}\sum^n_{j=1}w_j^2$,$\lambda\gt0$是正则化参数,第二项为正则化项
|
|
提早停止(Early stopping)
作图:随迭代次数 训练误差(递减) 或成本函数 及 交叉验证误差(先减后增),在表现最好时提前停止,解决过拟合
多元线性回归
多特征回归,即多 x 情况,若是存在$x_1,x_2$,则将会回归为一个平面
$x_j^{(i)}$表示:第 i 个测试示例中 特征 j 的值
模型描述
$Y=x_1\theta_1+x_2\theta_2$,已知大量 样本标签$Y$ | 特征$x_1,x_2$ | 权重参数$\theta_1,\theta_2$
拟合平面:$h_\theta(x)=\theta_0+\theta_1x_1+\theta_2x_2$,($\theta_0$是偏置值,微调平面位置)
补充一列$x_0=1$整合成矩阵形式——多元线性回归:$h_{\theta}(x)=\sum_{i=0}^n\theta_ix_i=\theta^Tx$
误差项
误差$\varepsilon$是真实值和预测值间的差异,对于每个样本,真实值=预测值+误差:$y^{(i)}=\theta^Tx^{(i)}+\varepsilon^{(i)}$
独立同分布
误差$\varepsilon^{(i)}$是独立同分布的,服从均值为0方差为$\theta^2$的高斯分布/正态分布
即$p(\varepsilon^{(i)})=\frac{1}{\sqrt{2\pi}\sigma}exp(-\frac{(\varepsilon^{(i)}-0)^2}{2\sigma^2})$
似然函数
消去误差$\varepsilon$得到概率:$p(y^{(i)}|x^{(i)};\theta)=\frac{1}{\sqrt{2\pi}\sigma}exp(-\frac{(y^{(i)}-\theta^Tx^{(i)})^2}{2\sigma^2})$
- 似然函数:多样本累乘,什么样的参数跟数据组合后恰好为真实值
$L(\theta)=\prod_{i=1}^mp(y^{(i)}|x^{(i)};\theta)$,
- 对数似然,将累乘法转换为加法
$logL(\theta)$
- 化简
$\sum_{i=1}^mlog\frac{1}{\sqrt{2\pi}\sigma}exp(-\frac{(y^{(i)}-\theta^Tx^{(i)})^2}{2\sigma^2})\=mlog\frac{1}{\sqrt{2\pi}\sigma}-\frac{1}{\sigma^2}\cdot\frac{1}{2}\sum_{i=1}^m(y^{(i)}-\theta^Tx^{(i)})^2$
- 目标:让似然函数越大越好,则使后面项(设为$J(\theta$)越小
$J(\theta)=\frac{1}{2}\sum_{i=1}^m(y^{(i)}-\theta^Tx^{(i)})^2$(最小二乘法)
- 求对$\theta$的偏导等于0
$\theta=(X^TX)^{-1}X^Ty$,此处X为行/列向量
使用梯度下降进行优化迭代
目标函数:$J(\theta,m)=\frac{1}{2m}\sum_{i=1}^m(y^{(i)}-\theta^Tx^{(i)})^2$,求偏导得到梯度方向,下降:向梯度反方向走,是指mini-batch 的大小,一般为2的幂数
- 批量梯度下降BGD:【易求得最优解,考虑所有样本,速度慢】
- $\frac{\partial J(\theta)}{\partial\theta_j}=-\frac{1}{m}\sum_{i=1}^m(y^i-h_{\theta}(x^i))x_j^i\quad\quad\quad\theta_j’=\theta_j+\frac{1}{m}\sum_{i=1}^m(y^i-h_{\theta}(x^i))x_j^i$
- 矩阵表示:$\frac{\partial J(\theta)}{\partial\theta_j}=\frac{2}{m}X^T\cdot(X\cdot\theta-y)$
- 随机梯度下降SGD:【每次随机找一个样本,迭代快,但不一定朝收敛方向,会在最小值周围徘徊】
- $\theta_j’=\theta_j+(y^i-h_{\theta}(x^i))x_j^i$
- 小批量梯度下降MBGD(Mini-batch):【每次更新选择小部分数据(如10个样本),实用,应对极大数据集】
- $\theta_j’:=\theta_j-\alpha\frac{1}{10}\sum_{k=i}^{i+9}(h_{\theta}(x^{(k)})-y^{(k)})x_j^{(k)}$,$\alpha$为学习率/步长
- 趋向于全局最小值,每步并非往最好方向,但计算成本低
特征放缩
将范围差异较大的不同特征范围调整到大致范围
- 基础归一化:除以最大值缩小值
