基本知识
安装
1
2
3
4
|
pip install langchain
pip install openai
pip install langchain-openai
# 手动下载tar解压后 python setup.py install
|
初始化
1
2
3
4
5
6
7
8
9
10
11
12
|
# coding=utf-8
import os
import httpx
from openai import OpenAI
import warnings
warnings.filterwarnings("ignore") # 去除警告
os.environ["OPENAI_API_KEY"] = 'openai_api_key'
# 解决httpx中ssl问题
proxy_url = "http://127.0.0.1:7890"
httpx_client = httpx.Client(proxies={"http://": proxy_url, "https://": proxy_url})
openai_client = OpenAI(http_client=httpx_client)
|
Text模型
1
2
3
4
5
6
7
|
response = openai_client.completions.create(
model="gpt-3.5-turbo-instruct",
temperature=0.5,
max_tokens=100,
prompt=user_prompt
)
print(response.choices[0].text.strip())
|
Chat模型
1
2
3
4
5
6
7
8
9
10
|
response = openai_client.chat.completions.create(
model="gpt-3.5-turbo",
messages=[
{"role": "system", "content": "You are a helpful assistant designed to output JSON. And Answer with chinese."},
{"role": "user", "content": "input_the_prompt_content"}
],
temperature=0.8,
max_tokens=20,
)
print(response.choices[0].message.content)
|
LangChain调用
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
|
# text模型
from langchain_openai import OpenAI
llm = OpenAI(model="gpt-xxx",temperature=0.8,max_tokens=60, http_client=httpx_client)
response = llm.invoke("xxx")
print(response)
# chat模型
from langchain.schema import HumanMessage, SystemMessage
from langchain_openai import ChatOpenAI
chat = ChatOpenAI(model="gpt-xxx", temperature=0.8, max_tokens=600, http_client=httpx_client)
messages = [
SystemMessage(content="你是一个很棒的智能助手"),
HumanMessage(content="帮助我xx"),
]
response = chat.invoke(messages)
print(response)
|
模型I/O
过程:Format输入提示,Predict调用模型,Parse输出解析
提示模板
1
2
3
4
5
|
from langchain.prompts import PromptTemplate
template = """对于 {price} 元的 {something} XXXX? """ # 原始模板f-string
prompt = PromptTemplate.from_template(template) # LangChain提示模板
input = prompt.format(something=["XX"], price="50")
|
语言模型
1
2
|
# 可初始化不同的语言模型
model.invoke(input)
|
Llama模型
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
|
# HuggingFace 调用Llama
from transformers import AutoTokenizer, AutoModelForCausalLM
# 分词器
tokenizer = AutoTokenizer.from_pretrained("meta-llama/Llama-2-7b-chat-hf")
# device_map 将预训练模型自动加载到可用的硬件设备上
model = AutoModelForCausalLM.from_pretrained(
"meta-llama/Llama-2-7b-chat-hf",
device_map = 'auto')
# 分词器将提示转化为模型可以理解的格式并将其移动到GPU上, pt返回PyTorch张量
prompt = "xxx?"
inputs = tokenizer(prompt, return_tensors="pt").to("cuda")
outputs = model.generate(inputs["input_ids"], max_new_tokens=2000)
# 令牌解码成文本
response = tokenizer.decode(outputs[0], skip_special_tokens=True)
|
输出解析
言语转换为结构化的数据结构
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
|
from langchain.output_parsers import StructuredOutputParser, ResponseSchema
prompt_template = """xxxxxx{format_instructions}"""
# 接收响应模式
response_schemas = [
ResponseSchema(name="description", description="描述xxx信息"),
ResponseSchema(name="reason", description="为何xxx"),
]
# 创建输出解析器
output_parser = StructuredOutputParser.from_response_schemas(response_schemas)
# 获取输出的格式说明
format_instructions = output_parser.get_format_instructions()
prompt = PromptTemplate.from_template(
prompt_template, partial_variables={"format_instructions": format_instructions}
)
parsed_output = output_parser.parse(output.content)# output为LLM返回
parsed_output["xxx"] = 'xxx' #也可直接赋值加入内容
# {'description': 'xxxx', 'reason': 'xxxxx', 'xxx': 'xxx'}
|
Pydantic(JSON)解析器
① 定义输出数据格式
1
2
3
4
5
6
7
8
9
10
11
|
# 创建一个空的DataFrame用于存储结果
import pandas as pd
df = pd.DataFrame(columns=["x_type", "price", "description", "reason"])
# 定义想要接收的数据格式
from pydantic import BaseModel, Field
class Description(BaseModel):
x_type: str = Field(description="种类")
price: int = Field(description="价格")
description: str = Field(description="描述")
reason: str = Field(description="原因")
|
② 创建输出解析器
1
2
3
4
|
from langchain.output_parsers import PydanticOutputParser
output_parser = PydanticOutputParser(pydantic_object=Description)
format_instructions = output_parser.get_format_instructions() # 输出格式指示
|
③ 创建提示模板
1
2
3
4
5
6
7
8
9
10
11
12
|
from langchain.prompts import PromptTemplate
prompt_template = """您是一位xxxx。
对于xx {adj} xxx {noun} ,您能xxx吗?
{format_instructions}"""
# 提示中加入输出解析器说明
prompt = PromptTemplate.from_template(prompt_template,
partial_variables={"format_instructions": format_instructions})
# input_variables: 输入变量列表
input = prompt.format(adj=adj, noun=noun) # input包含模板及输出解析器提示语
# 输出为json格式{"a": "a", "b": 1}
|
④ 解析模型输出
1
2
3
|
parsed_output = output_parser.parse(output)
# 将输出Pydantic格式转换为字典添加到DataFrame中
df.loc[len(df)] = parsed_output.dict()
|
自动修复解析器(OutputFixingParser)——解决单双引号错误
1
2
3
|
# 其中parser为PydanticOutputParser
new_parser = OutputFixingParser.from_llm(parser=parser, llm=ChatOpenAI())
new_parser.parse(xxx) # 交由LLM进行相关修复
|
重试解析器(RetryWithErrorOutputParser)——格式完全错误
1
2
|
retry_parser = RetryWithErrorOutputParser.from_llm(parser=parser, llm=OpenAI(temperature=0))
parse_result = retry_parser.parse_with_prompt(response, prompt_value)
|
提示工程
提示框架,LangChain中提供String(StringPromptTemplate)和Chat(BaseChatPromptTemplate)两种基本类型模板
- 指令instruction:告诉模型任务做啥,怎么做
- 上下文context:额外知识来源
- 提示输入prompt input:具体问题变量
- 输出指示器output indicator:标记要生成的文本的开始
提示模版类型
① PromptTemplate
1
2
3
4
5
6
7
8
9
10
11
12
|
from langchain import PromptTemplate
# 常用String提示模版
template = """xx{product}xxx"""
prompt = PromptTemplate.from_template(template)
print(prompt.format(product="input_something"))
# 提示模板类的构造函数
prompt = PromptTemplate(
input_variables=["test1", "test2"],
template="你是xxx, 对于{test1}的{test2}, xxx?"