- 均值归一化**:(var - 均值μ)** / (max_value - min_value) 转换为范围[-1, 1]
- Z分数归一化(Z-score normalization):(var - 均值μ) / 标准差σ 转换为范围[-1, 1]
多项式回归
- 通过修改多项式特征程度的大小,即不同的维度,来拟合不同的数据,拟合曲线
- 如:当有二维样本 a 和 b ,程度degree为2时的多项式特征将为$[1, a, b, a^2, b^2, ab]$,最终拟合后得到各个多项式特征变量前的参数,$y=\theta\cdot 1+\theta_1\cdot a+\theta_2\cdot b+\theta_3\cdot a^2+\theta_4\cdot b^2+\theta_5\cdot ab$
样本数量对结果影响
- 训练集大小极小时,测试集均方差高,训练集均方差低
- 随训练集大小增大,两均方差之差减小
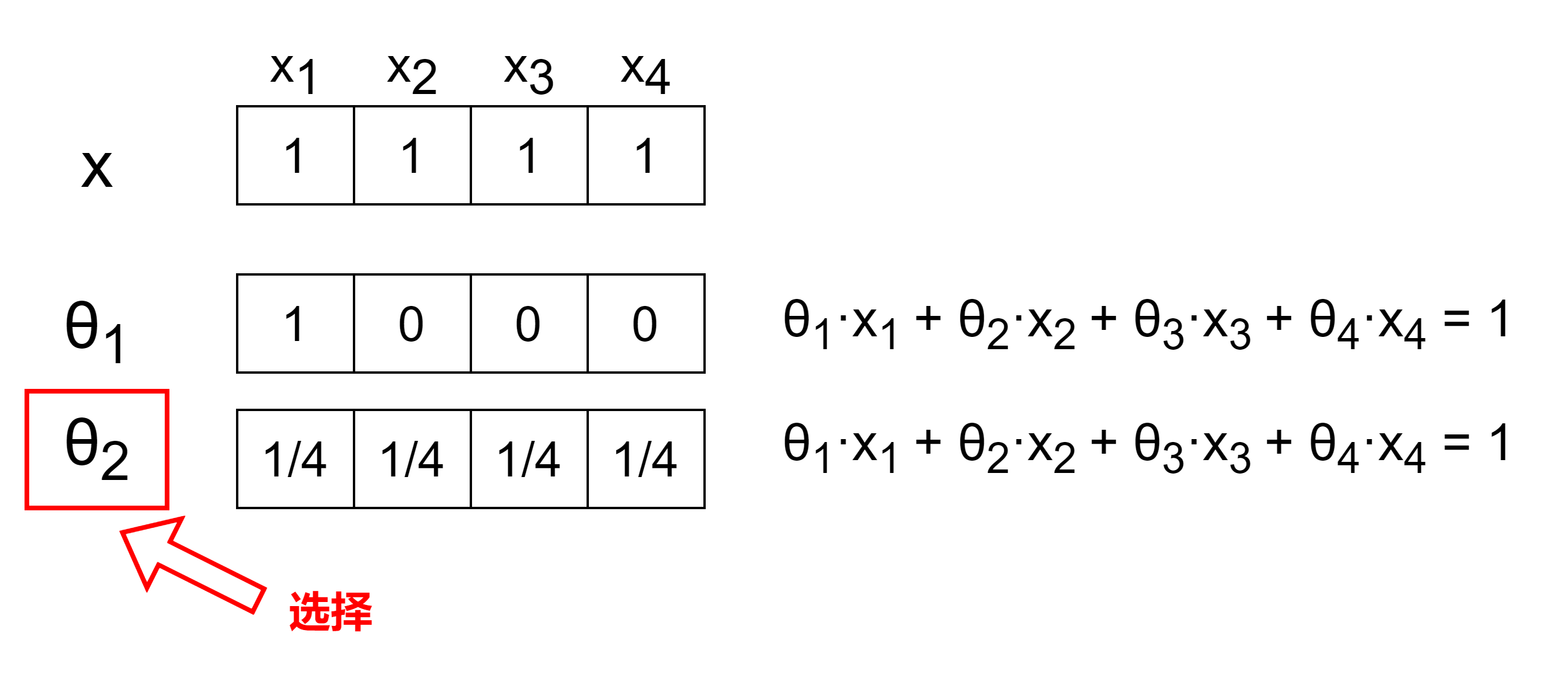
岭回归
- $J(\theta)=MSE(\theta)+\alpha \frac{1}{2}\sum_{i=1}^n\theta_i^2$
- 后一项中对每一个$\theta$量进行平方和计算并相加,以上图为例,1和2计算的结果分别为1和1/4,选择更小的值(即更加平稳的$\theta$),即$\theta_2$进行正则化处理
- 其中$\alpha$用于确定左右式的比重谁大,并且用于调整正则化程度
Lasso回归
- $J(\theta)=MSE(\theta)+\alpha \sum_{i=1}^n|\theta_i|$
- 后一项中对每一个$\theta$量绝对值计算并相加
分类算法
有监督问题
逻辑回归
logistic regression, 经典二元分类算法,逻辑回归的决策边界可以是非线性的,预测一个离散型的因变量
Sigmoid函数:
- $g(z)=\frac{1}{1+e^{-z}}=P(y=1|x)=\hat y$,z 可取任意实数,值域[0, 1]
- 线性回归中得到的预测值,可以映射到Sigmoid函数中完成值到概率的转换——分类
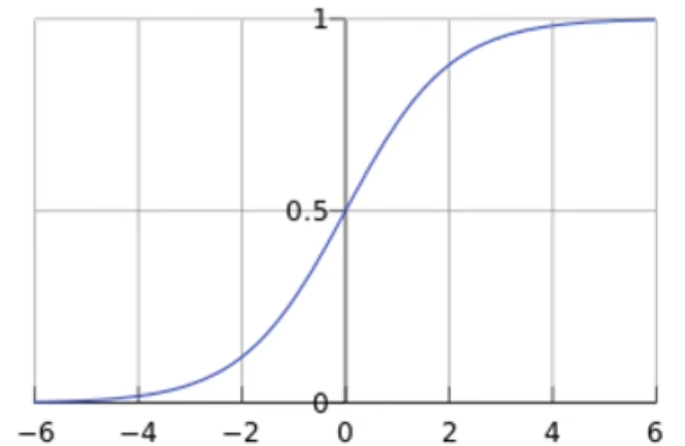
预测函数:$h_{\theta}(x)=g(\theta^Tx)=\frac{1}{1+e^{-\theta^Tx}}$,其中$z=\theta^Tx=\sum_{i=1}^n\theta_ix_i=\theta_0+\theta_1x_1+\cdots+\theta_nx_n$
注:$P(y=1|x;\theta)$中$\theta$表示其为影响该概率的参数
二分类任务:$\begin{cases}P(y=1|x;\theta)=h_{\theta}(x) \P(y=0|x;\theta)=1-h_{\theta}(x)\end{cases}$,整合:$P(y|x;\theta)=(h_{\theta}(x))^y(1-h_{\theta}(x))^{1-y}$
对于概率,设定一个阈值a,二分类**:概率大于等于a时,分类为1,当概率小于a时,分类为0**
决策边界
- 决策边界是将图形中的所有像素点代入分类器进行划分,假设划分为了0和1两种,则基于等高线划分为0高度和1高度,则可以绘制出决策边界
- 当得到参数$\theta$后,则可以代入到边界绘制函数中,将所有像素点进行预测画出决策边界(使用plt.contour函数)
a为阈值,由$\frac{1}{1+e^{-\theta^Tx}}=a$简化为$\frac{1-a}{a}=e^{-\theta^Tx}$
特殊时,当a=0.5时,上式为$e^{-\theta^Tx}=1=e^0$,即$z=-\theta^Tx=0$,此时为一个决策边界,二维下为直线,多维下为曲线,即等高线
非线性决策边界
使用多项式程度(polynomial_degree)来对特征值进行非线性变化
用多项式线性回归的式子替代sigmoid函数中的 z 后通过 z = 1 得出决策边界
代价函数
平方误差代价函数不适合逻辑回归,会导致梯度下降时有多个局部最低点
定义损失函数
$$L(f_{w,b}(x^{(i)}), y^{(i)})=\begin{cases}-log(f_{w,b}(x^{(i)}))\quad y^{(i)}=1\\ -log(1-f_{w,b}(x^{(i)}))\quad y^{(i)}=0\end{cases}$$
其中f(x)是sigmoid函数,所以取值[0, 1]
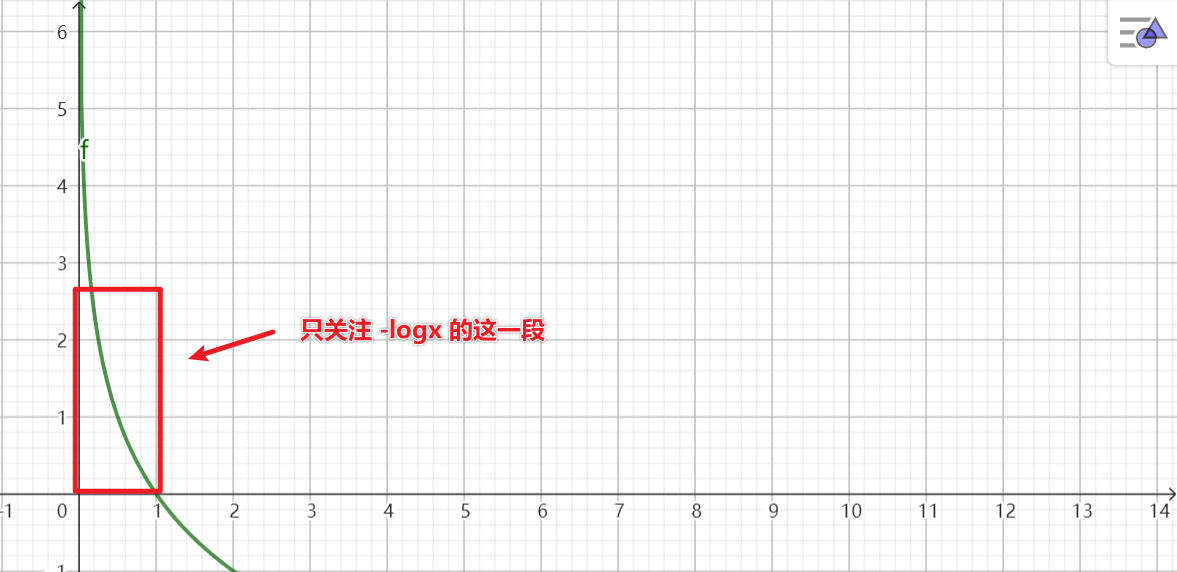
预测值接近1时,损失最低,越接近0,损失越高
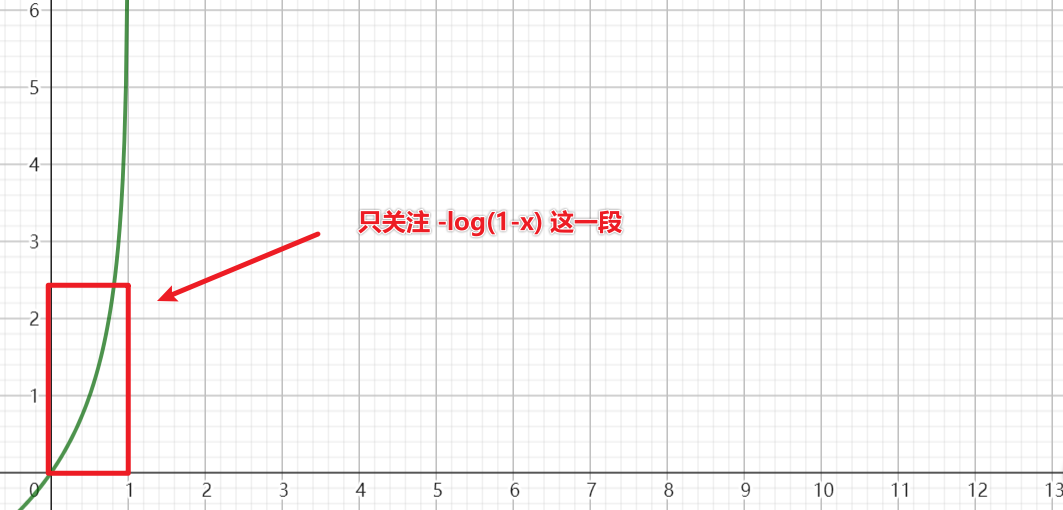
预测值接近1时,损失越高,越接近0,损失最低
损失函数合并为:$L(f_{w,b}(x^{(i)}), y^{(i)})=-y^{(i)}log(f_{w,b}(x^{(i)}))-(1-y^{(i)})log(1-f_{w,b}(x^{(i)})$
即此时代价函数为:$J(w,b)=\frac{1}{m}\sum^m_{i=1}L(f_{w,b}(x^{(i)}), y^{(i)})\ =-\frac{1}{m}\sum^m_{i=1}[y^{(i)}log(f_{w,b}(x^{(i)}))+(1-y^{(i)})log(1-f_{w,b}(x^{(i)}))]$,二元分类
- 似然函数:$L(\theta)=\prod_{i=1}^mP(y_i|x_i;\theta)=\prod_{i=1}^m(h_{\theta}(x_i))^{y_i}(1-h_{\theta}(x_i))^{1-y_i}$
- 对数似然:$l(\theta)=logL(\theta)=\sum_{i=1}^m(y_ilogh_{\theta}(x_i)+(1-y_i)log(1-h_{\theta}(x_i)))$
- 梯度上升求最大值,引入$J(\theta)=-\frac{1}{m}l(\theta$转换为梯度下降任务
- 求偏导:$\frac{\partial}{\partial\theta_j}J(\theta)=\cdots=-\frac{1}{m}\sum_{i=1}^m(y_i-g(\theta^Tx_i))x_i^j$
- 参数更新:$\theta_j’:=\theta_j-\alpha\frac{1}{m}\sum_{i=1}^m(h_{\theta}(x_i)-y_i)x_i^j$
正则化将代价函数变为:$J(w,b)-\frac{1}{m}\sum^m_{i=1}[y^{(i)}log(f_{w,b}(x^{(i)}))+(1-y^{(i)})log(1-f_{w,b}(x^{(i)}))]+\frac{\lambda}{2m}\sum^n_{j=1}w_j^2$
多分类逻辑回归
思路:将多分类转换为多次二分类,每次分为2类筛选出其中1类,n分类即进行n次二分类,以概率值进行分类
分类问题的损失函数:
损失值可以通过作图观察到随着迭代次数增加,逐渐减小趋于稳定
- 根据$l(\theta)=logL(\theta)=\sum_{i=1}^m(y_ilogh_{\theta}(x_i)+(1-y_i)log(1-h_{\theta}(x_i)))$计算
- 需要借助$f(x)=|logx|$来计算,离1越远损失越大
Softmax回归
多类别分类(multi class classification)——Logistic回归的推广
Softmax计算概率:
$\hat P_k=\sigma(s(x))_k=\frac{exp(s_k(x))}{\sum_{j=1}^Kexp(s_j(x))}$,将不同组的得分值 s 进行指数化来使得差异更大
假设四个输出:
$z_1=w_1\cdot x + b_1\\ z_2=w_2\cdot x + b_2\\ z_3=w_3\cdot x + b_3\\ z_4=w_4\cdot x + b_4$,$a_i=\frac{e^{z_i}}{e^{z_1}+e^{z_2}+e^{z_3}+e^{z_4}}=P(y=i|x)$
损失函数
$loss(a_1, \cdots, a_N, y)=\begin{cases}-\log{a_1}\quad if\,y=1\\ -\log{a_2}\quad if\,y=2\\ \quad\vdots\\ -\log{a_N}\quad if\,y=N\end{cases}$,使用-log函数来使得概率越接近 **1 ,**损失函数值越小
损失函数(交叉熵):$J(\theta)=-\frac{1}{m}\sum_{i=1}^m\sum_{k=1}^Ky_k^{(i)}log(\hat p_k^{(i)})$
运用到神经网络:输出层将需要 N 个神经元,以分为 N 个类别,Softmax激活功能使得$a_i$与$z_1 \cdots z_N$所有值相关,区别于logistic回归:$a_i$只与$z_i$有关
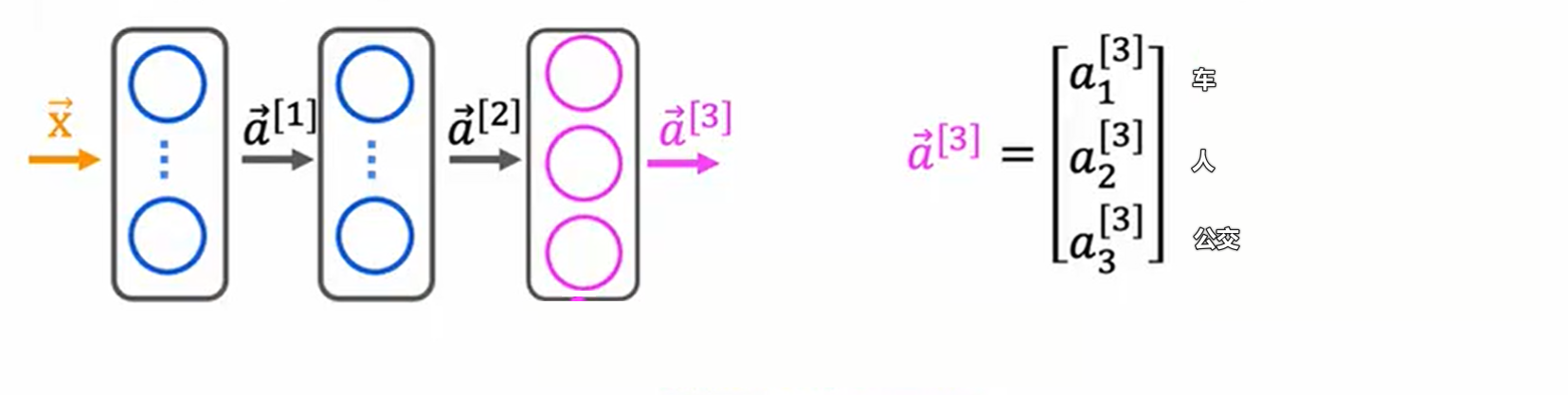
多标签分类(multi label classification)——输入单图像,判断是否有行人,是否有车,是否有公交,向量[1 0 1]
KNN算法
K-近邻算法:非参数、有监督的分类回归算法,K为奇数
解决:给定一个测试数据,若离它最近的K个训练数据大多都属于某一类别,则认为该测试数据也属于该类别
计算流程:
- 计算已知类别数据集中点与当前点距离,并排序
- 选取与当前点距离最小的K个点
- 确定前K个点所在类别的出现概率
- 返回出现频率最高的类别作为当前点预测分类
分析:
- 无需训练集,计算复杂度与训练集文档数目成正比O(n)