)
print(prompt.format(test1="xx", test2="xx"))
|
② ChatPromptTemplate
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
|
# 常用Chat提示模板, 组合各种角色消息模板
# 模板的构建
system_template = "xx{product}xx"
system_message_prompt = SystemMessagePromptTemplate.from_template(system_template)
human_template = "xxx{product_detail}。"
human_message_prompt = HumanMessagePromptTemplate.from_template(human_template)
prompt_template = ChatPromptTemplate.from_messages(
[system_message_prompt, human_message_prompt]
)
# 格式化提示消息生成提示
prompt = prompt_template.format_prompt(
product="xxx", product_detail="xxx"
).to_messages()
|
③ FewShotPromptTemplate
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
|
# 创建示例样本
samples = [
{
"key1": "xx",
"key2": "yy"
},
{
"key1": "zz",
"key2": "qq"
}
]
# 创建提示模板
template="键1: {key1}\n 键2: {key2}"
prompt_sample = PromptTemplate(input_variables=["key1", "key2"], template = template)
# 创建FewShotPromptTemplate对象
prompt = FewShotPromptTemplate(
examples = samples,
example_prompt=prompt_sample,
suffix="{key1}{key2}",
input_variables=["key1", "key2"]
)
|
CoT
- 思维链,Chain of Thought,用于引导模型推理
- Few-Shot CoT提示中提供CoT示例,Zero-Shot CoT让模型一步一步思考
1
2
|
cot_template = """将包含一些对话推导示例"""
system_prompt_cot = SystemMessagePromptTemplate.from_template(cot_template)
|
TOT
- 思维树,Tree of Thoughts
- 为任务定义具体思维步骤及每个步骤候选项数量
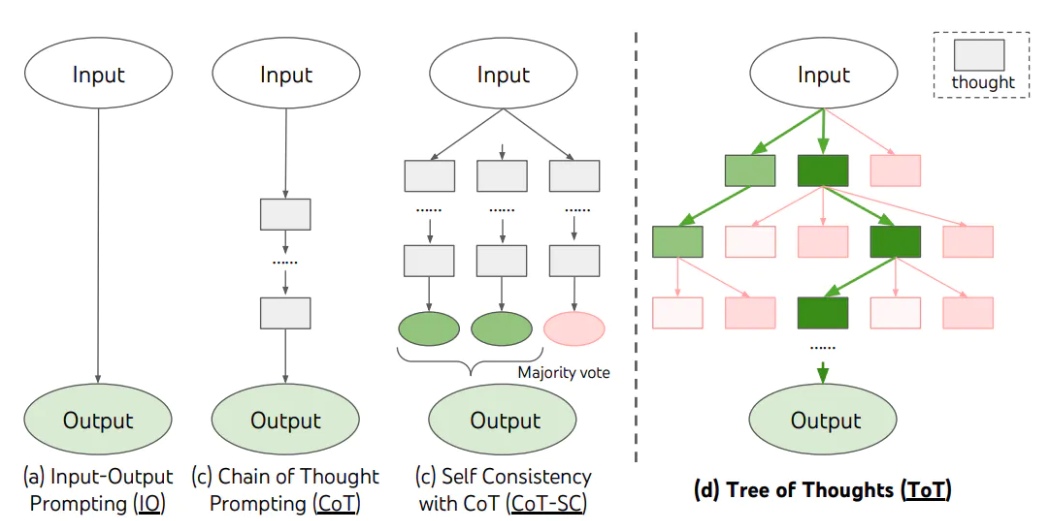
链
调用
老版本存在多种调用
1
2
3
4
5
|
result = llm_chain(dict) # __call__直接调用
llm_chain.run() # run调用
result = llm_chain.predict(xx="xx") # predict调用
result = llm_chain.apply([{dict},{dict},{dict}])# 针对输入列表apply调用, 返回字符串
result = llm_chain.generate(input_list)# 返回LLMResult对象
|
LLMChain
将提示词模板、语言模型、输出解析封装成链接口
1
2
3
4
5
6
7
8
9
10
|
from langchain_core.output_parsers import StrOutputParser
template = "{xxx}是?"
llm = OpenAI(temperature=0)
# 创建LLMChain
llm_chain = PromptTemplate.from_template(template) | llm | StrOutputParser() # RunnableSequence
result = llm_chain.invoke({"xxx": "hello"}) # 只能使用invoke调用
#llm_chain = LLMChain(llm=llm, prompt=PromptTemplate.from_template(template))
#result = llm_chain("hello") 老版本返回json格式
print(result)
|
顺序链
Sequential Chain,将多个链串联
1
2
3
4
5
6
7
8
9
10
|
# 创建多个LLMChain
first_chain = LLMChain(llm=llm, prompt=prompt_template, output_key="c") # 生成c作为后续输入
# 这是总的链,我们按顺序运行这三个链
overall_chain = SequentialChain(
chains=[first_chain, second_chain, third_chain],
input_variables=["a", "b"], # 直接输入
output_variables=["c","d","e"], # 由chat生成输入后续链中
verbose=True)
result = overall_chain({"a":"x", "b": "y"})
|
路由链
- 动态选择用于给定输入的下一个链,否则发入默认链
- 构建两个场景的模板
1
2
3
4
5
6
7
|
a_case_template = """你是a, 需要你回答:{input}"""
b_case_template = """你是b, 需要你回答:{input}"""
# 提示信息
prompt_infos = [
{"key": "a", "description": "a问题", "template": a_case_template,},
{"key": "b", "description": "b问题", "template": b_case_template,}]
|
1
2
3
4
5
|
chain_map = {}
for info in prompt_infos:
prompt = ...