- K值选择、距离度量、分类决策规则是三个基本要素
- 当对图像进行分类时导致以背景为主导了,而主体才应该为主要成分
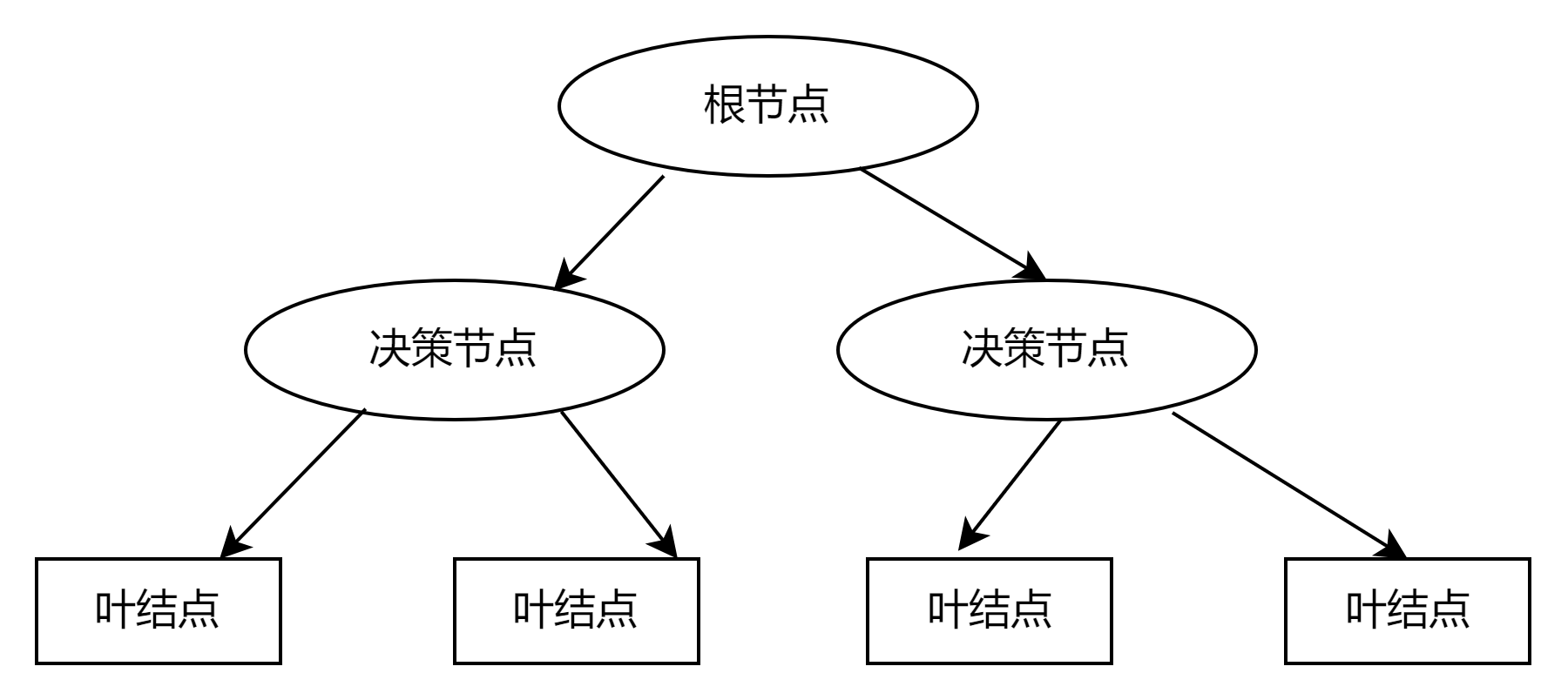
决策树
- 可以用于分类和回归,有监督算法
- 根结点(第一个选择点)到叶子结点(最终决策结果)
- 训练阶段构造树,测试阶段跟随树走一遍,适用于电子表格/结构化数据,不适用于非结构化数据:图像、音频、文本
选择决策结点的先后顺序,使用熵的原理,最大化纯度
熵
测量纯度,衡量标准,随机变量不确定性的度量
公式:各个的概率都要算,i个种类,$H(X)=-\sum p_i\cdot \log_{2} p_i,,,,i=1,2,\cdots,n$,log函数使得概率pi越靠近1,值越小
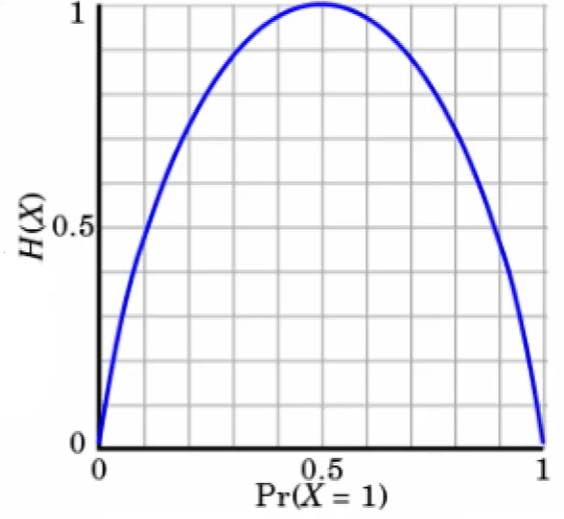
当概率为1或0时纯度最高,熵最小
信息增益原理:特征值X使得类Y的不确定性减少的程度,熵减
以分类猫狗为例,信息增益:$H(p_1^{root})-(w^{left}H(p_1^{left})+w^{right}H(p_1^{right}))$
|
|
- 计算根结点类别的熵值$H'$
- 计算所有特征值熵值:$H(i)=\sum p_j\cdot H(X)$,$p_j$为特征值取各个值时的概率,熵值为特征值各个取值的熵
- 获得信息增益:$a=H’-H(i)$,取最大值作为第一个决策点
- 继续计算剩下的熵值依次选取决策点
离散特征值:输入样本矩阵中不同类可用0/1编码代替特征
连续特征值:离散化,如何取分界点,使用贪婪算法对连续值进行切割二分,然后计算信息增益,选最大值
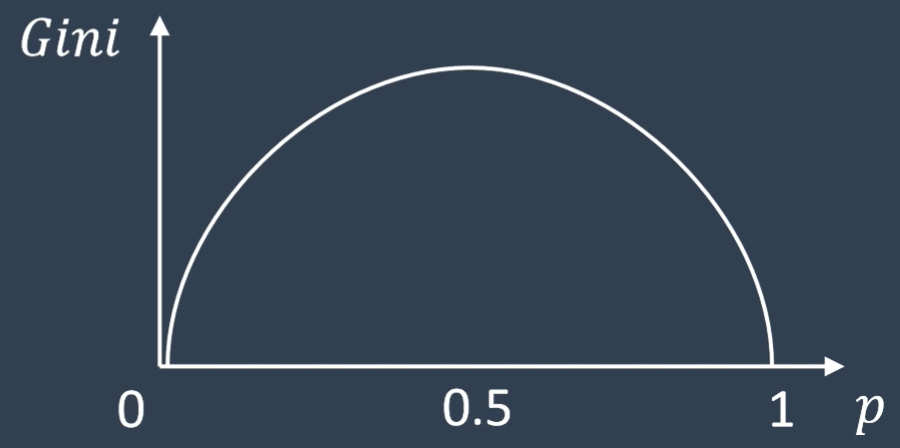
GINI系数
$Gini(p)=\sum^K_{k=1}p_k(1-p_k)=1-\sum_{k=1}^Kp_k^2$,选取GINI系数最小的来构建优先决策节点
回归树
决策树推广为回归算法——预测值:使用最终构建好的叶子结点中训练集数据的平均值预测
选择决策点:
- 将信息增益公式中计算熵值更换为计算决策分裂完的子集中预测数据值的平均方差
- 根结点最初熵值换为原始数据的总方差
剪枝策略
- 决策树过拟合风险很大
- 预剪枝:边建立决策树边剪枝,限制深度、叶子结点数、叶子结点样本数、信息增益量等
- 后剪枝:建立完决策树后剪枝,通过一定衡量标准:$C_{\alpha}(T)=C(T)+\alpha\cdot|T_{leaf}|$,叶子结点个数$T_{leaf}$,C函数:Gini值乘数量
- 分别计算分裂前和分裂后的损失值,若剪完后损失值减小则进行剪枝
ID3
- 信息增益
- ID3倾向于选择取值较多的属性作为节点
过程:
输入:训练数据集D,特征集A,阈值$\epsilon$
输出:决策树T
**(1)**若 D 中所有实例都属于同一个类 $C_k$ ,则 T 为单节点树,将 $C_k$ 作为该节点的类标记,返回 T
**(2)**若 A=∅ ,则 T 为单节点树,并将 D 中的实例数最大的类 $C_k$ 作为该节点的类标记,返回 T
**(3)**否则,计算特征 A 对数据集 D 的信息增益,选择信息增益最大的特征 $A_g$
**(4)**如果 $A_g$ 的信息增益小于阈值 $\epsilon$ ,则置 T 为单节点树,并将 D 中实例数最大的类 $C_k$ 作为该节点的类标记,返回 T【剪枝】
(5)否则,对 $A_g$ 的每一可能值 $a_i$ 依 $A_g=a_i$ 将 D 划分为若干非空子集 $D_i$ ,将 $D_i$ 中实例数最大的类作为标记,构建子节点,由节点及其子节点构成树 T ,返回 T
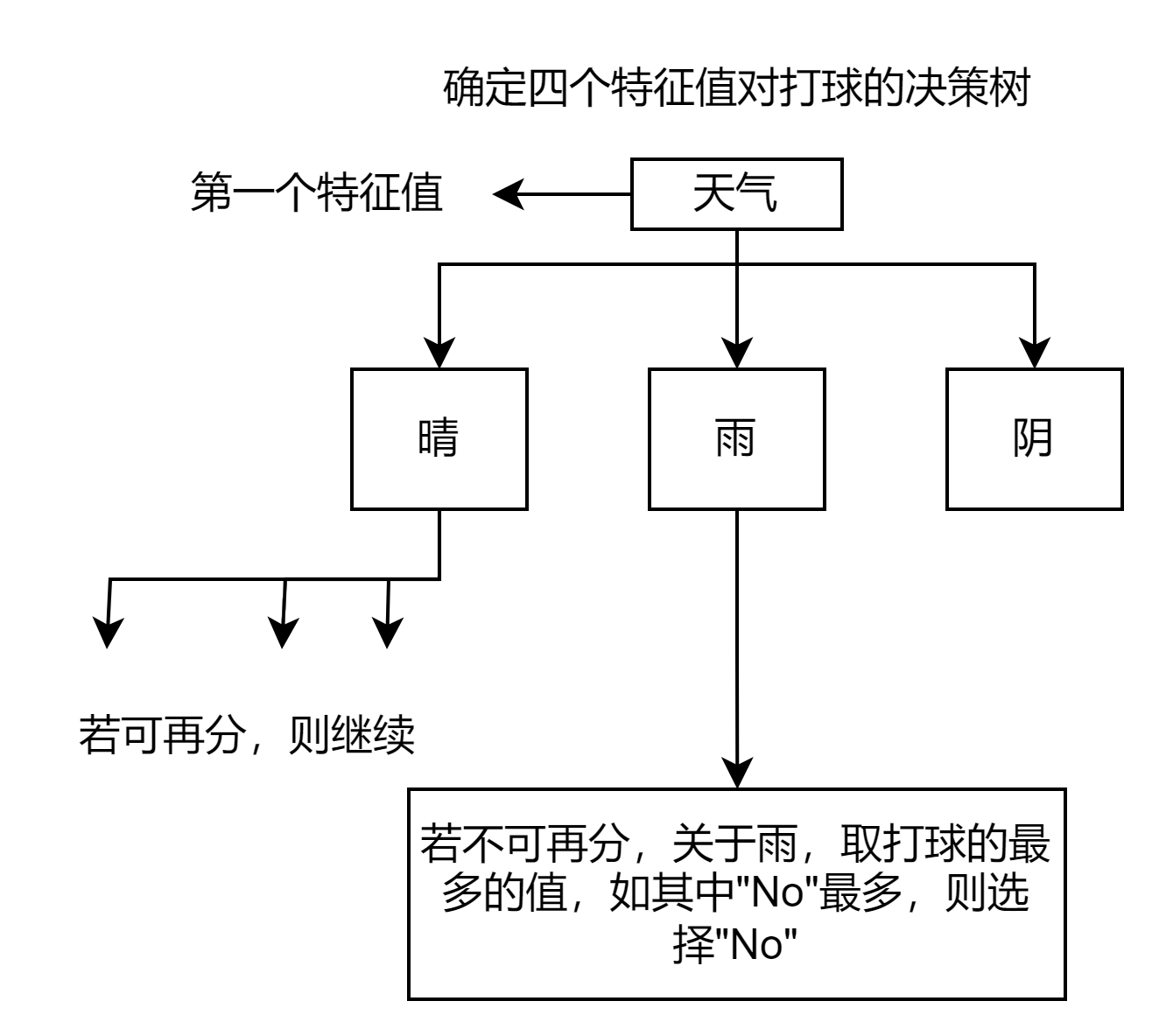
**(6)**对第 i 个子节点,以 $D_i$ 为训练集,以 $A-{A_g}$ 为特征集,递归调用 (1)~(5) ,得到子树 T ,返回 T
C4.5
- 举例:当有一行特征为ID编号,从0~K,将会导致ID的熵为0,而ID并不与结果相关,即信息增益不适合解决特征中及其稀疏的情况
- 解决ID3问题,考虑自身熵,使用信息增益率=信息增益/属性熵
- 当属性有很多值时,虽然信息增益变大,但相应属性熵也会变大,所以信息增益率计算不会很大
CART
使用GINI系数作为衡量标准
集成学习
分类
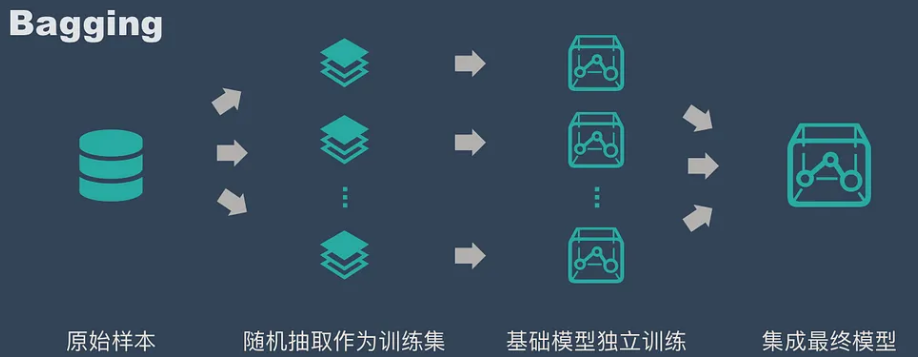
- **Bagging:并联,**训练多个分类器取平均,$f(x)=\frac{1}{M}\sum_{m=1}^Mf_m(x)$
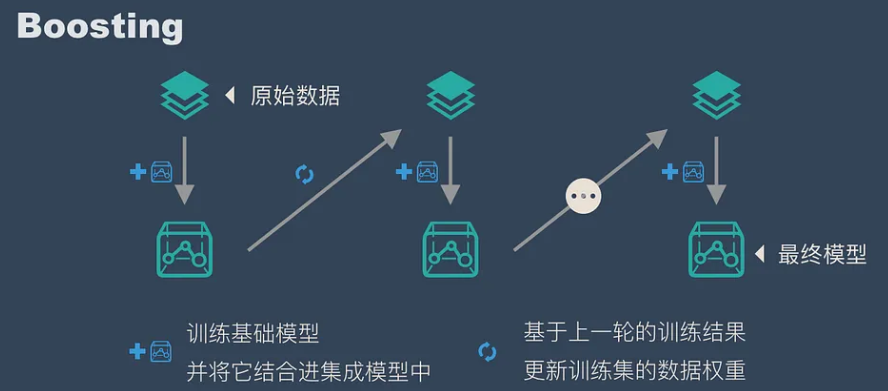