chain = ...
chain_map[info["key"]] = chain
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
|
from langchain.chains.router.llm_router import LLMRouterChain, RouterOutputParser
from langchain.chains.router.multi_prompt_prompt import (
MULTI_PROMPT_ROUTER_TEMPLATE as RounterTemplate,
)
destinations = [f"{p['key']}: {p['description']}" for p in prompt_infos]
# 路由模板
router_template = RounterTemplate.format(destinations="\n".join(destinations))
# 根据模板生成路由提示
router_prompt = PromptTemplate(
template=router_template,
input_variables=["input"],
output_parser=RouterOutputParser(),
)
router_chain = LLMRouterChain.from_llm(llm, router_prompt, verbose=True)
|
1
2
3
4
|
from langchain.chains import ConversationChain
default_chain = ConversationChain(llm=llm,
output_key="text",
verbose=True)
|
1
2
3
4
5
6
7
8
|
from langchain.chains.router import MultiPromptChain
chain = MultiPromptChain(
router_chain=router_chain,
destination_chains=chain_map,
default_chain=default_chain,
verbose=True,
)
|
运行
记忆
- 通过{history}参数将历史对话信息存储在提示模板中,作为新的提示内容
1
2
|
conversation = ConversationChain(llm=llm, memory=ConversationBufferMemory())
# 缓冲记忆 conversation.memory.buffer 中存储
|
缓冲窗口记忆
ConversationBufferWindowMemory,只保存最近窗口值的互动,限制使用的Token数
1
2
3
4
|
conversation = ConversationChain(
llm=llm,
memory=ConversationBufferWindowMemory(k=1)
)
|
对话总结记忆
ConversationSummaryMemory,由另一个llm汇总传递给history
1
2
3
4
|
conversation = ConversationChain(
llm=llm,
memory=ConversationSummaryMemory(llm=llm)
)
|
对话总结缓冲记忆
ConversationSummaryBufferMemory,混合记忆,总结早期互动,保留最近互动
1
|
conversation = ConversationChain(llm=llm, memory=ConversationBufferWindowMemory(k=1))
|
代理
- 思维链无法主动更新自己知识,解决大模型“事实幻觉”:先本地知识库找否则外部搜索
- 代理根据输入决定调用哪些外部工具(数据清洗、搜索引擎、应用程序)
ReAct
- 基于推理reasoning与行动Acting之间协同作用生成任务轨迹:观察-思考-行动
- 利用SERPAPI_API_KEY作为Google搜索工具
1
2
3
4
5
6
|
# 老版本
os.environ["SERPAPI_API_KEY"] = ("xx")
tools = load_tools(["serpapi", "llm-math"], llm=llm)
agent = initialize_agent(tools, llm, agent=AgentType.ZERO_SHOT_REACT_DESCRIPTION, verbose=True)
agent.invoke("xxx")
# thought > action > action input > observation > thought > final answer
|
1
2
3
4
5
6
7
8
|
# 新版本
tools = load_tools(["serpapi", "llm-math"], llm=llm)
prompt = hub.pull("hwchase17/react")
agent = create_react_agent(llm, tools, prompt)
agent_executor = AgentExecutor(agent=agent, tools=tools, verbose=True)
agent_executor.invoke({"input": "xx"})
|
Structured Tool Chat
1
2
3
4
5
6
7
8
9
|
# 使用playwright访问网页
from playwright.sync_api import sync_playwright
with sync_playwright() as p:
browser = p.chromium.lauch()
page = browser.new_page()
page.goto("https://xx.com/")
title = page.title()
browser.close()
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
|
async_browser = create_async_playwright_browser()
toolkit = PlayWrightBrowserToolkit.from_browser(async_browser=async_browser)
tools = toolkit.get_tools()
llm = xxx
agent_chain = initialize_agent(
tools,
llm,
# 基于输入的自然语言指令,智能选择适当的工具执行任务
agent=AgentType.STRUCTURED_CHAT_ZERO_SHOT_REACT_DESCIPTION,
verbose=True,
)
async def main():
response = await agent_chain.ainvoke("xxx")
loop = asyncio.get_event_loop()
loop.run_until_complete(main())
|
Self-Ask with Search:
- 自主询问搜索代理, Follow-up Question追问+Intermediate Answer中间答案,来辅助llm寻找事实性问题的过渡性答案
- 多跳问题(Multi-hop question)引出最终答案
1
2
3
4
5
6
7
8
9
10
11
12
13
|
search = SerpAPIWrapper()
tools = [
Tool(
name="Intermediate Answer",
func=search.run,
description="useful for when you need to ask with search",
)
]
self_ask_with_search = initialize_agent(
tools, llm, agent=AgentType.SELF_ASK_WITH_SEARCH, verbose=True
)
self_ask_with_search.run("xxx?")
|
Plan and execute
- 计划与执行代理,计划由一个大语言模型代理(负责推理)完成,执行由另一个大语言模型代理(负责调用工具)完成
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
|
search = SerpAPIWrapper()
llm = ChatOpenAI(model=os.environ["LLM_MODELEND"], temperature=0)
llm_math_chain = LLMMathChain.from_llm(llm=llm, verbose=True)
tools = [
Tool(
name="Search",
func=search.run,
description="useful for when you need to answer questions about current events",
),
Tool(
name="Calculator",
func=llm_math_chain.run,
description="useful for when you need to answer questions about math",
),
]
model = ChatOpenAI(model=os.environ["LLM_MODELEND"], temperature=0)
planner = load_chat_planner(model)
executor = load_agent_executor(model, tools, verbose=True)
agent = PlanAndExecute(planner=planner, executor=executor, verbose=True)
agent.invoke("xx?")
|
工具
1
|
tools = load_tools(["arxiv"],) # 论文研究
|
自治代理
Auto-GPT
- 互联网集成、实时数据访问、自我提示,短期记忆保存上下文,多模态可处理文本、图像
RAG
Retrieval-Augmented Generation,检索增强生成
- 检索:对于给定的输入从大型文档集合中查找文档,基于密集向量搜索
- 上下文编码:将文档与原始输入一起编码
- 生成:模型生成输出
文档加载
1
2
3
4
5
6
7
|
# TextLoader
loader = TextLoader("./x.txt", encoding="utf8")
# CSVLoader
# HTMLLoader
# JSONLoader
# MarkdownLoader
# PDFLoader
|
文本转换
长文档分割成小的块,适合模型的上下文窗口
文本分割器
- 将文本分成小的、有语义意义的块(句子),将小块组合成更大的块直到达到一定大小形成块
- 创建新的文本块与块有重叠来保持块之间上下文
文本嵌入
LLM来对文本块做嵌入(Embeddings),创建一段文本的向量表示,使可以在向量空间中思考文本并执行语义搜索操作,在向量空间查找最相似的文本片段
Langchain中Embeddings类设计用于与文本嵌入模型交互
1
2
|
from langchain_community.embeddings import OpenAIEmbeddings
embeddings_model = OpenAIEmbeddings()
|
存储嵌入
缓存存储:CacheBackedEmbeddings是一个支持缓存的嵌入式包装器,嵌入缓存在键值存储中:对文本进行哈希处理作为键
缓存策略
- InMemoryStore:内存中缓存,用于单元测试
- LocalFileStore:本地文件系统存储
- RedisStore:在Redis数据库中缓存嵌入,高速可扩展
1
2
3
4
5
6
7
|
store = InMemoryStore()
embedder = CacheBackedEmbeddings.from_bytes_store(
underlying_embeddings, # 实际生成文本嵌入的工具
store, # 嵌入的缓存位置
namespace=underlying_embeddings.model # 嵌入缓存的命名空间
)
embeddings = embdder.embed_documents(["first", "second"]) # embbeder为文本生成嵌入,结果向量存储在内存存储中
|
向量存储:通过向量数据库(Vector Store)保存
数据检索
通过非结构化查询返回相关文档,向量存储检索器支持向量检索
1
2
3
4
|
index = VectorstoreIndexCreator(embedding=embeddings).from_loaders([loader])
# 创建索引来查询检索
query = "xxx是什么?"