- Boosting:串联,从弱学习器开始加强,通过加权来训练,大部分情况下,经过 boosting 得到的结果偏差(bias)更小,$F_m(x)=F_{m-1}(x)+argmin_h\sum_{i=1}^nL(y_i,F_{m-1}(x_i)+h(x_i))$
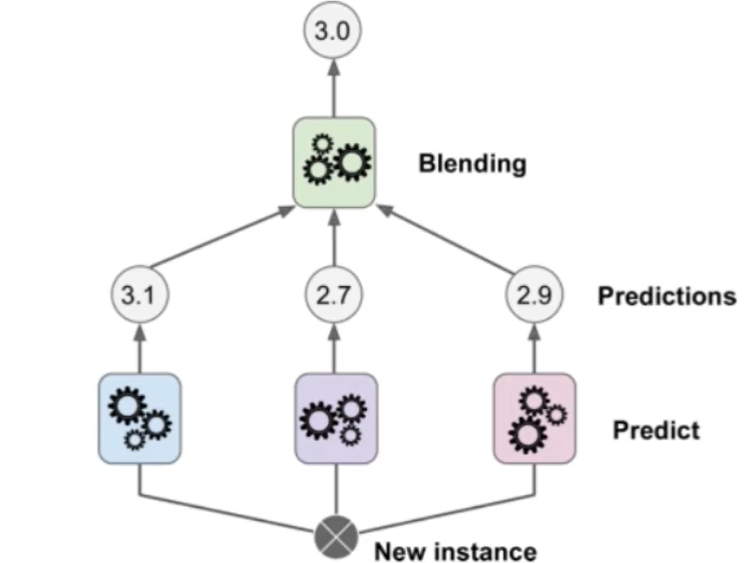
- **Stacking:堆叠,**聚合多个分类或回归模型(KNN, SVM, RF),第一阶段得出各自结果,第二阶段用前一阶段结果训练
随机森林
- RF,由于决策树对数据轻微变化敏感
- 属于Bagging模型
- 随机:
- 数据随机采样:原始数据中进行放回抽样(取得值可能重复),构造新的训练集
- 特征选择随机:每个节点,选择随机子集k(<n, or $k=\sqrt n$)个特征
- 分别训练多个相同参数的模型,预测时将所有模型结果再进行集成
- 森林:多个决策树并行放一起
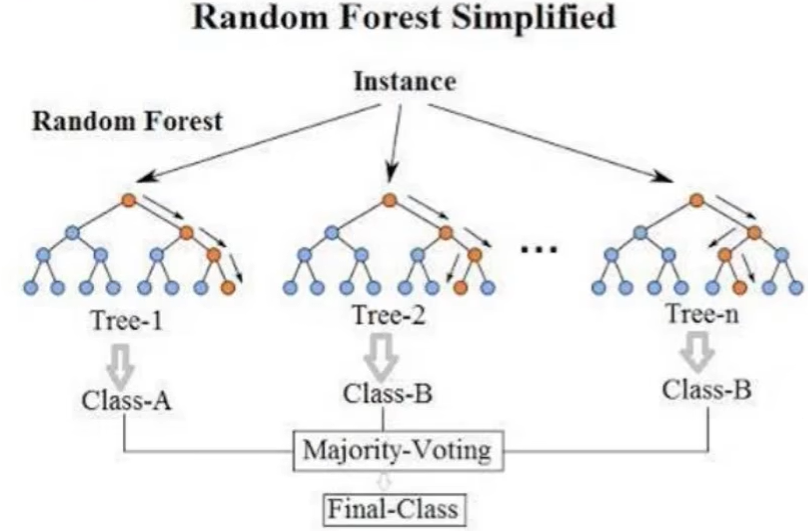
能处理高维,可解释性强,并行化速度快,能给出哪些特征值重要
投票策略
- 软投票:各自分类器的概率值进行加权平均,要求各个分类器都有概率值
- 硬投票:直接用类别值,少数服从多数
OOB策略
Out of Bag,在随机抽取的样本中,剩余的样本可以作为验证集进行验证
XGBoost
- eXtreme Gradient Boosting,极端梯度提升,属于boosting模型
- 在下一轮时,随机抽样更大概率选择前一轮预测出错的样本,每个样本都有权重
|
|
AdaBoost
- 属于boosting模型
- 每一轮训练都提升那些错误率小的基础模型权重,同时减小错误率高的模型权重
- 每一轮改变训练数据的权值或概率分布,通过提高那些在前一轮被弱分类器分错样例的权值,减小前一轮分对样例的权值
Gradient Boosting
- 串行地生成多个弱学习器,每个弱学习器的目标是拟合先前累加模型的损失函数的负梯度
- 使加上该弱学习器后的累积模型损失往负梯度的方向减少
- 且用不同的权重将基学习器进行线性组合,使表现优秀的学习器得到重用
提前停止策略
在验证误差不再提升后,提前结束训练而不是一直等待验证误差到最小值
聚类算法
无监督问题:不存在标签,将相似的东西分到一组
K-MEANS
概念
- 需指明簇的个数K
- 质心:均值,向量各维取平均
- 距离:用欧几里得距离和余弦相似度(先标准化)
- 优化目标:$min\sum_{i=1}^K\sum_{x\in C_i}dist(c_i,x)^2$
- 代价函数/失真函数:$J(c^{(1)},\cdots,c^{(m)},\mu_1,\cdots,\mu_K)=\frac{1}{m}\sum_{i=1}^m||x^{(i)}-\mu_{c^{(i)}}||^2$
- 应用举例:x轴身高,y轴体重,离散点类似线性增加,可用于分类小中大三个簇,K越多,分类越细
工作过程
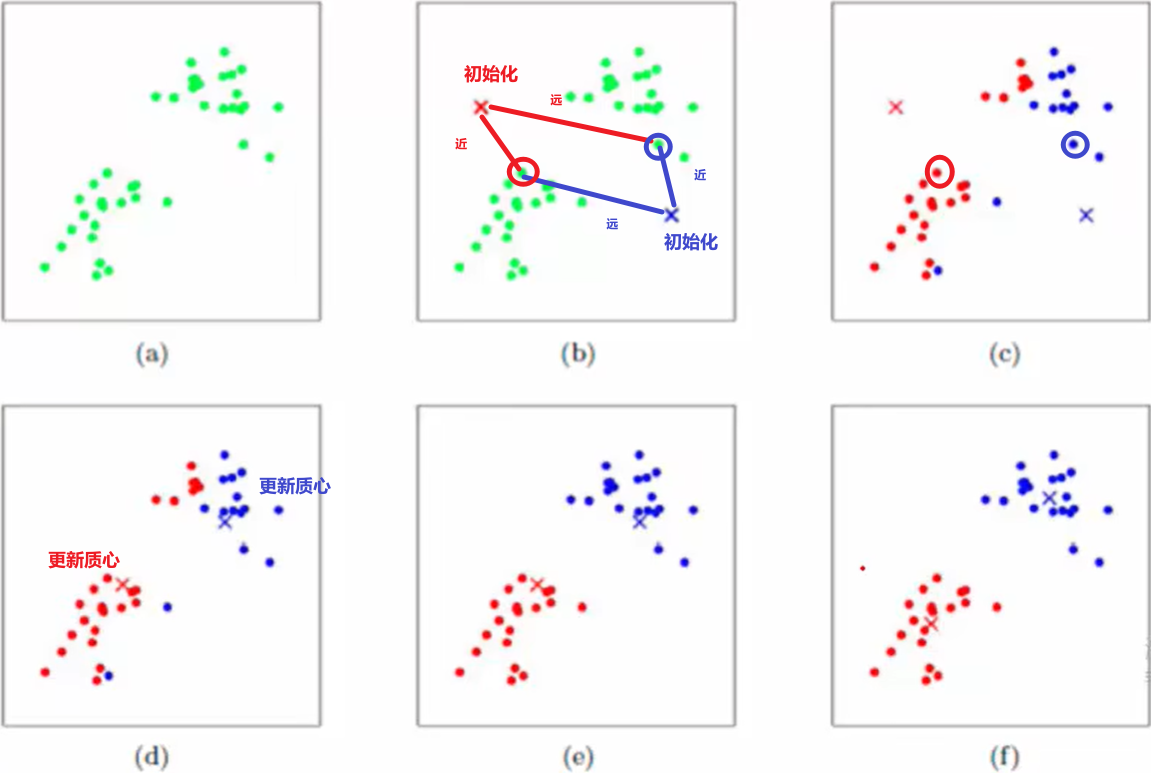
- 优势:简单,快速,适合常规数据集
- 劣势:难确定K,复杂度与样本呈线性关系,难发现形状复杂的簇,初始化不当会导致陷入局部最优值
Elbow method-肘法:x轴K的值,y轴代价函数值,看图像是否有斜率突变的情况
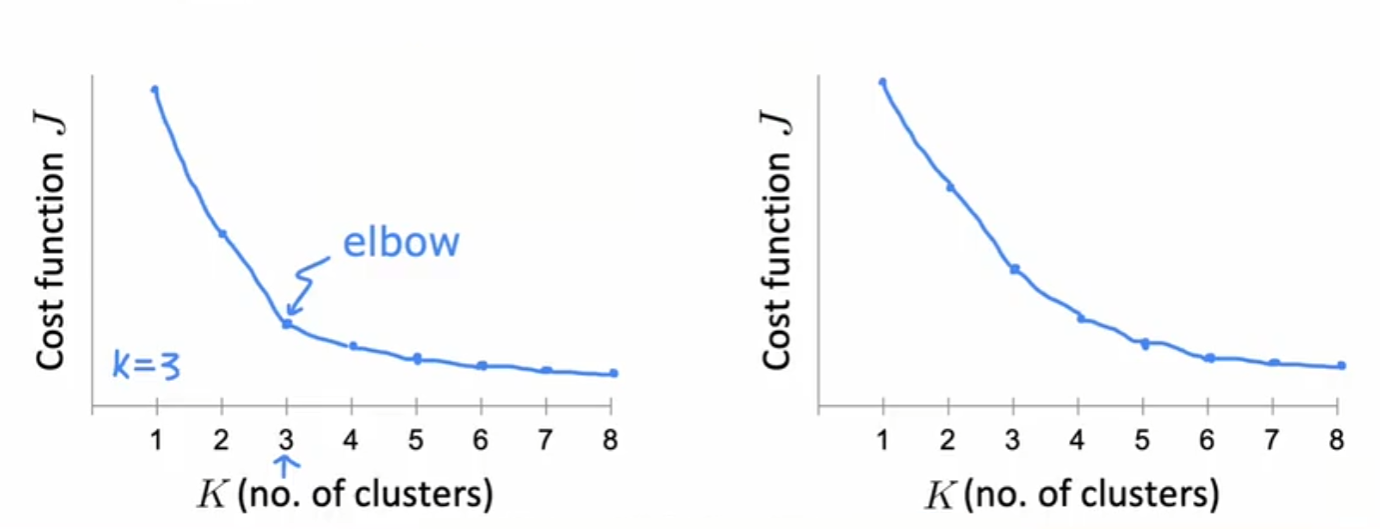
评估指标
Inertia指标
- 定义**:每个样本到质心的距离**
- 可用于取合适K值(簇的个数)
- 随K增大,Inertia指标一定下降,找指标下降过程中拐点处的K值【此处拐点指前后的变化率浮动大】
- 仅供选择,不一定最准确
轮廓系数
- 簇内不相似度$a_i$:样本i到同簇其他样本的平均距离
- 簇间不相似度$b_i$:计算样本i到其他簇Cj的所有样本的平均距离$b_{ij}$,$b_i=min{b_{i1},b_{i2},\cdots,b_{ik}}$
想让$a_i$越小,$b_i$越大,则有:
$s(i)=\frac{b(i)-a(i)}{max{a(i),b(i)}}=\begin{cases}1-\frac{a(i)}{b(i)},\quad a(i)\lt b(i)\\0,,,,,\quad\quad\quad a(i)=b(i)\\\frac{b(i)}{a(i)}-1,\quad a(i)\gt b(i)\end{cases}$
结论:
- $s_i$接近1,说明样本i聚类合理
- $s_i$接近-1,说明样本i更应该分类到其他簇
- $s_i$近似0,说明样本i在2个簇边界上
DBSCAN
(Density-Based Spatial Clustering of Applications with Noise)
基本概念
- 核心点:某个点的密度达到算法设定的阈值 —— r邻域内点的数量≥ 阈值 minPts
- $\epsilon$-邻域的距离阈值:设定的半径 r
- 直接密度可达:若点 p 在点 q 的 r邻域内,且 q 是核心点,则 p-q 直接密度可达