result = index.query(llm=llm, question=query)
|
回调
回调函数
函数A作为参数传给函数B,在函数B内部调用执行A,常用于处理异步操作
异步操作
1
2
3
4
5
6
7
|
import asyncio
async def main():
task1 = asyncio.create_task(xx)
await task1
asyncio.run(main())
|
事件触发时CallbackManager会在处理器上调用适当方法,可通过BaseCallbackHandler和AsyncCallbackHandler来自定义回调函数
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
|
# 创建同步回调处理器
class MySyncHandler(BaseCallbackHandler):
def on_llm_new_token(self, token: str, **kwargs) -> None:
print(f"获取数据: token: {token}") # 新 token 生成时打印
# 创建异步回调处理器
class MyAsyncHandler(AsyncCallbackHandler):
async def on_llm_start(self, serialized: Dict[str, Any], prompts: List[str], **kwargs: Any) -> None:
... # 开始时调用
async def on_llm_end(self, response: LLMResult, **kwargs: Any) -> None:
... # 结束时调用
# 主要的异步函数
async def main():
mychat = ChatOpenAI(
model='xxx',
max_tokens=100,
streaming=True,
callbacks=[MyFlowerShopSyncHandler(), MyFlowerShopAsyncHandler()],
)
# 异步生成聊天回复
await mychat.agenerate([[HumanMessage(content="xx?")]])
# 运行主异步函数
asyncio.run(main())
|
令牌计数器
get_openai_callback上下文管理器,监控与AI交互的token数量
1
2
3
4
5
6
7
8
9
|
# 初始化对话链
conversation = ConversationChain(llm=llm, memory=ConversationBufferMemory())
# 使用context manager进行token counting
with get_openai_callback() as cb:
conversation("1")
conversation("2")
print("\n总计使用的tokens:", cb.total_tokens)
|
异步交互令牌计数
1
2
3
4
5
6
7
8
9
|
async def A():
with get_openai_callback() as cb:
await asyncio.gather( # await挂起执行
# 3 个异步调用llm.agenerate(...)
*[llm.agenerate(messages=[[HumanMessage(content="aaaa?")]]) for _ in range(3)]
)
print(cb.total_tokens)
asyncio.run(A())
|
应用
数据库应用
Chain 查询
1
2
3
4
5
|
db = SQLDatabase.from_uri("sqlite:///test.db") # 连接数据库
# 温度0: 模型输出更具确定性
llm = ChatOpenAI(model=os.environ["LLM_MODELEND"], temperature=0, verbose=True)
db_chain = SQLDatabaseChain.from_llm(llm, db, verbose=True)
response = db_chain.run("xxx?")
|
Agent 查询数据库:具有纠错能力
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
db = SQLDatabase.from_uri("sqlite:///test.db")
llm = ...
# 创建SQL Agent
agent_executor = create_sql_agent(
llm=llm,
toolkit=SQLDatabaseToolkit(db=db, llm=llm),
verbose=True,
agent_type=AgentType.ZERO_SHOT_REACT_DESCRIPTION,
)
questions = ["q1?","q2?",]
for question in questions:
response = agent_executor.invoke(question)
|
CAMEL
CAMEL交流式代理框架通过角色扮演、启示式提示框架来引导代理交流过程
1
2
3
4
5
6
7
8
9
|
# 生成系统消息
assistant_sys_template = SystemMessagePromptTemplate.from_template(
template=assistant_inception_prompt
)
assistant_sys_msg = assistant_sys_template.format_messages(
assistant_role_name='xxx',
user_role_name='yyy',
task=task,
)[0]
|