- 密度可达:一个点的序列$q_0,q_1,\cdots,q_l$,对任意$q_i-q_{i-1}$是直接密度可达的,则称从$q_0$到$q_k$密度可达,“传播”
- 边界点:每一个类的非核心点
- 噪声点:不属于任何一个类簇的点,从任何一个核心点出发都密度不可达
- K-距离:给定数据集$P={p(i);,i=0,1,\cdots,n}$,p(i)到P中其他点的距离并且从小到大排序,分别为d(k),k=1,2,3,….,称为K-距离
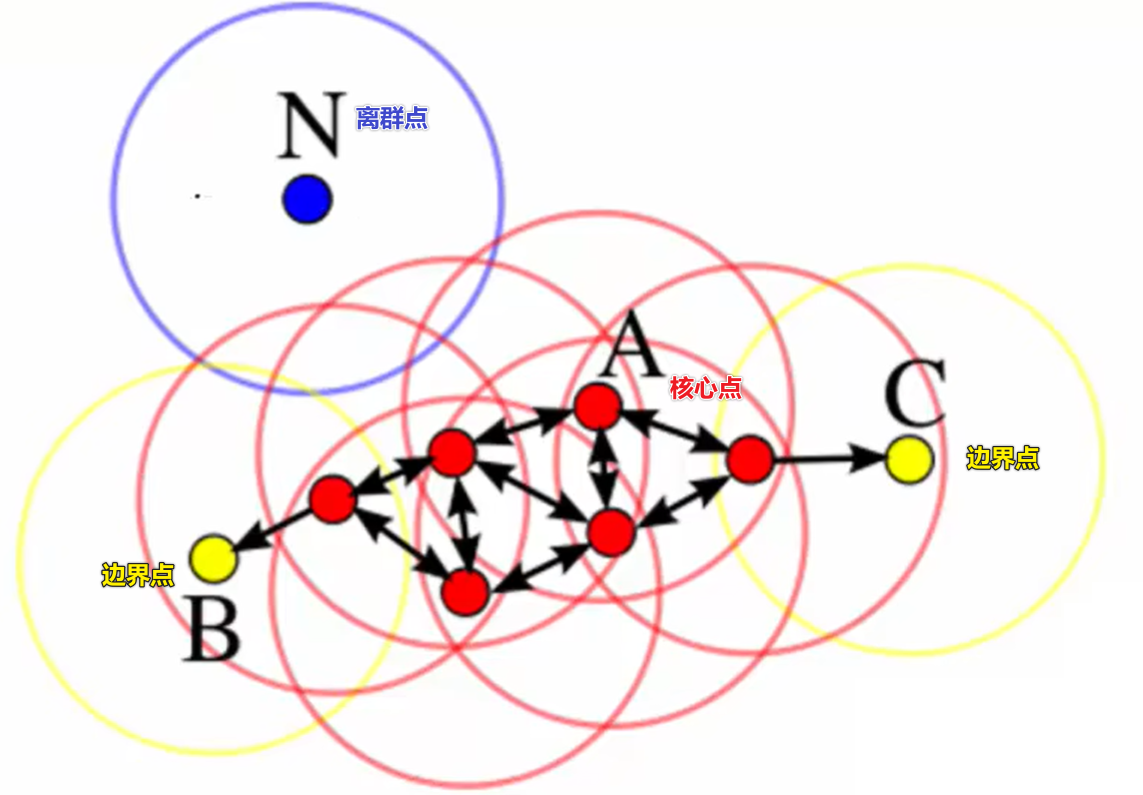
工作流程
输入**:数据集**$D$、指定半径$\epsilon$、密度阈值$MinPts$
- 所有对象标记 unvisited
- 随机选择一个对象p,标记为visited
- 若 p 的$\epsilon$-邻域至少有 MinPts 个对象[a, b, c, d…]:创建新簇 C,p 加入 C 中
- 令 N 为 p 的$\epsilon$-邻域中的对象集合,遍历[a, b, c, d…]中每个点 p’ 【不断扩张的过程】:
- 若 p’ 为unvisited,标记为visited;
- 若 p’ 的$\epsilon$-邻域至少有 MinPts 个对象,将这些对象加入N
- 若 p’ 不是任何簇的成员,加入 C 中
- 输出C**(若不满足3条件,则为噪声点)**
- 接着继续找标记为unvisited的对象,重复3-5
- 直到没有标记为unvisited的对象
参数选择:
- 选择半径$\epsilon$:根据K-距离找突变的点
- 选择 MinPrs:K-距离中的 k 值,一般取小一点
优点:擅长找离群点,可分任意形状
劣势:高维数据困难,参数难以选择,效率低
异常检测
- Anomaly Detection,非线性检测,无监督学习
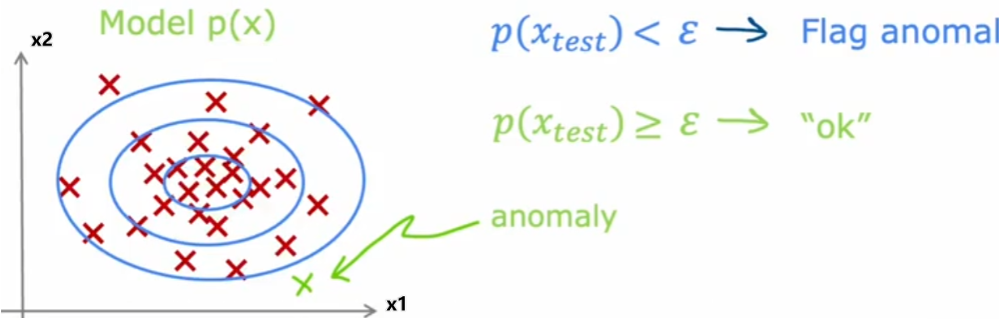
- 数据集:${x^{(1)},x^{(2)},\cdots,x^{(m)}}$,每个$x_i$有 m 个特征$x=[x_1,x_2,\cdots,x_n]$,检测$x_{test}$,以二维即2个特征为例,x轴为x1,y轴为x2,可作图观察点分布
密度估计:越内部概率越高,越外圈概率越低,计算$x_{test}$概率
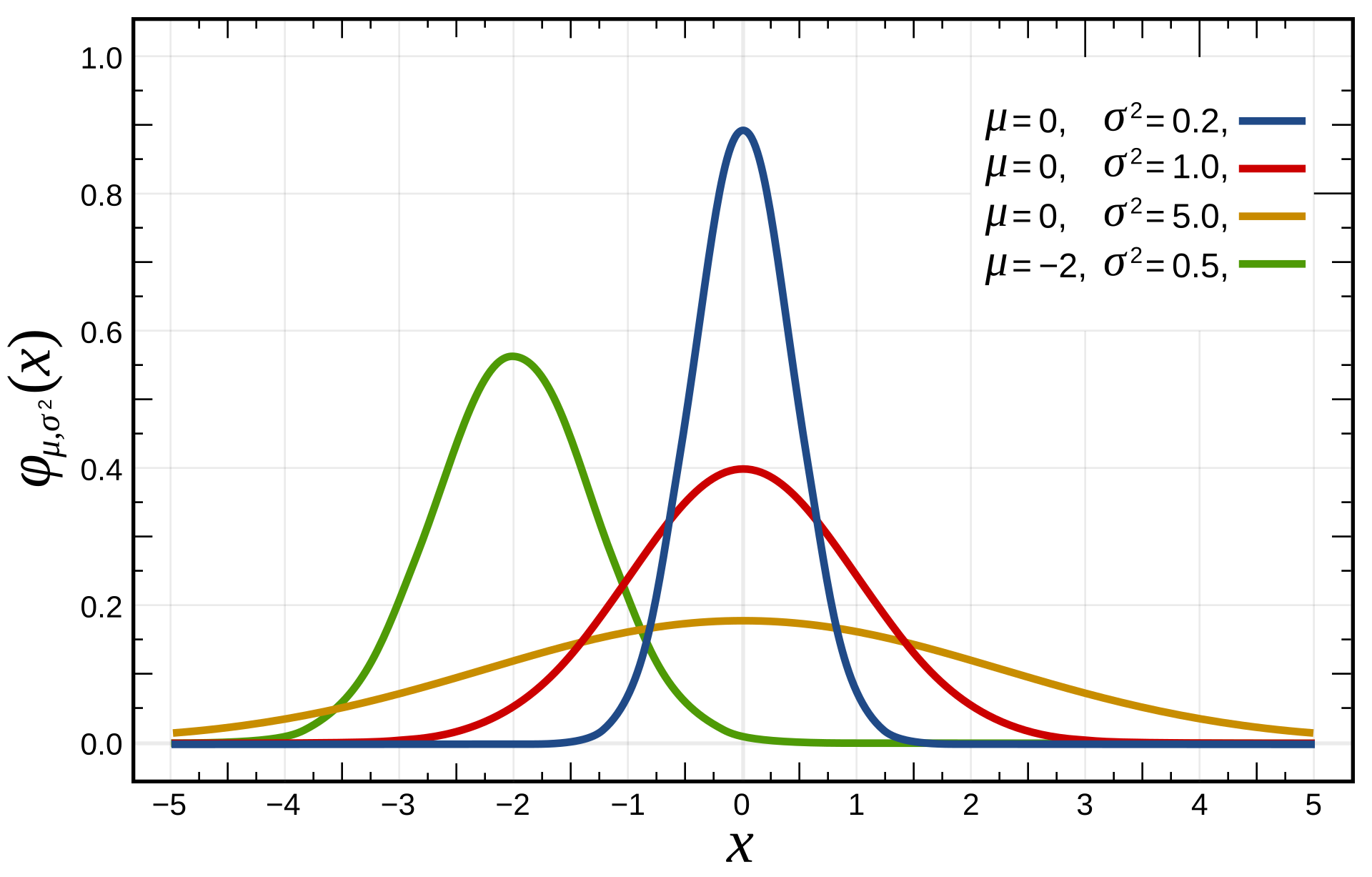
高斯/正态分布
$p(x)=\frac{1}{\sqrt{2\pi}\sigma}e^{\frac{-(x-\mu)^2}{2\sigma^2}}$,轴线与$\mu$有关,宽度与$\sigma$有关
算法实现
- 选择n个特征的$x_i$
- 通过数据集计算:$\mu_j=\frac{1}{m}\sum_{i=1}^mx_j^{(i)}$和$\sigma_j^2=\frac{1}{m}\sum(x_j^{(i)}-\mu_j)^2$
- 给定待测试 x ,计算$p(x)=\prod_{j=1}^np(x_j;\mu_j,\sigma^2_j)=\prod_{j=1}^n\frac{1}{\sqrt{2\pi}\sigma_j}e^{\frac{-(x_j-\mu_j)^2}{2\sigma_j^2}}$,$p(x)\lt \varepsilon$则异常e
评估方法
加入标签0正常1异常,分为训练集、交叉验证集、测试集,训练集只测试正常数据;交叉验证集加入少许异常数据预测01,混淆矩阵评估来调整参数及$\varepsilon$;测试集也有少许异常数据测试来公平判断系统
与有监督的区别:异常检测中的异常不断变化可能与训练集中不一致,有监督学习区别的垃圾邮件大多与训练集中相似
特征选择
- 非高斯特征可通过计算转化为高斯性质:$log(x+c)$,$x^{\frac{1}{c}}$,特征图的x轴为索引,y轴为特征的值
- 添加特征可以使用原有特征的比率来使得更容易进行异常检测
推荐系统
a-d四个人对m1-m5电影评分数据
| Movie | a | b | c | d | x1(浪漫电影) | x2(动作电影) |
|---|---|---|---|---|---|---|
| m1 | 5 | 5 | 0 | 0 | 0.9 | 0 |
| m2 | 5 | ? | ? | 0 | 1.0 | 0.01 |
| m3 | ? | 4 | 0 | ? | 0.99 | 0 |
| m4 | 0 | 0 | 5 | 4 | 0.1 | 1.0 |
| m5 | 0 | 0 | 5 | ? | 0 | 0.9 |
- $n_u$人数,$n_m$电影数,$r(i,j)=1/0$用户 j 是否给电影 i 打分,$y^{(i,j)}$用户 j 对 i 的打分值,$w^{(j)},b^{(j)}$用户 j 的参数,$x^{(i)}$电影 i 的特征向量
- 对 a(j) 预测第 3(i) 个电影:假设已得出了 w 和 b
- $w^{(j)}\cdot x^{(i)}+b^{(j)}=[5\quad 0]\cdot \begin{bmatrix}0.99\\ 0\end{bmatrix}+0=4.95$
成本函数
对单个用户 j
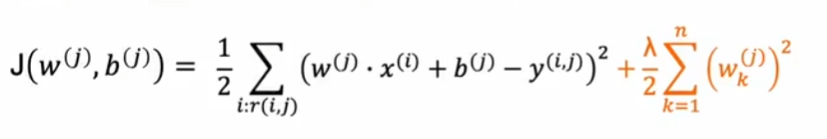
对所有用户
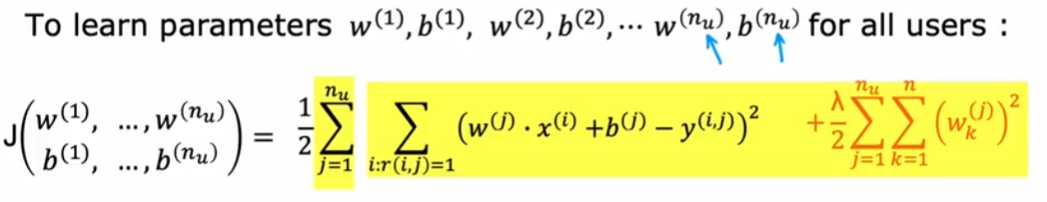
假设已知参数w和b,x1和x2特征值未知,可以通过成本函数推测特征值
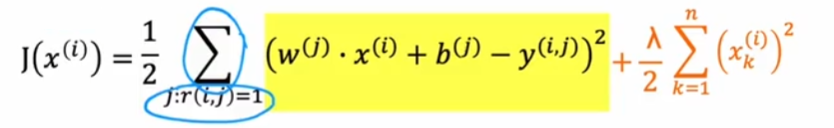
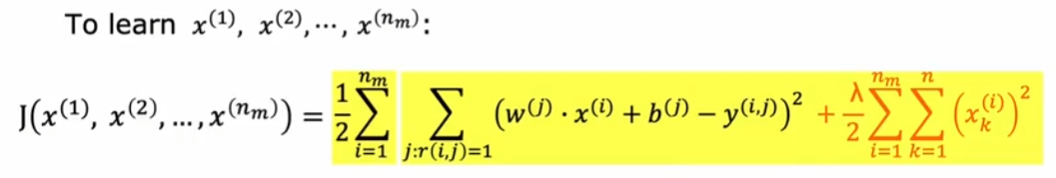
协同过滤
- Collaborative filtering,基于部分用户已打分情况推荐相似电影
- 多个用户合作评价同一部电影,可以猜测什么是适合该电影的功能,以及猜测尚未评价同一部电影的用户如何评价
上述成本函数结合:
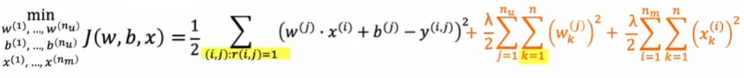
梯度下降变化
- $w_i^{(j)}=w_i^{(j)}-\alpha\frac{\partial}{\partial w_i^{(j)}}J(w,b,x)$
- $b^{(j)}=b^{(j)}-\alpha\frac{\partial}{\partial b^{(j)}}J(w,b,x)$
- $x_k^{(i)}=x_k^{(i)}-\alpha\frac{\partial}{\partial x_k^{(i)}}J(w,b,x)$,x也为参数
协同过滤算法可以通过逻辑回归运用到二进制标签应用
均值归一化
将评分都减去均值$\mu$,获取新的评分矩阵
对于用户 j,对于电影 i 预测:$w^{(j)}\cdot x^{(i)}+b^{(j)}+\mu_i$,对于新用户,此时参数均为0,则预测的值为均值而不是0,更合理
线性回归的梯度下降 使用自动求导( Auto Diff )实现
|
|
TensorFlow实现
|
|
寻找相关项:寻找$x^{(k)}$相似于$x^{(i)}$,求$\sum_{l=1}^n(x_l^{(k)}-x_l^{(i)})^2$
限制:冷启动问题——新项很少用户点评
内容过滤
- Content-based Filtering,基于用户和项的特征寻找合适匹配推荐
- 用户 j 特征$X_u^{(j)}$,电影 i 特征$X_m^{(i)}$,两个向量包含的评分数字可能不同,看是否 i 和 j 能匹配
- 预测 j 对 i 的评分由 wx+b 更改为 $V_u^{(j)}\cdot V_m^{(i)}$,分别从$X_u^{(j)}$和$X_m^{(i)}$计算得来,且包含评分数字相同
神经网络架构
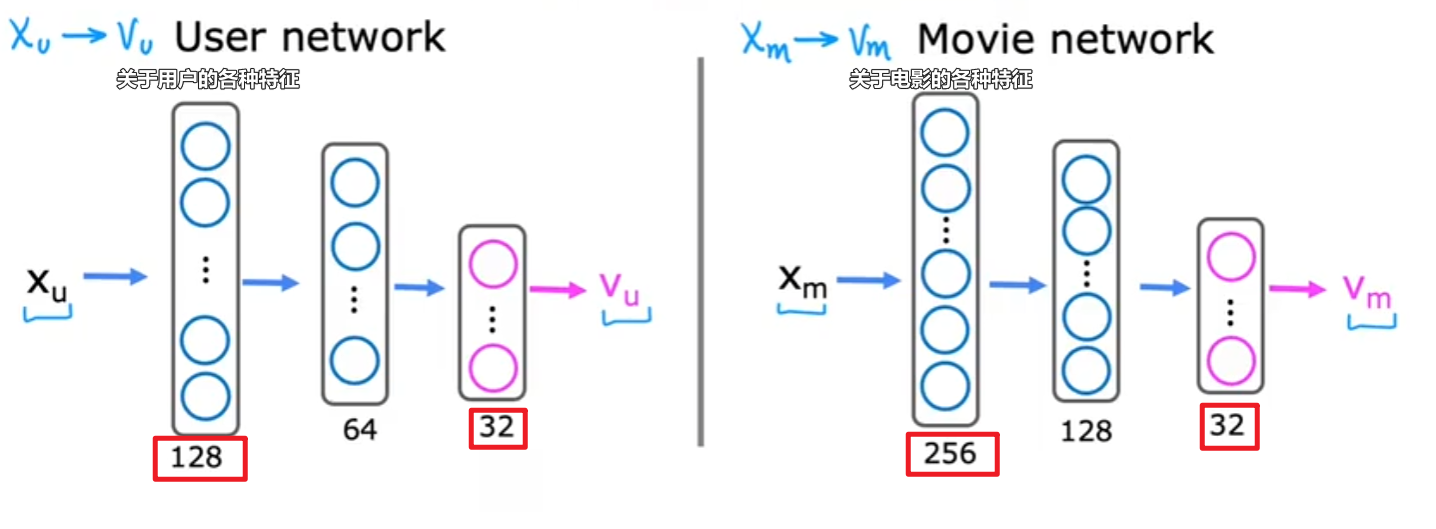
$g(V_u^{(j)}\cdot V_m^{(i)})$预测用户 j 对电影 i 即$y^{(i,j)}=1$的概率
- 32位向量$v_u^{(j)}$描述用户 j 的特征$x_u^{(j)}$
- 32位向量$v_m^{(i)}$描述电影 i 的特征$x_m^{(i)}$
成本函数
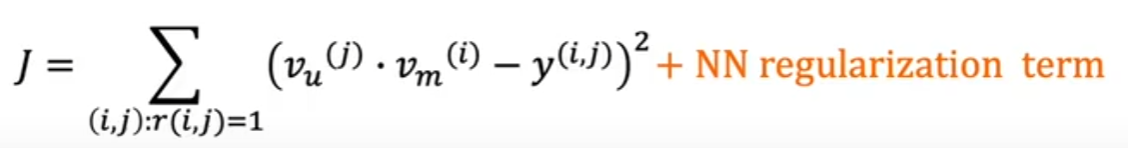
推荐类似 i 的电影:$small,,||V_m^{(k)}-V_m^{(i)}||^2$
大数据集高效推荐:检索(Retrieval),排名(Ranking)
检索:生成大量合理项目候选并去除重复项
排名:将候选使用上述神经网络框架预测分数并排名
|
|
SVM算法
- Support Vector Machine, 支持向量机算法,有监督算法,解决经典二分类问题
- 解决:选取最好的决策边界;特征数据本身难分
- 选出离边界点最远的
公式推导
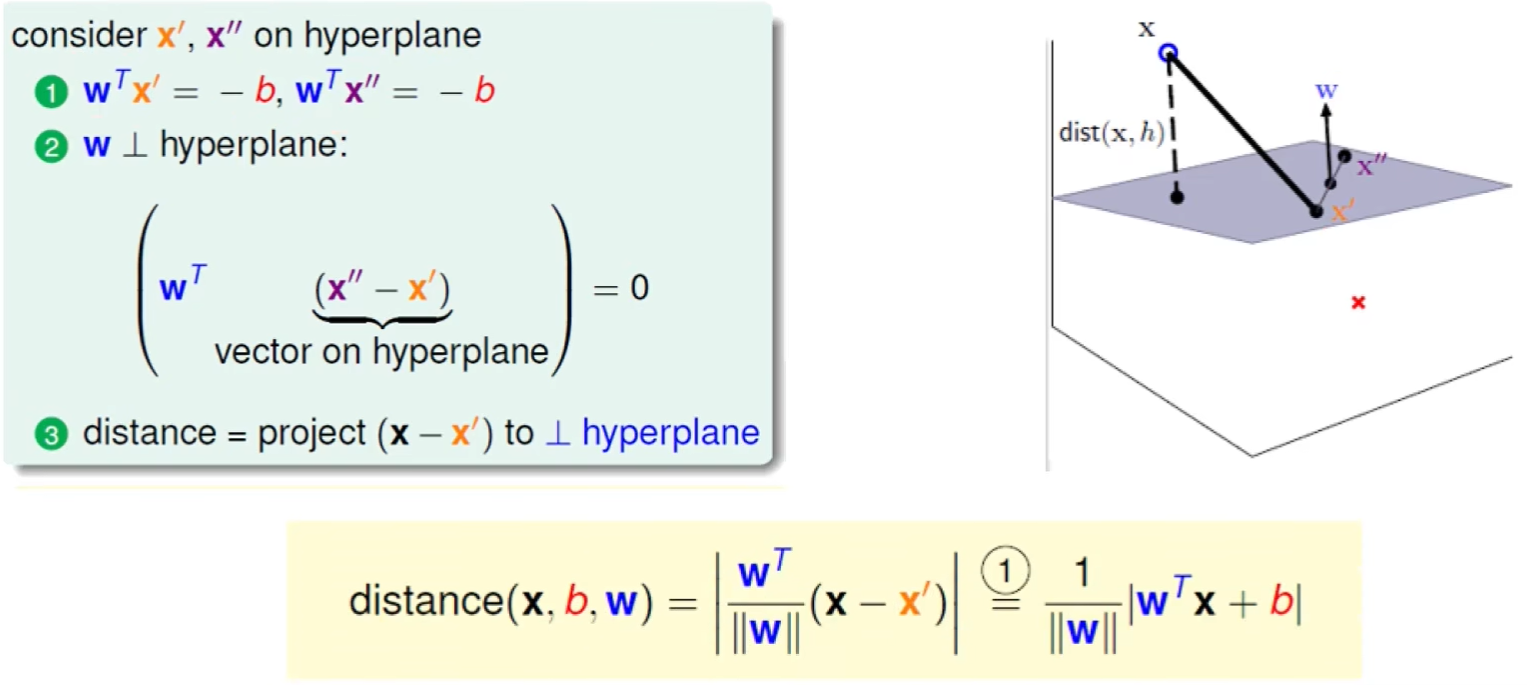
计算距离:
数据标签定义:
- 数据集:$(X_1,Y_1),(X_2,Y_2),\cdots,(X_n,Y_n)$
- Y为样本类别,X为正例Y=+1;X为负例Y=-1
- 决策方程:$y(x)=w^T\Phi(x)+b$,$\Phi(x)$对数据做了变换
- $\begin{cases}y(x_i)\gt 0\Leftrightarrow y_i=+1\\ y(x_i)\lt 0\Leftrightarrow y_i=-1\end{cases}\quad\Rightarrow\quad y_i\cdot y(x_i)\gt 0$
优化目标:
- 点到直线的距离化简****:$\frac{y_i\cdot(w^T\cdot \Phi(x_i)+b)}{||w||}$
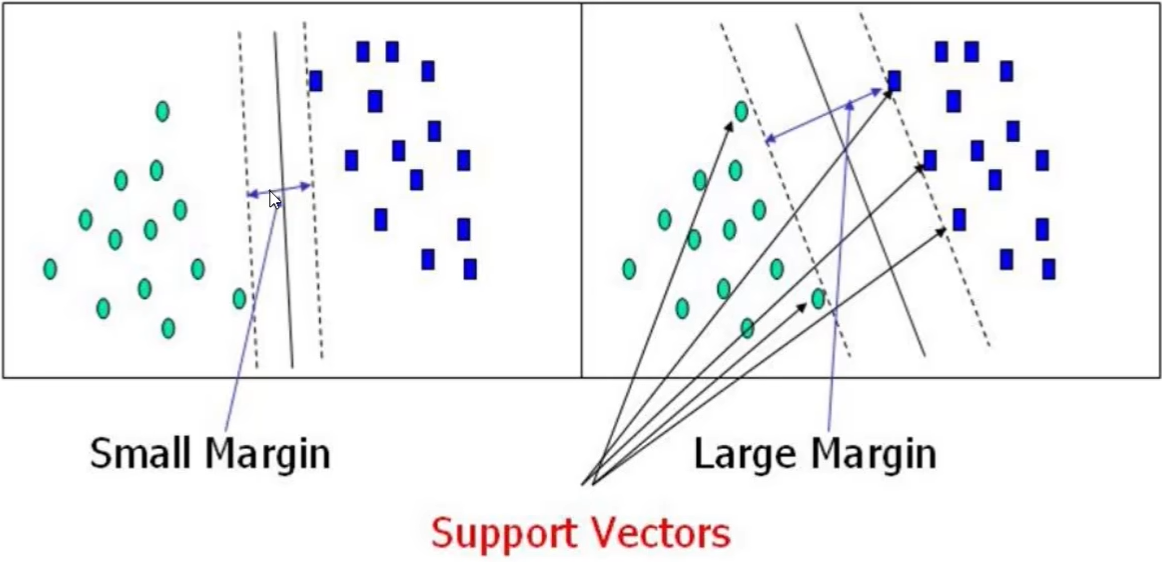
- 目标:找到一条线(w和b),使得离该线最近的点能够最远,$\mathop{arg,max}\limits_{w,b} {\frac{1}{||w||}\mathop{min}\limits_{i}[y_i\cdot(w^T\cdot\Phi(x_i)+b]}$
- 对式子放缩变换,使得$y_i\cdot(w^T\cdot \Phi(x_i)+b)\ge 1$【约束条件】,则对上式中,由于其中的min函数中的项大于等于1,则只需要考虑目标函数 $\mathop{arg,max}\limits_{w,b} \frac{1}{||w||}$
- 将求解最大值转换为求解最小值:$max_{w,b}\frac{1}{||w||} \quad\Longrightarrow \quad min_{w,b}\frac{1}{2}w^2$,并用拉格朗日乘子法求解
- 其中拉格朗日乘子法:待约束的优化问题:
- $\mathop{min}\limits_xf_0(x)$
- $subject\quad to\quad f_i(x)\le 0,,i=1,\cdots,m;\quad h_i(x)=0,,i=1,\cdots,q$
- 原式转换:$min,,L(x,\lambda,v)=f_0(x)+\sum_{i=1}^m\lambda_if_i(x)+\sum_{i=1}^qv_ih_i(x)$
- 式子化为:$L(w,b,\alpha)=\frac{1}{2}||w||^2-\sum_{i=1}^n\alpha_i(y_i(w^T\cdot \Phi(x_i)+b)-1)$
- 对w、b求导:
- $\frac{\partial L}{\partial w}=0\Rightarrow w=\sum_{i=1}^n\alpha_iy_i\Phi(x_n)$代入L函数
- $\frac{\partial L}{\partial b}=0\Rightarrow 0=\sum_{i=1}^n\alpha_iy_i$代入L函数得:
- $L(w,b,\alpha)=\sum_{i=1}^n\alpha_i-\frac{1}{2}\sum_{i=1,j=1}^n\alpha_i\alpha_jy_iy_j\Phi^T(x_i)\Phi(x_j)$
- 对$\alpha$求极大值转换为求极小值:$\mathop{min}\limits_{\alpha}\frac{1}{2}\sum_{i=1}^n\sum_{j=1}^n\alpha_i\alpha_jy_iy_j(\Phi(x_i)\cdot\Phi(x_j))-\sum_{i=1}^n\alpha_i$,条件:$\sum_{i=1}^n\alpha_iy_i=0$和$\alpha_i\ge 0$
- 实例将x和y代入获得关于$\alpha_i$的等式,然后对各个$\alpha_i$求偏导为0得到$\alpha_i$的值代入可求得w,b,$w=\sum_{i=1}^n\alpha_iy_i\Phi(x_n)$,$b=y_i-\sum_{i=1}^na_iy_i(x_ix_j)$
调整参数
软间隔——soft-margin
有时候数据中存在噪音点,对其进行考虑时会对决策线产生影响,需要要求放松一点,引入松弛因子$\xi_i$有:$y_i(w\cdot x_i+b)\ge 1-\xi_i$
则新的目标函数:$min\frac{1}{2}||w||^2+C\sum_{i=1}^n\xi_i$,使得函数越小
- C 很大时,意味分类严格;很小时,意味有更大错误容忍
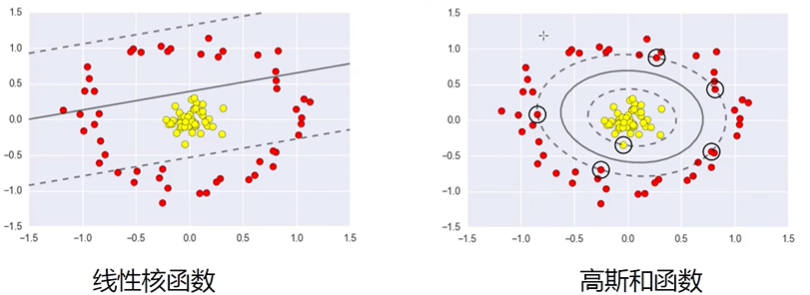
核函数
即$\Phi(x$,将低维中决策边界可能复杂过饱和的情况变换为高维中更简单决策边界的情况
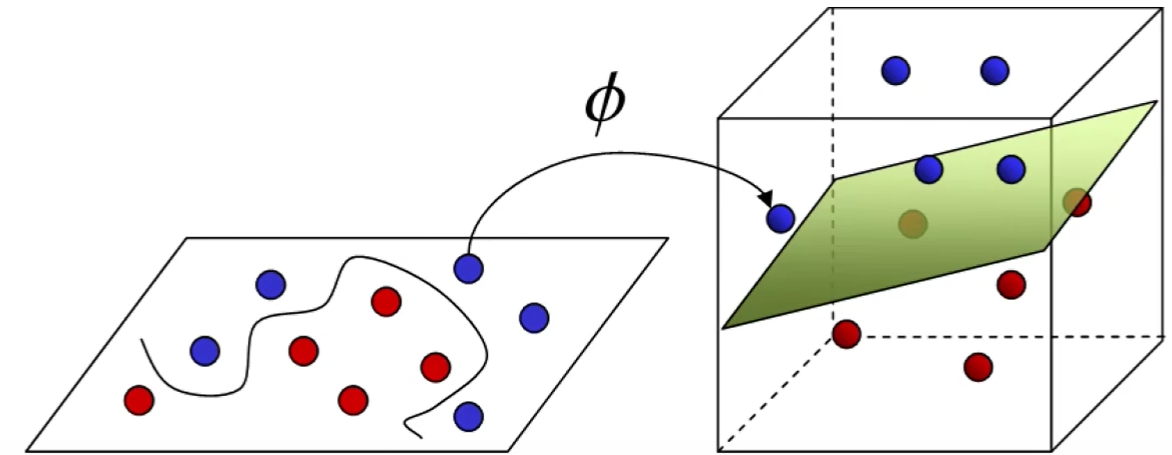
高斯核函数:$K(X,Y)=exp{-\frac{||X-Y||^2}{2\sigma^2}}$
朴素贝叶斯
贝叶斯公式:$P(A|B)=\frac{P(B|A)P(A)}{P(B)}$
邮件过滤
- 判定邮件D是否为垃圾邮件,h+表示垃圾邮件,h-表示正常邮件
$\begin{cases}P(h+|D)=\frac{P(h+)P(D|h+)}{P(D)}\\ P(h-|D)=\frac{P(h-)P(D|h-)}{P(D)}\end{cases}$,P(h+)和P(h-)为先验概率
- D由N个单词组成,所以有$P(D|h+)=P(d_1,d_2,\cdots,d_n|h+)=P(d_1|h+)\cdot P(d_2|d_1,h+)\cdot P(d_3|d_2,d_1,h+)\cdots$
- 朴素贝叶斯假设特征之间是独立的,则化简为$P(d_1|h+)\cdot P(d_2|h+)\cdot P(d_3|h+)\cdots$,则只要统计$d_i$这个单词在垃圾邮件中出现的概率即可